数据在经过清洗过滤后,会通过Open/AddBatch请求分批量将数据发送给存储层的BE节点上。在一个BE上支持多个LoadJob任务同时并发写入执行。LoadChannelMgr负责管理这些任务,并对数据进行分发。
internal service
Open/AddBatch请求接口使用BRPC,定义在be/src/service/internal_service.h文件中。如下列出了tablet_writer接口的调用流程。tablet_writer_open函数会调用LoadChannelMgr类的open函数;tablet_writer_add_batch函数调用 _tablet_writer_add_batch函数,tablet_writer_add_block函数调用_tablet_writer_add_block函数;tablet_writer_cancel函数会调用LoadChannelMgr类的cancel函数。
class PInternalServiceImpl : public PBackendService {
public:
PInternalServiceImpl(ExecEnv* exec_env);
virtual ~PInternalServiceImpl();
void tablet_writer_open(google::protobuf::RpcController* controller, const PTabletWriterOpenRequest* request, PTabletWriterOpenResult* response, google::protobuf::Closure* done) override;
auto st = _exec_env->load_channel_mgr()->open(*request); st.to_protobuf(response->mutable_status());
void tablet_writer_add_batch(google::protobuf::RpcController* controller, const PTabletWriterAddBatchRequest* request, PTabletWriterAddBatchResult* response, google::protobuf::Closure* done) override;
google::protobuf::Closure* new_done = new NewHttpClosure<PTransmitDataParams>(done);
_tablet_writer_add_batch(cntl_base, request, response, new_done);
void tablet_writer_add_batch_by_http(google::protobuf::RpcController* controller, const ::doris::PEmptyRequest* request, PTabletWriterAddBatchResult* response, google::protobuf::Closure* done) override;
PTabletWriterAddBatchRequest* new_request = new PTabletWriterAddBatchRequest();
google::protobuf::Closure* new_done = new NewHttpClosure<PTabletWriterAddBatchRequest>(new_request, done);
brpc::Controller* cntl = static_cast<brpc::Controller*>(cntl_base);
Status st = attachment_extract_request_contain_tuple<PTabletWriterAddBatchRequest>(new_request, cntl);
_tablet_writer_add_batch(cntl_base, new_request, response, new_done);
void tablet_writer_add_block(google::protobuf::RpcController* controller, const PTabletWriterAddBlockRequest* request, PTabletWriterAddBlockResult* response, google::protobuf::Closure* done) override;
google::protobuf::Closure* new_done = new NewHttpClosure<PTransmitDataParams>(done);
brpc::Controller* cntl = static_cast<brpc::Controller*>(cntl_base);
attachment_transfer_request_block<PTabletWriterAddBlockRequest>(request, cntl);
_tablet_writer_add_block(cntl_base, request, response, new_done);
void tablet_writer_add_block_by_http(google::protobuf::RpcController* controller, const ::doris::PEmptyRequest* request, PTabletWriterAddBlockResult* response, google::protobuf::Closure* done) override;
