NVMe 的由来
目前机械硬盘大多数使用 SATA (Serial ATA Advanced Host Controller Interface) 接口,接口协议为 AHCI,是 Intel 联合多家公司研发的系统接口标准。AHCI 最大队列深度为 32,即主机最多可以发 32 条命令给 HDD 或 SSD 执行,在 HDD 时代整个性能瓶颈在硬盘端,而不是接口和协议端,所以 AHCI 可以很好的匹配 HDD。但随着 SSD 硬盘技术的不断演进,使得底层闪存带宽越来越高,介质访问延迟越来越低,系统瓶颈已经由下转移到了上面的接口和协议端。这时你会发现 SATA 接口的 SSD 性能都不会超过 600MB/s,你会认为是底层闪存带宽不够,但其实是 SATA 接口速度限制了带宽。因为 SATA 3.0 最高带宽就是 600MB/s。此时,AHCI 和 SATA 已经不再满足高性能和低延迟的 SSD 的需求了,如果要充分释放 SSD 性能,那么就要设计新的协议和接口了。
在这样的背景下,2009 年下半年,Intel 、镁光、三星等厂商,一同制定了专门为 SSD 服务的 NVMe 协议,来取代 AHCI,从此 NVMe 应运而生。

NVMe 即 Non-Volatile Memory Express,是非易失性存储器标准,是在 PCIe 接口之上的协议标准,在协议栈中隶属高层。如下图所示:
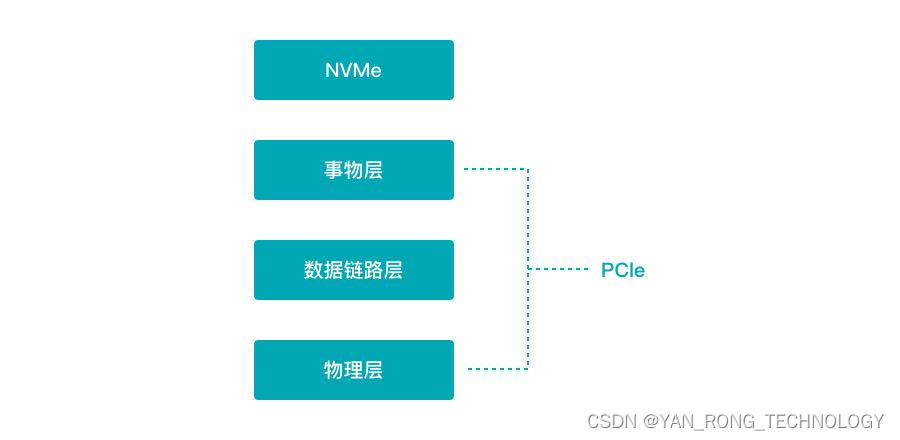
NVMe 针对 PCIe SSD 特点而设计,相比传统 AHCI 标准,NVMe 标准可以带来多方面的性能提升,可以说 NVMe 就是为了 SSD 而生的。
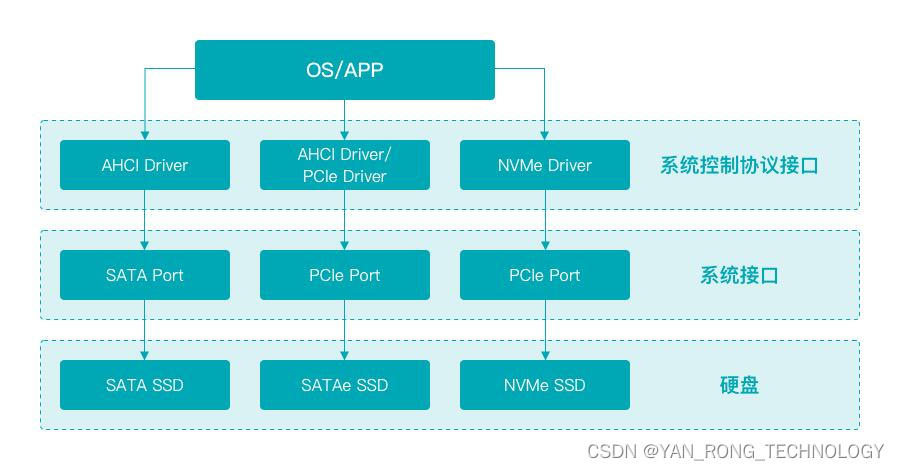
刚才我们提到了 AHCI、SATA、NVMe、PCIe,接下来,我们通过一张层次图来理解他们之间的关系和职责。
NVMe 的特点和优势
上面我们提到了 NVMe 是一种 Host 与 SSD 之间通信的协议,在整个协议栈中处于应用层的位置。NVMe相当于指挥官发送命令至下层去执行,即PCIe,它所制定的任何命令,都由 PCIe 去完成。虽然 AHCI 也可以和 PCI 搭档,但 AHCI 只有一个命令队列,最多同时只能发 32 条命令,根本驾驭不了 PCIe。而 NVMe 主要是面向 PCIe SSD 开发的一套接口标准,定义了系统接口和命令集,其目的就是让性能更好,延迟更低,功耗更低,所以目前 NVMe 和 PCIe 匹配无疑是最完美的。我们通过下面一张图来对比一下 AHCI 与 NVMe 的特点(注:图片来自 Intel FMS 2012)。

