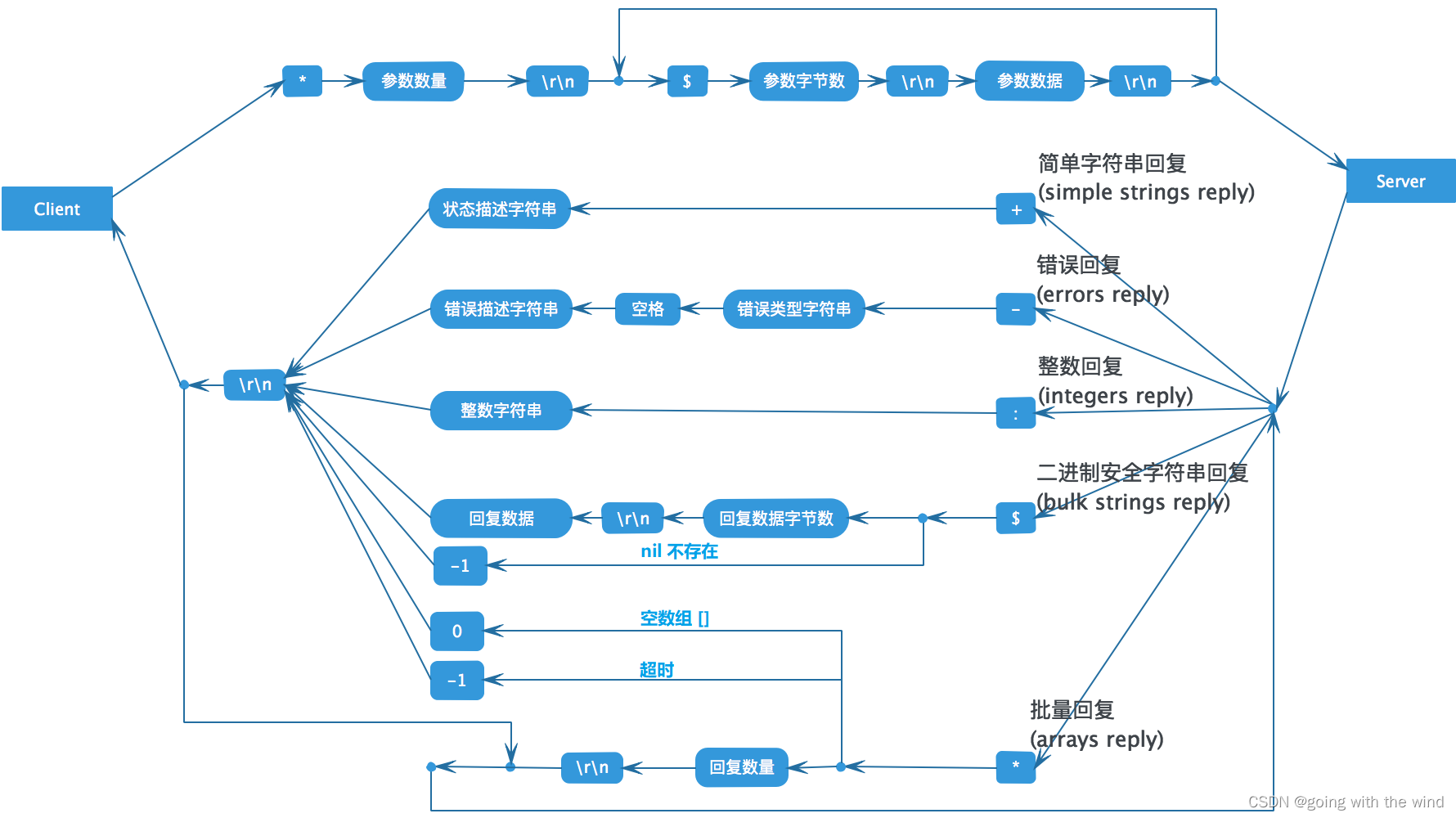
本篇开始总结二叉树的常用解题技巧,二叉树的顺序遍历和层序遍历刚好对应深度优先搜索和广度优先搜索。
1 顺序遍历
题目列表
144. 前序遍历
145. 二叉树的后序遍历
94. 二叉树的中序遍历
144. 二叉树的前序遍历
给你二叉树的根节点 root ,返回它节点值的 前序 遍历。

