【深度学习入门到进阶】必看系列,含激活函数、优化策略、损失函数、模型调优、归一化算法、卷积模型、序列模型、预训练模型、对抗神经网络等

专栏详细介绍:【深度学习入门到进阶】必看系列,含激活函数、优化策略、损失函数、模型调优、归一化算法、卷积模型、序列模型、预训练模型、对抗神经网络等
本专栏主要方便入门同学快速掌握相关知识。声明:部分项目为网络经典项目方便大家快速学习,后续会不断增添实战环节(比赛、论文、现实应用等)
专栏订阅:深度学习入门到进阶专栏
深度学习进阶篇-预训练模型[1]:预训练分词Subword、ELMo、Transformer模型原理;结构;技巧以及应用详解
从字面上看,预训练模型(pre-training model)是先通过一批语料进行训练模型,然后在这个初步训练好的模型基础上,再继续训练或者另作他用。这样的理解基本上是对的,预训练模型的训练和使用分别对应两个阶段:预训练阶段(pre-training)和 微调(fune-tuning)阶段。
预训练阶段一般会在超大规模的语料上,采用无监督(unsupervised)或者弱监督(weak-supervised)的方式训练模型,期望模型能够获得语言相关的知识,比如句法,语法知识等等。经过超大规模语料的”洗礼”,预训练模型往往会是一个Super模型,一方面体现在它具备足够多的语言知识,一方面是因为它的参数规模很大。
微调阶段是利用预训练好的模型,去定制化地训练某些任务,使得预训练模型”更懂”这个任务。例如,利用预训练好的模型继续训练文本分类任务,将会获得比较好的一个分类结果,直观地想,预训练模型已经懂得了语言的知识,在这些知识基础上去学习文本分类任务将会事半功倍。利用预训练模型去微调的一些任务(例如前述文本分类)被称为下游任务(down-stream)。
以BERT为例,BERT是在海量数据中进行训练的,预训练阶段包含两个任务:MLM(Masked Language Model)和NSP (Next Sentence Prediction)。前者类似”完形填空”,在一句中扣出一个单词,然后利用这句话的其他单词去预测被扣出的这个单词;后者是给定两句话,判断这两句话在原文中是否是相邻的关系。
BERT预训练完成之后,后边可以接入多种类型的下游任务,例如文本分类,序列标注,阅读理解等等,通过在这些任务上进行微调,可以获得比较好的实验结果。
1. 预训练分词Subword
1.1Subword介绍
1.1.1分词器是做什么的?
机器无法理解文本。当我们将句子序列送入模型时,模型仅仅能看到一串字节,它无法知道一个词从哪里开始,到哪里结束,所以也不知道一个词是怎么组成的。所以,为了帮助机器理解文本,我们需要
-
将文本分成一个个小片段
-
然后将这些片段表示为一个向量作为模型的输入
-
同时,我们需要将一个个小片段(token) 表示为向量,作为词嵌入矩阵, 通过在语料库上训练来优化token的表示,使其蕴含更多有用的信息,用于之后的任务。
1.1.2为什么需要分词?
在NLP任务中,神经网络模型的训练和预测都需要借助词表来对句子进行表示。 传统构造词表的方法,是先对各个句子进行分词,然后再统计并选出频数最高的前N个词组成词表。通常训练集中包含了大量的词汇,以英语为例,总的单词数量在17万到100万左右。 出于计算效率的考虑,通常N的选取无法包含训练集中的所有词。 因而,这种方法构造的词表存在着如下的问题:
-
实际应用中,模型预测的词汇是开放的,对于未在词表中出现的词(Out Of Vocabulary, OOV),模型将无法处理及生成;
-
词表中的低频词/稀疏词在模型训练过程中无法得到充分训练,进而模型不能充分理解这些词的语义;
-
一个单词因为不同的形态会产生不同的词,如由”look”衍生出的”looks”, “looking”, “looked”,显然这些词具有相近的意思,但是在词表中这些词会被当作不同的词处理,一方面增加了训练冗余,另一方面也造成了大词汇量问题。
一种解决思路是使用字符粒度来表示词表,虽然能够解决OOV问题,但单词被拆分成字符后,一方面丢失了词的语义信息,另一方面,模型输入会变得很长,这使得模型的训练更加复杂难以收敛。
1.1.3分词方法
分词的方法有很多,主要包括基于空格的分词方法,基于字母的分词方法和基于子词的分词方法,也可以自己设定一些分隔符号或者规则进行分词等等。基于子词的分词方法包括Byte Pair Encoding (BPE), WordPiece和Unigram Language Model。下面的章节会详细介绍这几种方法。
- 基于空格的分词方法
