目录
文章目录
- 目录
- 计算机系统
- 计算机硬件系统(冯诺依曼体系结构)
- PC 主机硬件
- CPU(中央处理器)
- CPU 的组成部分
- CPU 总线
- 控制器单元
- 运算器单元
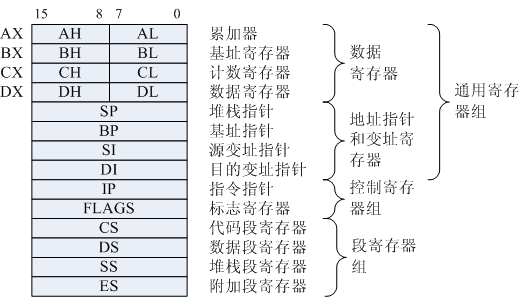
- 寄存器组
- 超线程与多核架构
- 三级高速缓存
- 为什么需要缓存
- 三级缓存结构
- CPU 的指令集
- 指令集的类型
- 指令的格式
- 指令的类型
- 指令的寻址
- CPU 的工作原理
- 流水线
- 执行周期
- Memory(内存储器)
- 存储器类型
- RAM 存储器
- DDR 存储器
- 内存控制器
- 双通道内存控制器
- CPU 访存读写
- Disk(外存储器)
- I/O 外部总线
- 主板
计算机系统
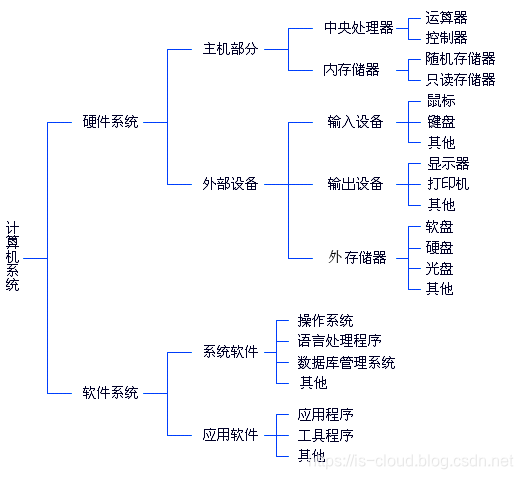
计算机硬件系统(冯诺依曼体系结构)
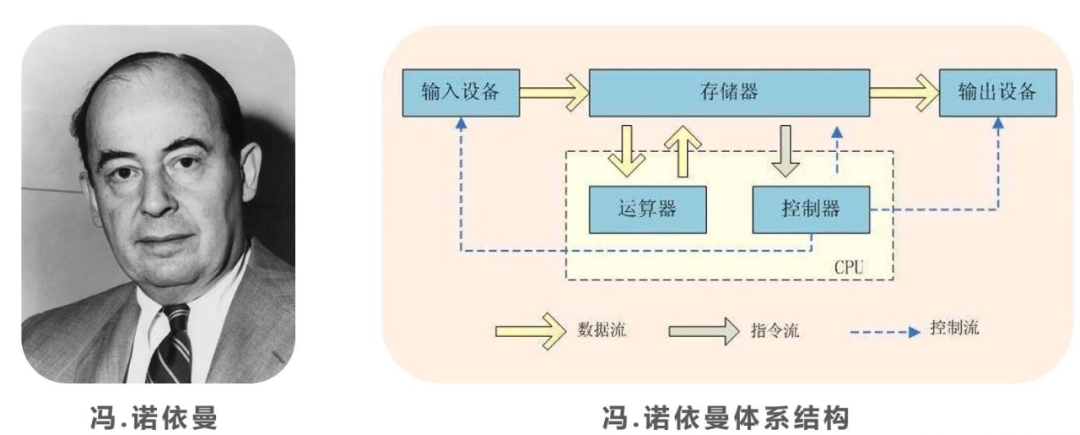
1945 年,冯·诺依曼(John von Neumann)在论文《First Draft of Report o the EDVAC》(第一份草案)中提出了冯·诺依曼体系结构,又称:存储程序计算机。即:程序本身是存储在主机内存中的,可以通过加载不同的程序来解决不同的问题。
冯·诺依曼体系结构奠定了现代计算机的体系结构,它包含了计算机硬件系统的 5 大组成部分:
- 存储器:负责非持久化存储指令(Instruction,程序代码)和操作数(Data,运算数据)。
- 控制器:负责从存储器读取指令流,并根据指令集规范对指令流的控制信息进行分析(e.g. 条件判断、循环、跳转),然后翻译为具体的控制信号,最终用于控制存储器、运算器、输入/输出设备的行为。
- 运算器:负责从存储器读取数据流,并根据控制信号对数据执行算术运算(e.g. 加减乘除)和逻辑运算(e.g. 与或非、位移、比较),最终的运算结果会写入到存储器。
- 输入设备:实现指令和数据的输入,并写入到存储器。包括:鼠标、键盘等设备。
- 输出设备:实现从存储器读取并将运算结果输出。包括:显示器、打印机等设备。
PC 主机硬件
在实际的 PC 中,我们会更经常地将一台计算机分为 “主机“ 和 “外设“ 这两大部分,其中核心的主机部分由以下部件组成:
- 主板(BIOS/CMOS、北桥/南桥芯片组)
- CPU
- 内存
- 磁盘(外存)
- 千兆网卡
- PCIe 扩展卡(万兆网卡、GPU 显卡)
- 系统总线
- 等

