- 服务概述
财务系统出现业务卡顿,数据库实例2遇到>>> WAITED TOO LONG FOR A ROW CACHE ENQUEUE LOCK! <<<错误导致业务HANG住。
对此HANG的原因进行分析:
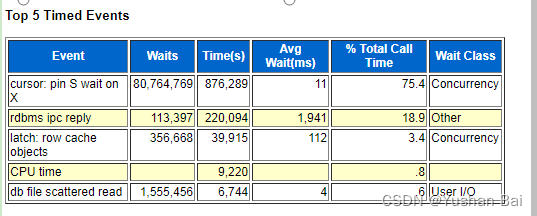
故障发生时,未有主机监控数据,从可以获取的数据库AWR中,可以发现在故障发生前一小时,已经出现有较多cursor: pin S wait on X Latch: row cache objects等待;而从AWR报告中也可以看到问题时段的shared pool 从4800M收缩为了2900M,查看SGA组件变动使用情况,可以发现将近2个GB是被KGH: NO ACCESS所使用,即处于shrik/grow的中间状态。
此时ALERT日志中开始出现有>>> WAITED TOO LONG FOR A ROW CACHE ENQUEUE LOCK! <<<错误,查看此时的System State dumped TRACE文件,核心进程在等待latch: row cache objects资源,根据故障时ALERT日志中systemstate dump prod2_ora_3191.trc信息来看,以典型的LCK0进程为例,此进程在等待和kghfrunp(释放shared pool中内存)有关的latch,此进程的历史等待事件中也大量存在'latch: shared pool'、latch: row cache objects;kghfrunp(kghfrunp相关的功能是需要从shared pool中释放空间相关)有关的latch。综合考虑,从现在得到的信息来看,很可能发生问题时shared pool的使用出现了问题。
- RAC数据库实例HANG分析
4.1 数据库实例日志的分析
4.1.1故障节点数据库实例Alert日志
节点1数据库实例的Alert日志
Fri May 31 12:11:03 2019
Incremental checkpoint up to RBA [0x16b38.55e5.0], current log tail at RBA [0x16b38.7949.0]
Fri May 31 12:31:15 2019
Incremental checkpoint up to RBA [0x16b38.d76f.0], current log tail at RBA [0x16b38.d7a1.0]
Fri May 31 12:38:24 2019
GES: Potential blocker (pid=4099) on resource CI-0000001E-00000002;
enqueue info in file /oracle/product/10.2.0/db/rdbms/log/prod2_lmd0_3768.trc and DIAG trace file
Fri May 31 12:49:04 2019
Beginning log switch checkpoint up to RBA [0x16b39.2.10], SCN: 6163266145639
Thread 2 advanced to log sequence 92985
Current log# 8 seq# 92985 mem# 0: +CWDATA/prod/onlinelog/group_8.525.896335299
Current log# 8 seq# 92985 mem# 1: +CWDATA/prod/onlinelog/group_8.628.896335301
Fri May 31 12:49:09 2019
LNS: Standby redo logfile selected for thread 2 sequence 92985 for destination LOG_ARCHIVE_DEST_2
Fri May 31 12:49:09 2019
Completed checkpoint up to RBA [0x16b39.2.10], SCN: 6163266145639
Fri May 31 12:51:21 2019
Incremental checkpoint up to RBA [0x16b39.19.0], current log tail at RBA [0x16b39.19.0]
Fri May 31 12:54:11 2019
GES: Potential blocker (pid=4099) on resource CI-00000046-00000002;
enqueue info in file /oracle/product/10.2.0/db/rdbms/log/prod2_lmd0_3768.trc and DIAG trace file
Fri May 31 13:02:58 2019
GES: Potential blocker (pid=3991) on resource DR-00000000-00000000;
enqueue info in file /oracle/product/10.2.0/db/rdbms/log/prod2_lmd0_3768.trc and DIAG trace file
Fri May 31 13:11:23 2019
Incremental checkpoint up to RBA [0x16b39.e1.0], current log tail at RBA [0x16b39.e1.0]
Fri May 31 13:14:13 2019
GES: Potential blocker (pid=4099) on resource CI-0000001E-00000002;
enqueue info in file /oracle/product/10.2.0/db/rdbms/log/prod2_lmd0_3768.trc and DIAG trace file
Fri May 31 13:25:34 2019
>>> WAITED TOO LONG FOR A ROW CACHE ENQUEUE LOCK! pid=287
System State dumped to trace file /oracle/product/10.2.0/db/rdbms/log/prod2_ora_3191.trc
Fri May 31 13:31:25 2019
Incremental checkpoint up to RBA [0x16b39.1ad.0], current log tail at RBA [0x16b39.1ad.0]
Fri May 31 13:33:01 2019
WARNING: inbound connection timed out (ORA-3136)
Fri May 31 13:33:01 2019
WARNING: inbound connection timed out (ORA-3136)
Fri May 31 13:33:01 2019
WARNING: inbound connection timed out (ORA-3136)对故障时间段的alert日志进行分析,可以发现当时节点1的ALERT日志中出现大量如下告警信息:
>>> WAITED TOO LONG FOR A ROW CACHE ENQUEUE LOCK! pid=***
4.2 对dump信息的分析
节点2的ALERT日志中提到了大量System State dumped文件,对此类TRACE文件进行了分析。如下:
使用发生问题后产生的systemstate dump prod2_ora_3191.trc。
[oracle@bys1 ~]$ awk -f ass109.awk prod2_ora_3191.trc
Starting Systemstate 1
.............................................