一个句子,使用不同的规则,将有许多种不同的分词结果。我们之前常用的分词方法将空格作为分词的边界。也就是图中的第三种方法。但是,这种方法存在问题,即只有在训练语料中出现的token才能被训练器学习到,而那些没有出现的token将会被 < U N K > <UNK> <UNK>等特殊标记代替,这样将影响模型的表现。如果我们将词典做得足够大,使其能容纳所有的单词。那么词典将非常庞大,产生很大的开销。同时对于出现次数很少的词,学习其token的向量表示也非常困难。除去这些原因,有很多语言不用空格进行分词,也就无法使用基于空格分词的方法。综上,我们需要新的分词方法来解决这些问题。
- 基于字母的分词方法
将每个字符看作一个词。
- 优点
不用担心未知词汇,可以为每一个单词生成词嵌入向量表示。
-
缺点
-
字母本身就没有任何的内在含义,得到的词嵌入向量缺乏含义。
-
计算复杂度提升(字母的数目远大于token的数目)
-
输出序列的长度将变大,对于Bert、CNN等限制最大长度的模型将很容易达到最大值。
-
-
基于子词的分词方法
为了改进分词方法,在 < U N K > <UNK> <UNK>数目和词向量含义丰富性之间达到平衡,提出了Subword Tokenization方法。这种方法的目的是通过一个有限的单词列表来解决所有单词的分词问题,同时将结果中token的数目降到最低。例如,可以用更小的词片段来组成更大的词:
“unfortunately” = “un” + “for” + “tun” + “ate” + “ly”
它的划分粒度介于词与字符之间,比如可以将”looking”划分为”look”和”ing”两个子词,而划分出来的”look”,”ing”又能够用来构造其它词,如”look”和”ed”子词可组成单词”looked”,因而Subword方法能够大大降低词典的大小,同时对相近词能更好地处理。
1.2 Byte Pair Encoding (BPE)
BPE最早是一种数据压缩算法,由Sennrich等人于2015年引入到NLP领域并很快得到推广。该算法简单有效,因而目前它是最流行的方法。GPT-2和RoBERTa使用的Subword算法都是BPE。在信号压缩领域中BPE过程可视化如下:

BPE获得Subword的步骤如下:
-
准备足够大的训练语料,并确定期望的Subword词表大小;
-
将单词拆分为成最小单元。比如英文中26个字母加上各种符号,这些作为初始词表;
-
在语料上统计单词内相邻单元对的频数,选取频数最高的单元对合并成新的Subword单元;
-
重复第3步直到达到第1步设定的Subword词表大小或下一个最高频数为1。
下面以一个例子来说明。假设有语料集经过统计后表示为: {‘low’:5,’lower’:2,’newest’:6,’widest’:3},其中数字代表的是对应单词在语料中的频数。
1)拆分单词成最小单元,并初始化词表。这里,最小单元为字符,因而,可得到
语料 | 词表 |
|---|---|
‘low</w>’:5 ‘lower</w>’:2 ‘newest</w>’:6 ‘widest</w>’:3 | l,o,w,e,r,n,s,t,i,d,</w> |
需要注意的是,在将单词拆分成最小单元时,要在单词序列后加上””(具体实现上可以使用其它符号)来表示中止符。在子词解码时,中止符可以区分单词边界。
2)在语料上统计相邻单元的频数。这里,最高频连续子词对”e”和”s”出现了6+3=9次,将其合并成”es”,有
语料 | 词表 |
|---|---|
‘low</w>’:5 ‘lower</w>’:2 ‘newest</w>’:6 ‘widest</w>’:3 | l,o,w,e,r,n,t,i,d,</w>,’es’ |
由于语料中不存在’s’子词了,因此将其从词表中删除,但是预料中还存在‘e’的子词,所以e还不能删除。同时加入新的子词’es’。一增一减,词表大小保持不变。
3)继续统计相邻子词的频数。此时,最高频连续子词对”es”和”t”出现了6+3=9次, 将其合并成”est”,有
语料 | 词表 |
|---|---|
‘low</w>’:5 ‘lower</w>’:2 ‘newest</w>’:6 ‘widest</w>’:3 | l,o,w,e,r,n,i,d,</w>,est |
接着,最高频连续子词对为”est”和””,有
语料 | 词表 |
|---|---|
‘low</w>’:5 ‘lower</w>’:2 ‘newest</w>’:6 ‘widest</w>’:3 | l,o,w,e,r,n,i,d,est</w> |
继续上述迭代直到达到预设的Subword词表大小或下一个最高频的字节对出现频率为1。 |
从上面的示例可以知道,每次合并后词表大小可能出现3种变化:
-
+1,表明加入合并后的新子词,同时原来的2个子词还保留(2个子词分开出现在语料中)。
-
+0,表明加入合并后的新子词,同时原来的2个子词中一个保留,一个被消解(一个子词完全随着另一个子词的出现而紧跟着出现)。
-
-1,表明加入合并后的新子词,同时原来的2个子词都被消解(2个子词同时连续出现)。
