2023年AI芯片报告汇总了60家国产AI芯片厂商,大致按如下应用类别进行归类:云端加速、智能驾驶、智能安防、智能家居、智能穿戴、其它AIoT。对于每一家筛选的公司,我们从主要产品、核心技术、应用场景、市场竞争力、发展里程碑等方面对公司进行全方位画像分析。
AI芯片报告概要
作为AspenCore Fabless100系列行业分析报告的一部分,2023年AI芯片报告在2022年《45家国产AI芯片厂商调研分析报告》基础上,汇总了60家国产AI芯片厂商,大致按如下应用类别进行归类:云端加速、智能驾驶、智能安防、智能家居、智能穿戴、其它AIoT。对于每一家筛选的公司,我们从主要产品、核心技术、应用场景、市场竞争力、发展里程碑等方面对公司进行全方位画像分析。
我们首先对“存算一体”技术及其对AI芯片未来发展带来的影响进行了简要阐述,然后分别对三大AI应用场景(云端加速、智能驾驶、边缘计算)进行了市场趋势概括。本届报告的内容大纲安排如下:
存算一体AI芯片及技术趋势
AI应用:云端加速
AI应用:智能驾驶
AI应用:边缘计算
Fabless100排行榜之Top 10 AI芯片公司
60家国产AI芯片厂商信息汇总
结语与展望
存算一体AI芯片及技术趋势
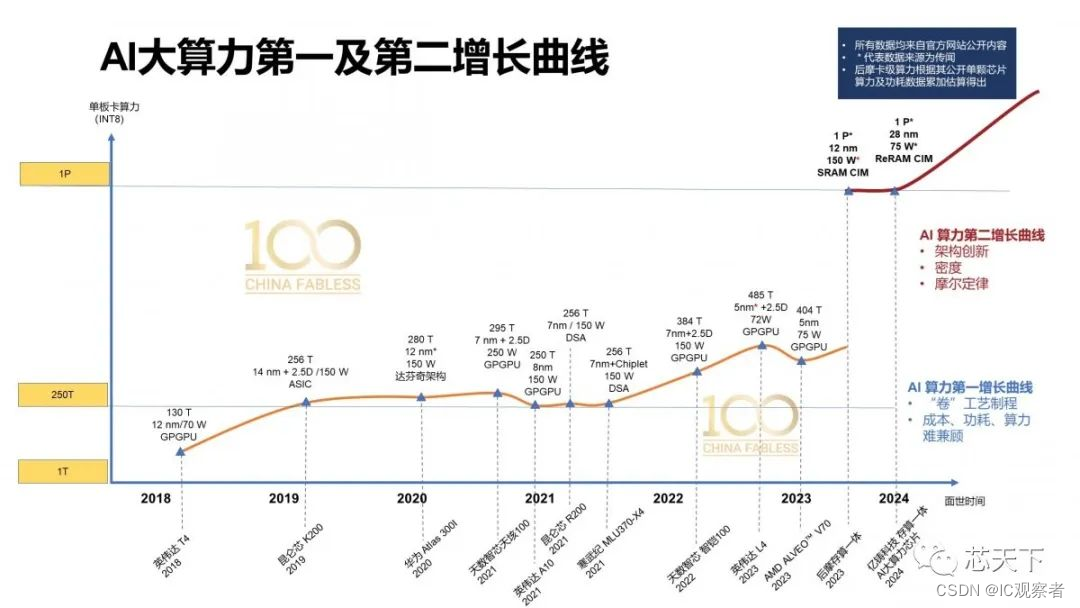
本部分内容涉及“存算一体”冲破能耗墙、Chiplet和2.5D/3D堆叠先进封装、ReRAM材料/工艺和AI应用潜力,以及存算一体+Chiplet助力AI算力第二增长曲线等内容。详细阅读请点击上面的链接。
AI应用:云端加速
ChatGPT等大语言模型(LLM)的AI模型训练需要大量并行处理能力,目前最适合的芯片还是GPU,比如英伟达H100和A100。尽管GPU价格昂贵且功耗极大(采用TSMC 4nm工艺的H100 GPU SXM加速卡功耗高达700W),但微软和谷歌等互联网巨头为了赢得AI竞赛仍大量购买,预计英伟达GPU的这种强劲需求势头仍将持续下去。
除了英伟达GPU外,目前能够提供云端训练和推理加速芯片的独立厂商及产品还有壁仞科技BR100系列、高通Cloud AI 100、墨芯智能英腾处理器(ANTOUM)、燧原科技邃思2.0/2.5、瀚博半导体SV100、寒武纪思元370、鲲云科技CAISA数据流推理AI芯片等。
以国内AI芯片初创公司墨芯为例,在最近的MLPerf评测中,墨芯凭借软硬协同的稀疏计算技术在ResNet50模型上蝉联冠军。其 S40计算卡以127,375 FPS获得单卡算力全球第一;S30计算卡以383,520 FPS算力获整机4卡算力全球第一。墨芯AI计算卡系列是基于其稀疏计算AI芯片12nm Antoum,性能超越了4nm工艺的GPU,展现出稀疏计算的强大优势。
基于双稀疏化算法技术和独特AI芯片架构的Antoum芯片针对云端AI推理场景,可支持高达32倍稀疏率。Antoum是一款高性能通用可编程芯片,可支持CNN、RNN、LSTM、Transformer、BERT等网络模型和浮点、定点丰富的数据类型。墨芯人工智能AI加速卡基于Antoum芯片,通过优化计算模式,可支持全面稀疏化神经网络开发,是一种高算力、低功耗的通用AI推理加速卡。
稀疏计算能够为AI大模型带来数十倍的加速性能,也许是GPU之外云端加速的一条“软硬协同”新途径。而前面提到的“存算一体”可能是另外一条迎接大模型挑战的“硬件”途径,国产AI芯片初创公司亿铸科技正在研发的基于ReRAM的全数字化存算一体AI大算力芯片及加速卡,仅用75W的功耗即可实现500T的算力。
AI应用:智能驾驶
伴随着汽车的智能化,汽车E/E架构正从传统的ECU为主转向域控制器,计算架构设计也从分布式逐渐转向集中式中央处理器。我们目前正处于从过去的分布式EE架构迈向域集中式EE架构的转变过程中,预计到2025年左右就会完成这一转变。此后将开启跨域融合,也就是转变为“中央+区域”(Central & Zonal)计算的EE架构时代。
汽车逐渐转变为像手机和电脑一样的联网通信和计算设备,但对计算处理能力的实时性和可靠性要求更高,因为汽车的运行环境更为复杂且安全性要求更为苛刻。针对L2及以上级别智能驾驶的AI芯片主要面向三个细分领域:辅助驾驶ADAS、智能座舱、自动驾驶。
