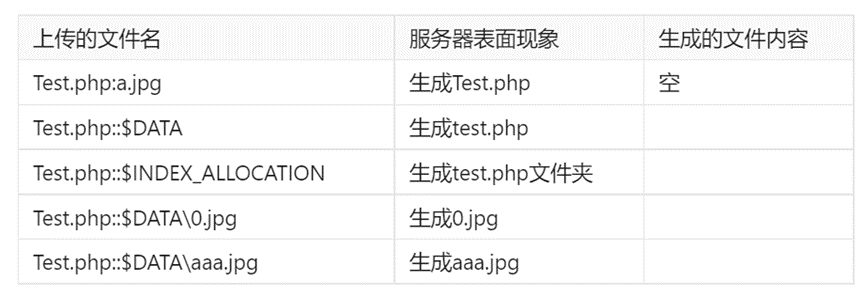
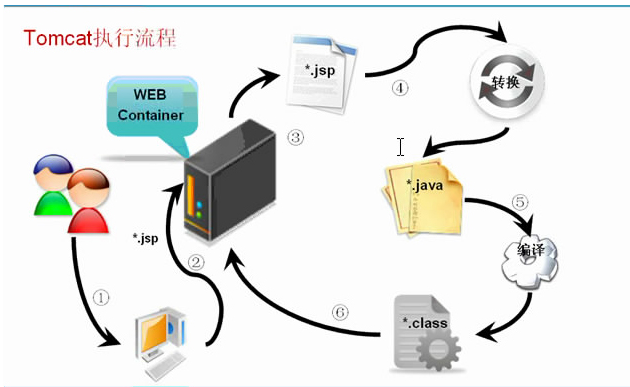
Python 读取扫描版 PDF、图片 PDF 并进行 OCR 识别的方法:
pytesseract:一种基于 Python 的 OCR 库,可用于识别扫描版 PDF 和图片 PDF 中的文本。
它可以使用 Google 的 OCR 引擎进行识别,也可以使用本地的 OCR 引擎进行识别。使用 pytesseract 需要安装 Tesseract OCR 引擎和 pytesseract 库,可以通过以下命令安装:
非纯图可复制pdf
pip install pytesseract
sudo apt-get install tesseract-ocr
然后,可以使用以下代码进行 PDF 中文文本的 OCR 识别:
import pytesseract
from pdf2image import convert_from_path
import os
pytesseract.pytesseract.tesseract_cmd = r'D:\software2\Tesseract\tesseract.exe'
custom_config = r'--tessdata-dir D:\software2\Tesseract\tessdata'
os.chdir(os.getcwd())
def tess_ocr(fname, lang):
# 将pdf转换为png后,保存在dirname文件夹
dirname = fname.rsplit('.', 1)[0]
if not os.path.exists(dirname):
os.mkdir(dirname)
images = convert_from_path(fname, fmt='png', output_folder=dirname)
text = ''
for img in images:
text += pytesseract.image_to_string(img, lang=lang)
with open('result1.txt', 'w', encoding='utf-8') as f:
f.write(text)
return text
fname = 'example.pdf'
text = tess_ocr(fname, lang='chi_sim')
print(text)
唯二可以识别纯图PDF的
用 銮 银 路 涉 及 220 千 伏 岩 礼 4R92 线 宪 泉 4R93 线 #21-423 塔 迂 改 工 程 中 标 结 果 公
吊
门
( 招 标 编 号 : ZJGZDL-2023-04-%02 )
一 、 中 标 人 信 息 :
标 段 ( 包 ) [0011 用 金 铁 路 涉 及 220 十 伏 岩 礼 4R92 线 宏 泉 4R93 线 #21-#23 塔 迁 改 工 程 :
中 标 人 : 绍 兴 建 元 申 力 集 团 有 限 公 司 中 标 费 率 , 下 泽 3. 508
二、 其他=
绍 兴 建 元 电 力 集 团 有 限 公 司 为 中 标 人
三 、 监 督 部 门
本 招 标 项 目 的 监 督 部 门 为 绍 兴 电 力 局 招 投 征
四 、 联 系 方 式
招 标 人 : 嵊 州 市 铁 路 项 目 工 程 建 设 指
地 “ 址 , 绍 兴 嵊 州 市
哑 系 人 : 吕 先 旺
田 话 : 18069621508
电 子 邮 件 : 5441426216qq. com
招 标 代 理 机 构 : 浙 江 广 正 建 设 顺 目 管 理 有 限 公 司
地 址 : 浙 江 省 绍 兴 市 越 城 区 阳 明 北 路 80 号 A 楼 匹 楼 L-1
联 系 人 : 高 强
电 话 : 13867532448
电 子 邮 件 : 734201819&dd. com
招 标 人 或 兰
Process finished with exit code 0
PyPDF2:一种用于处理 PDF 文件的 Python 库,可以用于读取扫描版 PDF 中的文本。