CPU(中央处理器)
得益于集成电路技术的发展,得以将控制器和运算器集成到了同一颗芯片之上,称为 CPU(Central Processing Unit,中央处理器),也称为 Micro-CPU(微处理器)。一颗典型的 Micro-CPU 主要包括了 5 个核心部分:
- 控制器单元
- 运算器单元
- 寄存器组
- 三级高速缓存
- CPU 总线
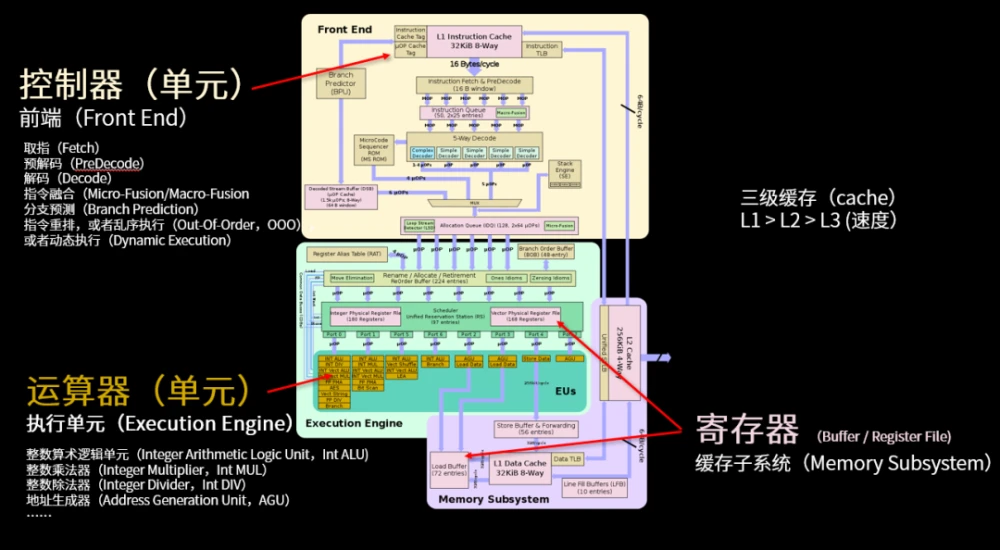
CPU 的组成部分
CPU 总线
首先需要了解的是 CPU 总线,作为 CPU 连接到内存以及其他外部设备的桥梁。CPU 总线由 3 个不同的部分组成:
- 数据总线(DB,Data Bus):用于在 CPU、内存和其他外部设备之间传输 Bit-stream(二进制位流),包括:指令、操作数等。DB 的宽度决定了 CPU 一次可以读写的位数,常见的有 32bits 和 64bits。
- 地址总线(AB,Address Bus):用于在 CPU、内存和其他外部设备之间传输 “主机内存“ 或 “外设存储“ 的 Physical Address(物理地址),告知 CPU 应该从什么位置(地址)读写数据。AB 的宽度决定了 CPU 的寻址空间,例如:32bits 的最大寻址空间为 4GB,所以 32bits 计算机系统只能支持 4G 内存。
- 控制总线(CB,Control Bus):用于在 CPU、内存和其他外部设备之间传输由控制单元发出的控制信号,例如:内存读写信号、中断请求信号、时钟信号和复位信号等。控制器和控制总线用于协调 CPU 和各个组件之间的操作。
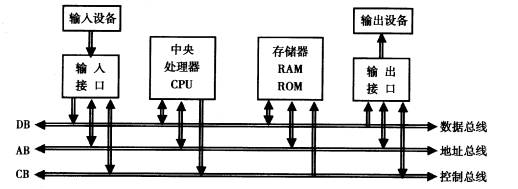
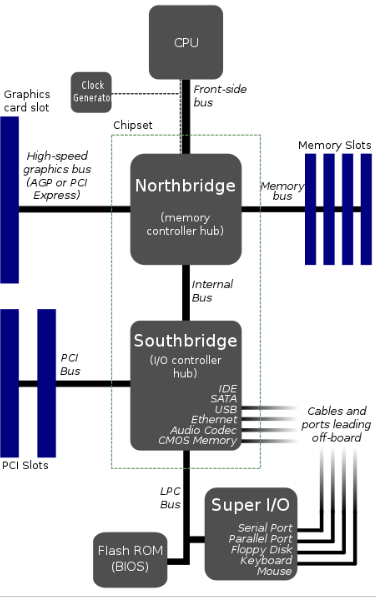
在一些早期的主板中,CPU 总线又被称为 FSB(Front Side Bus,前端总线),用于连接 CPU 和 Northbridge(北桥芯片),然后再由 Northbridge 负责处理 CPU 与内存和其他外部设备之间的传输。
FSB 在早期设计中具有扩展灵活和成本低等优势,但是这种设计以及难以满足多核处理器架构越来越多的 Cores 所提出来的越来越大的带宽需求。
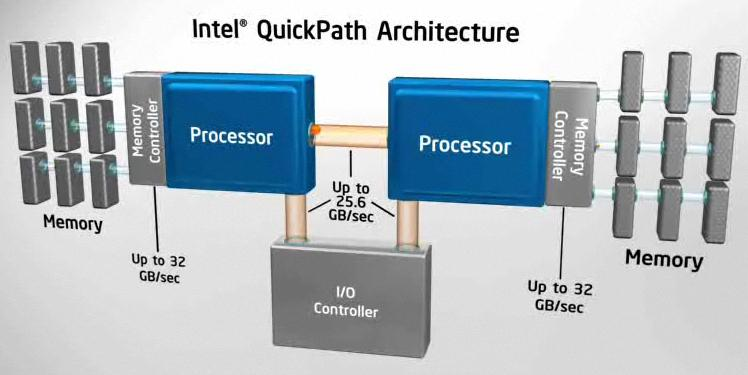
为了实现更大的 CPU 总线带宽以及更低的访存延迟,而在较新的主板中,FSB 和 Northbridge 已经逐渐被 Intel QPI(QuickPath Interconnect)、AMD HyperTransport 等高速 CPU 总线技术(点对点连接)所替代,使得 CPU 可以直接连接到 Memory 和 I/O Controller。
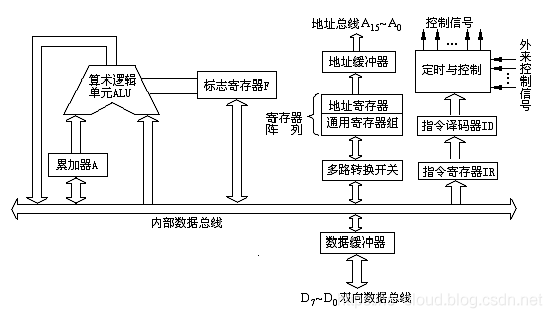
控制器单元
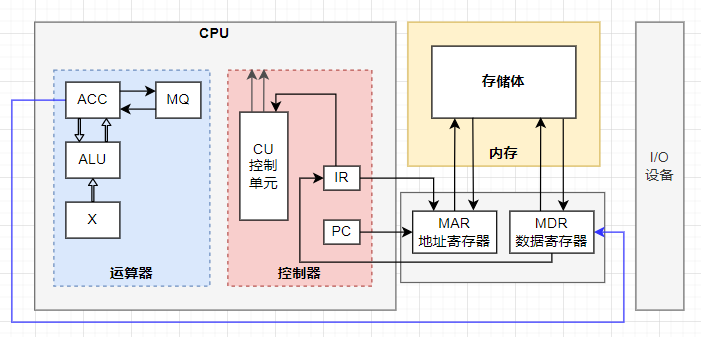
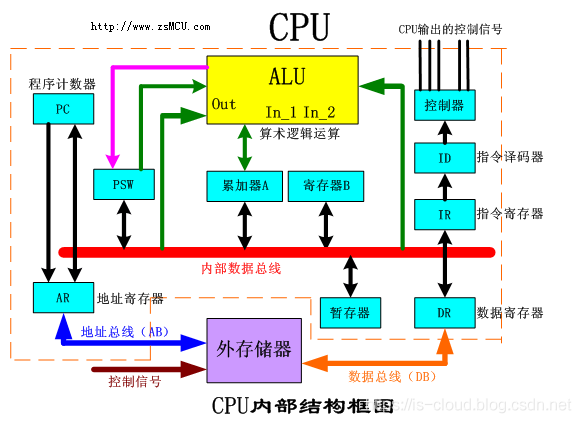
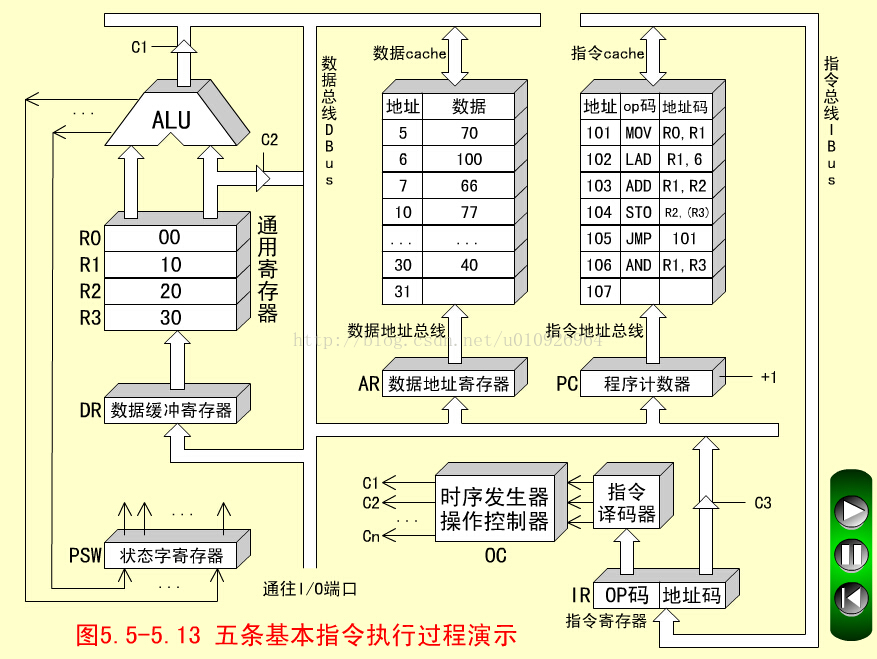
控制器单元(CU,Control Unit)是 CPU 的指挥控制中心,又称为 Front-end(前端),是指令流水线的起始点,负责指令流的获取和解析,并最终翻译为控制信号下达到内存和其他外部设备,以控制后续的执行阶段。
CU 通常包括以下几个主要组件:
-
PC(Program Counter,程序计数器):存放当前正在执行的指令的地址或即将要执行的下一条指令的地址。如果是顺序执行逻辑控制,那么在当前指令处理完毕后,PC 会对指令地址进行 +1 计数,即生成下一条指令的地址。生成地址后,经 AB(地址总线)写入到 MAR(Memory Address Register,内存地址寄存器)。
-
IR(Instruction Register,指令寄存器):存储当前正在执行的指令。IR 通过 MDR(Memory Data Register,内存数据寄存器)经 DB(数据总线)从 Memory 读取到指令代码。待 CU 处理完指令后,将指令的地址经 AB(地址总线)更新到 MAR(Memory Address Register,内存指令地址寄存器)中。
-
ID(Instruction Decoder,指令译码器):从 IR 读取等待执行的指令,进行解码,识别指令的类型和操作码(OPCODE),然后交给 CU 处理。
-
OC(Operation Controller,操作控制器):从 ID 获取到操作码后,并其翻译为具体的控制信号,最终经 CB(控制总线)输出到相应的组件执行。包括以下组件:
- 节拍脉冲源:产生一定频率的脉冲作为 CPU 的时钟脉冲,是 CPU 工作周期的基准信号。
- 启停电路:保证了可靠地送出或封锁完整的时钟脉冲。
- 时序控制信号源:在 CLK 时钟的作用下,根据当前正在执行的指令的需要,产生对应的时间控制信号,并根据被控功能部件的反馈信号调整时序控制信号。
CU 工作时,根据 PC 依次从 Memory 地址空间中取出程序的一行行代码(一条条 CPU 指令)并暂存在 IR 中,通过 ID 分析指令的内容,以确定应该执行什么操作,然后通过 OC 按照确定的时序,向相应的部件(e.g. 运算器、存储器、外设等)发出操作控制信号。