示例 1:
输入:root = [1,null,2,3]
输出:[1,2,3]示例 2:
输入:root = []
输出:[]
1. 递归实现
递归算法三要素:确定递归函数的参数和返回值、确定终止条件、确定单层递归的逻辑
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def preorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
# 递归法
if not root: return []
result = []
def traversal(root):
if not root: return
result.append(root.val) # 先将根节点值加入结果
if root.left: traversal(root.left) # 左
if root.right: traversal(root.right) # 右
traversal(root)
return result
2. 迭代实现
前序遍历是中左右,每次先处理的是中间节点,那么先将根节点放入栈中,然后将右孩子加入栈,再加入左孩子。
为什么要先加入 右孩子,再加入左孩子呢? 因为这样出栈的时候才是中左右的顺序。
class Solution:
def preorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
# 迭代法
if not root: return []
stack = [root]
res = []
while stack:
node = stack.pop()
res.append(node.val)
if node.right: stack.append(node.right)
if node.left: stack.append(node.left)
return res

94. 二叉树的中序遍历
给你二叉树的根节点 root ,返回它节点值的 中序 遍历。
示例 1:
输入:root = [1,null,2,3]
输出:[1,3,2]示例 2:
输入:root = []
输出:[]
1. 递归实现
class Solution:
def inorderTraversal(self, root: TreeNode) -> List[int]:
result = []
def traversal(root: TreeNode):
if root == None:
return
traversal(root.left) # 左
result.append(root.val) # 中序
traversal(root.right) # 右
traversal(root)
return result
2. 迭代实现
中序遍历是左中右,先访问的是二叉树顶部的节点,然后一层一层向下访问,直到到达树左面的最底部,再开始处理节点(也就是在把节点的数值放进result数组中),这就造成了处理顺序和访问顺序是不一致的。
那么在使用迭代法写中序遍历,就需要借用指针的遍历来帮助访问节点,栈则用来处理节点上的元素。
class Solution:
def inorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
if not root: return [] # 空树
stack = [] # 不能提前将root结点加入stack中'
res = []
cur = root
while cur or stack:
if cur: # 先迭代访问最底层左子树结点
stack.append(cur)
cur = cur.left
else: # 到达最左节点后处理栈顶结点
cur = stack.pop()
res.append(cur.val)
cur = cur.right # 取栈顶元素右结点
return res

145. 二叉树的后序遍历
给你二叉树的根节点 root ,返回它节点值的 后序 遍历。
示例 1:
输入:root = [1,null,2,3]
输出:[3,2,1]示例 2:
输入:root = []
输出:[]
1. 递归实现
class Solution:
def postorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
# 递归遍历
if not root: return []
result = []
def traversal(root: Optional[TreeNode])-> List[int]:
if not root: return
self.traversal(root.left) # 左
self.traversal(root.right) # 右
self.result.append(root.val) # 中
traversal(root)
return result
2. 迭代实现
后序遍历,先序遍历是中左右,后续遍历是左右中,那么我们只需要调整一下先序遍历的代码顺序,就变成中右左的遍历顺序,然后在反转result数组,输出的结果顺序就是左右中了,如下图:

class Solution:
def postorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
# 迭代遍历
if not root: return []
stack = [root]
result = []
while stack:
node = stack.pop()
result.append(node.val)
if node.left: stack.append(node.left)
if node.right: stack.append(node.right)
return result[::-1]
3 层序遍历
102. 二叉树的层序遍历
107. 二叉树的层次遍历II
199. 二叉树的右视图
637.二叉树的层平均值
429. N叉树的层序遍历/a>
515. 在每个树行中找最大值
116. 填充每个节点的下一个右侧节点指针
117.填充每个节点的下一个右侧节点指针II
104. 二叉树的最大深度
111. 二叉树的最小深度
102. 二叉树的层序遍历
给你二叉树的根节点 root ,返回其节点值的层序遍历。(即逐层地,从左到右访问所有节点)。

输入:root = [3,9,20,null,null,15,7]
输出:[[3],[9,20],[15,7]]
层序遍历一个二叉树。就是从左到右一层一层的去遍历二叉树。这种遍历的方式和我们之前讲过的都不太一样。
需要借用一个辅助数据结构即队列来实现,队列先进先出,符合一层一层遍历的逻辑,而用栈先进后出适合模拟深度优先遍历也就是递归的逻辑。
而这种层序遍历方式就是图论中的广度优先遍历,只不过我们应用在二叉树上。
使用队列实现二叉树广度优先遍历,动画如下:

方法一:广度优先搜索
class Solution:
def levelOrder(self, root: Optional[TreeNode]) -> List[List[int]]:
# 二叉树层序遍历迭代解法
if not root: return []
results = []
que = deque([root])
while que:
size = len(que)
result = []
for _ in range(size): # 这里一定要使用固定大小size,不要使用len(que),因为len(que)是不断变化的
cur = que.popleft()
result.append(cur.val)
if cur.left:
que.append(cur.left)
if cur.right:
que.append(cur.right)
results.append(result)
return results
方法二:深度优先搜索
用广度优先处理是很直观的,可以想象成是一把刀横着切割了每一层,但是深度优先遍历就不那么直观了。

我们开下脑洞,把这个二叉树的样子调整一下,摆成一个田字形的样子。田字形的每一层就对应一个 list。

按照深度优先的处理顺序,会先访问节点 1,再访问节点 2,接着是节点 3。 之后是第二列的 4 和 5,最后是第三列的 6。
每次递归的时候都需要带一个 index(表示当前的层数),也就对应那个田字格子中的第几行,如果当前行对应的 list 不存在,就加入一个空 list 进去。
动态演示如下:

class Solution:
def levelOrder(self, root: Optional[TreeNode]) -> List[List[int]]:
# DFS
def dfs(root, level):
if not root: return
# 假设 res 是 [[1], [2,3]], level 是 3,就再插入一个 [root.val] 放到 res 中
if len(res) < level:
res.append([root.val])
else:
# 将当前节点的值加入到res中,level 代表当前层,假设 level 是 3,节点值是 99
# res 是 [[1], [2,3], [4]],加入后 res 就变为 [[1], [2,3], [4,99]]
res[level-1].append(root.val)
# 递归的处理左子树,右子树,同时将层数 level+1
dfs(root.left, level+1)
dfs(root.right, level+1)
res = []
dfs(root, 1)
return res
107. 二叉树的层次遍历II
给你二叉树的根节点 root ,返回其节点值自底向上的层序遍历。 (即按从叶子节点所在层到根节点所在的层,逐层从左向右遍历)

输入:root = [3,9,20,null,null,15,7]
输出:[[15,7],[9,20],[3]]
方法一:广度优先搜索
from collections import deque
class Solution:
def levelOrderBottom(self, root: Optional[TreeNode]) -> List[List[int]]:
if not root: return []
results = []
que = deque([root])
while que:
size = len(que)
result = []
for _ in range(size):
node = que.popleft()
result.append(node.val)
if node.left: que.append(node.left)
if node.right: que.append(node.right)
results.append(result)
results.reverse()
return results
方法二:深度优先搜索
class Solution:
def levelOrderBottom(self, root: Optional[TreeNode]) -> List[List[int]]:
# DFS
def dfs(root, level):
if not root: return
if len(res) < level:
res.append([root.val])
else:
res[level-1].append(root.val)
dfs(root.left, level+1)
dfs(root.right, level+1)
res = []
dfs(root, 1)
return res[::-1]
199. 二叉树的右视图
给定一个二叉树的 根节点 root,想象自己站在它的右侧,按照从顶部到底部的顺序,返回从右侧所能看到的节点值。

输入: [1,2,3,null,5,null,4]
输出: [1,3,4]
from collections import deque
class Solution:
def rightSideView(self, root: Optional[TreeNode]) -> List[int]:
if not root: return []
res = []
# deque 相比list的好处是,list的 pop(0) 是 O(n) 复杂度,deque 的 popleft() 是 O(1) 复杂度
que = deque([root])
while que:
res.append(que[-1].val) # 每次都取最后一个node就可以
size = len(que)
for _ in range(size): # 执行这个遍历的目的是获取下一层所有的node
node = que.popleft()
if node.left: que.append(node.left)
if node.right: que.append(node.right)
return res
637. 二叉树的层平均值
给定一个非空二叉树的根节点 root , 以数组的形式返回每一层节点的平均值。与实际答案相差 10-5 以内的答案可以被接受。

