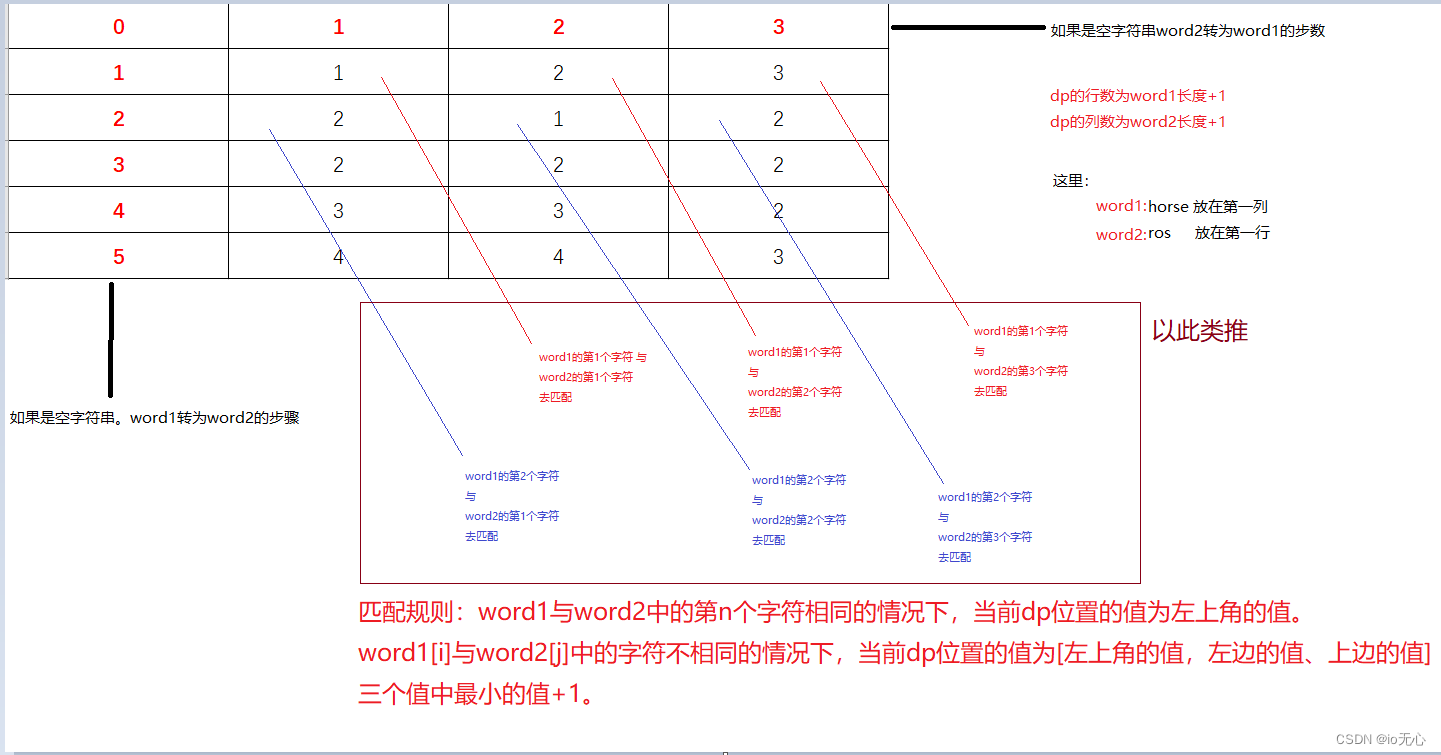
Buffer Pool
Innodb 存储引擎设计了一个缓冲池,来提升读写的性能。
在 MySQL 启动的时候,InnoDB 会为 Buffer Pool 申请一片连续的内存空间,然后按照默认的16KB的大小划分出一个个的页, Buffer Pool 中的页就叫做缓存页。此时这些缓存页都是空闲的,之后随着程序的运行,才会有磁盘上的页被缓存到 Buffer Pool 中。
当我们查询一条记录时,InnoDB 是会把这条记录的整个数据页的数据加载到 Buffer Pool 中,因为,通过索引只能定位到磁盘中的页,而不能定位到页中的一条记录。将页加载到 Buffer Pool 后,再通过页里的页目录二分查找去定位到某条具体的记录。
Free 链表:
● 管理空闲缓存页的
● 每次从磁盘中加载一个页到 Buffer Pool 中,就从 free 链表中取一个空闲缓存页,并且把该缓存页对应控制块上的信息填好,然后把该缓存页的控制块从 free 链表上移除
Flush 链表:
● 管理脏页的
● 设计 Buffer Pool 除了能提高读性能,还能提高写性能,也就是更新数据的时候,不需要每次都要写入磁盘,而是修改 Buffer Pool 中对应的缓存页,将缓存页标记为脏页,然后再由后台线程将脏页写入到磁盘。下次有查询语句命中了这条记录,直接读取缓存页中的记录就行了,这个记录就是最新的。
改良版的 Lru 链表:
为什么要使用改良版的 lru 链表呢?因为普通的 lru 链表,存在两个问题
● 预读失效
● Buffer Pool 污染,也就是 Buffer Pool 中的热数据被淘汰了
预读失效:
因为程序是具有空间局限性的,靠近当前被访问的数据,未来也大概率会被访问。
所以,MySQL 在加载数据页时,会提前把它相邻的数据页一并加载进来,目的是为了减少磁盘 IO。
但是可能这些被提前加载进来的数据页,并没有被访问,相当于这个预读是白做了,这个就是预读失效。
如果使用简单的 LRU 链表,就会把预读页放到 LRU 链表头部,而当 Buffer Pool空间不够的时候,还需要把末尾的页淘汰掉。
