文章目录
- 一、域泛化综述
- 1)Domain定义
- 2)Domain Generalization(DG)定义
- 3)一些相关领域与DG的区别
- 4)领域泛化的方法
- 表示学习
- 领域不变表示学习
- ①基于核的方法( kernel-based methods)
- ②领域对抗性学习(domain adversarial learning)
- ③显式特征对齐(explicit feature alignment)
- ④不变风险最小化(invariant risk minimization,IRM)
- 特征解纠缠
- 二、【ICLR‘23-notable 5%】Sparse Mixture-of-Experts are Domain Generalizable Learners
Author:S-Lab, NTU + HKUST
一、域泛化综述
1)Domain定义
\quad
一个域(Domain)是由从一个分布中采样的数据组成的。下面定义中,一个S就是一个domain。

\quad
一些数学定义如下:

2)Domain Generalization(DG)定义
\quad
如下面这张图展示一样:领域泛化的目标是从一个或几个不同但相关的领域(训练集)学习一个模型,在unseen的测试领域上得到很好的泛化。(在DG的定义中,“different but related” 是重点,就是说domains虽然不同,但是一定得相关,每个domain包含的类别其实是相同的。)

\quad
DG的定义如下,目的是在M个source domain上训练后,得到一个泛化性的预测函数h,使得其在unseen test domain上的误差最小。


\quad
也就是说,在DG的每一个domain中,所包含的类别是相同的,但是它们的联合分布不同,也就是获取每个域S的采样分布
P
X
Y
P_{XY}
PXY不同。直观的体现如下图,每个域包含的类别相同,但是表现的风格不同,比如sketch,cartoon和art painting等,每种风格就叫做一种域。

3)一些相关领域与DG的区别

- 迁移学习(Transfer learning):迁移学习在源任务(source task)上训练一个模型,旨在提高模型在 不同但相关 的目标域/任务上的性能(different but related target domain/task)。预训练-微调就是迁移学习常用的策略,其中源域和目标域的任务不同,且在训练时目标域可见。在DG中,目标域不能被访问,而且训练和测试任务通常是相同的,但它们的分布却不同。
- 域自适应(Domain adaptation):DA的目标是利用现有的训练源域(s)使给定目标域上的性能最大化。DA和DG的区别在于,DA可以访问目标域数据,而DG在训练过程中看不到这些数据。域适应可以看作是 transfer learning的变体,对于一个source-trained model,DA希望使用来自Target Domain的 sparse(少量带标签) 或 unlabelled data来修正或微调这个模型。这个微调的过程叫做Adaptation,相当于对在Source Domain上已经训练好的模型,使用Target Domain中的一些数据进行modify(or, finetuning),从而使模型能够适应新的领域,克服DS问题。
- 元学习(Meta learning):元学习是一种通用的学习策略,可以通过模拟training domain的meta-train和meta-test任务,来提高DG的性能。
- 零样本学习(Zero-shot learning):zero-shot的类别不同,DG的类别相同。zero-shot不关注domain的相不相同,关注的是类别的相不相同,只要测试时的class是unseen的即可。也就是说,零样本学习(zero-shot learning) 学习在测试时碰到的类别是全新的,是在训练时未见过的类别。而DG(domain generalization)在训练和测试时的class是相同的,只是测试时同一类别所处的domain是不同的,是在训练时没有见过的domain。此外,还有小样本学习(few-shot learning),它关注的是在样本数量有限下的分类,训练时会在拥有少量样本的大量类别上训练,在测试时,对于新的类别,只需要在几个样本上微调,就可以实现这一类别的识别。
4)领域泛化的方法
\quad
DG主要分为三类方法:数据操作、表征学习、学习策略。如下图所示。

\quad
数据操作:指的是通过对数据的增强和变化使训练数据得到增强。这一类包括数据增强和数据生成两大部分。数据增强基于输入数据的增强、随机化和转换来增加样本,数据生成通过VAE或GAN等生成不同的样本以帮助泛化。
\quad 表征学习:目的在于学习领域不变特征(Domain-invariant representation learning),以使得模型对不同领域都能进行很好地适配。领域不变特征学习主要包括四大部分:核方法、显式特征对齐、领域对抗训练、以及不变风险最小化(Invariant Risk Minimiation, IRM)。此外,还有单独的一类方法叫特征解耦,它与领域不变特征学习的目标一致都是通过学习领域不变表征来进行泛化,但学习方法不一致,试图将特征分解为领域共享或领域特定的部分,以更好地泛化。(但是领域不变表征学习的方式可能并不适合GeNeRF。)
\quad 学习策略:将机器学习中成熟的学习模式引入多领域训练中使得模型泛化性更强。这一部分主要包括基于集成学习和元学习的方法。此外,还有一些方法,比如自监督学习通过构建pretext任务来学习泛化表征,以及度量学习。
下面主要从表征学习这一主流类别出发来讲解:
表示学习
\quad 从上面对DG的定义可知,域泛化的目的是学习一个泛化性的预测函数h,这里对函数h解耦为: h = f ∘ g h=f \circ g h=f∘g,其中g是一个表征学习函数,f是一个分类函数。从这一定义上也可以看出,当前的域泛化研究主要用于分类任务。
\quad
在域泛化中,表示学习的目标可以定义为如下:

\quad
其中
l
r
e
g
l_{reg}
lreg是正则化项。许多方法从更好地学习特征提取函数g与相应正则函数g的角度来设计。根据不同的学习理念,将表示学习分为两类:领域不变表示学习(Domain-invariant feature learning) 和 特征解纠缠(Feature disentanglement)。
领域不变表示学习
\quad 有工作从理论上证明(Analysis of representations for domain adaptation),如果特征表示对不同的领域保持不变,则该表示是通用的,并可转移到不同的域。基于这一理论,已经提出了大量的领域自适应算法。类似地,对于域泛化,目标是将特定特征空间中多个源域之间的表示差异减少到域不变(相当于学习一个交集),以便学习的模型能够对看不见的域具有可泛化的能力。
\quad 从这一角度出发,领域不变表示学习分为四类:基于核的方法,领域对抗性学习,显式特征对齐,不变风险最小化。
①基于核的方法( kernel-based methods)
\quad Kernel-based machine learning的基本思想是将低维空间中线性不可分的数据映射到高维空间中,使得数据在高维空间中变得线性可分。这种方法有助于解决一些机器学习任务中的非线性问题,如分类、聚类、回归等。
\quad
核函数是Kernel-based machine learning的核心。核函数通常是一种计算距离的函数,它可以用于将数据从低维空间映射到高维空间,无需计算高维空间中数据的坐标,而是只需计算该特征空间中所有对样本之间的内积。。比如,RBF(径向基函数)是常用的核函数之一,其定义为:

\quad
其中,x和x’是数据样本,γ是一个可调的参数,用于控制核函数的形状。最具代表性的基于核的方法之一是支持向量机(SVM)。
\quad 在DG中有很多基于核的算法,它们将表示学习函数 g g g 实现为一些feature map(特征映射) φ ( ⋅ ) φ(⋅) φ(⋅),这些feature map很容易使用核函数 k ( ⋅ , ⋅ ) k(⋅,⋅) k(⋅,⋅)(如RBF核和拉普拉斯核)来计算(就是计算距离)。总的来说,基于核函数的方法通过将数据映射到高维特征空间,并在该空间中计算相似度或距离来实现领域泛化。
\quad 基于核函数的方法在领域泛化中的应用主要有两个方面(泛化深度学习综述):
- 领域自适应(Domain Adaptation):在领域自适应问题中,训练数据和测试数据来自于不同的数据分布(域),模型需要在训练数据的领域上学习,然后在测试数据的领域上进行泛化。因为在DA的设定中,测试域的部分数据可以看见,因此基于核函数的领域自适应方法通过在核函数中引入领域自适应的约束,例如最大均值差异(Maximum Mean Discrepancy,MMD),来减小训练数据和测试数据之间的领域差异(拉近两种分布之间的距离),从而提高模型在测试数据上的性能。
- 迁移学习(Transfer Learning):在跨领域学习问题中,训练数据和测试数据可能来自于不同的领域,但存在一些共享的信息或知识可以用于泛化。基于核函数的跨领域学习方法通过在核函数中考虑源领域和目标领域的相似性,从而在源领域学到的知识能够帮助提升在目标领域的泛化性能。
\quad 这里学习一下Maximum Mean Discrepancy (MMD) 的知识。MMD是一种非参数的测量两种概率分布之间距离的方法。它可以用在核方法中,量化两个样本集之间的差异,其基本思想是通过将数据映射到特征空间中的特征映射函数,来比较两种分布之间的距离。
\quad MMD 的工作方式是计算两个概率分布的样本均值之间的差异。具体来说,对于两个概率分布 P P P 和 Q Q Q,MMD 通过比较它们在特征空间中的表现来计算它们之间的距离。因此,需要一个特征映射函数,将样本数据从原始空间映射到特征空间,然后计算两个概率分布在特征空间中的表现差异。这一过程可以使用核函数进行实现。
\quad MMD 可以用于衡量原始数据分布和生成数据分布之间的差异,因此在生成对抗网络 (GAN) 中得到了广泛的应用。在训练 GAN 模型时,MMD 可以被用来度量生成的样本和真实样本之间的差异,帮助 GAN 模型更好地生成真实的样本。除了 GAN,MMD 还可以应用于各种机器学习任务中,包括分类、回归、聚类和异常检测等领域。
②领域对抗性学习(domain adversarial learning)
领域对抗性训练被广泛用于学习领域不变特征。比如用于DA的领域对抗神经网络(DANN),该网络训练生成器和鉴别器。鉴别器被训练来区分领域,而生成器被训练来欺骗鉴别器来学习域不变特征表示。
③显式特征对齐(explicit feature alignment)
\quad 首先了解一下特征分布对齐这件事。特征分布对齐旨在通过特定方法来使不同样本点的特征分布相同或相似。其目标是让所有样本都共享相同的特征分布,从而提高机器学习算法的性能,尤其是在跨域的情况下(不跨域的也可以用)。以下是一些实现特征分布对齐的方法:
- 使用自适应方法:自适应方法利用一些自适应技术来将特征映射到隐式空间中,在这个空间中原始特征分布与目标分布嵌入在同一空间中,从而可以更好地对齐不同样本的特征分布。
- 基于最大平均散度 (MMD) 的方法:MMD 是测量两个分布之间距离的一种方法,利用该方法可以在两个样本点之间计算最大平均散度,从而使特征分布尽可能的相似。可以通过使用各种核函数来实现该方法。
- 非监督域自适应方法:这种方法可以使用无标签的数据来完成域自适应。这些技术利用无标签的测试数据来为训练数据生成一个合适的域自适应模型,以从不同域中提取更合适的特征,从而实现特征分布的对齐。
\quad 特征分布对齐是域自适应中的一个重要的研究领域。实现特征分布对齐既可以通过非监督学习的方法,也可以通过监督学习的方法来实现,具体方法需要针对具体的问题做出选择。
\quad 基于显式特征对齐的泛化性工作是将跨源域的特征对齐,通过显式特征分布对齐或特征归一化来学习域不变表示。
\quad 使用显式特征分布对齐的方式是:通过显式地使多个源域的特征分布尽可能接近来实现特征对齐(核方法和对比学习是隐式的)。具体操作包括以下步骤:
- 统计多个源域的特征分布。使用某种距离度量(如KL散度)来衡量源域之间的特征分布差异。
- 引入一个最小化领域距离的损失函数,以迫使分布尽可能接近。
\quad 此外,还可以使用特征归一化的方法,通过将多个源域的特征进行归一化,使得它们具有相似的统计特性,从而达到特征对齐的目的。
④不变风险最小化(invariant risk minimization,IRM)
\quad
在介绍IRM之前,先了解一下经典的泛化性方法:经验风险最小化(Empirical Risk Minimization,ERM)。经验风险是训练数据集上的损失函数的平均值,参考之前的笔记:《统计学习方法》(李航)——学习笔记。经验风险最小化就是最小化training set上的average loss。
\quad
ERM是泛化性种最经典的算法,经常被当成baseline。它的缺点是缺点是它假设了testing set和training set是同一个distribution,没有充分考虑domain shift的问题。

