之前翻译了这篇论文,但是理解还不深。今天借着研究rotation的计划,回顾这篇文章。
论文的主要贡献
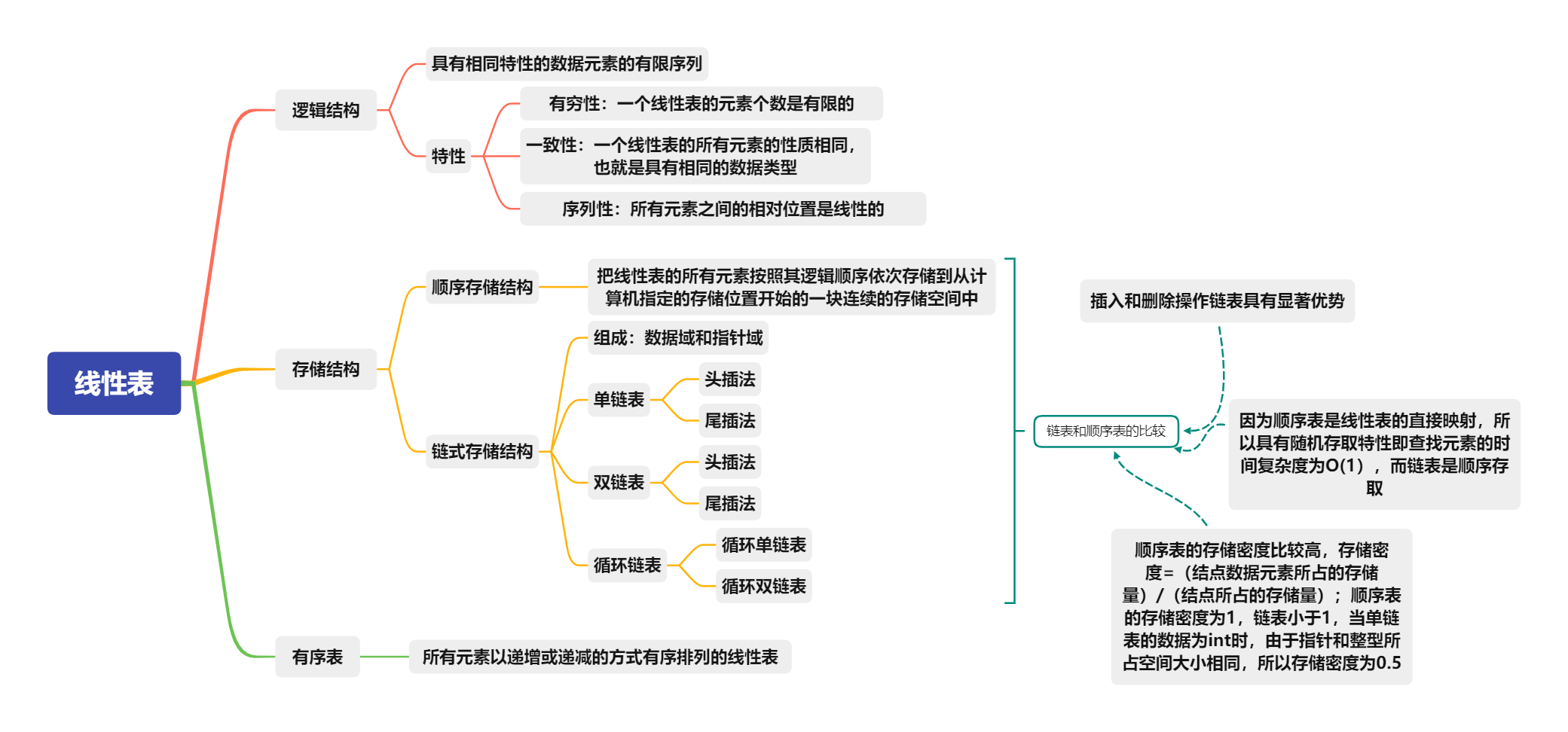
Focal loss主要是为了解决目标检测中正负样本比例严重失衡的问题。该损失函数降低了大量简单负样本在训练中所占的权重,也可理解为一种困难样本挖掘。
1、类class不平衡
我们发现,在密集探测器dense detectors的训练过程中遇到:1、 极端的地面背景类 ground-background class 不平衡是主要原因。2、 前景(positive)和背景(negatives)类别的不平衡问题。解决此class失衡问题,通过重塑标准的交叉熵损失, 它降低了分配给分类良好的示例的损失(it down-weights the loss assigned to well-classified examples)。提出了一种叫做Focal Loss的损失函数,Focal Loss 将训练重点放在稀疏的困难例子集上
防止产生大量 easy negatives
用来降低大量easy negatives在标准交叉熵中所占权重