运算器单元
运算器单元(PU,Processing Unit),又称为 ALU(Arithmetic Logic Unit,算术逻辑单元),用于执行算术运算(e.g. 加减乘除)和逻辑运算(e.g. 与或非、位移、比较)这两大运算类型。ALU 是存粹的执行单元,其所进行的全部运算操作都由 CU 所发出的控制信号指挥。
其中,算术运算可以细分为以下 2 种:
- 定点运算(Fixed-point arithmetic):指一种在固定的小数位数范围内进行算术运算的方式。在定点运算中,数值表示为定点格式,通常是固定的整数位和小数位,适用于对整数和固定小数精度的数据进行计算。例如:整数加法、减法、乘法和除法等。
- 浮点运算(Floating-point arithmetic):指一种在可变的小数位数范围内进行算术运算的方式。在浮点运算中,数值表示为浮点格式,由符号、尾数和指数组成,适用于处理大范围和高精度的数据,例如:科学计算、图形处理等,包括加法、减法、乘法、除法、开方等一系列复杂运算。
ALU 通过会内含了定点运算单元和浮点运算单元,两种运算单元在硬件设计上有所不同,以适应不同的运算需求和数据表示方式。例如:浮点运算相对于定点运算提供了更大的数值范围和更高的精度,所以也需要更多的硬件资源和处理时间。
而辑运算则可以细分为以下几种,通常基于逻辑门电路来实现。
- 逻辑与运算(AND)
- 逻辑或运算(OR)
- 逻辑非运算(NOT)
- 异或运算(XOR)
- 比较运算
- 位移运算
- 等
与 ALU 关系密切的寄存器是 AC(Accumulator,累加寄存器)是一个通用寄存器,为 ALU 提供一个工作区,可以暂时保存一个操作数或运算结果。
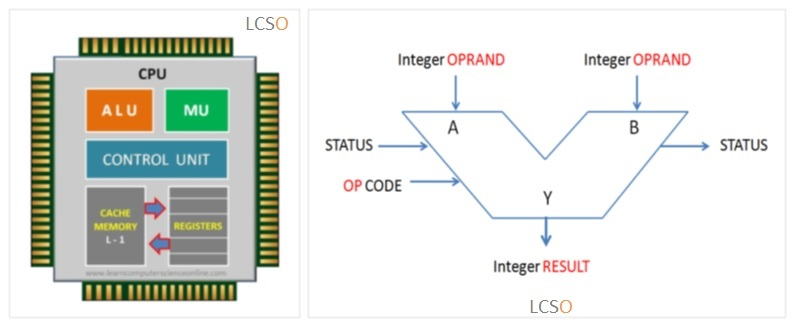
寄存器组
寄存器组是 CU 和 ALU 暂存数据的地方,包括等待处理的数据,或是已经处理过的数据。片内寄存器是 CPU 访问速度最快的存储部件,可以有效减少 CPU 访问 Memory 得次数,但收芯片面积和集成技术限制,寄存器的容量也最小。
CPU 的寄存器组可分为 2 大类:
- 专用寄存器:用途固定,寄存相应的数据;
- 通用寄存器:用途广泛,可由具体的程序规定其用途。
超线程与多核架构
CPU 的超线程(Hyper-threading)是一种可以在同一个 CPU Core 上执行 2 个 Thread(控制流)的技术。具体而言,它在同一个 Core 内复制了多一套用于完成任务控制的 Front-end 部件, 称之为 Architectural State 或 Logical CPU。这 2 个 Thread 共享着片内的 ALU、寄存器组、L1 Cache 等运算和存储部件。
超线程技术使得同一个 Core 可以 “并发“ 处理 2 个运算任务。例如:当一个 Logical CPU Missed Cache 后需要访问 Memory 时,这段时间内 ALU 就会被挂起(Memory Stall),而另一个 Logical CPU 就可以使用 ALU 来运算自己的任务了。
可见,超线程技术极致的压榨了 ALU 的并发性能,提升了吞吐量。但同时也会因为 2 个 Thread 对 ALU、L1 Cache 等共享资源的竞争导致处理时延变长。所以,超线程并不能带来两倍的处理能力,也不提供完全并行计算能力。
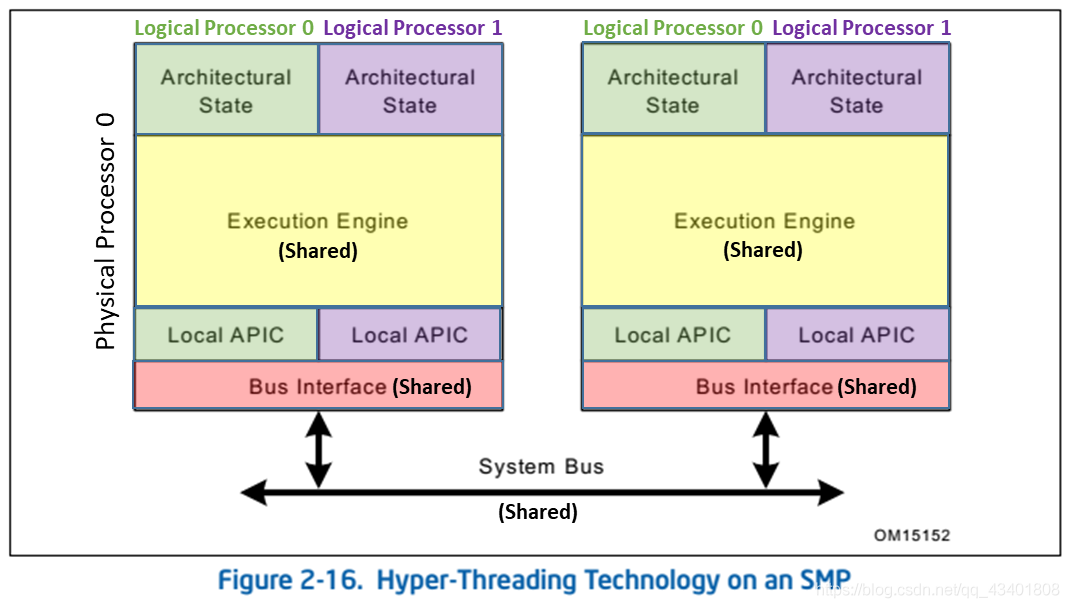
由于 CPU 超线程技术终究不是两个完全独立的 ALU 运算单元,不能提供 2 倍的处理能力和并行计算能力。所以进一步的,Intel 利用 SoC 技术,将多个 Core 集成到了同一块 CPU 芯片上,形成多核处理器(Multicore-processors)架构。
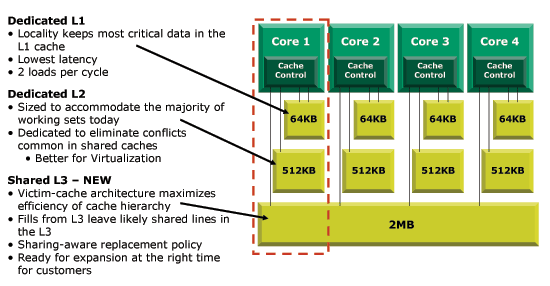
在多核架构中,每个 Core 都拥有独立的 L1/L2 Cache 和超线程。如下图所示。