ADAS
ADAS(高级辅助驾驶系统)通常包括导航与实时交通系统TMC、电子警察系统ISA、自适应巡航ACC、车道偏移报警系统LDWS、车道保持系统、碰撞避免或预碰撞系统、夜视系统、自适应灯光控制、行人保护系统、自动泊车系统、交通标志识别、盲点探测,驾驶员疲劳探测、下坡控制系统和电动汽车报警系统等。
而随着汽车功能越来越复杂,支持系统的芯片本身也变得越来越复杂,ADAS已不再是单独的域控制器,已经被整合和定义成为复杂的SoC了,多核心实时响应已经成为标配。AEB、LKA等功能都需要强大的视觉算法加持,利用激光雷达和传统雷达以及视觉融合等多种传感器的复杂算法更需要性能强大的芯片支持,很多SoC已经采用14nm甚至7nm的工艺节点。
从芯片设计的角度来说,现在ADAS处理器芯片面临的主要挑战包括:车规级标准,如ISO26262,要求达到ASIL-B甚至ASIL-D级别;多传感器融合的处理需要更高的芯片性能和带宽,以达到快速数据处理和传输吞吐率要求;增加硬件的深度学习设计,如何做好软硬件协同,以及适应快速发展的AI计算模型。
传统汽车芯片厂商如NXP、英飞凌、瑞萨、ST和TI等,都有各自的ADAS芯片和系统应用解决方案。而靠ADAS和自动驾驶芯片起家的Mobileye在这一市场也已经占据重要地位。国内汽车智能驾驶芯片开发商如地平线、黑芝麻智能、芯驰科技,以及四维图新旗下的杰发科技也都在ADAS领域提供了具有竞争力的芯片产品和ADAS应用方案。
智能座舱
单芯片方案实现智能座舱类似于座舱域控制器的方案,可以精简座舱处理器布局,降低成本。智能座舱单芯片方案要能够处理多块高清屏的显示、HUD、摄像头输入、语音及手势交互等设备,因此芯片厂商需要具备一定的技术积淀才能够研发类似的一体化芯片方案。
随着客户需求的多样化与技术的进步,以多模交互为核心的智能座舱正成为汽车行业技术发展的一大趋势。其中,在视觉识别和语音处理等交互技术的高度整合需求下,基于AI芯片的独立感知层将成为实现多模交互、推动智能座舱高速发展的关键驱动力。
未来座舱系统将变得非常复杂,不仅需要芯片方案,也需要相应的算法支持。芯片通过输出计算能力来支持操作系统、ADAS等软件的运行,未来智能座舱所代表的“车载信息娱乐系统+流媒体后视镜+抬头显示系统+全液晶仪表+车联网系统+车内乘员监控系统”等融合体验,都依赖于芯片计算能力的提升。同时具备芯片研发和相应的软件及算法开发能力的公司,在激烈的市场角逐中将更有竞争力。
以高通为代表的国际芯片厂商提供的智能座舱芯片和系统解决方案已经在很多国产汽车型号上采用。国产智能汽车AI芯片初创公司芯擎科技发布的多媒体智能座舱芯片“龍鷹一号”已经上车领克汽车旗下新能源中型SUV – 领克08。这款型号为SE1000的智能座舱芯片采用7nm工艺,拥有8核CPU、14核GPU,以及8 TOPS AI算力的独立NPU。其强大的音视频处理能力最多可支持7屏高清画面输出和12路视频信号接入,并配备了双HiFi 5 DSP处理器。此外,该芯片具备高安全等级的“安全岛”设计,满足ISO26262车规认证,专业的硬件加/解密引擎为车载应用提供了安全性保证。
自动驾驶
自动驾驶从L0到L5级别,随着功能的完善和性能的提升,在带来更好智能体验的同时,也对AI芯片的算力和性能提出更高的要求。L2(ADAS)需要的AI计算力小于10TOPS;L3的AI计算力为30~60TOPS;L4的AI计算力>100TOPS;L5需要的AI计算力为500-1000TOPS。要承担环境感知、多传感器融合及深度学习算法等超大算力需求的AI处理芯片通常采用GPU或DSA专用芯片,如英伟达的Orin GPU、地平线征程J5等。
