文章目录
- 0.引言
- 1. 数据集设置
- 1.1. dataset implementation py
- 1.2. dataset config py
- 2.模型设置
- 3.训练
0.引言
\qquad 本文是mmSegmentation语义分割框架教程(0.x版本)的1.x版本。不熟悉mmsegmentation是什么的读者可参考原文的引言部分,熟悉之后即可阅读本文。本文重点介绍使用mmsegmentation已有的模型快速搭建训练和测试自定义数据集的功能,全部功能请参考mmsegmentation的GitHub。
\qquad 与0.x版本类似,1.x版本的重点仍然是在使用配置文件上,分为四个部分
- dataset config
- model config
- runtime config
- schedule config
如果只是实现基本功能,那只需要重点关注前两类config即可。
1. 数据集设置
| config files | implementation files |
|---|---|
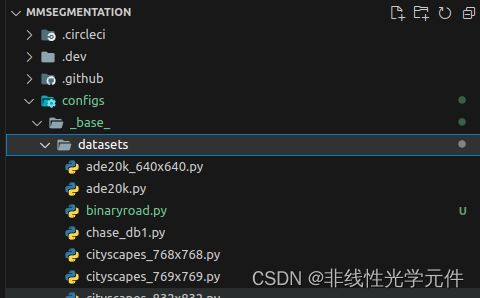 | 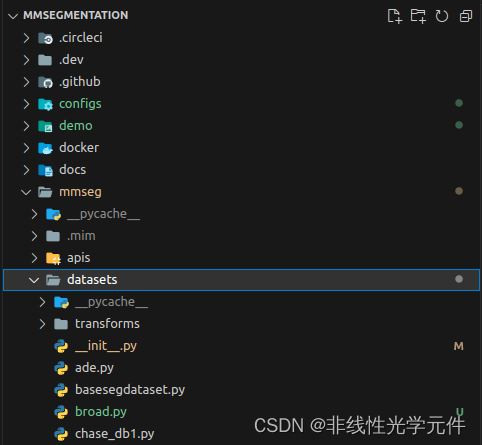 |
与0.x的版本类似,如上图,mmsegmentation的dataset的功能实现(implement)部分放在mmseg/datasets的文件夹中,而config部分放在configs/base/datasets的文件夹中。因此需要先定义一个简单的数据集implementation的py文件,再设置数据集config的py文件。
1.1. dataset implementation py
第一步,把新定义的数据集文件放在mmseg/datasets/文件夹中,下图是一个demo (broad.py):
# Copyright (c) OpenMMLab. All rights reserved.
from mmseg.registry import DATASETS
from .basesegdataset import BaseSegDataset
@DATASETS.register_module()
class BinaryRoadDataset(BaseSegDataset):
"""Cityscapes dataset.
The ``img_suffix`` is fixed to '.jpg' and ``seg_map_suffix`` is
fixed to '.jpg' for BinaryRoad dataset.
"""
METAINFO = dict(
classes=('background', 'road'),
palette=[[0,0,0], [244, 35, 232]])
def __init__(self,
img_suffix='.jpg',
seg_map_suffix='.jpg',
**kwargs) -> None:
super().__init__(
img_suffix=img_suffix, seg_map_suffix=seg_map_suffix, **kwargs)
需要注意的点不多:
- suffix: 需要与原图片suffix和分割图片的suffix一致,目前只尝试过jpg和png格式的seg_map_suffix,seg_map是灰度图像,默认从0开始算标签,整形,尺寸大小与原图一致。
- classes & palette:classes是标签的类别名,会以字符串形式显示在log中,palette是标签visualize时的半透明颜色,训练和测试的时候不重要但是必须要有。
第二步,修改同目录下的__init__文件,修改的也不多:
