STP(Spanning-Tree Protocol)的来源
在网络三层架构中,我们会使用冗余这一技术,也就是对三层架构中的这些东西进行备份。冗余包含了设备冗余、网关冗余、线路冗余、电源冗余。
在二层交换网络中进行线路冗余,如图,将每个交换机都相连,这样无论断了哪一根线都可以从另一边继续通信。这样就实现了线路备份。


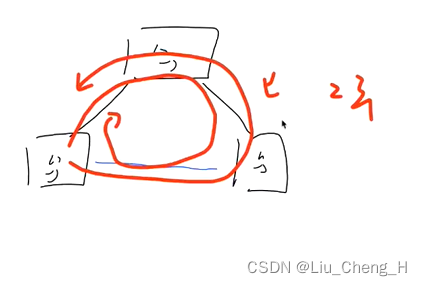
线路冗余(备份) --- 造成二层桥接环路 (二层交换机的转发列表mac地址表 也就是CAM表 --- 由流量经过时记录源mac地址产生)
在二层交换网络,也就是汇聚层和接入层的交换机,进行线路冗余的时候,由于交换机不像路由器能通过动态路由协议或者人工配置静态协议来有效避免出环,只能根据CAM地址表进行转发,我们对交换机之间进行线路冗余的时候,就会导致出环。比如LSW1交换机处连接PC,PC发送一个广播包,交给LSW1进行泛洪,LSW1会将PC发来的广播信息泛洪给其它两个交换机。LSW3收到该广播消息后会将该包继续进行泛洪给LSW2,这时候LSW2将会收到LSW1和LSW3发来的广播包,会将LSW1发来的广播包泛洪给LSW3,将LSW3发来的广播包泛洪给LSW1,造成环路,出现广播风暴。
环路则会导致这些问题:
- 广播风暴
- MAC地址表翻滚
- 同一数据帧的重复拷贝
最终导致设备性能下降重启或瘫痪
使用STP来解决二层交换网络出环这一问题。
生成树协议:将一个二层交换机网络看作一个树形结构,这个网络中所有的交换机都是树的节点,在这些节点中选择一个作为树的根,让这颗树从根开始到达顶部之间所有的节点到根都只有唯一的最佳路径,将其它路径的端口阻塞。当唯一的最佳路径断开时,自动打开部分阻塞端口达到备份的目的。
生成树在生成过程中,应该尽量的生成一棵星形结构,且最短路径树;

STP的发展
STP的发展指的是STP中使用的算法的发展
一、IEEE组织的802.1D算法:
整个交换网络为一棵树
选举出(1)根网桥、(2)根端口、(3)指定端口、(4)非指定端口(阻塞端口)来进行树结构的规划。
BPDU --- 桥协议数据单元 -- 交换机通过收发BPDU中的数据进行沟通。

配置BPDU --- 只有根网桥可以发送,在交换网络初始状态时,所有的交换机都定义本地为根网桥,都可以发送BPDU,当交换网络中的所有交换机都收到别人的BPDU 时,基于BPDU中BID的比对,选举出真正的根网桥,此时,只有真正的根网桥发送BPDU,其它的交换机都为非根网桥,不再发送BPDU,而是仅接收和转发根网桥的BPDU;周期2s发送,hold time保存时间为20s。
配置BPDU这个协议数据单元存在的主要目的就是确定二层交换网络中的根网桥保证树结构。
TCN—拓扑变更消息(也是BPDU): 本地交换机链路故障后,STP重新收敛,为了快速刷新全网所有交换机的MAC表,将向本地所有STP接口发送TCN(标记位中的TCN位置1),邻居交换机收到TCN后,先标记为ACK位为回复,用于可靠传输消息;之后将TCN逐级转发到根网桥处,由根网桥回复TC消息来逐级回复到所有交换机;使所有交换机临时将MAC表的老化时间修改为15s(默认的,转发延时)