Ass.Awk Version 1.0.9 - Processing prod2_ora_3191.trc
System State 1
~~~~~~~~~~~~~~~~
1:
2: waiting for 'pmon timer' wait
3: waiting for 'DIAG idle wait' wait
4: waiting for 'rdbms ipc message' wait
5: waiting for 'rdbms ipc message' wait
6: waiting for 'ges remote message' wait
7: waiting for 'gcs remote message' wait
8: waiting for 'gcs remote message' wait
9: waiting for 'gcs remote message' wait
10: waiting for 'gcs remote message' wait
11: waiting for 'gcs remote message' wait
12: waiting for 'gcs remote message' wait
13: waiting for 'gcs remote message' wait
14: waiting for 'gcs remote message' wait
15: waiting for 'gcs remote message' wait
16: waiting for 'gcs remote message' wait
17: waiting for 'gcs remote message' wait
18: waiting for 'gcs remote message' wait
19: waiting for 'gcs remote message' wait
20: waiting for 'gcs remote message' wait
21: waiting for 'gcs remote message' wait
22: waiting for 'gcs remote message' wait
23: waiting for 'gcs remote message' wait
24: waiting for 'gcs remote message' wait
25: waiting for 'gcs remote message' wait
26: waiting for 'gcs remote message' wait
27: waiting for 'rdbms ipc message' wait
28: waiting for 'rdbms ipc message' wait
29: waiting for 'rdbms ipc message' wait
30: waiting for 'rdbms ipc message' wait
31: waiting for 'rdbms ipc message' wait
32: waiting for 'rdbms ipc message' wait
33: waiting for 'rdbms ipc message' wait
34: waiting for 'rdbms ipc message' wait
35: waiting for 'rdbms ipc message' wait
36: waiting for 'rdbms ipc message' wait
37: waiting for 'rdbms ipc message' wait
38: waiting for 'rdbms ipc message' wait
39: waiting for 'rdbms ipc message' wait
40: waiting for 'latch: row cache objects'[Latch 33a5d5bd0] wait
41: waiting for 'cursor: pin S wait on X' wait
42: waiting for 'latch: shared pool' [Latch 33ba89b70] wait
43: waiting for 'rdbms ipc reply' wait
44: waiting for 'rdbms ipc message' wait
45: waiting for 'latch: row cache objects'[Latch 33a5d5bd0] wait
Blockers
~~~~~~~~
Above is a list of all the processes. If they are waiting for a resource
then it will be given in square brackets. Below is a summary of the
waited upon resources, together with the holder of that resource.
Notes:
~~~~~
o A process id of '???' implies that the holder was not found in the
systemstate.