PTabletWriterAddBlockRequest* new_request = new PTabletWriterAddBlockRequest();
google::protobuf::Closure* new_done = new NewHttpClosure<PTabletWriterAddBlockRequest>(new_request, done);
brpc::Controller* cntl = static_cast<brpc::Controller*>(cntl_base);
Status st = attachment_extract_request_contain_block<PTabletWriterAddBlockRequest>(new_request, cntl);
_tablet_writer_add_block(cntl_base, new_request, response, new_done);
void tablet_writer_cancel(google::protobuf::RpcController* controller, const PTabletWriterCancelRequest* request, PTabletWriterCancelResult* response, google::protobuf::Closure* done) override;
auto st = _exec_env->load_channel_mgr()->cancel(*request);
private:
void _tablet_writer_add_batch(google::protobuf::RpcController* controller, const PTabletWriterAddBatchRequest* request, PTabletWriterAddBatchResult* response, google::protobuf::Closure* done);
void _tablet_writer_add_block(google::protobuf::RpcController* controller, const PTabletWriterAddBlockRequest* request, PTabletWriterAddBlockResult* response, google::protobuf::Closure* done);
private:
ExecEnv* _exec_env;
PriorityThreadPool _tablet_worker_pool;
PriorityThreadPool _slave_replica_worker_pool;
}
LoadChannelMgr
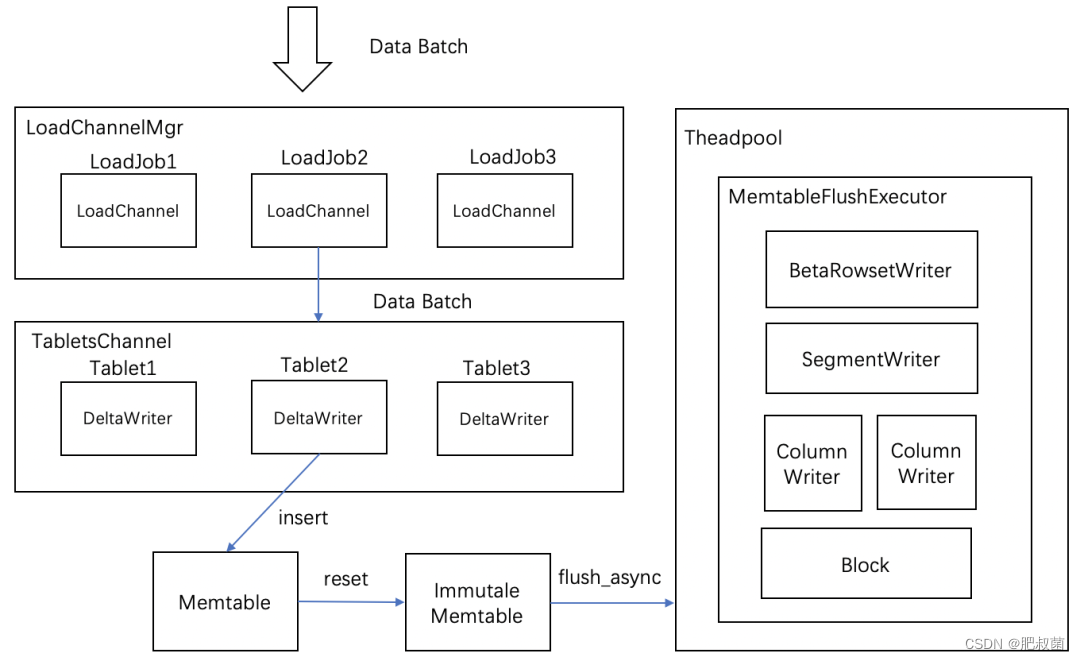
在一个BE上支持多个LoadJob任务同时并发写入执行。LoadChannelMgr负责管理这些任务,并对数据进行分发。每次导入任务LoadJob会建立一个LoadChannel来执行,LoadChannel维护了一次导入通道,LoadChannel可以将数据分批量写入操作直到导入完成。因此LoadChannelMgr需要维护一个loadjob和load channel映射关系(std::mutex _lock; // lock protect the load channel map 和 std::unordered_map<UniqueId, std::shared_ptr<LoadChannel>> _load_channels; // load id -> load channel)。LoadChannelMgr还需要为导入通道维护内存(_mem_usage统计所有导入通道内存消耗大小;导入内存软硬限制等),用于cache导入通道的LRU缓存(LastestSuccessChannelCache: Used to cache the LoadChannel of the import receiver,完成数据导入的通道后缓存于此),创建thread执行_start_load_channels_clean函数清理超时导入通道timeout load channels。
Status LoadChannelMgr::init(int64_t process_mem_limit) {
_load_hard_mem_limit = calc_process_max_load_memory(process_mem_limit);
_load_soft_mem_limit = _load_hard_mem_limit * config::load_process_soft_mem_limit_percent / 100;
_load_channel_min_mem_to_reduce = _load_hard_mem_limit * 0.1; // If a load channel's memory consumption is no more than 10% of the hard limit, it's not worth to reduce memory on it. Since we only reduce 1/3 memory for one load channel, for a channel consume 10% of hard limit, we can only release about 3% memory each time, it's not quite helpfull to reduce memory pressure. In this case we need to pick multiple load channels to reduce memory more effectively.