使用 PyPDF2 需要安装 PyPDF2 库,可以通过以下命令安装:
pip install PyPDF2
然后,可以使用以下代码读取 PDF 中的文本:
import PyPDF2
# 打开 PDF 文件
with open('example.pdf', 'rb') as f:
pdf_reader = PyPDF2.PdfReader(f)
# 读取 PDF 中的文本
text = ''
for page in pdf_reader.pages:
text += page.extract_text()
print(text)
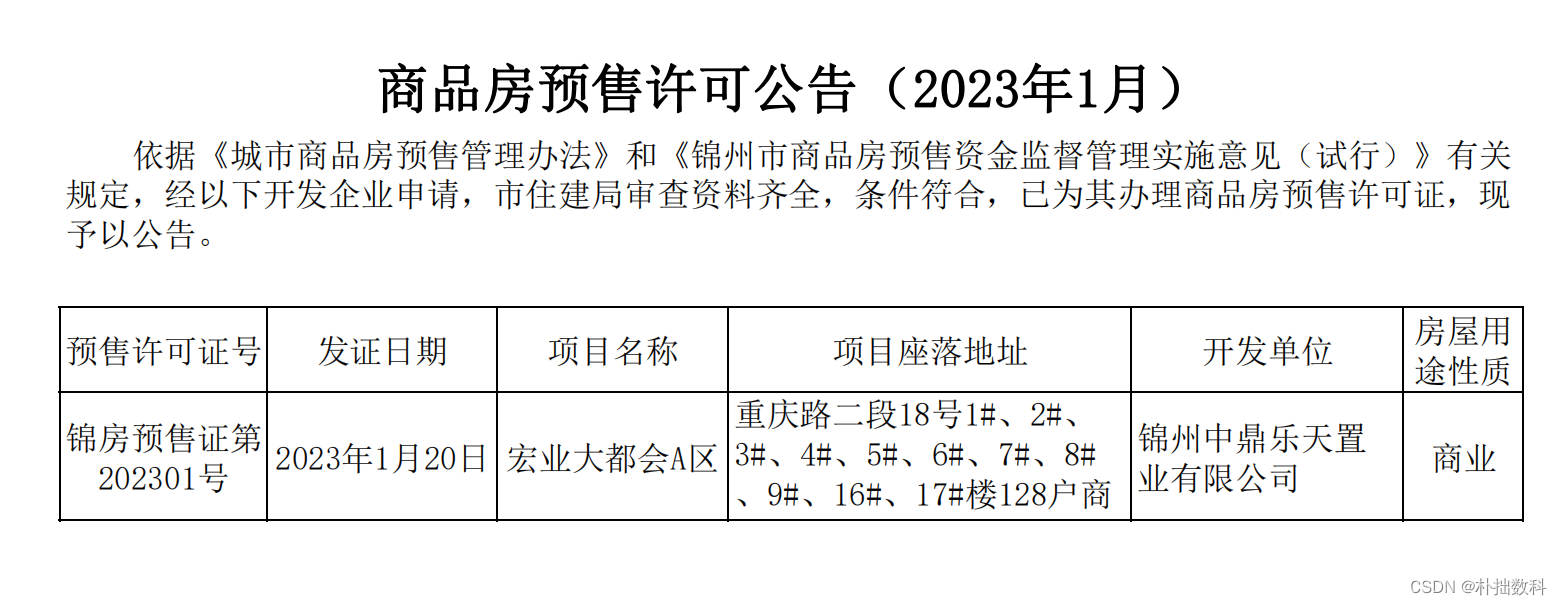
商品房预售许可公告(2023年1月)
依据《城市商品房预售管理办法》和《锦州市商品房预售资金监督管理实施意见(试行)》有关
规定,经以下开发企业申请,市住建局审查资料齐全,条件符合,已为其办理商品房预售许可证,现
予以公告。
预售许可证号发证日期 项目名称 项目座落地址 开发单位房屋用
途性质
锦房预售证第
202301号2023年1月20日宏业大都会A区重庆路二段18号1#、2#、
3#、4#、5#、6#、7#、8#
、9#、16#、17#楼128户商
业锦州中鼎乐天置
业有限公司商业
pdfminer:一种用于提取 PDF 中文本和元数据的 Python 库。
使用 pdfminer 需要安装 pdfminer 库,可以通过以下命令安装:
pip install pdfminer
然后,可以使用以下代码提取 PDF 中的文本:
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from pdfminer.pdfpage import PDFPage
from io import StringIO
# 打开 PDF 文件
with open('example.pdf', 'rb') as f:
rsrcmgr = PDFResourceManager()
retstr = StringIO()
laparams = LAParams()
device = TextConverter(rsrcmgr, retstr, laparams=laparams)
interpreter = PDFPageInterpreter(rsrcmgr, device)
# 读取 PDF 中的文本
for page in PDFPage.get_pages(f):
interpreter.process_page(page)
text = retstr.getvalue()
print(text)
商品房预售许可公告(2023年1月)
依据《城市商品房预售管理办法》和《锦州市商品房预售资金监督管理实施意见(试行)》有关
规定,经以下开发企业申请,市住建局审查资料齐全,条件符合,已为其办理商品房预售许可证,现
予以公告。
预售许可证号 发证日期
项目名称
项目座落地址
开发单位
锦房预售证第
202301号
2023年1月20日 宏业大都会A区
重庆路二段18号1#、2#、
3#、4#、5#、6#、7#、8#
、9#、16#、17#楼128户商
业
锦州中鼎乐天置
业有限公司
textract:一种用于提取 PDF 中文本和元数据的 Python 库,支持多种文件格式。
使用 textract 需要安装 textract 库和相应的依赖库,可以通过以下命令安装:
pip install textract
sudo apt-get install python-dev libxml2-dev libxslt1-dev antiword unrtf poppler-utils pstotext tesseract-ocr flac ffmpeg lame libmad0 libsox-fmt-mp3 sox libjpeg-dev swig
然后,可以使用以下代码提取 PDF 中的文本:
import textract
# 读取 PDF 中的文本
text = textract.process('example.pdf', method='tesseract', language='chi_sim')
print(text)