实际上,随着合并的次数增加,词表大小通常先增加后减小。
在得到Subword词表后,针对每一个单词,我们可以采用如下的方式来进行编码:
-
将词典中的所有子词按照长度由大到小进行排序;
-
对于单词w,依次遍历排好序的词典。查看当前子词是否是该单词的子字符串,如果是,则输出当前子词,并对剩余单词字符串继续匹配。
-
如果遍历完字典后,仍然有子字符串没有匹配,则将剩余字符串替换为特殊符号输出,如””。
-
单词的表示即为上述所有输出子词。
解码过程比较简单,如果相邻子词间没有中止符,则将两子词直接拼接,否则两子词之间添加分隔符。
- 优点
可以很有效地平衡词典尺寸和编码步骤数(将句子编码所需要的token数量)
- 缺点
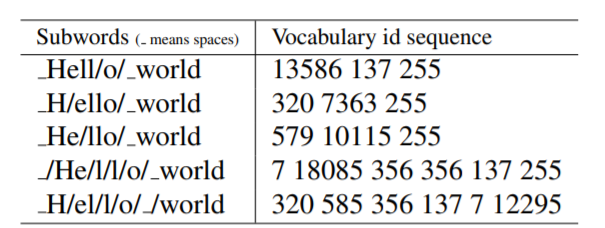
-
对于同一个句子, 例如Hello world,如图所示,可能会有不同的Subword序列。不同的Subword序列会产生完全不同的id序列表示,这种歧义可能在解码阶段无法解决。在翻译任务中,不同的id序列可能翻译出不同的句子,这显然是错误的。
-
在训练任务中,如果能对不同的Subword进行训练的话,将增加模型的健壮性,能够容忍更多的噪声,而BPE的贪心算法无法对随机分布进行学习。
1.3 WordPiece
Google的Bert模型在分词的时候使用的是WordPiece算法。与BPE算法类似,WordPiece算法也是每次从词表中选出两个子词合并成新的子词。与BPE的最大区别在于,如何选择两个子词进行合并:BPE选择频数最高的相邻子词合并,而WordPiece选择能够提升语言模型概率最大的相邻子词加入词表。
假设句子 S = ( t 1 , t 2 , . . . , t n ) S=(t_{1},t_{2},...,t_{n}) S=(t1,t2,...,tn)由n个子词组成, t i t_{i} ti表示子词,且假设各个子词之间是独立存在的,则句子S的语言模型似然值等价于所有子词概率的乘积:
l o g P ( S ) = ∑ i = 1 n l o g P ( t i ) log P(S)=\sum_{i=1}^n logP(t_{i}) logP(S)=i=1∑nlogP(ti)
假设把相邻位置的x和y两个子词进行合并,合并后产生的子词记为z,此时句子似然值的变化可表示为:
l o g P ( t z ) − ( l o g P ( t x ) + l o g P ( t y ) ) = l o g ( P ( t z ) P ( t x ) P ( t y ) ) logP(t_{z})-(logP(t_{x})+logP(t_{y}))=log(\frac{P(t_{z})}{P(t_{x})P(t_{y})}) logP(tz)−(logP(tx)+logP(ty))=log(P(tx)P(ty)P(tz))
从上面的公式,很容易发现,似然值的变化就是两个子词之间的互信息。简而言之,WordPiece每次选择合并的两个子词,他们具有最大的互信息值,也就是两子词在语言模型上具有较强的关联性,它们经常在语料中以相邻方式同时出现。
1.4 Unigram Language Model (ULM)
Unigram模型是Kudo.在论文“Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates”中提出的。当时主要是为了解决机器翻译中分词的问题。作者使用一种叫做marginalized likelihood的方法来建模翻译问题,考虑到不同分词结果对最终翻译结果的影响,引入了分词概率。
与WordPiece一样,Unigram Language Model(ULM)同样使用语言模型来挑选子词。不同之处在于,BPE和WordPiece算法的词表大小都是从小到大变化,属于增量法。而Unigram Language Model则是减量法,即先初始化一个大词表,根据评估准则不断丢弃词表,直到满足限定条件。ULM算法考虑了句子的不同分词可能,因而能够输出带概率的多个子词分段。
对于句子S, x ⃗ = ( x 1 , x 2 , . . . , x m ) \vec x=(x_{1},x_{2},...,x_{m}) x=(x1,x2,...,xm)为句子的一个分词结果,由m个子词组成。所以,当前分词下句子S的似然值可以表示为:
P ( x ⃗ ) = ∏ i = 1 m P ( x i ) P(\vec x)=\prod_{i=1}^m{P(x_{i})} P(x)=i=1∏mP(xi)
对于句子S,挑选似然值最大的作为分词结果,则可以表示为
x ∗ = a r g m a x x ∈ U ( x ) P ( x ⃗ ) x^{*}=arg max_{x \in U(x)} P(\vec x) x∗=argmaxx∈U(x)P(x)