三级高速缓存
为什么需要缓存
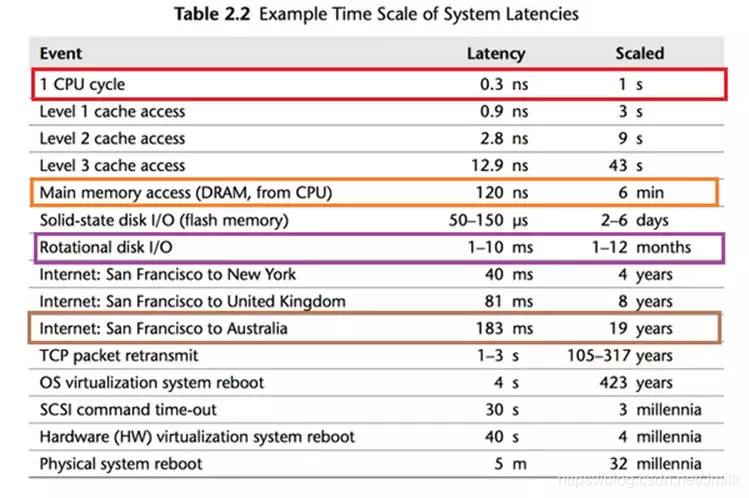
上图中列出了 CPU 的处理速度和访问各种存储器的速度:
- CPU 的处理速度:每个 CPU 时钟周期是 0.3 纳秒;
- CPU 的访存速度:
- 访问内存需要 120 纳秒;
- 访问固态硬盘需要 50-150 微秒;
- 访问传统硬盘需要 1-10 毫秒;
- 访问网络设备需要几十毫秒。
按照等比例换算,假设一个 CPU 时钟周期为 1 秒的话,那么:
- 访问内存需要 6 分钟;
- 访问固态硬盘需要 2-6 天;
- 访问传统硬盘需要 1-12 个月;
- 访问网络则需要几年时间。
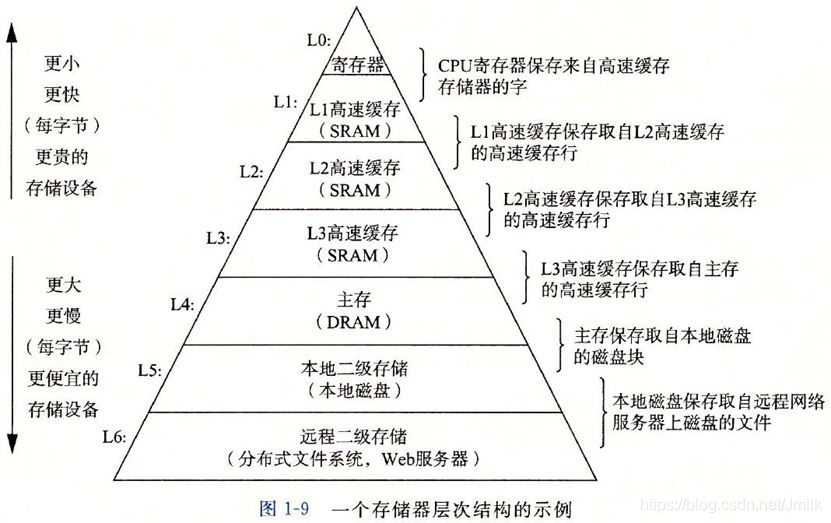
所以,存储器作为冯诺依曼体系结构的核心,为了解决 CPU 的处理速度和访存速度严重不平衡的问题而引入了片内三级高速缓存(CPU Cache)的硬件设计。
CPU Cache 是一个临时的数据交换缓冲区,其理论支撑是 “局部性访问原理“,即:程序访问的内存数据往往集中在很小的一个空间范围内。这是因为程序的虚拟地址空间是趋向于连续的,再加上循环程序流、子程序调用程序流的重复执行,所以程序的地址访问就会相对的集中。如果这部分指令和数据能在 CPU Cache 中找到(Hit,缓存命中),那么 CPU 就不需要访问存储器,从而降低整机的响应时间。
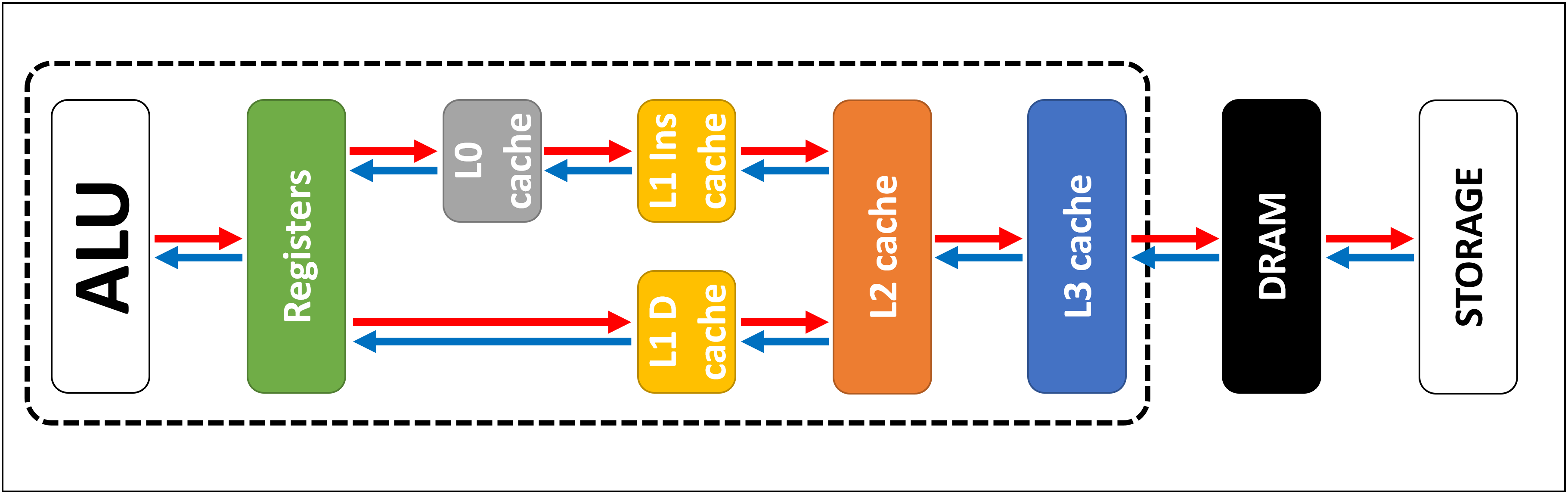
三级缓存结构
另外也由于 CPU Cache 被集成在 CPU 芯片内,更大的 CPU Cache 意味着更高的缓存命中率、更快的速度和更昂贵的成本。为了平衡性能和成本,Cache 逐渐演进为 L1-3 三级缓存结构。如下图所示,储器越往上速度越快,但是价格越来越贵, 越往下速度越慢,但是价格越来越便宜。
L1 Cache 最早出现在 Intel Pentium CPU 上:
- 结构:L1 Cache 被单一的 CPU Core 占有,避免了 CPU Multi-Cores、Multi-Threading 竞争缓冲空间造成的冲突。
- 速度:CPU 访问 L1 Cache 需要 3 个时钟周期。
- 空间:L1 Cache 还被细分为了用于存放指令和数据的 L1-i(Instruction Cache,一级指令缓存)和 L1-d(Data Cache,一级数据缓存。通常的,L1-i 和 L1-d 具有相同的容量,例如:I7-8700K 的 L1 Cache 为 32KB + 32KB。
L2 Cache 最早出现在 AMD Athlon 64X2 CPU 上:
- 结构:L2 Cache 也被单一的 CPU Core 占有。
- 速度:CPU 访问 L2 Cache 需要 10 个时钟周期。
- 空间:L2 Cache 速度更慢的原因有以下 2 个。可见,实际上 Cache 并非越大越好,L2 Cache 通常是 256KB 或 512KB。
- L2 比 L1 要更远离 CPU Core,CPU 读取 L2 的数据从物理距离上比 L1 更远;
- L2 的容量比 L1 更大,所以数据检索时间也更长。
L3 Cache 最早出现在 AMD K6-III CPU 上:
- 结构:L3 Cache 是 Multi-Cores Sharing 的缓存空间,所以会存在缓存竞争、缓冲同步、缓冲数据一致性等应用问题。
- 速度:CPU 访问 L3 Cache 需要 50 个时钟周期。
- 空间:L3 Cache 的容量对 CPU 性能的提升并非是线性增长的,即:L3 从 0 到 2M 的情况 CPU 性能提升非常明显,L3 从 2M 到 6M 提升可能就只有 10% 不到了。这是由于 L3 Cache Sharing 需要面对的情况。
CPU 的指令集
CPU 指令集(Instruction Set),又称为 CPU 架构,是 CPU 提供的可执行指令的集合,它决定了 CPU 的功能特性,并通过指令系统向上层软件生态提供互操作入口。