如果这些预读页如果一直不会被访问到,就会出现一个很奇怪的问题,不会被访问的预读页却占用了 LRU 链表前排的位置,而末尾淘汰的页,可能是频繁访问的页,这样就大大降低了缓存命中率。
所以MySQL改进了普通的 lru 链表,讲链表划分为两个区域,一个是yong区域,一个是old区域。
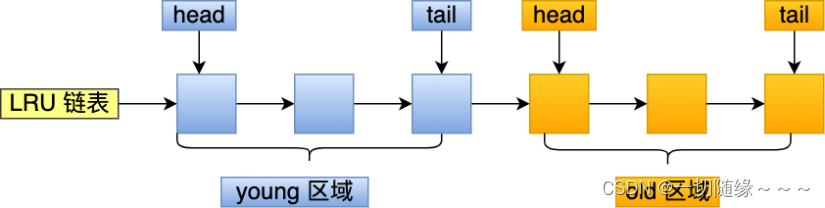
划分这两个区域后,预读的页就只需要加入到 old 区域的头部,当页被真正访问的时候,才将页插入 young 区域的头部。如果预读的页一直没有被访问,就会从 old 区域移除,这样就不会影响 young 区域中的热点数据。
Buffer Pool 污染:
如果使用简单的 LRU 链表,进行全表扫描的时候,就可能将 Buffer Pool 中的大部分页给替换出去,导致大量热点数据被淘汰了,等下次访问这些热点数据的时候,由于缓存未命中,就会导致大量的磁盘IO,导致MySQL性能会急剧下降。
像前面这种全表扫描的查询,很多缓冲页其实只会被访问一次,但是它却只因为被访问了一次而进入到 young 区域,从而导致热点数据被替换了。
LRU 链表中 young 区域就是热点数据,只要我们提高进入到 young 区域的门槛,就能有效地保证 young 区域里的热点数据不会被替换掉。
MySQL 是这样做的,进入到 young 区域条件增加了一个停留在 old 区域的时间判断。
在对某个处在 old 区域的缓存页进行第一次访问时,就在它对应的控制块中记录下来这个访问时间:
● 如果后续的访问时间与第一次访问的时间在某个时间间隔内,那么该缓存页就不会被从 old 区域移动到 young 区域的头部;
● 如果后续的访问时间与第一次访问的时间不在某个时间间隔内,那么该缓存页移动到 young 区域的头部;
这个间隔时间是由 innodb_old_blocks_time 控制的,默认是 1000 ms。
第二次访问的时间 - 第一次访问的时间 > 1 s
也就说,只有同时满足「被访问」与「在 old 区域停留时间超过 1 秒」两个条件,才会被插入到 young 区域头部,这样就解决了 Buffer Pool 污染的问题 。