NVIDIA DRIVE Orin SoC可提供254 TOPS性能,为自动驾驶、置信视图、数字集群以及 AI 驾驶舱提供动力支持。借助可扩展的 DRIVE Orin平台,开发者可从 L2+ 级系统一路升级至 L5 级全自动驾驶汽车系统。Orin SoC采用7纳米工艺,由Ampere架构GPU、ARM Hercules CPU、第二代深度学习加速器DLA、第二代视觉加速器PVA、视频编解码器、宽动态范围的ISP组成,同时引入了车规级的安全岛Safety Island设计。Orin支持204GB/s的内存带宽和最高64GB的DRAM,高速I/O接口与上一代Xavier SoC的接口兼容,可实现275TOPS的INT8算力(是Xavier的7倍),功耗为55W。
地平线发布的高性能大算力车载智能芯片征程5是其第三代车规级产品,遵循 ISO 26262 功能安全认证流程开发,并已经通过ASIL-B 认证。该芯片基于地平线BPU贝叶斯架构设计,可提供高达128TOPS算力;外部接口丰富,可接入超过16路高清视频输入;适用于先进图像感知算法加速,还可支持激光雷达、毫米波雷达等多传感器融合;支持预测规划以及H.265/JPEG实时编解码。
基于自研计算平台与产品矩阵,目前地平线已支持 L2、L3、L4 等不同级别自动驾驶的解决方案。在智能驾驶领域,地平线同全球四大汽车市场(美国、德国、日本和中国)的业务联系不断加深,目前达成合作的车厂及Tier1包括奥迪、博世、长安、比亚迪、上汽、广汽、长城、理想等。
另外一家国产智能驾驶AI芯片公司后摩智能最新发布的鸿途H30芯片基于SRAM 存储介质,采用数字存算一体架构,拥有极低的访存功耗和超高的计算密度。该芯片基于 12nm 工艺,在 Int8 数据精度下可实现高达 256TOPS 的物理算力,所需功耗不超过 35W,整个 SoC 能效比达到了 7.3Tops/W。为了更好地实现车规级功能,后摩智能基于鸿途H30 自主研发了硬件增强机制和检测机制,在提升芯片可靠性的同时,进一步保障了功能安全性。后摩鸿途H30芯片适用于面向商用车L4级别及乘用车L2++级别的智能驾驶解决方案。配合其力驭域控制器硬件及软件算法参考设计,可为商用车运营商在垂直交通应用场景下提供L4级自动驾驶整体方案。
AI应用:边缘计算
相对于云端加速和智能驾驶应用,面向边缘计算和端侧应用场景的AI芯片一般更加强调低功耗和高效能,因为在这类应用中部署的计算设备数量庞大,分布广泛(从边缘网关到终端),而且很多端侧设备都是采用电池供电,对功耗要求特别严格。这类应用包括智能手机/平板电脑、智能安防、智能家居、智能穿戴,以及智慧城市、工业物联网、智慧农业及智慧医疗等。
据Deloitte和Statista预测统计,边缘和端侧AI芯片按不同应用设备的出货量对比如下。智能手机集成的AI芯片出货量最大,将从2020年的5亿颗增加到2024年10亿颗;平板电脑、智能音箱和可穿戴设备也都有不同程度的增长;企业边缘设备的增长率最高,从2020年5000万颗增至2024年的2.5亿颗。
边缘/端侧AI芯片特性
面向边缘和端侧AI计算的AI芯片具有如下特点:
保护数据安全和隐私:数据可以就地处理,不需要传输到云端,从而减少敏感数据被盗取或泄露的风险;
不依赖网络:有些应用场合没有网络连接,或者网络连接质量很差或传输速度很慢,这种情况下边缘AI芯片就可以“就地处理”数据,实现很多原来无法做到的功能和任务;
降低功耗:边缘AI芯片的功耗比云端AI芯片低得多,在很多电池供电设备上可以极低的功耗执行AI计算;
低延迟:利用边缘AI芯片直接在设备上执行AI处理可以将数据延迟降低至纳秒级,这对数据的即时采集、处理和执行至关重要;
低成本部署 :边缘和端侧设备一般安装量很大,嵌入这类设备的AI芯片要求在功耗和成本上都要比云端AI芯片低,这样才能让AI应用大面积部署。
边缘计算AI芯片的技术发展趋势主要表现在三个方面:
低功耗设计:由于边缘计算需要更加高效地利用计算资源和硬件供电容量,许多AI芯片架构开始采用低功耗设计,以减少芯片的能耗开销,使其能够更加持久地运行;
安全加密:随着云端攻击事件日益增多,AI芯片架构更加注重安全性,通常采用加密技术、身份验证等措施来保护数据和系统安全;
弹性设计:由于边缘计算更加贴近实际应用场景,而边缘和终端应用比较碎片化,因此许多AI芯片架构开始采用弹性设计,以便灵活适应不同的应用需求,从而提高应用稳定性和可扩展性。