提高hard negatives所占权重
2、提出了RetinaNet
为了评估损失的有效性,我们设计并训练了一个简单的密集检测器,我们称之为RetinaNet。
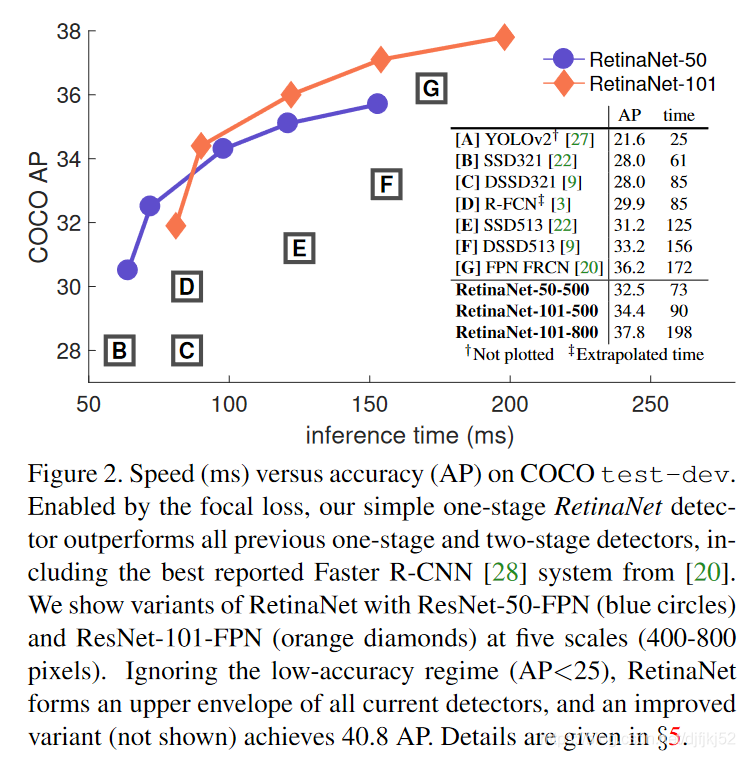
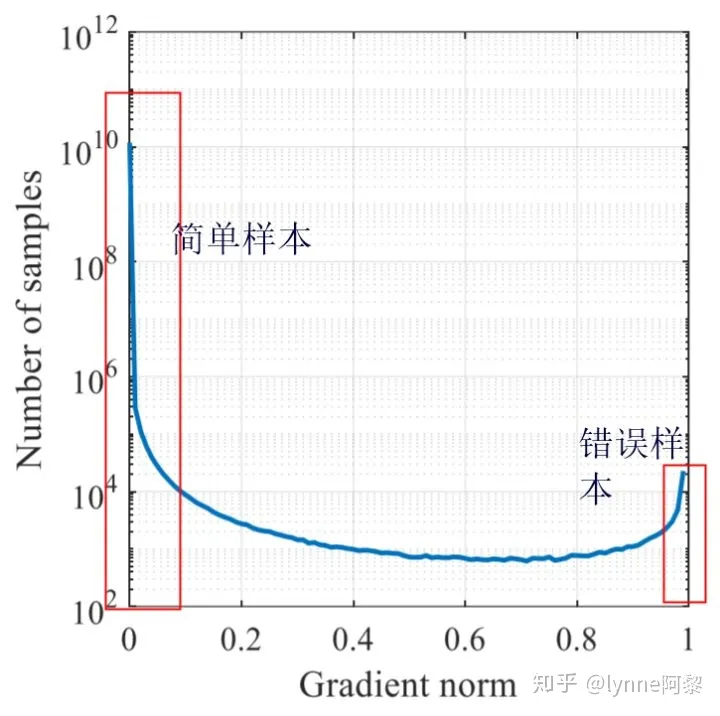
模型在测试数据集中的梯度分布
这里我们来看一张收敛的模型在测试数据集中的梯度分布。最左边梯度接近于0就是简单样本,简单样本的数量很多。中间部分是一些不同难度的样本,最右边就是loss很大的困难样本,这些样本在数量上相对于简单样本是非常少的,所以即使他们的梯度很大,但是如果使用交叉熵,那么他们对loss的贡献还是很少,所以他们还是很难学。
图片来源
下图是文中所给的不同样本的loss分布,还是如我们刚才所讨论的。这些易分的样本loss虽然不高但是数量很多,所以导致困难样本的loss容易被这些简单样本所覆盖,导致他们更加难学习。而引入focal loss之后可以看到我们降低了简单样本的loss,从而提高了他们对梯度的贡献。那么什么是focal loss呢,我们下面将着重介绍focal loss.