其中 U ( x ) U(x) U(x)包含了句子的所有分词结果。在实际应用中,词表大小有上万个,直接罗列所有可能的分词组合不具有操作性。针对这个问题,可通过维特比算法得到 x ∗ x^* x∗来解决。
那怎么求解每个子词的概率 P ( x i ) P(x_{i}) P(xi)呢?ULM通过EM算法来估计。假设当前词表V, 则M步最大化的对象是如下似然函数:
L = ∑ s = 1 ∣ D ∣ l o g ( P ( X ( s ) ) ) = ∑ s = 1 ∣ D ∣ l o g ( ∑ x ∈ U ( X ( s ) ) P ( x ) ) L=\sum_{s=1}^{|D|}log(P(X^{(s)}))=\sum_{s=1}^{|D|}log(\sum_{x \in U(X^{(s)})}P(x)) L=s=1∑∣D∣log(P(X(s)))=s=1∑∣D∣log(x∈U(X(s))∑P(x))
其中, ∣ D ∣ |D| ∣D∣是语料库中语料数量。上述公式的一个直观理解是,将语料库中所有句子的所有分词组合形成的概率相加。
但是,初始时,词表V并不存在。因而,ULM算法采用不断迭代的方法来构造词表以及求解分词概率:
-
初始时,建立一个足够大的词表。一般,可用语料中的所有字符加上常见的子字符串初始化词表,也可以通过BPE算法初始化。
-
针对当前词表,用EM算法求解每个子词在语料上的概率。
-
对于每个子词,计算当该子词被从词表中移除时,总的loss降低了多少,记为该子词的loss。
-
将子词按照loss大小进行排序,丢弃一定比例loss最小的子词(比如20%),保留下来的子词生成新的词表。这里需要注意的是,单字符不能被丢弃,这是为了避免OOV情况。
-
重复步骤2到4,直到词表大小减少到设定范围。
可以看出,ULM会保留那些以较高频率出现在很多句子的分词结果中的子词,因为这些子词如果被丢弃,其损失会很大。
-
优点
-
使用的训练算法可以利用所有可能的分词结果,这是通过data sampling算法实现的。
-
提出一种基于语言模型的分词算法,这种语言模型可以给多种分词结果赋予概率,从而可以学到其中的噪声。
-
1.5 三种子词分词器的关系

2. ELMo
2.1. ELMo简绍
Deep contextualized word representations 获得了 NAACL 2018 的 outstanding paper award,其方法有很大的启发意义。近几年来,预训练的 word representation 在 NLP 任务中表现出了很好的性能,已经是很多 NLP 任务不可或缺的一部分,论文作者认为一个好的 word representation 需要能建模以下两部分信息:单词的特征,如语义,语法;单词在不同语境下的变化,即一词多义。基于这样的动机,作者提出了 ELMo 模型。ELMo 能够训练出来每个词的 embedding,可以作为上下文相关的词的向量。其他几个贡献:
-
使用字符级别的 CNN 表示。由于单词级别考虑数据可能稀疏,出现 OOV 问题,拆成字符后稀疏性没有那么强了,刻画的会更好。
-
训练了从左到右或从右到左的语言模型。用这个语言模型输出的结果,直接作为词的向量。
-
contextualized:这是一个语言模型,其双向 LSTM 产生的词向量会包含左侧上文信息和右侧下文信息,所以称之为 contextualized
-
deep:句子中每个单词都能得到对应的三个 Embedding: 最底层是单词的 Word Embedding,往上走是第一层双向 LSTM 中对应单词位置的 Embedding,这层编码单词的句法信息更多一些;再往上走是第二层 LSTM 中对应单词位置的 Embedding,这层编码单词的语义信息更多一些。
下面的章节会详细介绍 ELMo。
2.1.1 从 Word Embedding 到 ELMo
Word Embedding:词嵌入。最简单的理解就是:将词进行向量化表示,实体的抽象成了数学描述,就可以进行建模,应用到很多任务中。之前用语言模型做 Word Embedding 比较火的是 word2vec 和 glove。使用 Word2Vec 或者 Glove,通过做语言模型任务,就可以获得每个单词的 Word Embedding,但是 Word Embedding 无法解决多义词的问题,同一个词在不同的上下文中表示不同的意思,但是在 Word Embedding 中一个词只有一个表示,这导致两种不同的上下文信息都会编码到相同的 word embedding 空间里去。如何根据句子上下文来进行单词的 Word Embedding 表示。ELMO 提供了解决方案。
我们有以下两个句子:
-
I read the book yesterday.