除了硬件设计的改变,深度学习框架也在发生变化。许多框架开始加入对边缘计算的支持,如PyTorch、TensorFlow、Caffe等。这些框架不仅可以支持边缘设备上的深度学习推断,还提供了对多种边缘计算平台的原生支持,如FPGA、ASIC等。
边缘AI应用场景
除了智能手机和平板电脑、企业计算和通信网络、智能驾驶/ADAS外,边缘AI应用场景还包括:
智能安防:从视觉分析的过程来看,对于需要实时近实时处理,或者涉及数据隐私的场景往往在智能边缘平台进行推理和识别。相较传统的图像视频处理器,视觉芯片集成了,这是中的计算单元。由于是专门为加速而设计的处理单元,在计算的速度和准确率都会有大幅的提升。据预测,到年安防芯片市场规模将超过亿美元,其中三分之二是具有功能的芯片。
智能家居:Matter标准加速了全球智能家居生态融合,将催生出更多跨场景、多功能的智能家居创新产品形态。数据显示,2019年全球消费者在智能家居方面的支出达到1030亿美元,预计2023年市场规模将增至1570亿美元,呈快速发展态势。
智能穿戴:目前市场上手表、手环、耳机产品占据了超过90%的比例,而AR/VR眼镜以及可穿戴医疗设备正成为智能穿戴市场新势力,有望推动下一轮增长。此外,医疗健康也是智能穿戴产品差异化的重点,各大厂商都在致力于打造差异化竞争力。
工业物联网:随着工业智能化和物联网等行业趋势的快速兴起,工业领域正在进入一个全新的物联网时代,数十亿嵌入式设备实现了无缝互连,工业物联网普及范围不断扩大,市场规模持续上升。
边缘AI应用场景还包括智慧城市(智能交通、智慧杆和市政智能电/水/气表网络等)、智慧农业(养/种殖、食品安全溯源防伪、环保生态旅游),以及智慧医疗(智能医疗设备、远程医疗、医疗大数据分析)等。
边缘AI市场竞争
边缘和端侧AI芯片的研发投入和下游应用设计导入相对云端训练和推理AI芯片来说门槛较低,因此竞争也更为激烈。一方面,国际芯片巨头看到边缘计算的应用前景纷纷进入这一市场,国际厂商包括英特尔、AMD、英伟达、高通、联发科、博通、TI、ST、瑞萨、英飞凌、Microchip和NXP等。另一方面,AI的兴起也推动着风投和初创公司加入边缘和终端AI芯片的角逐,这一领域比较知名的初创公司包括Hailo、Anari、Groq、Gyrfalcon、Kalray、Mythic、Zero ASIC(Adapteva)等。
在边缘AI芯片领域,国内初创公司跟国外厂商基本处于同一起跑线上,在融资和市场竞争方面甚至更为激烈。在我们汇总整理的60家AI芯片厂商中,大部分都是面向边缘和端侧AI应用场景的,比如华为海思、紫光展锐、地平线、亿智电子、爱芯元智、北京君正、瑞芯微、全志科技和云天励飞等。
2023 Fabless 100排行榜之Top 10 AI芯片公司
由AspenCore分析师团队根据量化数学模型、企业公开信息、厂商调查问卷,以及一手访谈资料,精心筛选出中国IC设计行业综合实力和增长潜力最强的公司。这些公司按照类别划分(每家公司仅归入一个类别),每个类别评选出Top 10。在60多家国产AI芯片公司中,我们从企业融资、技术创新、产品出货量及市场竞争力等方面筛选出10家最具实力和增长潜力的Top 10 AI芯片公司。
入选公司基本信息(只有寒武纪一家上市公司,其它入选公司都没有综合指数):
Top 60国产AI芯片厂商信息汇总
在我们挑选的这60家国产AI芯片公司中,属于云端加速应用类别的有22家;智能安防14家;智能驾驶11家;智能穿戴6家;智能家居5家;其它AIoT类别2家。
从公司总部所在城市来看,位于上海的有18家;北京16家;深圳6家;杭州5家;南京2家;珠海2家;成都2家;江苏省2家;福建省2家;湖北、安徽、重庆、广州和苏州各1家。
从公司成立年份来看,2016年及以前成立的有20家;2017年成立的7家;2018年成立的14家;2019年成立的6家;2020年成立的8家;2021年成立的4家;2022年成立的有1家。
60家国产AI芯片厂商详细介绍,关于芯片设计公司,IC修真院有给大家详细介绍。
亿铸科技
主要产品:基于ReRAM的全数字化存算一体AI大算力芯片及加速卡。
核心技术:对新型忆阻器RRAM cell级的深刻理解与应用;存算一体AI大算力芯片的硬件及软件架构设计;配套的软件编译器及工具链。