指令集的类型
值得注意的是,指令系统并非越复杂越好,因为每条 CPU 指令类型都需要特定的晶体管和电路元件来支撑实现,所以指令集越大就会使 CPU 的架构越复杂,执行操作的速度也更慢。并且在大多数场景中,实际上只有算术逻辑运算、数据传输、跳转和程序调用等几十条指令会被频繁的使用,而需要大量硬件支持的大多数复杂的指令却并不常用,也会造成硬件资源的浪费。
指令系统的设计原则一直都致力于缩小 CPU 指令集与高级语言之间的语义差异以及有利于操作系统的优化。
例如:
- 为了 C 语言中的 if 语句、do 语句,在汇编层面则提供了功能较强的条件跳转指令;
- 为了操作系统的实现和优化,则提供了控制系统状态的特权指令、以及管理多道程序和多处理机系统的专用指令。
所以现在常见的指令系统从大的方向上可以被分为 2 类:
-
复杂指令系统计算机(CISC):特点是指令数目多而复杂且通用性强。但由于每条指令的字长并不相等,CPU 必须加以判读,并为此付出了性能的代价。好处在于其更趋近于跨越了与高级编程语言的 “语义鸿沟”,提供了更 “高端” 的指令以支持高级编程语言的语义,例如:判断、循环、函数调用、返回等高级指令,故而软件应用生态完善。x86(The X86 architecture)就是最经典的 CISC。
-
精简指令系统计算机(RISC):特点是指令数目精简且专用性强、设计周期更短、价格低、能耗比底。CPU 流水线以及常用指令均可用硬件执行,并采用了大量的寄存器,使大部分指令操作都在寄存器之间进行,提高了处理速度。RISC 最早起源于 80 年代的 MIPS(Microprocessor without interlocked piped stages,无内部互锁流水级的微处理器)架构,现在典型的有 ARM(Advanced RISC Machine,进阶精简指令集机器)和 RISC-V(RISC-FIVE,第五代 RISC 开源指令集架构)架构。

指令的格式
一条 CPU 指令字的格式主要由 “操作码“ 和 “地址码“ 组成,而指令字的长度与 CPU 的位数密切相关。
- 操作码:说明指令操作的性质和功能(e.g. 加减乘除、数据传输),操作码长度由指令系统的指令条数决定,例如:CPU 支持 256 条指令,那么操作码就需要 8bits 的长度。
- 操作数的地址:CPU 通过该地址读取到所需要的操作数,可能是寄存器的地址,也可能是存储器的地址。
- 操作结果的储存地址:保存操作结果的地址。
- 下一条指令的地址:有 2 种地址生成方式:
- 顺序执行逻辑控制:通过 PC +1 得到下一条指令的地址;
- 跳跃执行逻辑控制:如跳转、函数调用等,通过跳转类指令本身给出下一条指令的地址。
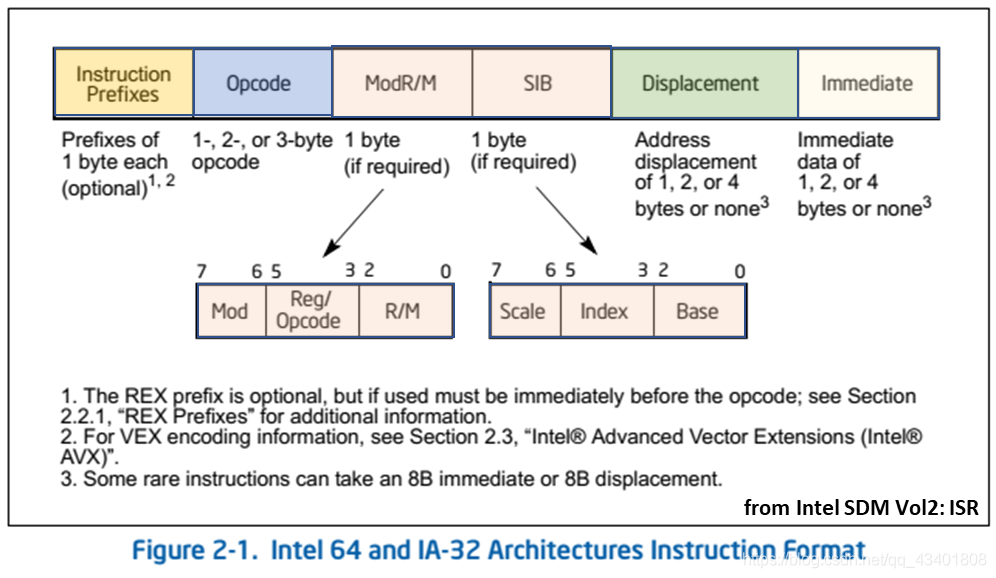
以 MIPS 架构的 32bits 指令(最新版本为 64bits)格式为例:
- 高 6bits 为操作码(OPCODE),描述了指令的操作类型。
- 低 26bits 又分为 R、I 和 J 这 3 种指令类型。
不同的指令类型和操作码组合能够完成多种功能实现,如下图所示:

加法算数指令 add $t0,$s2,$s1 的指令字及其对应的机器码如下:
- opcode:0。
- rs:代表第一个寄存器 s1 的地址是 17。
- rt:代表第二个寄存器 s2 的地址是 18。
- rd:代表目标临时寄存器 t0 的地址是 8。
- shamt:0,表示不位移。
最终加法算数指令 add $t0,$s2,$s1 的二进制机器码表示为 000000 10001 10010 01000 00000 1000000(0X02324020)。可以看见,机器码中没有保存任何实际的程序数据,而是保存了程序数据的储存的地址,这也算是存储程序计算机指令集设计的一大特点。

需要注意的是,在不同的 CPU 架构中,会具有不同的指令格式。在指令字长较长的 CPU 中,操作码的长度一般是固定的,由指令集的数量决定。但在指令字较短的计算机中,为了能够充分利用指令字的位数,在有限的长度中实现更多的指令集数目,所以其操作码长度被设计成是可变的,即把它们的操作码在必要的时候扩充到地址码字段。这就是所谓的操作码扩展技术。
指令的类型
日常使用的 Intel CPU 指令大概有 2000 多条,可以分为以下 5 大类型:
- 算术类:加减乘除。
- 数据传输类:变量赋值、读写内存数据。
- 逻辑类:与或非。
- 条件分支类:条件判断语句。
- 无条件跳转类:方法、函数的调用跳转。

更详细的,还会具有如下指令类型:
- 算术逻辑运算指令
- 移位操作指令
- 算术移位
- 逻辑移位
- 循环移位
- 矢量运算指令(矩阵运算)
- 浮点运算指令
- 十进制运算指令
- 字符串处理指令
- 字符串传送
- 字符串比较
- 字符串查询
- 字符串转换
- 数据传输指令
- 寄存器与寄存器传输
- 寄存器与主存储器单元传输
- 存储器单元与存储器单元传输
- 数据交换(源操作数与目的操作下互换)
- 转移指令
- 条件转移
- 无条件转移
- 过程调用与返回
- 陷阱
- 堆栈及堆栈操作指令
- I/O 指令
- 特权指令
- 多处理机指令(在多处理器系统中保证共享数据的一致性等)
- 控制指令
- 等等
指令的寻址
指令寻址,即:CPU 根据指令字的地址码从寄存器或存储器中读写实际数据的过程。
指令的寻址方式跟硬件关系密切,不同的计算机有不同的寻址方式。例如:
- 有的计算机寻址方式种类少,所以会直接在操作码上表示寻址方式;
- 有些计算机的寻址方式种类多,就会在指令字中添加一个特别用于标记寻址方式的字段。
总的来说,常见的指令寻址方式有以下几种:
- 直接寻址:指令字的地址码直接给出了操作数在寄存器或存储器中的地址,是最简单的寻址方式。
- 间接寻址:指令字的地址码所指向的寄存器或存储器的内容并不是真实的操作数,而是操作数的地址。间接寻址常用于跳转指令,只要修改寄存器或存储器的地址就可以实现跳转到不同的操作数上。
- 相对寻址:把 PC 的内容(当前执行指令的地址)与地址码部分给出的偏移量(Disp)求和作为操作数的地址。这种寻址方式同样常用于跳转(转移)指令,当程序执行到本条指令后,跳转到 PC+Disp。
- 立即数寻址:即地址码本身就是一个操作数,该方式的特点就是速度快(实际上没有寻址过程),但操作数固定。常用于为某个寄存器或存储器单元赋初值,或提供一个常数。
- 通用寄存器寻址:通用寄存器可以用于临时储存操作数、操作数的地址或中间结果,指令字的地址码可以指向这些寄存器。通用寄存器具有地址短,存取速度快的特性,所以地址码指向通用寄存器的指令的长度也会更短,节省存储空间,执行效率更快。常被用于执行速度要求严格的指令中。
- 变址寄存器寻址:变址寄存器内的地址与指令字地址之和得到了实际的有效地址,如果 CPU 中存在基址寄存器,那么就还得加上基址地址。这种寻址方式常用于处理需要循环执行的程序,例如:循环处理数组,此时变址寄存器所改变的就是数组的下标了。
- 堆栈寻址:堆栈是有若干个连续的存储器单元组成的先进后出(FILO)存储区。堆栈是用于提供操作数和保存运算结果的主要存储区,同时还主要用于暂存中断和子程序调用时的线程数据及返回地址。
- 基址寄存器寻址:基址寄存器是存放基址(基础地址)的寄存器,通常是一个专用寄存器。执行指令时,需要将基址与指令字的地址码结合得到完成的地址,此时的地址码充当着偏移量的角色。
当存储器容量较大时,直接寻址方式是无法访问所有的存储单元,所以通常会采用分段或分页内存管理方式。此时,段或页的首地址就会存放于基址寄存器中,而指令字的地址码就作为段或页的长度,这样只要修改基址寄存器的内容就可以访问到存储器的任意单元了。这种寻址方式常被用于为程序或数据分配存储区,与虚拟内存地址实现密切相关。
基址寄存器寻址方式解决了程序在存储器中的定位存储单元和扩大 CPU 寻址空间的问题。
CPU 的工作原理
流水线
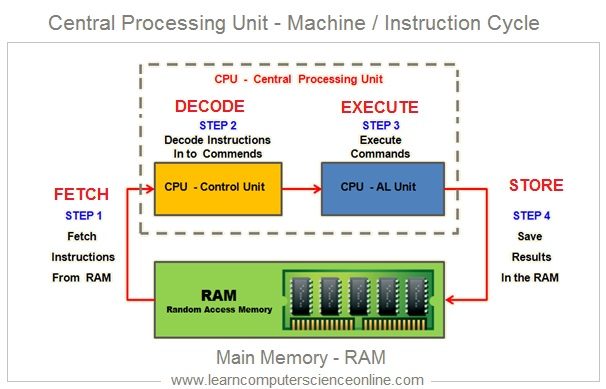
CPU 将一条指令的执行划分为多个不同的阶段,根据不同的 CPU 架构会有所差别,以经典的 RISC 架构为例,存在以下常规步骤:
- 取指令:CU 在时序脉冲的作用下,从 main() 程序入口将第一条指令的地址写入 PC,然后 CU 将 PC 存储的指令地址送到 AB(地址总线)上,CPU 就将这个地址指向的指令读到 IR。
- 分析指令:ID 从 IR 读取指令字的内容并进行解码,理解指令的操作码和操作数。对于执行指令过程中所需要用到的操作数,会将操作数的地址码也送到 AB 上,CPU 就将这个地址指向的数据读取到寄存器组中暂存起来。
- 执行指令:OC 发出控制型号到 ALU,由 ALU 完成对数据的运算处理。
- 访问主存:ALU 将运算结构写入存储器。
- 写回寄存器:例如 PC +1,周而复始,一条一条指令执行下去,直到停电为止。
在上述常规步骤的执行期间还可能会穿插着一下内容:
- 控制程序指令和数据的输入与运算结果输出:根据程序的内容或人工干预,CU 在适当的时候向输入/输出设备发出相应的指令来完成 I/O 功能。
- 对异常情况和某些中断请求的处理:在特定的时刻(异常中断、输入/输出中断),由相应的部件或设备向 CPU 发出中断请求信号或 DMA 请求信号。
- 中断请求信号:待 CPU 执行完当前指令后,响应该中断请求,中止当前执行的程序,转而执行中断程序。待中断程序执行完后,再回到原程序继续执行下去。
- DMA 请求信号:待 CPU 完成当前机器周期的操作后,暂停工作,让出总线给 I/O 设备。待完成 I/O 设备和存储器之间的数据传输之后,CPU 从暂时中止的机器周期开始继续执行原程序的指令。
可见,上述不同的步骤可能由 CPU 内部的不同部件(e.g. CU、ALU)来完成。在这样的前提下,如果 CPU 只是单纯的顺序执行这些步骤的话,势必会在某一时刻使得一些部件处于空闲状态。
那么,如果 CU 对其他各个部件都调度恰当、让不同部件可以并行工作的话,能够极大的提高 CPU 整体的工作效率和运算速度,这就是多级流水线调度方式(Pipeline)的设计思想,即:将 CPU 指令的处理过程拆分为多个步骤,并通过多个硬件处理单元并行执行来加快指令执行速度。
除了流水线技术之外,后来还引入了乱序执行以及分支预测等更加复杂的技术。
流水线的类型:
- 指令执行流水线
- 运算操作流水线
流水线的优点:
- 提高 CPU 主频:流水线将组合逻辑分割成多个小块,因为每段的关键路径变短了,所以能提高系统主频。
- 提高系统吞吐量:因为流水线让任务以类似并行方式处理,提高硬件模块的利用率,所以能提高吞吐量(Throughput)。
流水线的缺点:
- 由于流水线让许多指令被同时执行,假如分支预测错误的话整个流水线上所有的指令全部要被取消,流水线要被重新充满,就需要从存储器或者 CPU 缓存中调用指令,导致延迟时间,在这段时间里 CPU 是没有任何工作的。