NVMe 和 AHCI 相比,它的优势主要体现在以下几点:
1、低延迟
- SSD 到 CPU 的路径更近了:从 SATA SSD 到 PCIe SSD,原生 PCIe 主控与 CPU 直接相连,而不需要像 SATA 一样连接到南桥中转,因此基于 PCIe 的 SSD 时延更低。如下图所示:PCIeSSD 作为一个PCIeEndpoint(EP)通过 PCIe 连接着 RootComplex(RC),RC 连接着 CPU 和内存。
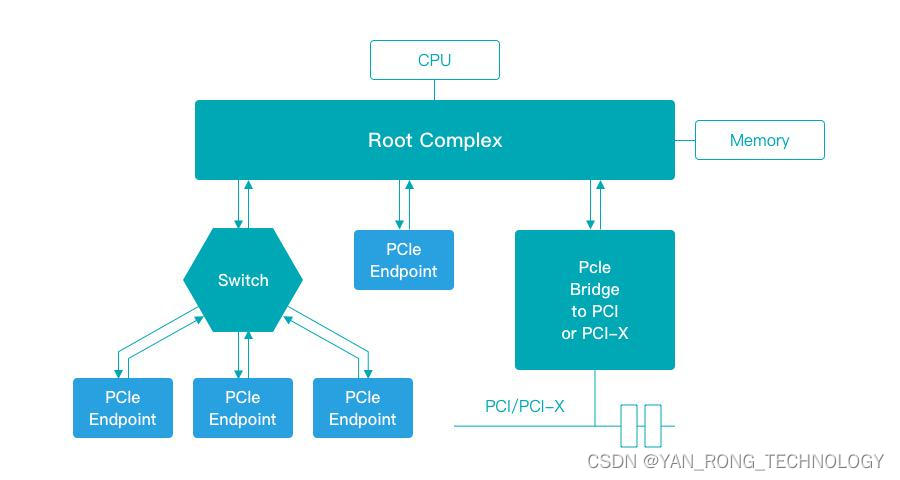
- 命令更加精简:跟 ATA 规范中定义的命令相比,NVMe 的命令个数少了很多,完全是为了 SSD 量身定制的。NVMe 缩短了 CPU 到 SSD 的指令路径,比如 NVMe 减少了对寄存器的访问次数;使用了MSI-X 中断管理;并行&多线程优化-----NVMe 减少了各个 CPU 核之间的锁同步操作等。
- 众所周知,底层存储介质 SSD 要比传统机械硬盘速度快很多;
所以基于 PCIe + NVMe 的 SSD 具有非常低的延迟。
2、高带宽、高 IOPS 性能
理论上 IOPS 与队列深度 (Queue Depth) 和 IO 延迟有关,用数学表达式是:
IOPS=队列深度/IO延迟
从上述的表达式中,我们可以看出 IOPS 与队列深度有很大的关系。注意:实际应用中,随着队列深度的增加,IO 延迟也会相应地变大。
通常 SATA 接口的 SSD,在队列深度上可以达到 32,然而这也是 AHCI 所能做到的极限。但目前企业级 PCIeSSD,其队列深度要达到 128,甚至是 256 才能够发挥出最高的 IOPS 性能。而在 NVMe 标准下,最大的队列深度可达 64K,队列数量也从 AHCI 的 1,提高到了 64K。再加上 PCIe 接口本身在性能上碾压 SATA,使得 NVMe SSD 在性能上碾压 SATA SSD 是顺理成章的事情。
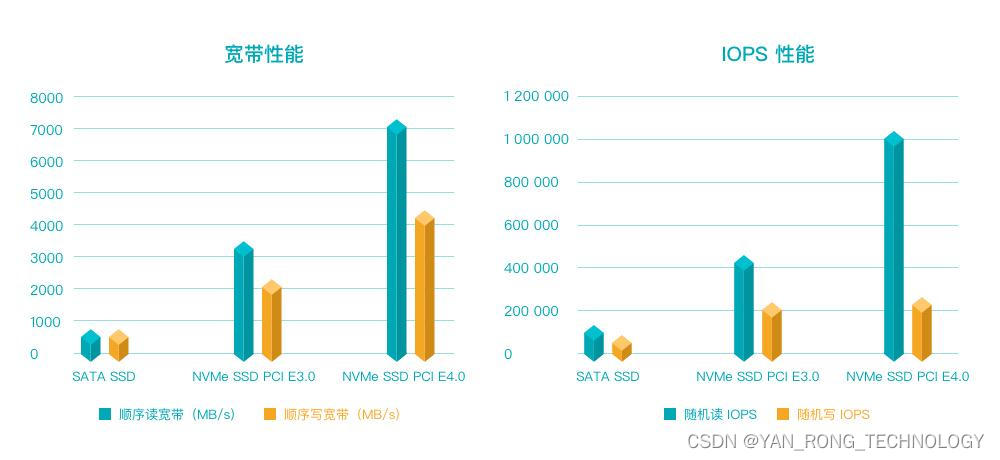
NVMeSSD和 SATA SSD 的性能对比图
3、低功耗
NVMe 中加入了自动功耗状态切换和动态能耗管理功能。NVMe Spec 支持 1-32 电源状态 (PS, Power State)。在 Host 开启自动电源状态转换功能时,可以根据自己喜好设置 Idle 多长时间后自动转换其他电源状态。