_mem_tracker = std::make_unique<MemTrackerLimiter>(MemTrackerLimiter::Type::LOAD, "LoadChannelMgr");
REGISTER_HOOK_METRIC(load_channel_mem_consumption, [this]() { return _mem_tracker->consumption(); });
_last_success_channel = new_lru_cache("LastestSuccessChannelCache", 1024);
RETURN_IF_ERROR(_start_bg_worker());
return Status::OK();
}
LoadChannelMgr主要负责导入通道维护和内存超限管理两大任务,包含在open时为请求创建导入通道;cancel时关闭通道;add_batch时使用LRU缓存cache和清理已完成的导入通道,内存超限时清理内存。后台thread执行_start_load_channels_clean函数清理超时导入通道timeout load channels
open函数为导入数据请求创建导入通道,首先提取loadid,查找或创建导入通道。
Status LoadChannelMgr::open(const PTabletWriterOpenRequest& params) {
UniqueId load_id(params.id()); std::shared_ptr<LoadChannel> channel; std::lock_guard<std::mutex> l(_lock);
auto it = _load_channels.find(load_id);
if (it != _load_channels.end()) { channel = it->second; // 查找到正使用中的loadid->loadchannel
} else { // create a new load channel
int64_t timeout_in_req_s = params.has_load_channel_timeout_s() ? params.load_channel_timeout_s() : -1;
int64_t channel_timeout_s = calc_channel_timeout_s(timeout_in_req_s);
bool is_high_priority = (params.has_is_high_priority() && params.is_high_priority());
// Use the same mem limit as LoadChannelMgr for a single load channel
auto channel_mem_tracker = std::make_unique<MemTracker>(fmt::format("LoadChannel#senderIp={}#loadID={}", params.sender_ip(), load_id.to_string()));
channel.reset(new LoadChannel(load_id, std::move(channel_mem_tracker), channel_timeout_s, is_high_priority, params.sender_ip(), params.is_vectorized())); // 创建导入通道
_load_channels.insert({load_id, channel});
}
}
RETURN_IF_ERROR(channel->open(params)); // 打开导入通道
return Status::OK();
}
add_batch函数是向导入通道里添加数据的入口,其也包含了使用LRU缓存cache和清理已完成的导入通道,内存超限时清理内存功能。_get_load_channel函数从loadjob和load channel映射和cache导入通道的LRU缓存查询导入通道,如果从cache导入通道的LRU缓存查到则需判定是否导入已经完成,否则继续该次导入数据;如果是低等级导入任务需要参与内存超限处理任务;向导入通道中加载数据;最终判定导入通道是否完成导入,完成需要从loadjob和load channel映射去除,加入cache导入通道的LRU缓存。
template <typename TabletWriterAddRequest, typename TabletWriterAddResult>
Status LoadChannelMgr::add_batch(const TabletWriterAddRequest& request, TabletWriterAddResult* response) {
UniqueId load_id(request.id());
// 1. get load channel
std::shared_ptr<LoadChannel> channel; bool is_eof;
auto status = _get_load_channel(channel, is_eof, load_id, request);
if (!status.ok() || is_eof) { return status; }
if (!channel->is_high_priority()) { // 2. check if mem consumption exceed limit If this is a high priority load task, do not handle this. because this may block for a while, which may lead to rpc timeout.
_handle_mem_exceed_limit();
}
// 3. add batch to load channel batch may not exist in request(eg: eos request without batch), this case will be handled in load channel's add batch method.
Status st = channel->add_batch(request, response);
if (UNLIKELY(!st.ok())) { channel->cancel(); return st; }
// 4. handle finish
if (channel->is_finished()) {
_finish_load_channel(load_id);
}
return Status::OK();
}
template <typename Request>
Status LoadChannelMgr::_get_load_channel(std::shared_ptr<LoadChannel>& channel, bool& is_eof, const UniqueId& load_id, const Request& request) {
is_eof = false; std::lock_guard<std::mutex> l(_lock);
auto it = _load_channels.find(load_id);
if (it == _load_channels.end()) {
auto handle = _last_success_channel->lookup(load_id.to_string()); // success only when eos be true
if (handle != nullptr) {
_last_success_channel->release(handle);
if (request.has_eos() && request.eos()) { is_eof = true; return Status::OK(); }
}
return Status::InternalError("fail to add batch in load channel. unknown load_id={}", load_id.to_string());
}
channel = it->second;
return Status::OK();
}
void LoadChannelMgr::_finish_load_channel(const UniqueId load_id) {
VLOG_NOTICE << "removing load channel " << load_id << " because it's finished";
{
std::lock_guard<std::mutex> l(_lock);
_load_channels.erase(load_id);
auto handle = _last_success_channel->insert(load_id.to_string(), nullptr, 1, dummy_deleter);
_last_success_channel->release(handle);
}
VLOG_CRITICAL << "removed load channel " << load_id;
}
其实add_batch函数都是由线程池中线程执行,因此需要_wait_flush_cond信号量保证同时只有一个线程在进行内存清理,其他线程必须等待该线程进行唤醒。
void LoadChannelMgr::_handle_mem_exceed_limit() {
// Check the soft limit.
