文章目录
Broker Load基本原理和语法介绍
一、基本原理
二、Broker Load语法
Broker Load基本原理和语法介绍
Apache Doris架构中除了有BE和FE进程之外,还可以部署Broker可选进程,主要用于支持Doris读写远端存储上的文件和目录。例如:Apache HDFS 、阿里云OSS、亚马逊S3等。Broker Load这种数据导入方式主要用于通过 Broker 服务进程读取远端存储(如S3、HDFS)上的数据导入到 Doris 表里。
使用Broker load 最适合的场景就是原始数据在文件系统(HDFS,BOS,AFS)中的场景,数据量在几十到百GB 级别。用户需要通过 MySQL协议创建 Broker load 导入,并通过查看导入命令检查导入结果。
一、基本原理
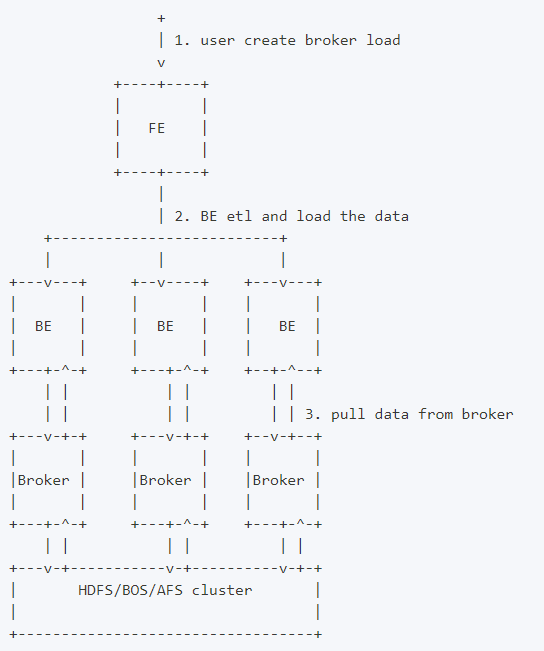
使用Broker Load导入数据时,用户在提交导入任务后,FE 会生成对应的 Plan 并根据目前 BE 的个数和文件的大小,将 Plan 分给 多个 BE 执行,每个 BE 执行一部分导入数据。BE 在执行的过程中会从 Broker 拉取数据,在对数据 transform 之后将数据导入系统。所有 BE 均完成导入,由 FE 最终决定导入是否成功。
二、Broker Load语法
LOAD LABEL load_label
( data_desc1[, data_desc2, ...] )
WITH BROKER broker_name
[broker_properties]
[load_properties]
[COMMENT "comments"];- load_label:
每个导入需要指定一个唯一的 Label。后续可以通过这个 label 来查看作业进度,格式为[database.]label_name
- data_desc1:
用于描述一组需要导入的文件。
[MERGE|APPEND|DELETE]
DATA INFILE("file_path1"[, file_path2, ...])
[NEGATIVE]
INTO TABLE `table_name`
[PARTITION (p1, p2, ...)]
[COLUMNS TERMINATED BY "column_separator"]
[FORMAT AS "file_type"]
[(column_list)]
[COLUMNS FROM PATH AS (c1, c2, ...)]
[SET (column_mapping)]
[PRECEDING FILTER predicate]
[WHERE predicate]
[DELETE ON expr]
[ORDER BY source_sequence]
[PROPERTIES ("key1"="value1", ...)]
1、[MERGE|APPEND|DELETE]
数据合并类型,默认为 APPEND,表示本次导入是普通的追加写操作。MERGE 和 DELETE 类型仅适用于 Unique Key 模型表,其中 MERGE 类型需要配合[DELETE ON]语句使用,以标注 Delete Flag列,而DELETE类型则表示本次导入的所有数据皆为删除数据。
2、DATA INFILE
指定需要导入的文件路径,可以是多个,可以使用通配符。路径最终必须匹配到文件, 如果只匹配到目录则导入会失败 。
3、NEGATIVE
该关键词用于表示本次导入为一批“负”导入。这种方式仅针对具有整型 SUM 聚合类型的聚合数据表。该方式会将导入数据中,SUM 聚合列对应的整型数值取反。主要用于冲抵之前导入错误的数据。
4、PARTITION(p1, p2, ...)