输入:root = [3,9,20,null,null,15,7]
输出:[3.00000,14.50000,11.00000]
解释:第 0 层的平均值为 3,第 1 层的平均值为 14.5,第 2 层的平均值为 11 。因此返回 [3, 14.5, 11] 。
方法一:广度优先搜索
从根节点开始搜索,每一轮遍历同一层的全部节点,计算该层的节点数以及该层的节点值之和,然后计算该层的平均值。
如何确保每一轮遍历的是同一层的全部节点呢?我们可以借鉴层次遍历的做法,广度优先搜索使用队列存储待访问节点,只要确保在每一轮遍历时,队列中的节点是同一层的全部节点即可。具体做法如下:
- 初始时,将根节点加入队列;
- 每一轮遍历时,将队列中的节点全部取出,计算这些节点的数量以及它们的节点值之和,并计算这些节点的平均值,然后将这些节点的全部非空子节点加入队列,重复上述操作直到队列为空,遍历结束。
由于初始时队列中只有根节点,满足队列中的节点是同一层的全部节点,每一轮遍历时都会将队列中的当前层节点全部取出,并将下一层的全部节点加入队列,因此可以确保每一轮遍历的是同一层的全部节点。
具体实现方面,可以在每一轮遍历之前获得队列中的节点数量 size \textit{size} size,遍历时只遍历 size \textit{size} size 个节点,即可满足每一轮遍历的是同一层的全部节点。
from collections import deque
class Solution:
def averageOfLevels(self, root: Optional[TreeNode]) -> List[float]:
result = []
que = deque([root])
while que:
size = len(que)
total = 0
for _ in range(size):
cur = que.popleft()
total += cur.val
if cur.left: que.append(cur.left)
if cur.right: que.append(cur.right)
result.append(total/size)
return result
方法二:深度优先搜索
使用深度优先搜索计算二叉树的层平均值,需要维护两个数组, counts \textit{counts} counts 用于存储二叉树的每一层的节点数, sums \textit{sums} sums 用于存储二叉树的每一层的节点值之和。搜索过程中需要记录当前节点所在层,如果访问到的节点在第 i i i 层,则将 counts [ i ] \textit{counts}[i] counts[i] 的值加 1,并将该节点的值加到 sums [ i ] \textit{sums}[i] sums[i]。
遍历结束之后,第 i i i 层的平均值即为 sums [ i ] / counts [ i ] \textit{sums}[i] / \textit{counts}[i] sums[i]/counts[i]。
class Solution:
def averageOfLevels(self, root: Optional[TreeNode]) -> List[float]:
# DFS
def dfs(root: Optional[TreeNode], level: int) -> List[float]:
if not root: return
if len(total) < level:
total.append(root.val)
count.append(1)
else:
total[level-1] += root.val
count[level-1] += 1
dfs(root.left, level+1)
dfs(root.right, level+1)
count, total = [], []
dfs(root, 1)
return [t/c for t, c in zip(total, count)]
429. N叉树的层序遍历
给定一个 N 叉树,返回其节点值的层序遍历。(即从左到右,逐层遍历)。树的序列化输入是用层序遍历,每组子节点都由 null 值分隔(参见示例)。

输入:root = [1,null,3,2,4,null,5,6]
输出:[[1],[3,2,4],[5,6]]
方法一:广度优先搜索
class Solution:
def levelOrder(self, root: 'Node') -> List[List[int]]:
if not root: return []
results = []
que = deque([root])
while que:
size = len(que)
result = []
for _ in range(size):
node = que.popleft()
result.append(node.val)
# cur.children 是 Node 对象组成的列表,也可能为 None
if node.children:
que.extend(node.children)
results.append(result)
return results
方法二:深度优先搜索
class Solution:
def levelOrder(self, root: 'Node') -> List[List[int]]:
# DFS
def dfs(root, level):
if not root: return
if len(res) < level:
res.append([root.val])
else:
res[level-1].append(root.val)
for child in root.children:
dfs(child, level+1)
res = []
dfs(root, 1)
return res
515. 在每个树行中找最大值
给定一棵二叉树的根节点 root ,请找出该二叉树中每一层的最大值。