OCR.space API:一种基于云的 OCR 服务,提供了 Python API。使用 OCR.space API 需要注册 OCR.space 帐户并获取 API 密钥,然后可以使用以下代码进行 OCR 识别:
import requests
# OCR.space API 的 URL 和 API 密钥
url = 'https://api.ocr.space/parse/image'
api_key = 'YOUR_API_KEY'
# 读取 PDF 中的图像
pages = convert_from_path('example.pdf')
# 识别 PDF 中的文本
text = ''
for page in pages:
# 将图像上传到 OCR.space API 进行识别
response = requests.post(url, files={'file': ('image.png', page, 'image/png')}, data={'apikey': api_key})
# 解析 OCR.space API 的响应,并获取识别结果
result = response.json()
if result['IsErroredOnProcessing']:
print(result['ErrorMessage'])
else:
text += result['ParsedResults'][0]['ParsedText']
print(text)
PyMuPDF:一种用于处理 PDF 文件的 Python 库,可以用于进行 PDF OCR 识别和文字搜索。
使用 PyMuPDF 需要安装 PyMuPDF 库,可以通过以下命令安装:
pip install PyMuPDF
然后,可以使用以下代码进行 PDF OCR 识别:
import fitz
# 打开 PDF 文件
doc = fitz.open('example.pdf')
# 对 PDF 进行 OCR 识别
for page in doc:
page.run_ocr()
text = page.get_text()
print(text)
也可以使用以下代码进行 PDF 文字搜索:
import fitz
# 打开 PDF 文件
doc = fitz.open('example.pdf')
# 搜索 PDF 中的文本
for page in doc:
text_instances = page.search_for('search_text')
for inst in text_instances:
highlight = page.add_highlight_annot(inst)
highlight.update()
# 保存修改后的 PDF 文件
doc.save('example_highlighted.pdf')
pdfplumber:一种用于提取 PDF 中文本和元数据的 Python 库,支持多种文件格式。使用 pdfplumber 需要安装 pdfplumber 库,可以通过以下命令安装:
pip install pdfplumber
然后,可以使用以下代码进行 PDF OCR 识别:
import pdfplumber
# 打开 PDF 文件
with pdfplumber.open('example.pdf') as pdf:
# 对 PDF 进行 OCR 识别
for page in pdf.pages:
text = page.extract_text()
print(text)
# 也可以使用以下代码进行 PDF 文字搜索:
import pdfplumber
# 打开 PDF 文件
with pdfplumber.open('example.pdf') as pdf:
# 搜索 PDF 中的文本
for page in pdf.pages:
text_instances = page.find('search_text')
for inst in text_instances:
page.add_rectangle(inst['x0'], inst['top'], inst['x1'], inst['bottom'], fill=None, stroke_width=1)