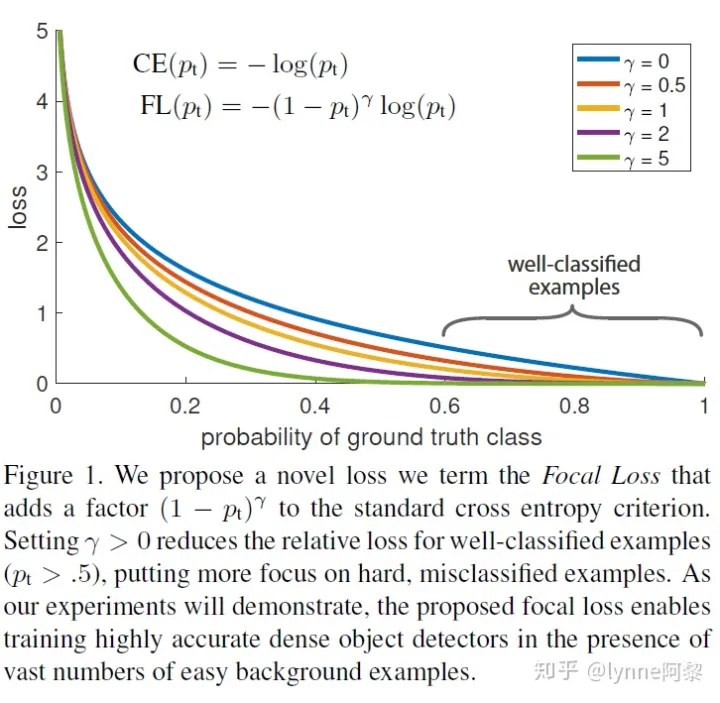
focal loss 是一种思想,可以和CE结合,也可以和其他损失结合
二分类问题Focal loss计算如下
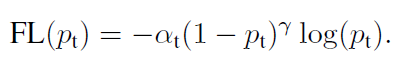
当然Focal loss对多分类的任务也同样适用。
不适合 focal loss 的分析
参考
focal loss论文 揭示了目标检测的核心问题:正负样本分布极端不均衡并由此导致的大量简单负样本占据了loss(梯度、或者training过程),作者由此设计了focal loss,以及训练focal loss的网络结构retinanet以及一系列训练中需要注意的点。
但是focal loss并不是万能的,在很多场景下,比如单多标签分类上不一定好使,不仅仅是因为α,γ参数不好整,更重要的是,在pt高的时候,pred和gt越接近(置信度越高),focal的越狠,如果不是负样本中有大量的easy example的话,这种focal对容易学的样本都产生了很大的降权,损失有很能被难例主导,简单和难例的损失权重是不对等的,噪声比较大的样本不一定能学明白,还有可能降点。这种对简单样本降权有点像margin的那味。
思考:是否适合做数值回归?
看论文【论文】Focal-EIOU Loss:Focal and Efficient IOU Loss for Accurate Bounding Box Regression 用于精确边界框回归,是可行的。
论文中的结论:
实验结果表明:
引入的边长损失以及Focal L1损失函数的设计增加了IoU目标的损失和梯度,进而提高了bbox回归精度。
Focal L1损失函数它根据猜想的损失函数梯度所具有的属性,设计了损失函数的梯度,再反向积分得到这个损失函数起到了很好的效果。
但是实验表明Focal_EIOU并不存在某个损失函数在所有数据集上碾压其它损失函数,还要依赖于数据集的分布,锚点框的设计,检测算法的设计等等诸多因素,在特定的任务下需要多做尝试才能知道选择哪个边界框损失函数。
代码分析
分析