输入: root = [1,3,2,5,3,null,9]
输出: [1,3,9]
方法一:广度优先搜索
class Solution:
def largestValues(self, root: Optional[TreeNode]) -> List[int]:
# BFS
if not root: return []
que = deque([root])
res = []
while que:
size = len(que)
max_value = float('-inf')
for _ in range(size):
node = que.popleft()
max_value = max(max_value, node.val)
if node.left: que.append(node.left)
if node.right: que.append(node.right)
res.append(max_value)
return res
方法二:深度优先搜索
class Solution:
def largestValues(self, root: Optional[TreeNode]) -> List[int]:
# DFS
def dfs(root, level):
if not root: return
if len(res) < level:
res.append(root.val)
else:
res[level-1] = (max(root.val, res[level-1]))
dfs(root.left, level+1)
dfs(root.right, level+1)
res = []
dfs(root, 1)
return res
116. 填充每个节点的下一个右侧节点指针

方法一:层序遍历
from collections import deque
class Solution:
def connect(self, root: 'Optional[Node]') -> 'Optional[Node]':
if not root: return None # 这里空树,直接返回None
que = deque([root])
while que:
n = len(que)
for i in range(n):
cur = que.popleft()
if cur.left: que.append(cur.left)
if cur.right: que.append(cur.right)
if i == n-1: break # 遍历到最右边,结束本行循环
cur.next = que[0] # 指向同一行的右边节点
return root
117. 填充每个节点的下一个右侧节点指针 II

from collections import deque
class Solution:
def connect(self, root: 'Node') -> 'Node':
if not root: return root
que = deque([root])
while que:
size = len(que)
for i in range(size):
cur = que.popleft()
if cur.left: que.append(cur.left)
if cur.right: que.append(cur.right)
if i == size-1: break
cur.next = que[0]
return root
104. 二叉树的最大深度
给定一个二叉树,找出其最大深度。二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
- 说明: 叶子节点是指没有子节点的节点。
- 示例:给定二叉树
[3,9,20,null,null,15,7]
3
/ \
9 20
/ \
15 7
返回它的最大深度 3。
方法一:深度优先搜索
from collections import deque
class Solution:
def maxDepth(self, root: Optional[TreeNode]) -> int:
if not root: return 0
que = deque([root])
depth = 0
while que:
size = len(que)
depth += 1
for _ in range(size):
node = que.popleft()
if node.left: que.append(node.left)
if node.right: que.append(node.right)
return depth
方法二:广度优先搜索
class Solution:
def maxDepth(self, root: Optional[TreeNode]) -> int:
# DFS 自底向上
if not root: return 0
# 感受一下这里是将最底层的结果往上抛
# 因为这里的递归边界条件是叶子节点
left_height = self.maxDepth(root.left)
right_height = self.maxDepth(root.right)
return max(left_height, right_height) + 1
# DFS 自顶向下
res = 0
def dfs(root, depth):
nonlocal res
if not root: return
if not root.left and not root.right:
res = max(res, depth)
dfs(root.left, depth+1)
dfs(root.right, depth+1)
dfs(root, 1)
return res
- 自顶向下:直接return 函数调用自身下一级实现,比如
return Fibonacci(n-1) + Fibonacci(n-2); - 自底向上:先递归到最小单位(叶子节点),再从最小单位往上抛结果,传递结果

111. 二叉树的最小深度
给定一个二叉树,找出其最小深度。最小深度是从根节点到最近叶子节点的最短路径上的节点数量。
- 说明:叶子节点是指没有子节点的节点。
- 示例 1:

输入:root = [3,9,20,null,null,15,7]
输出:2
方法一:深度优先搜索
class Solution:
def minDepth(self, root: TreeNode) -> int:
if not root:
return 0
if not root.left and not root.right:
return 1
min_depth = 10**9
if root.left:
min_depth = min(self.minDepth(root.left), min_depth)
if root.right:
min_depth = min(self.minDepth(root.right), min_depth)
return min_depth + 1
方法二:广度优先搜索
class Solution:
def minDepth(self, root: TreeNode) -> int:
if not root:
return 0
que = collections.deque([(root, 1)])
while que:
node, depth = que.popleft()
if not node.left and not node.right:
return depth
if node.left:
que.append((node.left, depth + 1))
if node.right:
que.append((node.right, depth + 1))
return 0
二叉树遍历暂时告一段落,但还有很多自己不满意的地方,后面在学习中持续补充,谢谢大家的鼓励和支持!
 _____
_____