发送TCN的原因是为了使所有交换机临时将MAC表的老化时间从300s修改为15s,为什么要这样做呢?比如上图场景,虚线的网线阻塞为备份线路,当右边交换机的根端口断开后,这时候STP重新收敛,30s收敛完后,阻塞端口开放,备份线路启动,当主机B发送一个数据包到主机A,从备份线路到达左边交换机G0/0/2接口时,MAC地址表会记录主机B的MAC地址和端口号G0/0/2,但是左边交换机中MAC地址表还未到300s刷新时间,之前记录的主机B的MAC地址和对应的端口G0/0/1还未删除,当主机A给主机B回包时,交换机就不知道应该给G0/0/1还是G00/0/2接口进行单播,所以需要将之前的记录删除,就会发送TCN来更改老化时间为30s使得之前的MAC地址表记录删除。
(1)根网桥 --- 一棵树中只有一台root根网桥
通过比较BPDU中的BID来进行选择
BID = 网桥优先级 + MAC地址
网桥优先级范围是 0-65535,交换机网桥优先级默认为32768
MAC地址 交换机只有拥有svi接口才具有MAC地址
选择根网桥方式 : 优先级小则优,若优先级相同则MAC地址小为优。
(2)根端口 --- 每台非根网桥上只有一个根端口,接收来自根网桥的BPDU,转发用户的流量
离根网桥最近的端口为根端口
1.比较从根网桥发出后,通过该接口进入时最小的cost值

2.入向cost值相同,比较该接口上级设备的BID,小优

3.上级BID相同,比较上级设备的接口的PID,先优先级小,若一致,则编号小优

4.对端PID相同,比较本地接口PID,小优;
中间设备为hub或者透明交换机(不带console口),不受STP控制,下面交换机通过STP只能看到上面交换机,相当于对端PID相同

PID = 端口ID = 接口优先级(0-240,步长16,默认128)+ 接口编号
(3)指定端口 --- 二层交换网络中的每一条物理链路都有且仅有一个指定端口,转出来自根网桥的BPDU,同时可以转发用户流量。
默认根网桥上所有接口都是指定端口,根端口的对端一定为指定端口
1.比较从根网桥发出时,通过该接口进入这段链路时的cost值最小(出向)
2.若出向cost值相同,比较本地的BID,小优

3.本地BID相同,比较本地PID
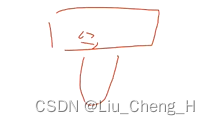
4.本地PID相同,直接阻塞该端口
中间设备为hub或者透明交换机(不带console口),不受STP控制,相当本地PID相同

这第四种情况是最常见的,当我们的交换机下面连接了透明交换机,如果在透明交换机上用一根线连接了透明交换机的两个接口,那么交换机就会发现本地PID相同出现环路,但是透明交换机不受STP控制,无法堵塞透明交换机的一个端口,那么上面的交换机将会直接阻塞连接透明交换机的端口,使得该端口下的网络都会停止。就像我们生活中的如果一个交换机连接了一个教室的透明交换机,大家上课的电脑都连接在透明交换机上,如果一个同学将一个网线插在了透明交换机的两个接口上,则所有人都上不了网了。还有一种情况是没有回插,一根网线连接了电脑,但是这根网线无意间被损坏,导致里面的八根铜丝相遇,四根从左往右,另外四根从右往左,就会造成环路。也会导致PID相同上不了网。