应用场景:中心侧服务器、云计算、数据中心、智慧安防、智慧教育、智慧金融、自动驾驶、计算机视觉、智能视频处理应用、自然语言处理、AIGC、云端和边缘计算应用等。
市场竞争力:超高能效比、超大算力发展空间、支持高精度计算,首家面向云计算和中心侧推出存算一体AI大算力芯片的公司,团队有大量高端集成电路设计和量产经验以及丰富的应用和产品化实战经历。
发展里程碑:完成过亿元天使轮融资,由中科创星、联想之星和汇芯投资(国家5G创新中心)联合领投;获得超亿元Pre-A轮融资,隆湫资本领投。
爱芯元智
主要产品:AX650N、AX630A、AX620A、AX620U、AX170A
核心技术:高算力,高画质,高能效比的SoC芯片。小型化封装,低功耗,带来优质的AI体验。
应用场景:AI摄像机、智能盒、智能运动相机、智能交通摄像机、智能车载视觉系统、AI加速卡、智能视觉中枢
市场竞争力:超强算力、AISP、4K编解码、视频结构化、多路解码
发展里程碑:截至2022年1月,爱芯元智已经完成四轮融资,整体融资进程顺利,公司发展方向获得投资方高度认可。
地平线
主要产品:征程系列 征程®5芯片 、旭日系列 旭日® 3、Matrix系列 Matrix®5
核心技术:第三代车规级产品,也是国内首颗遵循 ISO 26262 功能安全认证流程开发,并通过ASIL-B 认证的车载智能芯片。
应用场景:高级别自动驾驶及智能座舱量产
市场竞争力:双核BPU贝叶斯架构,高性能算力128 TOPS,八核 Arm® Cortex® -A55 CPU集群,CV引擎,双核DSP,双核ISP,强力Codec,支持多路4K及全高清视频输入及处理,双核锁步MCU,功能安全等级达 ASIL-B(D),全面符合 AEC-Q100 Grade 2 车规级标准。
发展里程碑:2020年地平线量产中国首款车规级AI芯片“征程二代”,2020 年 12 月 C 轮融资总额超 7 亿美金,已完成 C1 轮融资。
瀚博半导体
主要产品:载天VA1:通用AI推理加速卡、SV100系列:性能优异的云端推理芯片
核心技术:高效率深度学习AI推理加速:INT8 峰值算力超 200 TOPS,同能耗下2-10倍于GPU的AI吞吐率,超低延时,适合实时应用。深度学习推理性能指标数倍于现有主流数据中心GPU,超高吞吐量、超低延迟;
应用场景:机器视觉、视频处理、图像处理、深度学习AI推理加速,检测,分类,识别,分割,视频处理,LSTM/RNN,NLP/BERT,推荐等。针对各种深度学习推理负载而优化的通用架构,支持计算机视觉、视频处理、自然语言处理和搜索推荐等推理应用场景
市场竞争力:强大的视频处理性能:支持高密度H.264, H.265或AVS2 1080p解码,分辨率支持高达8K。
良好的通用性和可扩展性:支持FP16, BF16和INT8等数据类型的众多主流神经网络快速部署。集成高密度视频解码,广泛适用于云端与边缘解决方案,单芯片INT8峰值算力超 200 TOPS,节省设备投资、降低运营成本。
发展里程碑:瀚博半导体获评第一届毕马威中国“芯科技”新锐企业50榜单、瀚博半导体入选2021年全球EE Times Silicon 100榜单。2021年4月完成A+轮5亿元人民币融资、2021年12月完成16亿人民币B-1和B-2连续融资。
寒武纪
主要产品:智能加速卡-MLU370-S4智能加速卡、智能边缘计算模组-MLU220-SOM、MLU220-M.2边缘端人工智能加速卡
核心技术:TSMC 7nm制程,寒武纪新一代人工智能芯片架构MLUarch03加持,采用全新的MLUv02架构,基于信用卡大小的模组上可以实现16TOPS AI算力的单系统解决方案,功耗仅为15W。
应用场景:智慧金融、智慧能源、智能制造、智慧电力,智能制造,智慧轨交,智慧能源等边缘计算场景。支持视觉、语音、自然语言处理以及传统机器学习等高度多样化的人工智能应用,实现各种业务的边缘端智能化解决方案。
市场竞争力:相较于同尺寸GPU,可提供3倍的解码能力和1.5倍的编码能力。MLU370-S4加速卡的能效出色,体积小巧,可在服务器中实现高密度部署。高集成:边缘端智能SOC模组、低延时:智能业务本地实现、应用广:支持多类人工智能应用。