执行周期
在了解执行周期之前,还需要先了解几个频率相关的概念,包括:
-
时钟脉冲:指脉冲信号,是一个由 CU 按一定电压幅度、在一定时间间隔内连续发出的电子脉冲信号,是计算机的基本工作脉冲,控制着计算机的工作节奏。时钟频率越高,时钟周期就越短,工作速度也就越快。
-
时钟频率(Clock Speed):指同步电路中时钟脉冲的基础频率,是单位时间(1s)内所产生的时钟脉冲的个数。时钟频率是描述周期性循环信号在单位时间内所出现的次数,标准计量单位是 Hz(赫兹)。
-
CPU 主频:是 CPU 内部工作的时钟频率,是评定 CPU 性能的重要指标,一般来说主频数值越大越好。需要注意的是,主频仅是 CPU 性能表现的一个方面,而不代表 CPU 的整体性能,CPU 的运算速度还考虑流水线的各方面的性能指标(缓存、指令集、CPU 的位数等)。
-
主板外频:是 CPU 外部的工作频率,由主板提供的一个基准时钟频率。CPU 主频和外频的关系如下:
- CPU 主频 = 信频 * 外频。
- CPU 主频 = 倍频 * 外频。
-
FSB 频率:在早期的主板中,FSB 频率是连接 CPU 和主板桥芯片的 FSB 上的数据传输频率。
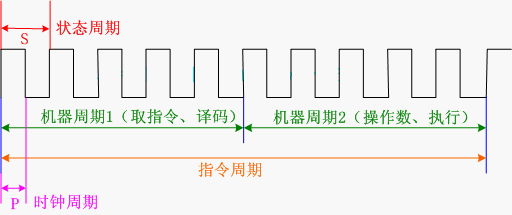
周期就是频率的倒数,CPU 的执行周期可以分为以下几种:
-
时钟周期(P 周期):也称为 CPU 节拍。是时钟频率的倒数(1/时钟频率),例如:时钟频率为 4.77MHz,那么每个时钟周期约就为 200ns。作为 CPU 中最小的工作时间单位,不可被中断。在一个时钟周期内,CPU 仅完成一个最基本的动作,更小的时钟周期就意味着更高的工作频率。
-
状态周期(S 周期):时钟脉冲经过二分频后定义为状态,一个状态包含两个 CPU 节拍。
-
机器周期:在 CU 流水线调度方式中,一条指令的执行被分为多个步骤,每个步骤完成一项工作,而完成一项工作操作所需要的时间就称为机器周期。通常的,一个机器周期由 12 个时钟周期组成,也就是由 6 个状态周期组成。
-
指令周期:指令周期是执行完成一条指令所需要时间,由若干个机器周期组成。指令周期的类型有:非访内存指令周期、取数/存数指令周期、空操作指令周期、转移指令周期等等。
-
总线周期:CPU 是通过 CPU 总线来访问 Main Memory 和 I/O Endpoint 的,总线周期指的就是 CPU 完成一次访问 Memory 或 I/O Endpoint 所需要的时间。一个总线周期由若干个时钟周期组成。
Memory(内存储器)
存储器类型
RAM 存储器
RAM(Random Access Memory,随机存储器)是一种半导体的、非永久记忆(易失性,Volatile)的、可随机访问任意地址的存储单元,且存取开销与物理地址的位置无关。其具有 2 个非常重要的特性:“可随机访问” 和 “易失性”,这些特性都服务于冯诺依曼体系 “存储程序” 的核心理想。
-
DRAM(动态随机存储器):常用于主存储器。其使用了电容存储,只能将数据保持很短的时间。所以为了保持数据,就必须隔一段时间刷新(Refresh)一次,如果存储单元没有被刷新,存储的信息就会丢失。DRAM 存储单元的电路相对简单,只含一个晶体管和一个电容器,集成度非常高,可以轻松做出大容量。但是因为靠电容器来储存信息,所以需要不断刷新补充电容器的电荷,充电放电之间的时间差导致了 DRAM 比 SRAM 的反应要缓慢得多。
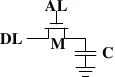
-
SRAM(静态随机存储器):常用于高速缓冲。所谓的 “静态”,指这种存储器只要保持通电,里面储存的数据就可以恒常保持。相对之下,DRAM 里面储存的数据需要周期性地 Refresh。然而,当电力供应停止(关机)时,储存的数据还是会消失。SRAM 存储单元的电路非常复杂,导致 SRAM 的集成度很低,功耗IE较 DRAM 大。但 SRAM 的特点就是快,有电就有数据,不需要刷新时间所以凸显其数据传输速度很快。
DDR 存储器
DDR(双倍速率同步动态随机存储器)是 RAM 的一种演进。RAM 在一个 CPU 时钟周期内只传输一次数据(在时钟上升期进行传输),而 DDR 内存则可以在一个 CPU 时钟周期内传输两次数据(在时钟上升期和下降期各传输一次),因此称为 “双倍速率同步动态随机存储器“。可见,DDR 可以在与 RAM 具有相同的 CPU 主频下达到更高的数据传输率。
从外形体积上 DDR 与 RAM 相比差别并不大,他们具有同样的尺寸和同样的针脚距离。但 DDR 为 184 针脚,比 RAM 多出了 16 个针脚,主要包含了新的控制、时钟、电源和接地等信号。DDR 内存采用的是支持 2.5V 电压的 SSTL2 标准,而不是 RAM 使用的 3.3V 电压的 LVTTL 标准。

内存控制器
双通道内存控制器
为了适应双路 NUMA CPU 架构,解决内存带宽不足的问题,Memory 也引入了双通道(Two-channel)内存控制器技术。
在北桥芯片里集成了两个 Memory Controller,它们相互独立,每个控制器控制一个内存通道。对这两个内存通道,CPU 均可分别寻址和读写数据,从而使内存的带宽增加一倍,数据存取速度也相应增加一倍(理论上)。目前主流芯片组的双通道内存技术均是指双通道 DDR 内存技术,由两个 64bits DDR 内存控制器组成,其带宽可达 128bits。
CPU 访存读写
CPU 和 Memory 之间通过 CPU 总线连接,具有 AB(地址总线)、DB(数据总线)、CB(控制总线)这 3 种类型。而在 CPU 访存读写过程中,数据面主要通过 MAR&AB 和 MDR&DB 的组合来完成,而控制面则通过 CB 发出的控制信号来完成。
- 若 MAR 为 K 位字长,则表示 CPU 的寻址宽度,即允许 Memory 包含有 2**K 个可寻址存储单位;
- 若 MDR 为 n 位字长,则表示在一个 CPU 总线周期内,CPU 和 Memory 之间通过总线进行 n 位的数据传输。
CB 可以发出 READ、WRITE 和 READY(表示存储器功能完成)这 3 种控制信号。
- READ:CPU 必须指定一个地址,将该地址送到 MAR 再经 AB 送到 Memory。同时,CPU 通过 CB 发送 READ 信号到 Memory。此后,CPU 等待 Memory 通过 CB 发来一个 READY 信号,表示已经完成了数据的读,并将数据经 DB 放到 MDR 上了。最后,CPU 再从 MDR 取出相应的数据。
- WRITE:CPU 首先将存放数据的地址通过 MAR 经 AB 发送到 Memory,并将数据放到 MDR,同时发出一个 WRITE 信号到 Memory。此后,CPU 等待接收 READY 信号。Memory 会根据 AB 收到的地址来存放 DB 收到的数据,然后通过 CB 发送 READY 信号给 CPU 接收。
可见,CPU 和 Memory 之间采用的是异步工作方式,以 READY 信号表示以此访存操作的结束。