(4)非指定端口(阻塞端口) --- 以上角色选举完,其它接口都为非指定端口,逻辑上阻塞,实际上可以接收消息,但是不转发
cost值:不同带宽 存在不同cost
802.1d标准: 802.1T标准
10M = 100 1000M= 20000
100M=19 100M=200000
1000M=4
10000M=2
>100000M=1
判断下图中的根网桥,根端口,指定端口,非指定端口
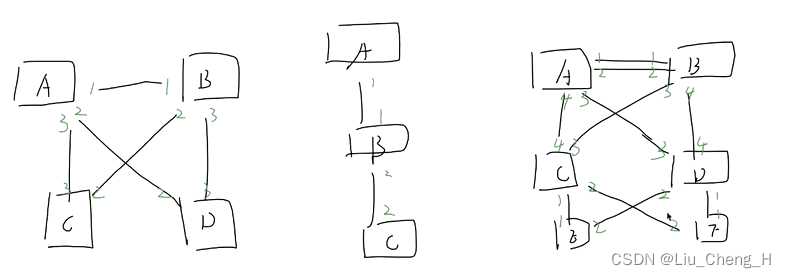
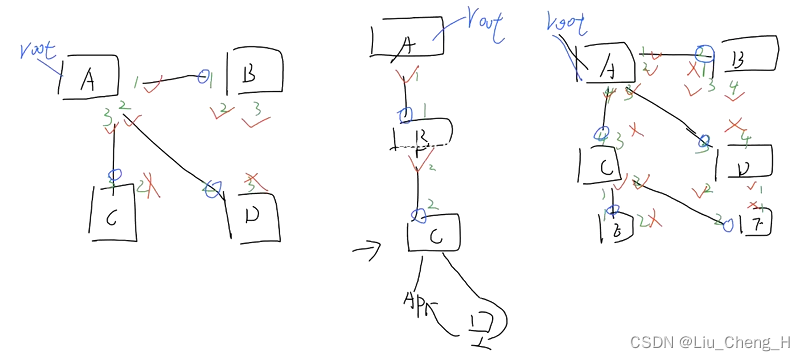
干涉生成树角色的选举
生成协议中,至少应该将根网桥干涉到汇聚层处;
以下图为例
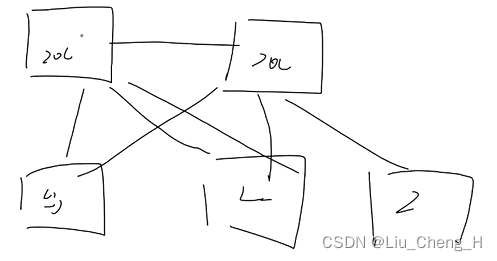
如果接入层交换机成为了根网桥,那么经过STP之后,就会变成下图的效果