发展里程碑:2018年9月寒武纪在高交会在主题参观路线中名列第一,2021年12月发布首颗 7nm 训练芯片思元 290 及玄思1000加速器。
黑芝麻智能
主要产品:黑芝麻智能华山°二号A1000 Pro超高性能车规级自动驾驶计算芯片
核心技术:A1000 Pro 支持INT8稀疏加速,INT8 算力为106TOPSINT4 的算力高达国内领先的196TOPS。芯片采用异构多核架构,16核Arm v8 CPU , 16nm工艺制程, 25w典型功耗; 支持多达20路高清摄像头输入, 支持ASIL-B级别
应用场景:为L3/L4级别自动驾驶提供多场景解决方案、大算力架构支持L3/L4高级别自动驾驶功能,实现从停车场泊车, 城市内部,到高速道路等多场景的完美无缝衔接。
市场竞争力:支持高阶自动驾驶功能、20路高清摄像头输入、典型功耗25W功耗、支持高阶自动驾驶功能,泊车、城市、高速等、多场景无缝衔接
发展里程碑:2022年8月黑芝麻智能完成c轮和c+轮全部融资,募资总规模超5亿美元,投后估值20亿美元。目前,黑芝麻智能华山二号A1000芯片已获得了15个不同车型的定点项目。
后摩智能
主要产品:第二代芯片–基于RRAM等先进存储工艺的大算力、高能效比的智能计算芯片、鸿途H30
核心技术:基于先进的RRAM等存储工艺,继续扩充模型容量,进一步降低功耗,增加算力,最终可实现单芯片算力1000TOPS,鸿途H30是首款存算一体智驾芯片,最高物理算力 256TOPS,典型功耗 35W,成为国内率先落地存算一体大算力AI 芯片的公司。
应用场景:面向泛机器人/无人车等边缘场景解决方案
市场竞争力:开放芯片、工具链,形成完整的参考样例,开放易用,可实现一站式部署和快速应用。鸿途H30 基于 SRAM 存储介质,采用数字存算一体架构,拥有极低的访存功耗和超高的计算密度,在 Int8 数据精度条件下,其 AI 核心IPU 能效比高达 15Tops/W,是传统架构芯片的7 倍以上。目前,其已成功运行常用的经典 CV 网络和多种自动驾驶先进网络。
发展里程碑:完成数千万美元天使轮融资,红杉资本中国基金领投、完成3亿元Pre-A轮融资,启明创投领投
宣布完成数亿人民币Pre-A+轮融资,经纬创投、金浦悦达汽车基金联合领投。
墨芯人工智能
主要产品:双稀疏化芯片Antoum计算卡S4、S10和S30
核心技术:软硬件协同设计、高倍率稀疏张量核、可扩展性、高性能多媒体处理能力
应用场景:支持计算机视觉、自然语言处理、多模态等众多数据中心AI推理应用,适用于互联网、运营商、智慧城市、生命科学、自动驾驶等大规模推理场景
市场竞争力:超高算力:通过优化计算模式,支持全面稀疏化神经网络,Antoum芯片提供超高算力。超低功耗:墨芯Antoum芯片将同等运算量的耗电量降至1/10,以大大降低能耗成本。高能效比:对多种常用的AI模型通用性优异,相比当前主流产品有10倍以上的能耗比提升潜力。高性能视频处理:专用硬件转码引擎,可以解码多路全高清视频流,轻松地将可扩展的深度学习集成到视频处理中,以提供创新的智能视频服务。
发展里程碑:墨芯荣获2022中国“芯科技”新锐企业50。
清微智能
主要产品:TX系列芯片
核心技术:云端可重构大算力芯片、清微智能TX8系列高性能云端训推一体芯片是基于原创可重构计算架构,实现的高性能计算芯片
应用场景:面向NLP、视频处理、自动驾驶、大型数据中心、智算中心等场景需求提供高效能的大算力芯片方案
市场竞争力:超低功耗视觉处理芯片,基于可重构神经网络引警RNE,实现高性能计算。芯片支持AlexNet、GoogleNet、ResNet、VGG、Faster-RCNN、YoloSSD、FCN和SegNet等主流神经网络,内置3D引擎
发展里程碑:2015年,国家技术发明二等奖国家发明专利金奖;2018年,清微智能在北京成立并获天使轮融资。
燧原科技
主要产品:云燧T20人工智能训练加速卡、云燧i20第二代人工智能推理加速卡、云燧T21人工智能训练加速模组。
