Linux是一个非常强大、灵活和可定制的操作系统,这使得它成为了程序员的首选操作系统之一。程序员喜欢使用Linux的原因有以下几点:开源、稳定性、安全性、命令行界面、社区支持。那么新手改如何玩转Linux呢?跟着我一起来看看吧。

以下是对新手的一些建议:
1、了解基本的Linux命令:Linux是基于命令行的操作系统,因此了解基本的命令是非常重要的。例如,ls、cd、mkdir、rm等命令。
2、学习Shell脚本编程:Shell脚本是一种自动化任务的方式,可以帮助你更高效地完成任务。
3、安装和升级软件:Linux有许多不同的软件包管理器,例如apt、yum等。学习如何使用这些软件包管理器可以帮助你更轻松地安装和升级软件。
4、熟悉Linux文件系统:Linux文件系统与Windows文件系统有很大的不同,因此需要花时间熟悉Linux文件系统的结构和组成部分。
5、学习网络配置:Linux是一个非常强大的网络操作系统,因此学习如何配置网络接口、防火墙和路由器等是非常重要的。
6、加入Linux社区:Linux社区是一个非常活跃的社区,有许多专家和爱好者可以帮助你解决问题和提供建议。
7、尝试不同的Linux发行版:Linux有许多不同的发行版,例如Ubuntu、Debian、Fedora等。尝试不同的发行版可以帮助你更好地了解Linux的不同方面。
Linux爬虫怎么部署
部署Linux爬虫需要以下步骤:
1、在Linux服务器上安装Python环境和相关依赖库,如requests、BeautifulSoup等。
2、编写爬虫代码,可以使用Python的requests库发送HTTP请求获取网页内容,使用BeautifulSoup库解析网页内容。
3、将爬虫代码上传到Linux服务器上。
4、使用Linux命令行工具进入到爬虫代码所在的目录,运行命令启动爬虫程序。
5、可以使用nohup命令将爬虫程序放到后台运行,避免因为SSH断开连接导致程序停止运行。
6、可以使用crontab命令设置定时任务,定时运行爬虫程序。
需要注意的是,爬虫程序的运行需要遵守相关法律法规,不得用于非法用途。同时,爬虫程序的运行也需要遵守网站的使用规则,不得对网站造成过大的负担或影响网站正常运行。
Linux部署爬虫代码
在Linux上部署爬虫代码需要以下步骤:
1、安装Python环境:在Linux上安装Python环境,可以使用系统自带的Python版本,也可以手动安装最新版本的Python。
2、安装爬虫框架:选择一个适合自己的爬虫框架,如Scrapy、BeautifulSoup等,使用pip命令安装。
3、编写爬虫代码:根据自己的需求编写爬虫代码,可以参考框架的官方文档和示例代码。
4、配置爬虫参数:根据需要配置爬虫的参数,如爬取的网站、爬取的数据类型、爬取的频率等。
5、启动爬虫:在Linux命令行中运行爬虫代码,可以使用nohup命令将爬虫进程放到后台运行。
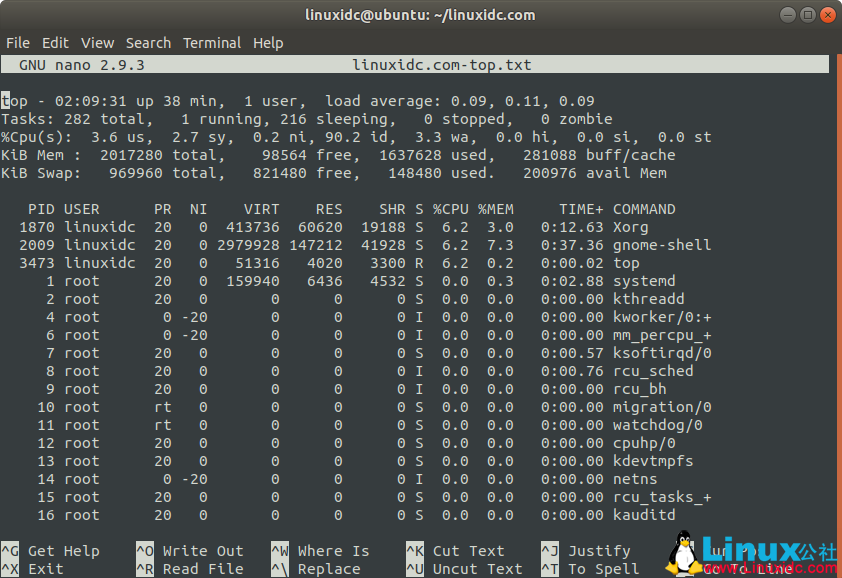
6、监控爬虫状态:可以使用Linux自带的top命令或者第三方工具如htop来监控爬虫进程的状态,如CPU占用率、内存占用率等。
7、日志管理:将爬虫的日志输出到文件中,方便查看和分析爬虫运行情况。
8、定时任务:可以使用Linux自带的crontab命令或者第三方工具如supervisor来设置定时任务,定期运行爬虫代码。