如果接入层的两个交换机下的电脑想要访问对方,则需要走很远的路

谁成为了根网桥,谁就是网络的中心,所有的流量都为到此进行聚合,汇聚层三层交换机就是用来做流量聚合的,搭建为一个星型结构,现在用接入层交换机去做根网桥,选路变远,性能没有三层交换机好。所以生成树角色选举需要干涉。
生成树端口除了有角色外,还有状态
接口状态:
down --- 没有BPDU收发,开始BPDU收发进入侦听状态
侦听 --- 强制15s时间,所有交换机进行BPDU收发选举根网桥、根、指定端口进入学习状态、非指定端口进入阻塞状态
学习 --- 强制15s时间,学习记录所有经过的流量中的源mac地址生成mac地址表,根、指定端口进入转发状态。
转发 --- 根、指定端口,可以转发用户报文
阻塞 --- 非指定端口逻辑阻塞
注:只有当接口进入到转发状态后,才能为用户转发数据报文,之前的30s不转发任何数据
收敛时间:
初次收敛 --- 30s = 15s侦听 + 15s学习
结构变化收敛 (STP课程52分钟处)
存在直连检测:本地仅存在一个阻塞端口,若其他端口断开,该阻塞端口马上进入15s侦听选举,结果若为启用,那么将再进入15s学习 --- 总共30s
没有直连检测:本地不存在直连检测,若其它端口断开,将会发送次优BPDU(以本地为根)给其它邻居交换机,其它邻居交换机无视该数据,邻居交换机开始进行20shold time及时,到时阻塞进入15s侦听,15s学习 一共50s
802.1D缺点:
收敛速度慢
链路资源率低
cisco公司也想用这个802.1D这个算法,它提出802.1D这个算法的缺点,链路利用率太低,所以自己设计了一个PVST算法来解决这一缺点。但它只能cisco私有。
- 二、PVST --- 基于vlan的生成树协议 cisco私有
- 一个vlan为一棵树,如果有两个vlan就有两棵树,可以将不同vlan的根网桥放置于不同汇聚层设备上,来实现所有链路均工作,且互为备份的效果。
- 例如下图这种情况,二层交换网络之前存在vlan1和vlan2,也就是有两棵树,但是对于这两个vlan而言,它们在选举四个角色的时候,选举的结果都是一样的。都是按照802.1D的算法进行角色选举,交换机a的BID最小(三个交换机网桥优先级相同,但是a的MAC地址最小),所以无论在哪个vlan里面a都是根网桥,最终堵塞的都是同一个端口。仍然造成链路资源浪费,所以就通过修改vlan1vlan2交换机的优先级来使得vlan1的根网桥为左边交换机,vlan2的根网桥为右边交换机,最终堵塞端口就是一边一个,这样两个vlan走不同的线路,就解决了链路资源浪费这个缺点。
-
vlan1的BPDU优先级为32768+1=32769
- vlan2的BPDU优先级为32768+2=32770
- 优先级=4096倍数+vlanid 人为仅可修改4096倍数
- 不同vlan的BPDU区别在于优先级,默认优先级都是32768,但由于vlan不同,所以最终不同vlan的BPDU不同,每个vlan都会发送BPDU包,vlan1广播域里面三个交换机都发送32769的BPDU,最终MAC地址小的作为根网桥,vlan2广播域里面三个交换机都发送32770的BPDU,最终也以MAC地址小的作为根网桥,最终无论哪个vlan,根网桥都是MAC地址小的交换机。这样无论哪个vlan最终堵塞端口也是同一个端口。所以我们需要修改交换机的优先级使得不同vlan的根网桥不同,比如vlan1将左边交换机优先级-4096,vlan2将右边交换机优先级-4096*2,这样在vlan1里,左边交换机优先级低作为根网桥,vlan2里,右边交换机优先级低作为根网桥。
实验:
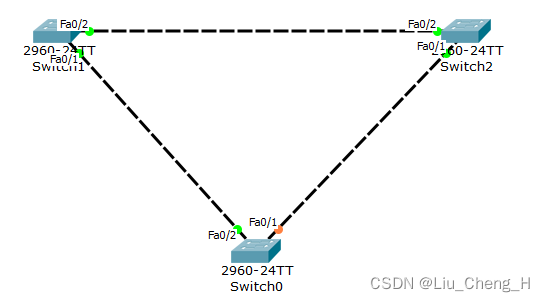
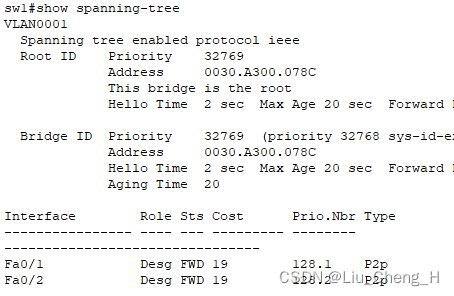
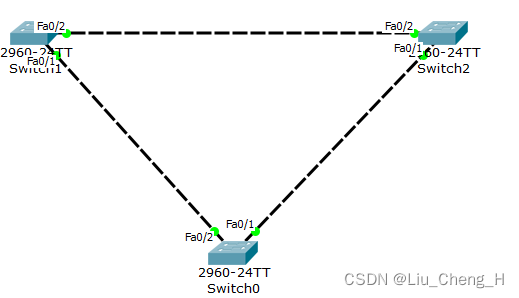
在这个二层交换网络中,现在只存在vlan1,所以也就只有一棵树
通过这个图线路接口的灯可以看出sw1为根网桥
也可以进入sw1交换机查看生成树