\quad
此外,还有一个概念也非常重要,就是虚假特征(spurious features)。
\quad
在进行跨域泛化时,常常会出现一个问题,即测试数据中可能存在一些看似与标签相关但实际上不是因果因素(causal factors),我们称之为显性混淆因素,或者一些看似与标签不相关但却能影响预测的因素,我们称之为隐性混淆因素。
\quad
其中,隐性混淆因素中的某些因素可能是偶然出现的,而与真实标签无关。这些因素被称为虚假特征(spurious features),它们可能在训练数据域中是与标签强相关的,但在测试数据中则不再具有这样的属性。
\quad
举个例子来说,在猫狗分类问题中,背景信息可能是与标签无关的虚假特征。如在训练数据中,只有猫图片的背景是花纹的,而狗图片的背景是纯黑色的,那么模型可能会学习到将花纹作为猫的特征,这样就会出现在测试数据中,只要是花纹背景的图片就被划分为猫的情况,这是不符合真实情况的。
\quad
因此,处理虚假特征是域泛化中很重要的一步,方法包括但不限于特征选择、特征变换、域自适应等。
\quad
了解完上面的前置知识后,再来看Invariant Risk Minimization(IRM)。
\quad
IRM的目标是学到invariant feature across domains,而不是和环境相关的spurious feature,如果把spurious feature记为Xs,invariant feature记为Xv,也就是有P(Y|Xv)恒定,P(Y|Xs)变化。IRM的核心思想是在模型训练过程中强制要求模型对混淆变量不敏感,即使混淆变量在不同的域中有所改变,模型也能够保持稳定的预测能力。
\quad
因此,IRM适用于那些需要处理数据中存在混淆变量的域泛化问题,比如,在医疗图像分析的领域中,由于通常数据集来源于多个医院,而这些医院之间可能存在观察性或者操作性混杂,如扫描设备的差异、拍照角度、光线等因素,这些混淆因素可能会对模型的泛化能力产生影响。在这种情况下,IRM方法能够有效地减轻混淆因素的影响,从而提升模型的泛化性能。
\quad
但是,IRM适合多个环境中共享同一个特征空间的情况下。如果不同环境下的特征空间不同,那么IRM可能会失效,需要使用其他方法来处理。
特征解纠缠
\quad 解纠缠表示学习旨在学习将样本映射到特征向量的函数,该特征向量包含关于不同变量因子的所有信息,每个维度(或维度的子集)仅包含关于某些因子的信息。
\quad 基于解纠缠的DG方法通常将特征表示分解为可理解的组合/子特征,其中一个特征是domain-shared/invariant feature,另一个是与 domain-specific feature。
\quad 根据网络结构和实现机制的选择,基于解纠缠的DG主要可分为三类:多分量分析、生成建模和因果激励方法。下面主要介绍生成建模这一类。
从数据生成过程的角度来看,生成模型可以用来进行解纠缠。这类方法试图从domain-level, sample-level, 和label-level构建样本的生成机制。一些工作进一步将输入分解到与class-irrelevant features中,这些特征包含与特定实例[201]相关的信息。域不变变分自编码器(DIVA)[124]将特征分解为域信息、类别信息和其他信息,这些信息在VAE框架中学习。Peng等人[125]在VAE的框架下解纠缠除了细粒度的域信息和类别信息。Qiao等人[40]也使用VAE进行解纠缠,他们提出了一个统一的特征解纠缠网络(UFDN),该网络将数据域和感兴趣的图像属性作为待解纠缠的潜在因素。类似地,Zhang等人[126]解开了样本的语义和变分部分。
[40] F. Qiao, L. Zhao, and X. Peng, “Learning to learn single domain generalization,” in CVPR, 2020, pp. 12 556–12 565.
[124] M. Ilse, J. M. Tomczak, C. Louizos, and M. Welling, “Diva: Domain invariant variational autoencoders,” in Proceedings of the Third Conference on Medical Imaging with Deep Learning, 2020.
[125] X. Peng, Z. Huang, X. Sun, and K. Saenko, “Domain agnostic learning with disentangled representations,” in ICML, 2019.
[126] H. Zhang, Y.-F. Zhang, W. Liu, A. Weller, B. Sch¨olkopf, and E. P. Xing, “Towards principled disentanglement for domain
generalization,” in ICML2021 Machine Learning for Data Workshop, 2021.
[201] Y. Wang, H. Li, L.-P. Chau, and A. C. Kot, “Variational disentanglement for domain generalization,” arXiv preprint arXiv:2109.05826, 2021.
参考:《Generalizing to Unseen Domains: A Survey on Domain Generalization》、泛化深度学习综述、《小王爱迁移》系列之二十八:一篇综述带你全面了解迁移学习的领域泛化(Domain Generalization)
二、【ICLR‘23-notable 5%】Sparse Mixture-of-Experts are Domain Generalizable Learners
泛化到分布外(out-of-distribution ,OOD)的数据是人类视觉的先天能力,但对机器学习模型具有高度挑战性。领域泛化(Domain generalization,DG)是解决这一问题的一种方法,它鼓励模型在各种分布变化下具有弹性,如背景、照明、纹理、形状和地理/人口统计属性。
从表征学习的角度出发,实现DG有以下几种范式:domain alignment,invariant causality prediction, meta-learning, ensemble learning, feature disentanglement。最近的研究表明,这些方法改进了ERM,并在大规模DG数据集上取得了良好的结果。除了ERM之外,域泛化其实还有很多其他的方法(DeepDG):