int64_t process_mem_limit = MemInfo::soft_mem_limit();
if (_mem_tracker->consumption() < _load_soft_mem_limit && MemInfo::proc_mem_no_allocator_cache() < process_mem_limit) { return; }
// Indicate whether current thread is reducing mem on hard limit.
bool reducing_mem_on_hard_limit = false;
std::vector<std::shared_ptr<LoadChannel>> channels_to_reduce_mem;
{
std::unique_lock<std::mutex> l(_lock);
while (_should_wait_flush) { // _should_wait_flush被设置,因此该线程需要等待condition
LOG(INFO) << "Reached the load hard limit " << _load_hard_mem_limit << ", waiting for flush";
_wait_flush_cond.wait(l);
}
bool hard_limit_reached = _mem_tracker->consumption() >= _load_hard_mem_limit || MemInfo::proc_mem_no_allocator_cache() >= process_mem_limit;
// Some other thread is flushing data, and not reached hard limit now, we don't need to handle mem limit in current thread.
if (_soft_reduce_mem_in_progress && !hard_limit_reached) { return; }
// Pick LoadChannels to reduce memory usage, if some other thread is reducing memory due to soft limit, and we reached hard limit now, current thread may pick some duplicate channels and trigger duplicate reducing memory process. But the load channel's reduce memory process is thread safe, only 1 thread can reduce memory at the same time, other threads will wait on a condition variable, after the reduce-memory work finished, all threads will return. 正式清理内存
using ChannelMemPair = std::pair<std::shared_ptr<LoadChannel>, int64_t>;
std::vector<ChannelMemPair> candidate_channels;
int64_t total_consume = 0;
for (auto& kv : _load_channels) {
if (kv.second->is_high_priority()) { // do not select high priority channel to reduce memory to avoid blocking them.
continue;
}
int64_t mem = kv.second->mem_consumption();
candidate_channels.push_back(std::make_pair(kv.second, mem)); // save the mem consumption, since the calculation might be expensive.
total_consume += mem;
}
if (candidate_channels.empty()) { // should not happen, add log to observe
LOG(WARNING) << "All load channels are high priority, failed to find suitable" << "channels to reduce memory when total load mem limit exceed";
return;
}
// sort all load channels, try to find the largest one.
std::sort(candidate_channels.begin(), candidate_channels.end(), [](const ChannelMemPair& lhs, const ChannelMemPair& rhs) { return lhs.second > rhs.second; });
int64_t mem_consumption_in_picked_channel = 0;
auto largest_channel = *candidate_channels.begin();
// If some load-channel is big enough, we can reduce it only, try our best to avoid reducing small load channels.
if (_load_channel_min_mem_to_reduce > 0 && largest_channel.second > _load_channel_min_mem_to_reduce) { // Pick 1 load channel to reduce memory.
channels_to_reduce_mem.push_back(largest_channel.first);
mem_consumption_in_picked_channel = largest_channel.second;
} else { // Pick multiple channels to reduce memory.