Disk(外存储器)
Disk(外存储器)通常为磁表面的、串行访问的、永久性记忆的存储器类型。主流的有 HDD(Hard Disk Drive,机械磁盘)、SSD(Solid-state Drive,固态磁盘)类型,先进的有以 NAND Flash(闪存)作为介质的永久性存储器。
区别于 HDD 以机械臂带动磁头转动实现读写操作,SSD 和 NAND 以电位高低或者相位状态的不同来记录 0 和 1。外存的主要技术指标有:存储密度、存储容量、寻址时间、数据传输率、误码率和价格等。
I/O 外部总线
现代计算机硬件系统都是采用了 “多总线架构“,即:将相较于主机而言速度更低的外部设备从 CPU 总线上分离出去,形成了 CPU 总线 和 I/O 外部总线分离的双总线结构。同理,还可以将高速 I/O 设备(e.g. 图形、视频、网络)与低速 I/O 设备分离为两条 I/O 总线,成为三总线结构。
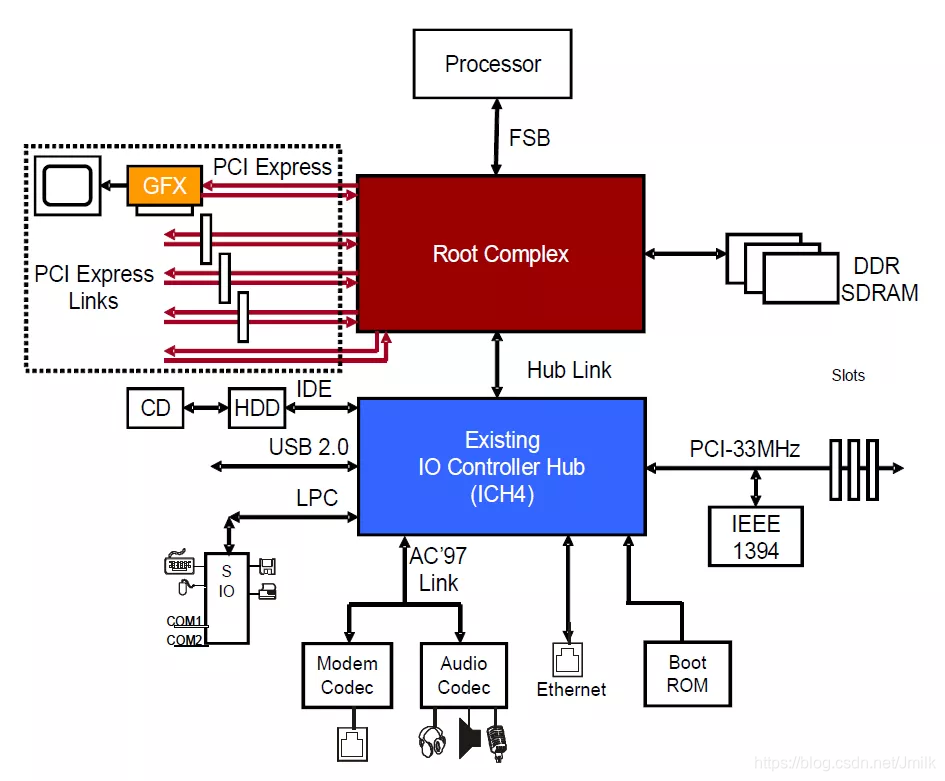
I/O 外部总线可分为 2 大类型:
- 串行总线:一位一位的传送二进制的总线,例如:USB、IEEE 1394 等。
- 并行总线:一次能同时传送多个二进制位数的总线,例如:ISA/IDE 和 SCSI 等。
I/O 外部总线和 CPU 总线一样,同样需要 Controller 来进行控制,用于保证在同一时间内只能有一个申请者在使用 I/O 外部总线,并支持多种不同的 I/O 通信方式:
- 同步通信:通信双方由统一的时钟控制数据传输,时钟由 CPU 发出,并送到总线上的所有部件,在规定的总线周期内,只有通信双方可以收发数据。
- 异步通信:通信双方通过 “握手” 信号实现总线数据传送,通常用于实现不同速度部件之间的数据传送。
- 并行通信:表示同时传输多位字长,有 8 位、16 位、32 位和 64 位等。特点是位数越多传输越快,但传输距离较短,只能在一个机柜内使用。
- 串行通信:串行通信表示一位一位的传输。特点是速度较慢,但胜在通信线路简单,容易实现双向传输,特别适合远距离传输。
- 串行异步通信:串行通信和异步通信的结合。这种通信方式需要使用到特殊的数据格式(具有起始位、停止位和奇偶校验位)。
通常的,出现了一种新的并行通信协议,就会紧随着出现与之对应的串行通信协议。这是因为并行通信方式总是存在着一些难以克服的缺陷,使其无法满足所有的应用场景。比如:
- 信号时滞:虽然并行通信中的所有位是同时传输的,但却不能保证是所有位都同时到达的,先到等后到就造成了时滞的问题。而且会随着传输距离的拉长越发明显。
- 串扰:总线上传输的是电子信息,所以并排线缆间容易出现互相干扰的问题,这也导致了并行通信有着更高的误码率。
- 影响机箱散热:并行通信依赖大连接器和很宽的带状传输电缆,这会挤压机箱的散热空间。
主板
主板(Motherboard, Mainboard,Mobo),又称主机板、系统板、逻辑板(Logic Board)、母板、底板等,是构成复杂电子系统,例如:电子计算机的中心或者主电路板。
下图为较为古老的 LGA 1366 主板,包含了南桥和北桥,这是最后一代使用双晶片的主机板。之后所有 Intel 与 AMD 的主板均仅有南桥,北桥和内建显示核心已整合到 CPU。

- CPU 插槽(LGA 1366)
- 北桥(被散热片覆盖)
- 南桥(被散热片覆盖)
- 内存插座(三通道)
- PCI 扩充槽
- PCI Express 扩充槽
- 跳线
- 控制面板(开关掣、LED 等)
- 20+4pin 主机板电源
- 4+4pin 处理器电源
- 背板 I/O
- 前置 USB 针脚
- 前置面板音效针脚
- SATA 插座
- ATA 插座(大部分 Intel Sandy Bridge 以后的家用主板都已舍弃 IDE 介面)
- 软碟机插座(目前绝大多数主板已舍弃软碟机介面)
-
主板 CPU 插槽

-
主板内存插槽

-
PCI-E 插槽:可以作为万兆网卡、GPU 显卡、SSD 固态硬盘、声卡等外部设备的扩展接口。

-
主板网卡适配器

-
主板 SATA 接口插槽









![[C++]哈希表实现,unordered_map\set封装](https://img-blog.csdnimg.cn/00deabab0b6441a381c1cb2c44b4d60f.png)