可以看出在vlan1这棵树中,sw1就是根网桥优先级为32769,mac地址为0030.A300.078C
两个接口都为指定接口
阻塞接口在sw0交换机上
这时候我们再创建一个vlan2
sw1#configure terminal
Enter configuration commands, one per line. End with CNTL/Z.
sw1(config)#vlan 2
sw1(config-vlan)#end
sw1#
%SYS-5-CONFIG_I: Configured from console by console
sw1#show spanning-tree 可以看到我们在sw1上创建了vlan2之后,仍然只有vlan1一棵生成树,是因为还未配置trunk干道,交换机的接口都不属于vlan2,所以只有vlan1一棵生成树
将接口改为trunk干道
sw1(config)#interface range fastEthernet 0/1 -2
sw1(config-if-range)#switchport mode trunk
为了让vlan2覆盖整个二层交换网络,每个交换机都需要配置vlan2和trunk干道,一条线只需要配一次trunk干道
将sw0也创建vlan2并配置trunk干道
sw0#configure terminal
Enter configuration commands, one per line. End with CNTL/Z.
sw0(config)#interface fastEthernet 0/1
sw0(config-if)#switchport mode trunk
sw0(config-if)#vlan 2 sw2只需要创建vlan2就可以了,它的两个接口已经成为了trunk干道
Switch#configure terminal
Enter configuration commands, one per line. End with CNTL/Z.
Switch(config)#hostname sw2
sw2(config)#vlan 2这时候,vlan2已经覆盖了二层交换网络
我们再次查看生成树发现sw1是vlan1和vlan2的根网桥,那么堵塞接口仍然未变不转发用户数据,还是造成了链路资源的浪费。
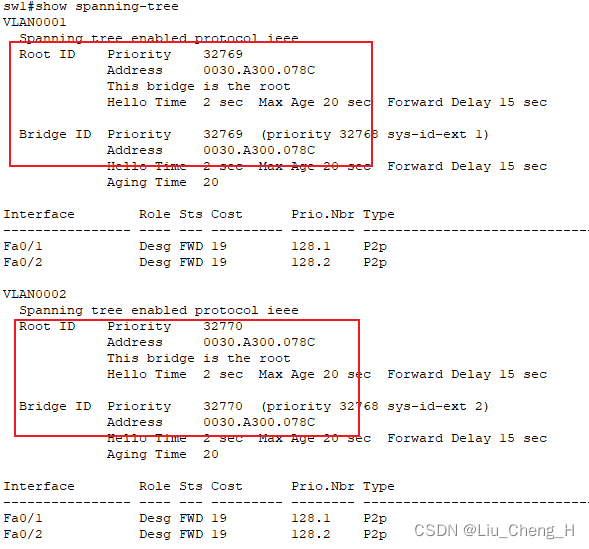
我们在vlan2的生成树里修改sw2的网桥优先级变小,让sw2成为vlan2的根网桥
sw2(config)#spanning-tree vlan 2 priority ?
<0-61440> bridge priority in increments of 4096
sw2(config)#spanning-tree vlan 2 priority 111
% Bridge Priority must be in increments of 4096.
% Allowed values are:
0 4096 8192 12288 16384 20480 24576 28672
32768 36864 40960 45056 49152 53248 57344 61440
sw2(config)#spanning-tree vlan 2 priority 28672
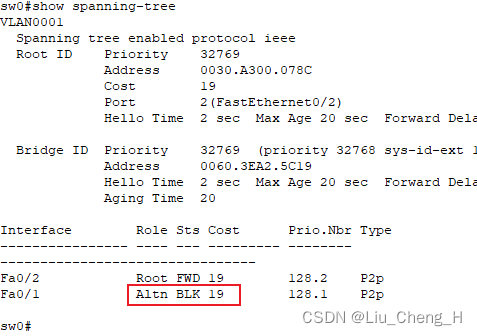
sw2(config)#查看sw2的生成树可以看出此时sw2成为vlan2生成树的根网桥,两个端口都是指定端口