-
Can you read the letter now?
花些时间考虑下这两个句子的区别,第一个句子中的动词 “read” 是过去式,而第二个句子中的 “read” 却是现在式,这是一种一词多义现象。
传统的词嵌入会对两个句子中的词 “read” 生成同样的向量,所以这些架构无法区别多义词,它们无法识别词的上下文。
与之相反,ELMo 的词向量能够很好地解决这种问题。ELMo 模型将整个句子输入方程式中来计算词嵌入。因此,上例中两个句子的 “read” 会有不同的 ELMo 向量。
2.2.ELMo 原理
在此之前的 Word Embedding 本质上是个静态的方式,所谓静态指的是训练好之后每个单词的表达就固定住了,以后使用的时候,不论新句子上下文单词是什么,这个单词的 Word Embedding 不会跟着上下文场景的变化而改变,所以对于比如 Bank 这个词,它事先学好的 Word Embedding 中混合了几种语义 ,在应用中来了个新句子,即使从上下文中(比如句子包含 money 等词)明显可以看出它代表的是 “银行” 的含义,但是对应的 Word Embedding 内容也不会变,它还是混合了多种语义。这是为何说它是静态的,这也是问题所在。
ELMO 的本质思想是:我事先用语言模型学好一个单词的 Word Embedding,此时多义词无法区分,不过这没关系。在我实际使用 Word Embedding 的时候,单词已经具备了特定的上下文了,这个时候我可以根据上下文单词的语义去调整单词的 Word Embedding 表示,这样经过调整后的 Word Embedding 更能表达在这个上下文中的具体含义,自然也就解决了多义词的问题了。所以 ELMO 本身是个根据当前上下文对 Word Embedding 动态调整的思路。
ELMo 表征是 “深” 的,就是说它们是 BiLM 的所有层的内部表征的函数。这样做的好处是能够产生丰富的词语表征。高层的 LSTM 的状态可以捕捉词语以一种和语境相关的特征(比如可以应用在语义消歧),而低层的 LSTM 可以找到语法方面的特征(比如可以做词性标注)。如果把它们结合在一起,会在下游的 NLP 任务中显出优势。
2.2.1 模型结构
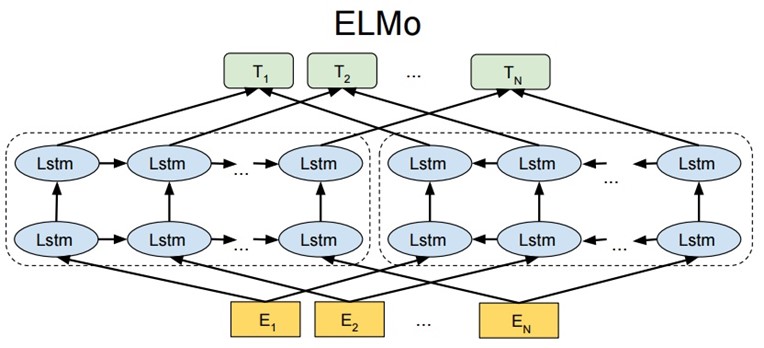
ELMO 基于语言模型的,确切的来说是一个 Bidirectional language models,也是一个 Bidirectional LSTM 结构。我们要做的是给定一个含有 N 个 tokens 的序列。分为以下三步:
-
第一步:得到 word embedding,即上图的 E。所谓 word embedding 就是一个 n*1 维的列向量,其中 n 表示 embedding 向量的大小;
-
第二步:送入双向 LSTM 模型中,即上图中的 Lstm;
-
第三步:将 LSTM 的输出 h k h_{k} hk,与上下文矩阵 W ′ W' W′相乘,再将该列向量经过 Softmax 归一化。其中,假定数据集有 V 个单词, W ′ W' W′是 ∣ V ∣ ∗ m |V|*m ∣V∣∗m的矩阵, h k h_{k} hk是 m ∗ 1 m*1 m∗1的列向量,于是最终结果是 ∣ V ∣ ∗ 1 |V|*1 ∣V∣∗1的归一化后向量,即从输入单词得到的针对每个单词的概率。
2.2.2 双向语言模型
假定一个序列有 N 个 token,即 ( t 1 , t 2 , . . . , t N ) (t_{1},t_{2},...,t_{N}) (t1,t2,...,tN),对于前向语言模型(forward LM),我们基于 ( t 1 , . . , t k − 1 ) (t_{1},..,t_{k-1}) (t1,..,tk−1)来预测 t k t_{k} tk,前向公式表示为:
p ( t 1 , t 2 , . . . , t N ) = ∏ k = 1 N p ( t k ∣ t 1 , t 2 , . . . , t k − 1 ) p(t_{1},t_{2},...,t_{N})=\prod_{k=1}^{N}p(t_{k}|t_{1},t_{2},...,t_{k-1}) p(t1,t2,...,tN)=k=1∏Np(tk∣t1,t2,...,tk−1)
向后语言模型(backword LM)与向前语言模型类似,除了计算的时候倒置输入序列,用后面的上下文预测前面的词:
p ( t 1 , t 2 , . . . , t N ) = ∏ k = 1 N p ( t k ∣ t k + 1 , t k + 2 , . . . , t N ) p(t_{1},t_{2},...,t_{N})=\prod_{k=1}^{N}p(t_{k}|t_{k+1},t_{k+2},...,t_{N}) p(t1,t2,...,tN)=k=1∏Np(tk∣tk+1,tk+2,...,tN)