# 保存修改后的 PDF 文件
pdf.save('example_highlighted.pdf')
商品房预售许可公告(2023年1月)
依据《城市商品房预售管理办法》和《锦州市商品房预售资金监督管理实施意见(试行)》有关
规定,经以下开发企业申请,市住建局审查资料齐全,条件符合,已为其办理商品房预售许可证,现
予以公告。
房屋用
预售许可证号 发证日期 项目名称 项目座落地址 开发单位
途性质
重庆路二段18号1#、2#、
锦房预售证第 锦州中鼎乐天置
2023年1月20日 宏业大都会A区 3#、4#、5#、6#、7#、8# 商业
202301号 业有限公司
、9#、16#、17#楼128户商
业
PyPDF2:一种用于处理 PDF 文件的 Python 库,可以用于进行 PDF OCR 识别和文字搜索。使用 PyPDF2 需要安装 PyPDF2 库,可以通过以下命令安装:
pip install PyPDF2
然后,可以使用以下代码进行 PDF OCR 识别:
import PyPDF2
# 打开 PDF 文件
with open('example.pdf', 'rb') as f:
pdf_reader = PyPDF2.PdfReader(f)
# 对 PDF 进行 OCR 识别
for page in pdf_reader.pages:
text = page.extract_text()
print(text)
也可以使用以下代码进行 PDF 文字搜索:
import PyPDF2
# 打开 PDF 文件
with open('example.pdf', 'rb') as f:
pdf_reader = PyPDF2.PdfReader(f)
# 搜索 PDF 中的文本
for page in pdf_reader.pages:
if 'search_text' in page.extract_text():
# TODO: 处理搜索结果
pass
商品房预售许可公告(2023年1月)
依据《城市商品房预售管理办法》和《锦州市商品房预售资金监督管理实施意见(试行)》有关
规定,经以下开发企业申请,市住建局审查资料齐全,条件符合,已为其办理商品房预售许可证,现
予以公告。
预售许可证号发证日期 项目名称 项目座落地址 开发单位房屋用
途性质
锦房预售证第
202301号2023年1月20日宏业大都会A区重庆路二段18号1#、2#、
3#、4#、5#、6#、7#、8#
、9#、16#、17#楼128户商
业锦州中鼎乐天置
业有限公司商业
Adobe Acrobat DC Pro:Adobe Acrobat DC Pro 是一款功能强大的 PDF 编辑器,可以用于进行 PDF OCR 识别和文字搜索。
可以使用 Python 调用 Adobe Acrobat DC Pro 的 COM 接口来进行操作。具体步骤如下:
首先,需要在 Windows 系统中安装 Adobe Acrobat DC Pro,并打开“编辑”-“首选项”-“JavaScript”选项卡,启用“对外部 JavaScript 的调用”选项。
然后,可以使用以下代码进行 PDF OCR 识别:
import win32com.client
# 创建 Adobe Acrobat DC Pro 的 COM 对象
acrobat = win32com.client.Dispatch('AcroExch.App')
# 打开 PDF 文件
doc = win32com.client.Dispatch('AcroExch.PDDoc')
doc.Open('example.pdf')
# 对 PDF 进行 OCR 识别
for i in range(doc.GetNumPages()):
page = doc.AcquirePage(i)
pageOCR = win32com.client.Dispatch('AcroOCRPage')
pageOCR.tesseractLanguage = 'chi_sim'
pageOCR.bRecognizeText = True
pageOCR.Recognize(page)