Resource Holder State
Latch 33a5d5bd0 ??? Blocker
Latch 33ba89b70 ??? Blocker
Object Names
~~~~~~~~~~~~
Latch 33a5d5bd0 Child row cache objects
Latch 33ba89b70 Child library cache
167446 Lines Processed.latch: row cache objects等待具体信息
LCK0进程在等待和kghfrunp(释放shared pool中内存)有关的latch,此进程的历史等待事件中也大量存在'latch: shared pool'、latch: row cache objects
PROCESS 45:
----------------------------------------
SO: 0x357240660, type: 2, owner: (nil), flag: INIT/-/-/0x00
(process) Oracle pid=45, calls cur/top: 0x33472fae8/0x33472fae8, flag: (6) SYSTEM
int error: 0, call error: 0, sess error: 0, txn error 0
(post info) last post received: 0 0 24
last post received-location: ksasnd
last process to post me: 35224fdd8 39 0
last post sent: 0 0 87
last post sent-location: kjmdrmchk: drm_hb ack
last process posted by me: 355269da8 1 6
(latch info) wait_event=0 bits=0
Location from where call was made: kqrbip:
waiting for 33a5d5bd0 Child row cache objects level=4 child#=16
Location from where latch is held: kghfrunp: clatch: wait: ====>>> 可以看到这个latch是因为kghfrunp(KGH: Ask client to free unpinned space)相关的功能发起的,而这个功能是需要从shared pool中释放空间有关
Context saved from call: 0
state=busy, wlstate=free
waiters [orapid (seconds since: put on list, posted, alive check)]:
50 (1, 1559280342, 1)
45 (1, 1559280342, 1)
waiter count=2
gotten 540727585 times wait, failed first 2224239 sleeps 386931
gotten 3781484 times nowait, failed: 419225
possible holder pid = 223 ospid=30412
on wait list for 33a5d5bd0
Process Group: DEFAULT, pseudo proc: 0x3552a2308
O/S info: user: oracle, term: UNKNOWN, ospid: 4099
OSD pid info: Unix process pid: 4099, image: oracle@findbb (LCK0)
Short stack dump: ksdxfstk()+32<-ksdxcb()+1547<-sspuser()+111<-<0x311720eb10>此进程的历史等待事件:
----------------------------------------
SO: 0x3553c5998, type: 4, owner: 0x357240660, flag: INIT/-/-/0x00
(session) sid: 1537 trans: (nil), creator: 0x357240660, flag: (51) USR/- BSY/-/-/-/-/-
DID: 0000-002D-00000003, short-term DID: 0000-0000-00000000
txn branch: (nil)
oct: 0, prv: 0, sql: (nil), psql: (nil), user: 0/SYS
waiting for 'latch: row cache objects' blocking sess=0x(nil) seq=30395 wait_time=0 seconds since wait started=0
address=33a5d5bd0, number=c7, tries=2
Dumping Session Wait History
for 'latch: row cache objects' count=1 wait_time=41
address=33a5d5bd0, number=c7, tries=1
for 'latch: row cache objects' count=1 wait_time=422982
address=33a5d5bd0, number=c7, tries=0
for 'latch: shared pool' count=1 wait_time=28
address=600ebf80, number=d5, tries=0
for 'latch: shared pool' count=1 wait_time=57
address=600ebf80, number=d5, tries=0
for 'latch: row cache objects' count=1 wait_time=135277
address=33a5d5bd0, number=c7, tries=0
for 'latch: shared pool' count=1 wait_time=29
address=600ebf80, number=d5, tries=1
for 'latch: shared pool' count=1 wait_time=37
address=600ebf80, number=d5, tries=0
for 'latch: shared pool' count=1 wait_time=78