# Copyright (c) OpenMMLab. All rights reserved.
# yapf: disable
from .ade import ADE20KDataset
from .basesegdataset import BaseSegDataset
from .chase_db1 import ChaseDB1Dataset
from .cityscapes import CityscapesDataset
from .coco_stuff import COCOStuffDataset
from .dark_zurich import DarkZurichDataset
from .dataset_wrappers import MultiImageMixDataset
from .decathlon import DecathlonDataset
from .drive import DRIVEDataset
from .hrf import HRFDataset
from .isaid import iSAIDDataset
from .isprs import ISPRSDataset
from .lip import LIPDataset
from .loveda import LoveDADataset
from .mapillary import MapillaryDataset_v1, MapillaryDataset_v2
from .night_driving import NightDrivingDataset
from .pascal_context import PascalContextDataset, PascalContextDataset59
from .potsdam import PotsdamDataset
from .refuge import REFUGEDataset
from .stare import STAREDataset
from .synapse import SynapseDataset
# yapf: disable
from .transforms import (CLAHE, AdjustGamma, BioMedical3DPad,
BioMedical3DRandomCrop, BioMedical3DRandomFlip,
BioMedicalGaussianBlur, BioMedicalGaussianNoise,
BioMedicalRandomGamma, GenerateEdge, LoadAnnotations,
LoadBiomedicalAnnotation, LoadBiomedicalData,
LoadBiomedicalImageFromFile, LoadImageFromNDArray,
PackSegInputs, PhotoMetricDistortion, RandomCrop,
RandomCutOut, RandomMosaic, RandomRotate,
RandomRotFlip, Rerange, ResizeShortestEdge,
ResizeToMultiple, RGB2Gray, SegRescale)
from .voc import PascalVOCDataset
from .broad import BinaryRoadDataset # add custom dataset
# yapf: enable
__all__ = [
'BaseSegDataset', 'BioMedical3DRandomCrop', 'BioMedical3DRandomFlip',
'CityscapesDataset', 'PascalVOCDataset', 'ADE20KDataset',
'PascalContextDataset', 'PascalContextDataset59', 'ChaseDB1Dataset',
'DRIVEDataset', 'HRFDataset', 'STAREDataset', 'DarkZurichDataset',
'NightDrivingDataset', 'COCOStuffDataset', 'LoveDADataset',
'MultiImageMixDataset', 'iSAIDDataset', 'ISPRSDataset', 'PotsdamDataset',
'LoadAnnotations', 'RandomCrop', 'SegRescale', 'PhotoMetricDistortion',
'RandomRotate', 'AdjustGamma', 'CLAHE', 'Rerange', 'RGB2Gray',
'RandomCutOut', 'RandomMosaic', 'PackSegInputs', 'ResizeToMultiple',
'LoadImageFromNDArray', 'LoadBiomedicalImageFromFile',
'LoadBiomedicalAnnotation', 'LoadBiomedicalData', 'GenerateEdge',
'DecathlonDataset', 'LIPDataset', 'ResizeShortestEdge',
'BioMedicalGaussianNoise', 'BioMedicalGaussianBlur',
'BioMedicalRandomGamma', 'BioMedical3DPad', 'RandomRotFlip',
'SynapseDataset', 'REFUGEDataset', 'MapillaryDataset_v1',
'MapillaryDataset_v2',"BinaryRoadDataset"
] # add custom dataset
- from … import …处添加自定义数据集类
__all__变量添加类名(为了兼容yapf,这里就不展开了)
1.2. dataset config py
只需要一步操作即可,添加一个父级config,放在configs/_base_/datasets/下 (binaryroad.py)
# dataset settings
dataset_type = 'BinaryRoadDataset' # must be the same name of custom dataset
data_root = '' # subconfig file must define this path
crop_size = (1080, 1440) # raw image size (H, W), subconfig file can overwrite
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations'),
dict(
type='Resize',
scale=crop_size,
keep_ratio=True),
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
dict(type='RandomFlip', prob=0.5),
dict(type='PhotoMetricDistortion'),
dict(type='PackSegInputs')
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='Resize', scale=crop_size, keep_ratio=True),
# add loading annotation after ``Resize`` because ground truth
# does not need to do resize data transform
dict(type='LoadAnnotations'),
dict(type='PackSegInputs')
]
img_ratios = [0.5, 0.75, 1.0, 1.25, 1.5, 1.75]
tta_pipeline = [
dict(type='LoadImageFromFile', backend_args=None),
dict(
type='TestTimeAug',
transforms=[
[
dict(type='Resize', scale_factor=r, keep_ratio=True)
for r in img_ratios
],
[
dict(type='RandomFlip', prob=0., direction='horizontal'),