text = pageOCR.GetText()
print(text)
也可以使用以下代码进行 PDF 文字搜索:
import win32com.client
# 创建 Adobe Acrobat DC Pro 的 COM 对象
acrobat = win32com.client.Dispatch('AcroExch.App')
# 打开 PDF 文件
doc = win32com.client.Dispatch('AcroExch.PDDoc')
doc.Open('example.pdf')
# 搜索 PDF 中的文本
search_text = 'search_text'
search = win32com.client.Dispatch('AcroExch.PDTextSelect')
search.pageNum = 0
search.charIndex = 0
search.query(search_text)
while search.findNext():
# TODO: 处理搜索结果
pass
Tika:一种用于提取 PDF 中文本和元数据的 Python 库,支持多种文件格式。使用 Tika 需要安装 Tika 库和 Java 运行环境,可以通过以下命令安装:
pip install tika
sudo apt-get install default-jdk
然后,可以使用以下代码进行 PDF OCR 识别:
from tika import parser
# 读取 PDF 文件
with open('example.pdf', 'rb') as f:
# 对 PDF 进行 OCR 识别
text = parser.from_file(f, language='chi_sim')['content']
print(text)
也可以使用以下代码进行 PDF 文字搜索:
from tika import parser
# 读取 PDF 文件
with open('example.pdf', 'rb') as f:
# 搜索 PDF 中的文本
search_text = 'search_text'
text = parser.from_file(f, xmlContent=True)['content']
if search_text in text:
# TODO: 处理搜索结果
pass
以上是Python 进行 PDF OCR 识别和文字搜索的方法,包括调用 Adobe Acrobat DC Pro 的方法,你可以根据具体需求选择适合自己的方法。
可以使用百度 OCR API 将 PDF 转成图片,然后再使用 OCR API 进行文字识别。具体步骤如下:
安装百度 OCR SDK
首先,需要在 Python 环境中安装百度 OCR SDK。可以使用以下命令安装:
pip install baidu-aip
获取百度 OCR API 的 APP ID、API Key 和 Secret Key
在使用百度 OCR API 进行文字识别之前,需要先获取 APP ID、API Key 和 Secret Key。具体步骤如下:
在百度开发者中心创建一个账号,并登录。
在控制台中创建一个新的 OCR 应用,并获取 APP ID、API Key 和 Secret Key。
将 PDF 转成图片
可以使用 PyMuPDF 库将 PDF 转成图片,具体步骤如下:
import fitz
打开 PDF 文件
doc = fitz.open(‘example.pdf’)
将 PDF 转成图片
for i in range(doc.page_count):
page = doc[i]
pix = page.get_pixmap()
pix.writePNG(f’page_{i+1}.png’)
在上面的代码中,使用 fitz.open() 函数打开 PDF 文件,然后使用 page.get_pixmap() 函数将 PDF 中的每一页转换为图片,并使用 pix.writePNG() 函数将图片保存为 PNG 格式。
使用百度 OCR API 进行文字识别
可以使用百度 OCR SDK 的 AipOcr 类进行文字识别,具体步骤如下:
from aip import AipOcr
初始化百度 OCR API
APP_ID = ‘your_app_id’
API_KEY = ‘your_api_key’
SECRET_KEY = ‘your_secret_key’
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
读取图片文件
with open(‘page_1.png’, ‘rb’) as f:
image = f.read()
调用百度 OCR API 进行文字识别
result = client.basicGeneral(image)
if ‘words_result’ in result:
for item in result[‘words_result’]:
print(item[‘words’])
在上面的代码中,使用 AipOcr 类初始化百度 OCR API,并调用 client.basicGeneral() 函数进行文字识别。在调用 client.basicGeneral() 函数时,需要传入图片的二进制数据,可以使用 Python 内置的 open() 函数读取图片文件,并将其转换为二进制格式。
OCR API 可以返回识别结果的 JSON 数据,包含识别结果、置信度等信息。在上面的代码中,可以通过遍历 result[‘words_result’] 列表获取识别结果。
完整代码示例:
初始化百度 OCR API
from pdf2image import convert_from_path
from aip import AipOcr
import os
APP_ID = '--'
API_KEY = '--'
SECRET_KEY = '--'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
def baidu_ocr(fname):
f = open('result.txt', 'w', encoding='utf-8')
dirname = fname.rsplit('.', 1)[0]
if not os.path.exists(dirname):
os.mkdir(dirname)
images = convert_from_path(fname, fmt='png', output_folder=dirname)
for img in images:
with open(img.filename, 'rb') as fimg:
img = fimg.read() # 根据'PIL.PngImagePlugin.PngImageFile'对象的filename属性读取图片为二进制
msg = client.basicGeneral(img)
for i in msg.get('words_result'):
f.write('{}\n'.format(i.get('words')))
f.write('\f\n')
f.close()
baidu_ocr('example4.pdf')
甬金铁路涉及220千伏岩礼4R92线岩泉4R93线#21-#23塔迁改工程中标结果公
告
(招标编号:ZJGZDI.-2023-04-02)
一、中标人信息:
标段(包)[001]甬金铁路涉及220千伏岩礼4R92线岩泉4R93线#21-#23塔迁改工程:
中标人:绍兴建元电力集团有限公司
中标费率:下浮3.50%
二、其他:
绍兴建元电力集团有限公司为中标人
三、监督部门
本招标项目的监督部门为绍兴电力局招投标管理中心。
四、联系方式
招标人:嵊州市铁路项目工程建设指挥部
地址:绍兴嵊州市
联系人:吕先旺
电话:1S069621508
电子邮件:544142621@q4.c0m
招标代理机构:浙江广正建设项日管理有限公司
地址:浙江省绍兴市越城区阳明北路$0号A楼四楼1
联系人:高强
电话:13867532448
电子邮件:734201819@44.com
招标人或其招标代理机构主要负责人
招标人或其招标纸理机
(盖章)
/
在上面的代码中,使用 io.BytesIO() 函数将图片转换为字节流,并调用百度 OCR API 进行文字识别。最后,将识别结果输出到控制台。