写到最后
那么,焱融追光 F8000X 全闪文件存储针对 NVMe 的性能做了哪些优化呢?
存储处理器资源既要负责 RDMA 网络数据包收发处理逻辑,又要转发 IO 给磁盘,负责磁盘的读写开销。对于传统机械硬盘来说,可以采用大量线程去压榨磁盘性能,而针对 NVMe SSD 这种方式是不现实的。所以焱融追光 F8000X 全闪文件存储采用异步非阻塞 IO 模式,有效减少上下文切换,全路径实现了零拷贝,支持批量提交和回收,增加了并行能力:
- 减少用户到内核态拷贝:通常 POSIX I/O,例如: read(),write()这种系统调用,每次用户数据要从用户态到内核态 COPY 一次。采用异步非阻塞的DMA操作,既避免拷贝,也降低 CPU 负载。
- 减少上下文切换:在 OS 发出系统调用请求之后,就去处理别的任务,等中断通知再接着上下文去处理后续任务。对于慢速介质是可以的,但是对于 NVMe SSD 这种高速介质,其实发完请求很快就结束了,又通过中断切换上下文代价太大。所以不如直接通过 Polling,相当于是用 CPU 资源换取低延迟,每个盘启动一个线程一直 polling,当来任务时立马去感知到事件去处理,使得 IOPS 提升,降低延迟。
- 增加并行:采用异步多队列线程池模型,减少锁冲突,充分发挥 IO 并行能力。
焱融追光 F8000X 全闪文件存储使用全 NVMeSSD,通过深度 I/O 模型优化设计能够充分利用 NVMe 的多队列特性,获得更高的 IOPS 性能。同时,高效分配处理器核心资源,支撑网络层面高并发数据收发处理的同时,避免大量线程的调度开销,充分发挥 NVMe SSD 磁盘性能。







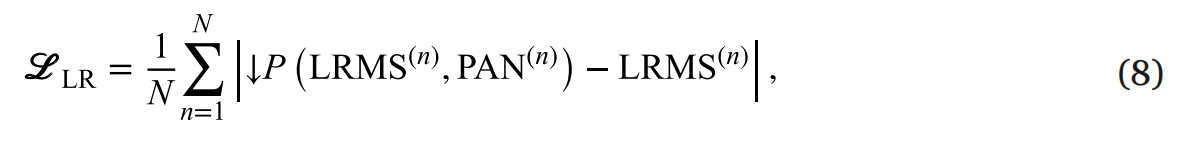

![[附源码]计算机毕业设计springboot学生宿舍管理系统](https://img-blog.csdnimg.cn/32fb4021356f42d4948ebf9ed0e5c00a.png)

![[附源码]计算机毕业设计springboot校友社交系统](https://img-blog.csdnimg.cn/4a091617afe64fddb93d1dc5f17d39d8.png)