查看sw0可以看出在vlan1的生成树中,fa0/1为阻塞端口,在vlan2生成树中,fa0/2为阻塞端口
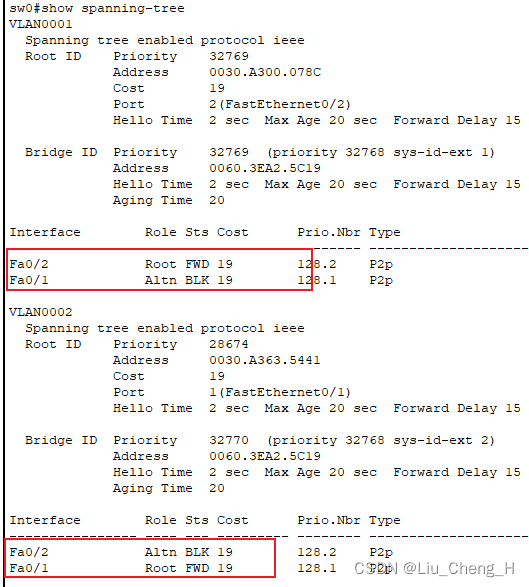
通过查看图中交换机接口都变为绿灯可以看出两条链路都在使用,一条是vlan1在使用,一条是vlan2在使用,所以解决了链路资源浪费的缺点。
三、PVST + 在PVST的基础,兼容802.1q的trunk封装;且设计了部分的加速;
端口加速(接入层连接用户的接口) 上行链路加速-针对直连检测 骨干加速—针对次优BPDU
端口加速,跳过三十秒

上行链路加速仅在接入层设备上配置,因为配置后,该交换机将自动加大本地的网桥优先级;
在直连检测条件下阻塞接口将跳过30s,直接进入转发状态--上行链路加速
骨干加速所有交换机均可配置,针对接收到次优BPDU的阻塞端口可以跳过20s的hold time;
缺点:1、收敛慢(加速不彻底) 2、树多(仅cisco存在单独的芯片,友商无法负荷)
PVST+ 优点:分流 --- 提高利用率 部分加速
缺点:树多,加速不彻底
对于cisco有独立的芯片,所以也不害怕树多
但是对于其它厂家就不太友好
四、快速生成树
cisco的RSTP --- 基于vlan的快速生成树 - 一个vlan一棵树 pvst+的升级
公有RSTP(802.1w) --- 整个交换网络一棵树 802.1d的升级
快速的原理:
- 取消了计时器,而是在一个状态工作完成后,直接进入下一状态;
- 分段式同步,两台设备间逐级收敛;使用请求和同意标记;依赖标记位的第1和第6位
- BPDU的保活为6s;hello time 2s;
- 将端口加速(边缘接口)、上行链路加速、骨干加速集成了
- 兼容802.1d和PVST,但802.1d和PVST没有使用标记位中的第1-6位,故不能快速收敛;因此如果网络中有一台设备不支持快速收敛,那么其他开启快速收敛的设备也不能快速;
当tcn消息出现时,不需要等待根网桥的BPDU,就可以刷新本地的cam表;
切记:接口默认为半双工时,即便允许RSTP,依然基于慢速的802.1D算法来收敛;
PVST+ --> RSTP 一个vlan一棵树
802.1D --> RSTP(802.1W) 一个交换网络一棵树
五、MSTP/MST/802.1S 华为设备默认使用该协议 最主流的目前
继承了快速生成树的基础; 将多个vlan放置于一个组内,基于每个组一棵生成树;
不同组间的BPDU中优先级= 4096倍数+组号
cisco查看生成树show spanning-tree
华为查看生成树 display stp brief

82.1D组织