一个双向语言模型包含前向和后向语言模型,训练的目标就是联合前向和后向的最大似然:
∑ k = 1 N ( l o g p ( t k ∣ t 1 , . . . , t k − 1 ; Θ x , Θ → L S T M , Θ s ) + l o g p ( t k ∣ t k + 1 , . . . , t N ; Θ ← L S T M , Θ s ) ) \sum_{k=1}^N (log p(t_{k}|t_{1},...,t_{k-1};\Theta_{x},\overrightarrow\Theta_{LSTM},\Theta_{s})+log p(t_{k}|t_{k+1},...,t_{N};\overleftarrow\Theta_{LSTM},\Theta_{s})) k=1∑N(logp(tk∣t1,...,tk−1;Θx,ΘLSTM,Θs)+logp(tk∣tk+1,...,tN;ΘLSTM,Θs))
两个网络里都出现了 Θ x \Theta_{x} Θx和 Θ s \Theta_{s} Θs,两个网络共享的参数。
其中 Θ x \Theta_{x} Θx表示映射层的共享,表示第一步中,将单词映射为 word embedding 的共享,就是说同一个单词,映射为同一个 word embedding。
Θ s \Theta_{s} Θs表示第三步中的上下文矩阵的参数,这个参数在前向和后向 LSTM 中是相同的。
2.2.3 ELMo
ELMo 对于每个 token t k t_{k} tk, 通过一个 L 层的 biLM 计算 2L+1 个表征(representations),这是输入第二阶段的初始值:
R k = { x k L M , h → k , j L M , h ← k , j L M ∣ j = 1 , . . . , L } R_{k}=\{ x_{k}^{LM},\overrightarrow h^{LM}_{k,j},\overleftarrow h^{LM}_{k,j}|j=1,...,L\} Rk={xkLM,hk,jLM,hk,jLM∣j=1,...,L}
= { h k , j L M ∣ j = 0 , . . . , L } =\{h_{k,j}^{LM}|j=0,...,L\} ={hk,jLM∣j=0,...,L}
其中 k 表示单词位置,j 表示所在层,j=0 表示输入层。故整体可用右侧的 h 表示。 h k , 0 L M h_{k,0}^{LM} hk,0LM是对 token 进行直接编码的结果 (这里是字符通过 CNN 编码), h k , j L M = [ h → k , j L M ; h ← k , j L M ] h_{k,j}^{LM}=[\overrightarrow h^{LM}_{k,j};\overleftarrow h^{LM}_{k,j}] hk,jLM=[hk,jLM;hk,jLM]是每个 biLSTM 层输出的结果。在实验中还发现不同层的 biLM 的输出的 token 表示对于不同的任务效果不同. 最上面一层的输出是用 softmax 来预测下面一个单词
应用中将 ELMo 中所有层的输出 R 压缩为单个向量, E L M o k = E ( R k ; Θ ϵ ) ELMo_{k}=E(R_{k};\Theta_{\epsilon}) ELMok=E(Rk;Θϵ),最简单的压缩方法是取最上层的结果做为 token 的表示: E ( R k ) = h k , L L M E(R_{k})=h_{k,L}^{LM} E(Rk)=hk,LLM, 更通用的做法是通过一些参数来联合所有层的信息:
E L M o k t a s k = E ( R k ; Θ t a s k ) ELMo_{k}^{task}=E(R_{k};\Theta^{task}) ELMoktask=E(Rk;Θtask)
= γ t a s k ∑ j = 0 L s j t a s k h k , j L M =\gamma^{task}\sum_{j=0}^{L}s_{j}^{task}h_{k,j}^{LM} =γtaskj=0∑Lsjtaskhk,jLM
其中 s j s_{j} sj是 softmax 标准化权重, γ \gamma γ是缩放系数,允许任务模型去缩放整个 ELMO 向量。文中提到γ在不同任务中取不同的值效果会有较大的差异, 需要注意, 在 SQuAD 中设置为 0.01 取得的效果要好于设置为 1 时。
文章中提到的 Pre-trained 的 language model 是用了两层的 biLM, 对 token 进行上下文无关的编码是通过 CNN 对字符进行编码, 然后将三层的输出 scale 到 1024 维, 最后对每个 token 输出 3 个 1024 维的向量表示.