address=600ebf80, number=d5, tries=0
for 'latch: row cache objects' count=1 wait_time=47585
address=33a5d5bd0, number=c7, tries=0
for 'latch: row cache objects' count=1 wait_time=45842
address=33a5d5bd0, number=c7, tries=0
temporary object counter: 0
----------------------------------------
UOL used : 0 locks(used=0, free=0)
KGX Atomic Operation Log 0x35afaaab8
Mutex (nil)(0, 0) idn 7fff00000000 oper NONE
Cursor Pin uid 1537 efd 3 whr 11 slp 0
KGX Atomic Operation Log 0x35afaab00
Mutex (nil)(0, 0) idn 7fff00000000 oper NONE
Library Cache uid 1537 efd 0 whr 0 slp 0
KGX Atomic Operation Log 0x35afaab48
Mutex (nil)(0, 0) idn 7fff00000000 oper NONE
Library Cache uid 1537 efd 0 whr 0 slp 0
----------------------------------------
SO: 0x33c58c458, type: 41, owner: 0x3553c5998, flag:4.3 数据库AWR信息分析
数据库实例在11点时已经HANG住,未生成AWR快照。因此使用9-10点的快照来查看故障发生前是否存在异常。
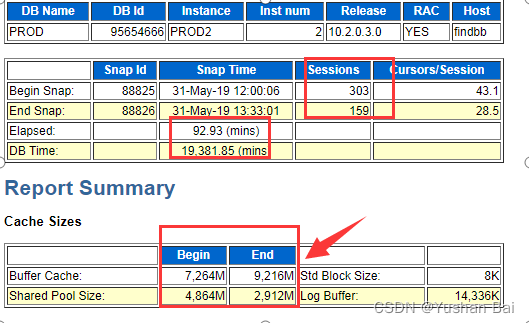
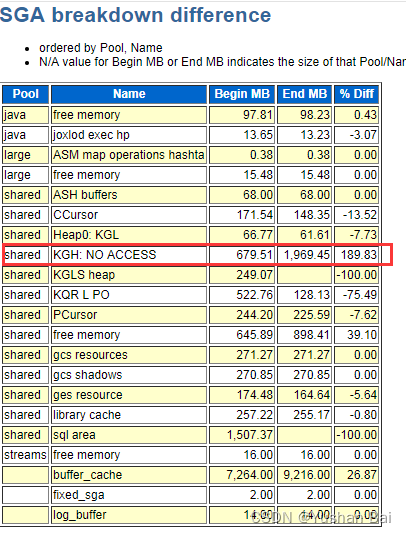
从AWR可以看到shared pool 从4800M收缩为了2900M,查看SGA组件变动使用情况,可以发现将近2个GB是被KGH: NO ACCESS所使用,即处于shrik/grow的中间状态。
- 总结与建议
针对此次RAC数据库实例问题,总结及建议如下:
5.1 问题描述与分析
此套RAC上运行的数据库实例,数据库版本为10.2.0.3.0;
其中数据库实例2遇到>>> WAITED TOO LONG FOR A ROW CACHE ENQUEUE LOCK! <<<错误导致业务HANG住。
对此HANG的原因进行分析:
故障发生时,未有主机监控数据,从可以获取的数据库AWR中,可以发现在故障发生前一小时,已经出现有较多cursor: pin S wait on X Latch: row cache objects等待;而从AWR报告中也可以看到问题时段的shared pool 从4800M收缩为了2900M,查看SGA组件变动使用情况,可以发现将近2个GB是被KGH: NO ACCESS所使用,即处于shrik/grow的中间状态。
此时ALERT日志中开始出现有>>> WAITED TOO LONG FOR A ROW CACHE ENQUEUE LOCK! <<<错误,查看此时的System State dumped TRACE文件,核心进程在等待latch: row cache objects资源,根据故障时ALERT日志中systemstate dump prod2_ora_3191.trc信息来看,以典型的LCK0进程为例,此进程在等待和kghfrunp(释放shared pool中内存)有关的latch,此进程的历史等待事件中也大量存在'latch: shared pool'、latch: row cache objects;kghfrunp(kghfrunp相关的功能是需要从shared pool中释放空间相关)有关的latch。综合考虑,从现在得到的信息来看,很可能发生问题时shared pool的使用出现了问题。
5.2 后续处理方法与建议
1. 数据库SGA内存参数的优化
当前节点1主机内存大小为32GB,节点2由于更换过硬件设备,内存为128GB。
因此之前出于两节点参数统一未对节点2的内存参数进行增加,使用的是sga_target= 12884901888,即12GB。
建议将两节点内存统计设置为SGA设置为节点1内存的一半大小,即16GB。(注意此操作需要重启数据库需要安排停机维护时间窗口进行)
2.数据库buffer cache及shared pool组件优化
建议设置最小的buffer cache及shared pool的值
这是用来设置下限值,使SGA自动管理时不会调整到低于此值。具体值应结合历史AWR报告中Report Summary部分的Cache Sizes大小及Advisory Statistics 部分建议的 Buffer Pool Advisory/Shared Pool Advisory值。使用的命令如下:(注意在非业务高峰时或安排停机维护时间窗口进行)
SQL> ALTER SYSTEM SET DB_CACHE_SIZE=n SCOPE=SPFILE;
SQL> ALTER SYSTEM SET SHARED_POOL_SIZE=m SCOPE=SPFILE;
建议可以设置为BUFFER CACHE 10GB,SHARED POOL 5GB。
3.关闭DRM相关参数
10G
_gc_affinity_time=0
_gc_undo_affinity=FALSE
这2个参数是静态参数,也就是说必须要重启实例才能生效。
实际上可以设置另外2个动态的隐含参数,来达到这个目的。按下面的值设置这2个参数之后,不能完全算是禁止/关闭了DRM,而是从”事实上“关闭了DRM。
--可以设置更高的值。
_gc_affinity_limit=250
_gc_affinity_minimum=10485760
alter system set "_gc_affinity_limit"=250;
alter system set "_gc_affinity_minimum"=10485760;
甚至可以将以上2个参数值设置得更大。这2个参数是立即生效的,在所有的节点上设置这2个参数之后,系统不再进行DRM。
4.建议继续加强对于RAC集群、数据库运行情况、主机资源使用的监控。再次出现类似异常时可以手动收集HANG和Systemstate dump信息来辅助分析,以协助排查。