dict(type='RandomFlip', prob=1., direction='horizontal')
], [dict(type='LoadAnnotations')], [dict(type='PackSegInputs')]
])
]
train_dataloader = dict(
batch_size=4,
num_workers=4,
persistent_workers=True,
sampler=dict(type='InfiniteSampler', shuffle=True),
dataset=dict(
type=dataset_type,
data_root=data_root,
data_prefix=dict(
img_path='img/train', seg_map_path='ann/train'),
pipeline=train_pipeline))
val_dataloader = dict(
batch_size=1,
num_workers=4,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=False),
dataset=dict(
type=dataset_type,
data_root=data_root,
data_prefix=dict(
img_path='img/val', seg_map_path='ann/val'),
pipeline=test_pipeline))
test_dataloader = dict(
batch_size=1,
num_workers=4,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=False),
dataset=dict(
type=dataset_type,
data_root=data_root,
data_prefix=dict(
img_path='img/test', seg_map_path='ann/test'),
pipeline=test_pipeline))
val_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU'], ignore_index=2)
test_evaluator = val_evaluator
下面是一些重要参数的解释:
dataset_type:必须和自定义数据集类名称完全一致data_root:数据集根目录,后续所有的pipeline使用的目录都会在此目录下的子目录读取pipeline: type='Reisze’是直接将图片Resize到指定大小(HxW),也可以使用1.x提供的RandomResize,有兴趣的读者可以去原项目提供的例程学习。dataloader:shuffle=True是打乱图片,一般训练集要求打乱图片训练增加随机性,val和test则不需要。num_workers和pytorch的定义差不多,使用多进程加载数据,一般num_workers>=4速度提升就不再明显。persistent_workers=True官方的解释也是一种加速图片加载的操作,在这里不展开其原理介绍。data_prefix:图片前缀,也可以包含路径。以data_root为子目录。按照上述的设置,训练集图片放在data_root/img/train下,训练集标签放在data_root/ann/train下。使用Linux的读者可以直接使用软连接的方式链接原路径下的文件,在不影响训练的同时还节省了磁盘空间。evaluator:分割指标评估器,ignore_index是忽略seg_map中像素值为xxx的点的metric性能指标。在1.x的更新文档中,相较0.x版本改善了IoU Metric的计算速度。- 如若不需要测试集,可将其直接设为验证集。
2.模型设置
第一步,在configs/下找一个基准模型,这里我找的是HRNet,其他的网络设置类似:
根据基准模型的其他配置文件自己写一个配置文件,注意,这个配置文件就是最TopLevel的配置文件。
demo(fcn_hr18_4xb2-20k_binaryroad_480_640.py)如下:
_base_ = [
'../_base_/models/fcn_hr18.py', '../_base_/datasets/binaryroad.py',
'../_base_/default_runtime.py', '../_base_/schedules/schedule_20k.py'
]
crop_size = (480, 640)
data_preprocessor = dict(size=crop_size)
model = dict(data_preprocessor=data_preprocessor)
norm_cfg = dict(type='BN', requires_grad=True)
train_dataloader = dict(
batch_size=2)
需要注意的是:
- 由于包含
_base_变量,该文件的放置路径不要随意更改,应该和configs/_base_目录是同级关系 - TopLevel的配置文件设置的dict自动覆盖子配置文件的config,与python字典的
.update()函数类似
常用参数解释:
- norm_cfg:如果是单GPU,应该设’BN’,否则设’SynBN’(默认)
- crop_size: 图片crop大小,在我的配置中,也是Resize后的图片大小,设的比原图片小可以减小训练时的内存占用,但Inference时也应执行相同的操作
- data_preprocessor: 1.x新增加的类型,我复制的其他config的配置
- batch_size:验证集和测试集都应该设为1,训练集的batch_size大小依据GPU内存而定,如果出现OOM内存溢出错误,就设置的小一些。但需要注意
batch_size不要设1,部分pytorch版本的BatchNormalization操作不支持batch_size=1 - schedule config: 这里的schedule_20k.py设置的iteration=20k,iteration是训练的次数,按batch计算的,和数据集大小无关。例如
batch_size=2,iteration=20k,相当于送入网络训练了40k张图片。 - runtime config:可查看对应文件进行阅读,只是一些log和visualization的设置,一般不需要修改
3.训练
至于一行命令即可,在mmsegmentation的根目录执行:
python tools/train.py configs/hrnet/fcn_hr18_4xb2-40k_binaryroad_480_640.py --work-dir work_dir
--work-dir是保存记录文件及checkpoint的路径。如果中途训练终端了,还可以–resume进行继续训练,也可以使用load-from参数load一个已经训练的模型(但是iteration会置0)
work_dir中的文件截图如下:
我把前几代iteration的checkpoint删掉了,deploy文件夹和mmdeploy_onnxrun是我新加的,后续会介绍。
与 MMSeg 0.x 相比,MMSeg 1.x 在 tools/train.py 中提供的命令行参数更少。
关于如何加载模型和断点继续训练,我把官方的Markdown拷贝如下:
| 功能 | 原版(0.x) | 新版(1.x) |
| 加载预训练模型 | --load_from=$CHECKPOINT | --cfg-options load_from=$CHECKPOINT |
| 从特定检查点恢复训练 | --resume-from=$CHECKPOINT | --resume=$CHECKPOINT |
| 从最新的检查点恢复训练 | --auto-resume | --resume='auto' |
| 训练期间是否不评估检查点 | --no-validate | --cfg-options val_cfg=None val_dataloader=None val_evaluator=None |
| 指定训练设备 | --gpu-id=$DEVICE_ID | - |
| 是否为不同进程设置不同的种子 | --diff-seed | --cfg-options randomness.diff_rank_seed=True |
| 是否为 CUDNN 后端设置确定性选项 | --deterministic | --cfg-options randomness.deterministic=True |