同时,在各种计算机视觉任务中,backbone architecture的创新在提高性能方面起着关键作用,引起了人们的广泛关注。也有工作证明了不同的CNN架构在DG数据集上有着不同的性能。受这些先驱工作的启发,我们conjecture(设想,引入假设很好的一个词:conjecture):“backbone architecture design would be promising for DG”。因此为了验证这样的直觉,我们在同等计算开销下评估了Transformer-based 和 CNN-based 的架构。但是令人吃惊的是,使用ERM训练的ViT-S/16的效果,要比使用SOTA域泛化方法(DomainNet, OfficeHome and VLCS datasets上的)训练的ResNet50的效果还要好,尽管具有相同参数量的它们在 in-distribution domain 上的效果差不多。
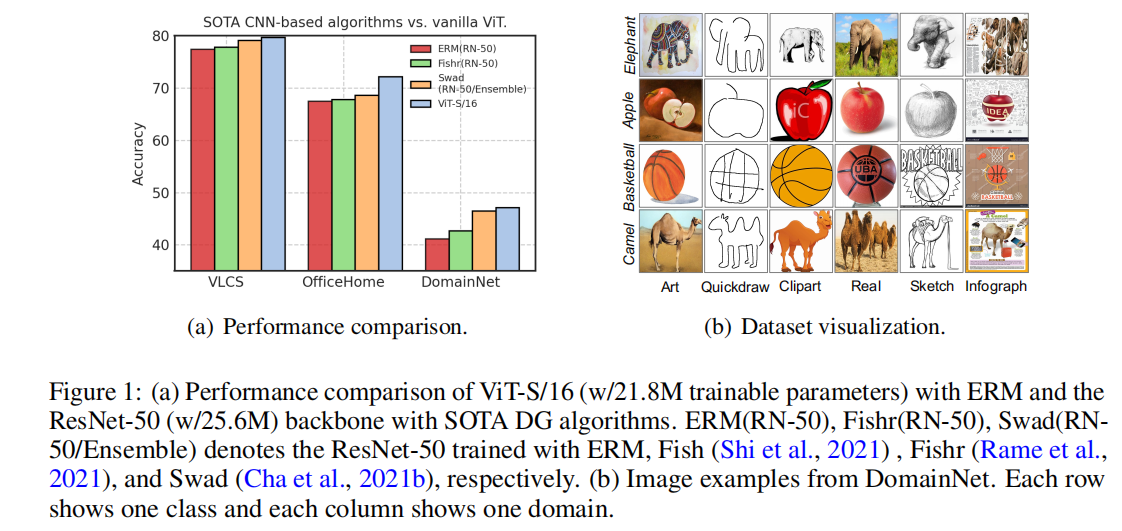
基于算法对齐框架,我们从理论上验证了这一效应。我们首先证明了使用ERM损失函数训练的网络如果其结构更类似于invariant correlation,则对分布转移更具有鲁棒性,其中相似性由Xu et al.等人(2020a)定义的alignment value正式衡量。相反,如果一个网络的体系结构与伪相关性相一致,则它的鲁棒性较差。然后,我们研究了主干架构(即卷积和注意)之间的对齐和这些数据集中的相关性,这解释了基于vit的方法的优越性能。
为了进一步提高性能,我们的分析表明:为了解决域泛化问题,我们应该利用视觉任务中invariant correlations的属性,并设计网络架构来与这些属性相一致。 这就需要在领域泛化和经典计算机视觉的交叉点上进行调查。在领域泛化中,人们普遍认为数据是由一组属性组成的,数据的分布移是这些属性的分布偏移。这些属性的潜在因子分解模型与经典计算机视觉中的视觉属性生成模型几乎相同。为了捕获这些不同的属性,我们提出了一个 Generalizable Mixture-of-Experts (GMoE),它建立于 sparse
mixture-of-experts (sparse MoEs) (Shazeer et al., 2017) and vision transformer (Dosovitskiy et al., 2021)。稀疏MoEs最初被提出作为非常大但有效的模型的关键促成因素。通过理论和经验证据,这篇文章证明了MoEs是处理视觉属性的专家,导致了更好的alignment with invariant correlations。
本文的创新性:
- A Novel View of DG: In contrast to previous works, this paper initiates a formal exploration of the backbone architecture in DG. Based on algorithmic alignment (Xu et al., 2020a), we prove that a network is more robust to distribution shifts if its architecture aligns with the invariant correlation, whereas less robust if its architecture aligns with spurious correlation. The theorems are verified on synthetic and real datasets.
- A Novel Model for DG: Based on our theoretical analysis, we propose Generalizable Mixture-ofExperts (GMoE) and prove that it enjoys a better alignment than vision transformers. GMoE is built upon sparse mixture-of-experts (Shazeer et al., 2017) and vision transformer (Dosovitskiy et al., 2021), with a theory-guided performance enhancement for DG.
- Excellent Performance: xxx
写文章时:
第一个创新性一般是一个别人从来没有过的观察角度和分析,并通过这样的观察和分析证明出一个结论。
第二个创新性一般是基于这样的观察设计了一个模型来结局。
第三个一般是模型结果。