核心技术:领先的TF32等浮点AI算力基于HBM2E的高吞吐低延时动态性特征支持、高性能高能效、模型覆盖面广、易部署易运维等特点、领先的FP32、FP16、INT8等AI算力、多类型计算范式支持、动态性特征支持。基于OAM开放标准,支持机柜级高算力密度方案、提供液冷散热方案,支持高能效的绿色智算集群建设、独立的高带宽通道,加速卡间通信、基于OAI开放标准,支持多类型互联拓扑、支持超大规模智算集群。
应用场景:数据中心,人工智能智算集群、独家的机内4卡全互联方案、增强的单机8卡互联方案。广泛应用于计算机视觉、语音识别与合成、自然语言处理、搜索与推荐等推理场景。面向数据中心,可广泛应用于互联网、金融、教育、医疗、工业以及政务等行业。
市场竞争力:燧原智能互联(GCU-LARE)是专为训练加速集群研发的互联技术,具有组网简洁、扩展性好、成本优化等优点。GCU-LARE互联技术可提升单机多卡和多机多卡系统的可扩展性,灵活实现从单机多卡到多机多卡乃至高达千卡级别不同规模的高性价比互联方案,以满足不同客户对深度学习训练集群的需求。虚拟化支持,多租户、多任务多实例、细粒度,提升资源利用率,自适应管理,能效最大化,多级监控,安全运行,AS、ECC加持,系统高可用,抗老化技术,长久运行性能稳定。OCP(开放计算项目)OAM(开放加速模组)标准设计、兼容OCP OAI标准(开放加速器基础设施)的高性能人工智能训练加速模组,多层次API接口开放完整工具链,支持高效开发与模型调试,编程模型开放,支持第三方深度定制。
发展里程碑:Pre-A轮融资3.4亿腾讯领投、A轮融资3亿红点领投、B轮融资7亿武岳峰领投、C轮融资18亿中信产业基金中金资本旗下基金春华资本领投、C+轮融资国家集成电路产业投资基金投资。
天数智芯
主要产品:天垓BI-V100
核心技术:天垓100的软硬件架构针对通用计算和人工智能而设计,与行业主流GPU产品软硬件架构可类比,采用2.5D COWOS封装技术,丰富的自研指令集全方位支持标量、矢量、张量运算,提供业界领先的高算力和高能效比。
应用场景:支持业界前沿算法,目前已有200多个通用计算及人工智能应用落地,数量持续增加,从容面对未来的算法变迁,为人工智能及通用计算和相关垂直应用行业提供匹配行业高速发展的计算力。
市场竞争力:天垓100支持国内外标准化的软硬件生态,兼容国内外主流框架及官方算子、常用网络模型和加速库,兼容主流GPU通用计算模型,应用迁移成本低、耗时短、无需重新开发。
发展里程碑:2029年09月完成B轮融资。2021年03月完成C轮融资。2022年"天垓100"系列产品累计订单接近2亿人民币。
芯驰科技
主要产品:X9-舱之芯、G9-网之芯、V9-驾之芯、E3-控之芯
核心技术:全场景车规芯片产品和解决方案覆盖智能座舱、智能驾驶、中央网关和高性能MCU,涵盖未来汽车电子电气架构最核心的芯片类别。舱之芯X9:智能座舱全交互,支持舱驾融合;驾之芯V9:基于全开放UniDrive平台,高效支撑各级别智能驾驶;控之芯E3:高性能、高安全车规MCU,核心领域应用全覆盖;
应用场景:仪表、中控、电子后视镜、娱乐、DMS、360环视+APA、语音系统等座舱功能全覆盖;支持舱泊一体、舱驾一体等应用;基于UniDrive平台,高效支撑各级别智驾;面向SOA的中央网关:整车OTA、信息安全、车身控制等;跨域融合网关,包括中央网关+液晶仪表、中央网关+空调面板等;支持5G/C-V2X场景应用;高可靠MCU应用于汽车电池管理系统(BMS)、智驾(ADAS/AD)、区域控制器网关(Zonal)和底盘类(Chassis)应用;显示MCU应用于液晶仪表(Cluster)、抬头显示控制器(HUD)、电子后视镜(eMirror);车身MCU应用于T-Box、车身控制器(BCM)、热管理(HVAC)、照明(Lighting)等领域。
市场竞争力:芯驰拥有近20年车规级量产经验的国际水平团队,是国内为数不多的具有车规核心芯片产品定义、技术研发及大规模量产落地的整建制团队。芯驰的核心IP完全自主设计,覆盖车规处理器关键核心技术,在全球范围拥有近200项自主知识产权。目前,芯驰的车规芯片已实现大规模量产,服务客户超过260家,拥有近200个定点项目,覆盖了中国90%以上车厂和部分国际主流车企。