2.3.ELMo 训练
2.3.1 第一阶段 语言模型进行预训练
ELMo 采用了典型的两阶段过程,第一个阶段是利用语言模型进行预训练;第二个阶段是在做下游任务时,从预训练网络中提取对应单词的网络各层的 Word Embedding 作为新特征补充到下游任务中。图展示的是其预训练过程:
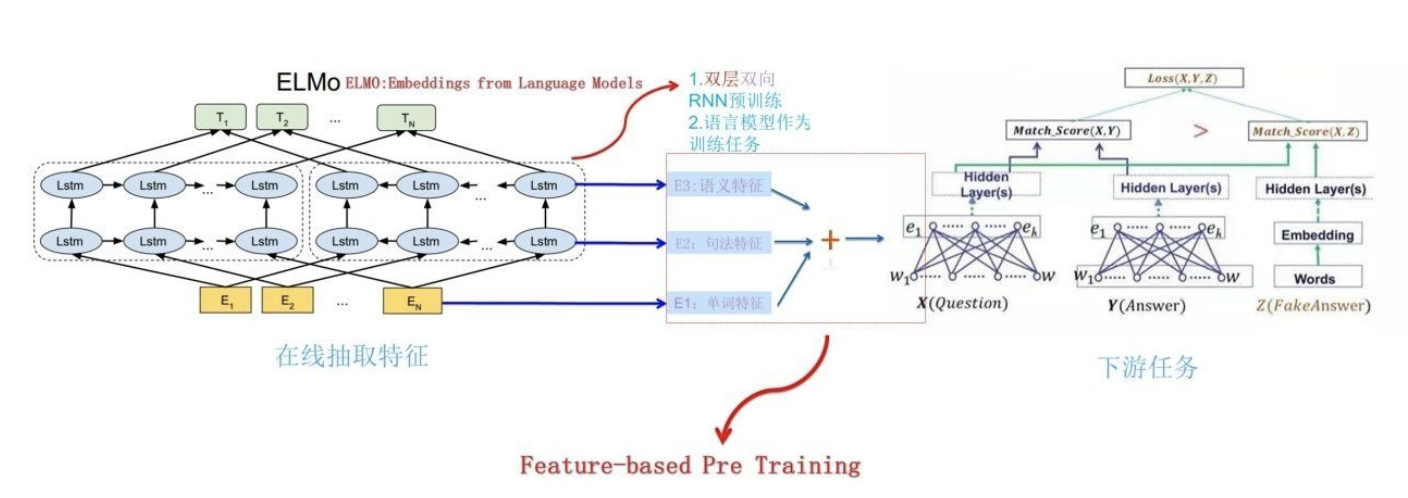
它的网络结构采用了双层双向 LSTM,目前语言模型训练的任务目标是根据单词 W i W_{i} Wi的上下文去正确预测单词 W i W_{i} Wi, W i W_{i} Wi之前的单词序列 Context-before 称为上文,之后的单词序列 Context-after 称为下文。图中左端的前向双层 LSTM 代表正方向编码器,输入的是从左到右顺序的除了预测单词外 W i W_{i} Wi的上文 Context-before;右端的逆向双层 LSTM 代表反方向编码器,输入的是从右到左的逆序的句子下文 Context-after;每个编码器的深度都是两层 LSTM 叠加。这个网络结构其实在 NLP 中是很常用的。
使用这个网络结构利用大量语料做语言模型任务就能预先训练好这个网络,如果训练好这个网络后,输入一个新句子 S n e w S_{new} Snew,句子中每个单词都能得到对应的三个 Embedding: 最底层是单词的 Word Embedding,往上走是第一层双向 LSTM 中对应单词位置的 Embedding,这层编码单词的句法信息更多一些;再往上走是第二层 LSTM 中对应单词位置的 Embedding,这层编码单词的语义信息更多一些。也就是说,ELMO 的预训练过程不仅仅学会单词的 Word Embedding,还学会了一个双层双向的 LSTM 网络结构,而这两者后面都有用。
2.3.2 第二阶段 接入下游 NLP 任务
下图展示了下游任务的使用过程,比如我们的下游任务仍然是 QA 问题,此时对于问句 X,我们可以先将句子 X 作为预训练好的 ELMo 网络的输入,这样句子 X 中每个单词在 ELMO 网络中都能获得对应的三个 Embedding,之后给予这三个 Embedding 中的每一个 Embedding 一个权重 a,这个权重可以学习得来,根据各自权重累加求和,将三个 Embedding 整合成一个。然后将整合后的这个 Embedding 作为 X 句在自己任务的那个网络结构中对应单词的输入,以此作为补充的新特征给下游任务使用。