int64_t mem_to_flushed = total_consume / 3;
for (auto ch : candidate_channels) {
channels_to_reduce_mem.push_back(ch.first);
mem_consumption_in_picked_channel += ch.second;
if (mem_consumption_in_picked_channel >= mem_to_flushed) { break; }
}
}
std::ostringstream oss;
if (MemInfo::proc_mem_no_allocator_cache() < process_mem_limit) {
oss << "reducing memory of " << channels_to_reduce_mem.size() << " load channels (total mem consumption: " << mem_consumption_in_picked_channel << " bytes), because total load mem consumption " << PrettyPrinter::print(_mem_tracker->consumption(), TUnit::BYTES) << " has exceeded";
if (_mem_tracker->consumption() > _load_hard_mem_limit) {
_should_wait_flush = true; reducing_mem_on_hard_limit = true;
oss << " hard limit: " << PrettyPrinter::print(_load_hard_mem_limit, TUnit::BYTES);
} else {
_soft_reduce_mem_in_progress = true;
oss << " soft limit: " << PrettyPrinter::print(_load_soft_mem_limit, TUnit::BYTES);
}
} else {
_should_wait_flush = true;
reducing_mem_on_hard_limit = true;
oss << "reducing memory of " << channels_to_reduce_mem.size() << " load channels (total mem consumption: " << mem_consumption_in_picked_channel << " bytes), because " << PerfCounters::get_vm_rss_str() << " has exceeded limit " << PrettyPrinter::print(process_mem_limit, TUnit::BYTES) << " , tc/jemalloc allocator cache " << MemInfo::allocator_cache_mem_str();
}
LOG(INFO) << oss.str();
}
for (auto ch : channels_to_reduce_mem) {
uint64_t begin = GetCurrentTimeMicros();
int64_t mem_usage = ch->mem_consumption();
ch->handle_mem_exceed_limit(); // 调用导入通道的内存清理函数
LOG(INFO) << "reduced memory of " << *ch << ", cost " << (GetCurrentTimeMicros() - begin) / 1000 << " ms, released memory: " << mem_usage - ch->mem_consumption() << " bytes";
}
{
std::lock_guard<std::mutex> l(_lock);
// If a thread have finished the memtable flush for soft limit, and now the hard limit is already reached, it should not update these variables.
if (reducing_mem_on_hard_limit && _should_wait_flush) {
_should_wait_flush = false; _wait_flush_cond.notify_all(); // 唤醒其他线程
}
if (_soft_reduce_mem_in_progress) {
_soft_reduce_mem_in_progress = false;
}
_refresh_mem_tracker_without_lock(); // refresh mem tacker to avoid duplicate reduce
}
return;
}
class LoadChannelMgr {
public:
LoadChannelMgr(); ~LoadChannelMgr();
Status init(int64_t process_mem_limit);
Status open(const PTabletWriterOpenRequest& request); // open a new load channel if not exist
template <typename TabletWriterAddRequest, typename TabletWriterAddResult>
Status add_batch(const TabletWriterAddRequest& request, TabletWriterAddResult* response);
Status cancel(const PTabletWriterCancelRequest& request); // cancel all tablet stream for 'load_id' load
void refresh_mem_tracker() {std::lock_guard<std::mutex> l(_lock); _refresh_mem_tracker_without_lock(); }
MemTrackerLimiter* mem_tracker() { return _mem_tracker.get(); }
private:
template <typename Request>
Status _get_load_channel(std::shared_ptr<LoadChannel>& channel, bool& is_eof, const UniqueId& load_id, const Request& request);
void _finish_load_channel(UniqueId load_id);
void _handle_mem_exceed_limit(); // check if the total load mem consumption exceeds limit. If yes, it will pick a load channel to try to reduce memory consumption.
Status _start_bg_worker();
// lock should be held when calling this method
void _refresh_mem_tracker_without_lock() {
_mem_usage = 0;
for (auto& kv : _load_channels) {
_mem_usage += kv.second->mem_consumption();
}
THREAD_MEM_TRACKER_TRANSFER_TO(_mem_usage - _mem_tracker->consumption(), _mem_tracker.get());
}
protected:
std::mutex _lock; // lock protect the load channel map
std::unordered_map<UniqueId, std::shared_ptr<LoadChannel>> _load_channels; // load id -> load channel
Cache* _last_success_channel = nullptr;
// check the total load channel mem consumption of this Backend
int64_t _mem_usage = 0; int64_t _load_hard_mem_limit = -1; int64_t _load_soft_mem_limit = -1;
std::unique_ptr<MemTrackerLimiter> _mem_tracker;
// By default, we try to reduce memory on the load channel with largest mem consumption, but if there are lots of small load channel, even the largest one consumes very small memory, in this case we need to pick multiple load channels to reduce memory more effectively. `_load_channel_min_mem_to_reduce` is used to determine whether the largest load channel's memory consumption is big enough.
int64_t _load_channel_min_mem_to_reduce = -1;
bool _soft_reduce_mem_in_progress = false;
bool _should_wait_flush = false; std::condition_variable _wait_flush_cond; // If hard limit reached, one thread will trigger load channel flush, other threads should wait on the condition variable.
CountDownLatch _stop_background_threads_latch;
scoped_refptr<Thread> _load_channels_clean_thread; // thread to clean timeout load channels
Status _start_load_channels_clean();
};