可以指定仅导入表的某些分区。不再分区范围内的数据将被忽略。
5、COLUMNS TERMINATED BY
指定列分隔符。仅在 CSV 格式下有效。仅能指定单字节分隔符。
6、FORMAT AS
指定文件类型,支持 CSV、PARQUET 和 ORC 格式。默认为 CSV。
7、column list
用于指定原始文件中的列顺序。如:(k1, k2, tmpk1)。
8、COLUMNS FROM PATH AS
指定从导入文件路径中抽取的列。
9、SET (column_mapping)
指定列的转换函数。
10、PRECEDING FILTER predicate
前置过滤条件。数据首先根据 column list 和 COLUMNS FROM PATH AS 按顺序拼接成原始数据行。然后按照前置过滤条件进行过滤。
11、WHERE predicate
根据条件对导入的数据进行过滤。
12、DELETE ON expr
需配合 MEREGE 导入模式一起使用,仅针对 Unique Key 模型的表。用于指定导入数据中表示 Delete Flag 的列和计算关系。
13、ORDER BY
仅针对 Unique Key 模型的表。用于指定导入数据中表示 Sequence Col 的列。主要用于导入时保证数据顺序。
14、PROPERTIES ("key1"="value1", ...)
指定导入的format的一些参数。如导入的文件是json格式,则可以在这里指定json_root、jsonpaths、fuzzy_parse等参数。
- WITH BROKER broker_name
指定需要使用的 Broker 服务名称。通常用户需要通过操作命令中的 WITH BROKER "broker_name" 子句来指定一个已经存在的 Broker Name。Broker Name 是用户在通过 ALTER SYSTEM ADD BROKER 命令添加 Broker 进程时指定的一个名称。一个名称通常对应一个或多个 Broker 进程。Doris 会根据名称选择可用的 Broker 进程。用户可以通过 SHOW BROKER 命令查看当前集群中已经存在的 Broker。
注:Broker Name 只是一个用户自定义名称,不代表 Broker 的类型。在公有云 Doris 中,Broker服务名称为 bos。
- broker_properties
指定 broker 所需的信息。这些信息通常被用于 Broker 能够访问远端存储系统。格式如下:
(
"key1" = "val1",
"key2" = "val2",
...
)
可配置如下:
- timeout:导入超时时间。默认为 4 小时。单位秒。
- max_filter_ratio:最大容忍可过滤(数据不规范等原因)的数据比例。默认零容忍。取值范围为 0 到 1。
- exec_mem_limit:导入内存限制。默认为 2GB。单位为字节。
- strict_mode:是否对数据进行严格限制。默认为 false。严格模式开启后将过滤掉类型转换错误的数据。
- timezone:指定某些受时区影响的函数的时区,如 strftime/alignment_timestamp/from_unixtime 等等,具体请查阅时区文档:https://doris.apache.org/zh-CN/docs/dev/advanced/time-zone/。如果不指定,则使用 "Asia/Shanghai" 时区。
- load_parallelism:导入并发度,默认为1。调大导入并发度会启动多个执行计划同时执行导入任务,加快导入速度。
- send_batch_parallelism:用于设置发送批处理数据的并行度,如果并行度的值超过 BE 配置中的 max_send_batch_parallelism_per_job(发送批处理数据的最大并行度,默认5),那么作为协调点的 BE 将使用 max_send_batch_parallelism_per_job 的值。
- load_to_single_tablet:布尔类型,为true表示支持一个任务只导入数据到对应分区的一个tablet,默认值为false,作业的任务数取决于整体并发度。该参数只允许在对带有random分区的olap表导数的时候设置。
- comment
指定导入任务的备注信息。可选参数。
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨












![[HarekazeCTF2019]baby_rop2](https://img-blog.csdnimg.cn/837bc7a5c57e48a0bf1fedd766454d15.png)