发展里程碑:2018年08月华登国际领投天使轮1亿人民币;2019年04月经纬中国领投Pre-A轮数亿元人民币;2020年09月完成A轮融资;2021年07月普罗资本旗下国开装备基金与云晖资本联合领投B轮近10亿元融资;2022年11月完成B+轮近10亿元融资,由上汽金石创新产业基金战略领投,中信证券投资、江苏金石交通科技产业基金、安徽交控金石投资、国中资本、华泰保险、前海赛睿等机构参与,上海科创、张江高科、云晖资本、合创资本等老股东持续跟投。
芯擎科技
主要产品:智能座舱多媒体芯片SE1000
核心技术:7纳米工艺制程设计的新一代高性能、低功耗车规级智能座舱芯片,高性能定制CPU集群,通过面向异构计算而精心设计的SOC系统。
应用场景:车载信息娱乐系统
市场竞争力:内置高性能嵌入式AI神经网络处理单元,提供更多个性化的智能语音、机器视觉及辅助自动驾驶体验。新一代多核心的图形处理单元,可以动态根据负载进行资源分配;一机多屏多系统,支持多高分辨率屏幕同时输出;内置高性能音频信号处理单元及丰富的音频接口,为用户提供丰富超凡的音视频娱乐体验。具备高安全等级的“安全岛”设计,满足ISO26262车规认证,确保汽车功能安全;专业的硬件加/解密引擎为车载应用提供了安全性保证
发展里程碑:2022年四季度顺利完成近5亿元A+轮融资、2022年3月,芯擎科技获得一汽集团战略投资;7月,芯擎科技完成近十亿元A轮融资,由红杉中国领投。
亿智电子
主要产品:边缘侧/端侧AI SoC芯片SV系列、SA系列、SH系列。
核心技术:具备数字和模拟IP的自主研发实力,自研包括NPU、ISP、Video Codec、显示及图形处理、高速数模混合接口等IP。基于自研NPU及配套工具链,亿智AI SoC芯片支持丰富的AI算法落地,如人形检测、人脸识别与抓拍、双目活体检测、车辆检测与识别、车牌识别、周界防御、宠物识别、哭声检测、跌倒检测、双向语音等等。
应用场景:适用于4K超高清智能IPC、双目相机、视频猫眼、智能门锁、人脸考勤门禁等多种智能终端设备、多重类目进行精准检测、识别和监控、前车启动、行人预警、盲区检测等行车记录仪类产品、物体分类识别、文字识别、人脸检测识别、骨骼分析、手势识别等智能视觉应用场景。
市场竞争力:面向视觉AI场景,亿智完成对分辨率2M~8M,算力0.5 TOPS~2 TOPS规格全覆盖,产品布局不断完善。在智慧安防领域,亿智芯片拥有专业安防ISP图像质量;支持4K编码;支持快速启动和出图,实现低功耗应用。在智能车载领域,亿智芯片有效感知车辆、车道线以及周边行车场景,为汽车电子市场赋能高级别智能车载硬件。兼具通用算力、低功耗、高能效比等多种优势,亿智AI芯片已广泛应用于智能家电、智能办公、智慧教育等AIoT领域。
发展里程碑:2019年量产自研AI SoC,2019年4月亿智宣布完成由英特尔投资领投的Pre-A轮融资2019年5月,亿智电子宣布获中建投资本领投A轮融资。2022年九月亿智电子完成数亿元B轮融资。
知存科技
主要产品:WTM系列SoC芯片、WTM8000存算一体AI处理芯片
核心技术:智能语音芯片,WTM1001运行功耗为300μA,算力是市场上同类芯片的20倍,可直接存储和运行神经网络,运算过程无数据搬运,效率提高近50倍。可实现基于AI的各种视频增强处理,视频增强等算法、超清视频。为AI-ISP提供4K@60FPS的高能效NPU及高清视频增强能力。
应用场景:智能穿戴、语音识别、智能家居、物体识别、分类检测,以及视频增强等场景、各种高能效复杂边缘计算场景。
市场竞争力:基于存算一体技术,实现NN VAD和上百条语音命令词识别、超低功耗实现NN环境降噪算法、健康监测与分析算法、典型应用场景下,工作功耗均在微瓦级别、采用极小封装尺寸
发展里程碑:2018年6月-获得科大讯飞领投的500万融资、2018年1月-获得启迪之星领投的千万融资。2019年7月-获得中芯国际、浙江普华、招商局、三峡鑫泰等近亿元投资。2020年8月-完成近亿元A+轮融资。2021年2月-完成近亿元A3轮融资。2023年1月-完成2亿元B2轮融资。