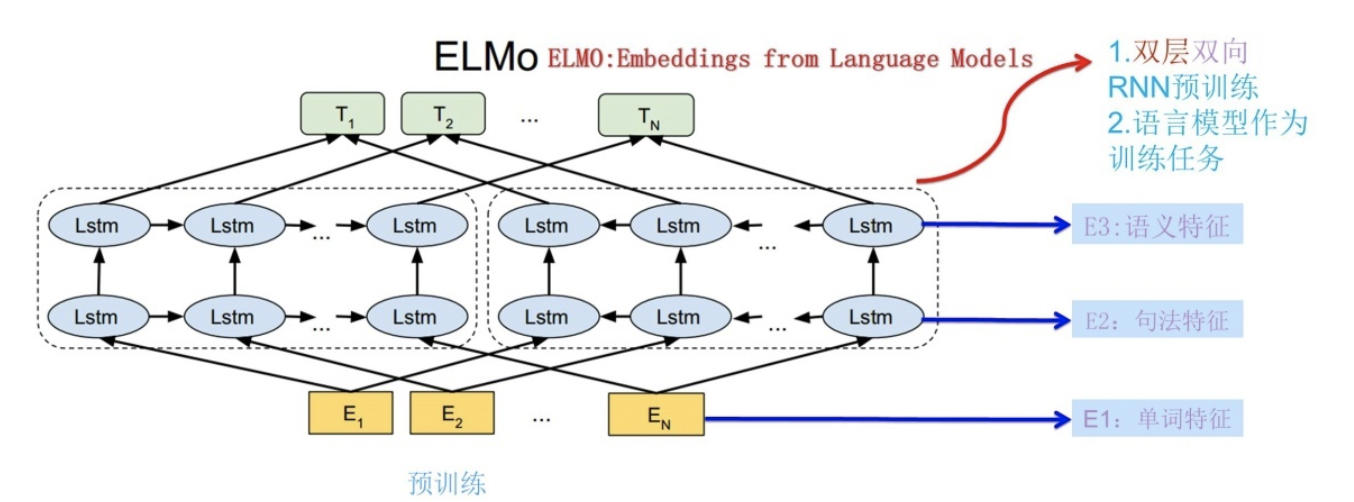
对于上图所示下游任务 QA 中的回答句子 Y 来说也是如此处理。因为 ELMO 给下游提供的是每个单词的特征形式,所以这一类预训练的方法被称为 “Feature-based Pre-Training”。
最后,作者发现给 ELMo 模型增加一定数量的 Dropout,在某些情况下给损失函数加入正则项 λ ∣ ∣ w ∣ ∣ 2 2 \lambda ||w||^2_{2} λ∣∣w∣∣22,这等于给 ELMo 模型加了一个归纳偏置,使得权重接近 BiLM 所有层的平均权重。
2.4. ELMo 使用步骤
ELMO 的使用主要有三步:
-
在大的语料库上预训练 biLM 模型。模型由两层 biLSTM 组成,模型之间用残差连接起来。而且作者认为低层的 biLSTM 层能提取语料中的句法信息,高层的 biLSTM 能提取语料中的语义信息。
-
在我们的训练语料(去除标签),fine-tuning 预训练好的 biLM 模型。这一步可以看作是 biLM 的 domain transfer。
-
利用 ELMo 产生的 word embedding 来作为任务的输入,有时也可以即在输入时加入,也在输出时加入。
2.4.1优缺点
-
优点
-
考虑上下文,针对不同的上下文生成不同的词向量。表达不同的语法或语义信息。如 “活动” 一词,既可以是名词,也可以是动词,既可以做主语,也可以做谓语等。针对这种情况,ELMo 能够根据不同的语法或语义信息生成不同的词向量。
-
6 个 NLP 任务中性能都有幅度不同的提升,最高的提升达到 25% 左右,而且这 6 个任务的覆盖范围比较广,包含句子语义关系判断,分类任务,阅读理解等多个领域,这说明其适用范围是非常广的,普适性强,这是一个非常好的优点。
-
-
缺点
-
使用 LSTM 提取特征,而 LSTM 提取特征的能力弱于 Transformer
-
使用向量拼接方式融合上下文特征,这种方式获取的上下文信息效果不如想象中好
-
训练时间长,这也是 RNN 的本质导致的,和上面特征提取缺点差不多;
-
参考文献:
Deep contextualized word representations
3.Transformer
3.1.Transformer 介绍
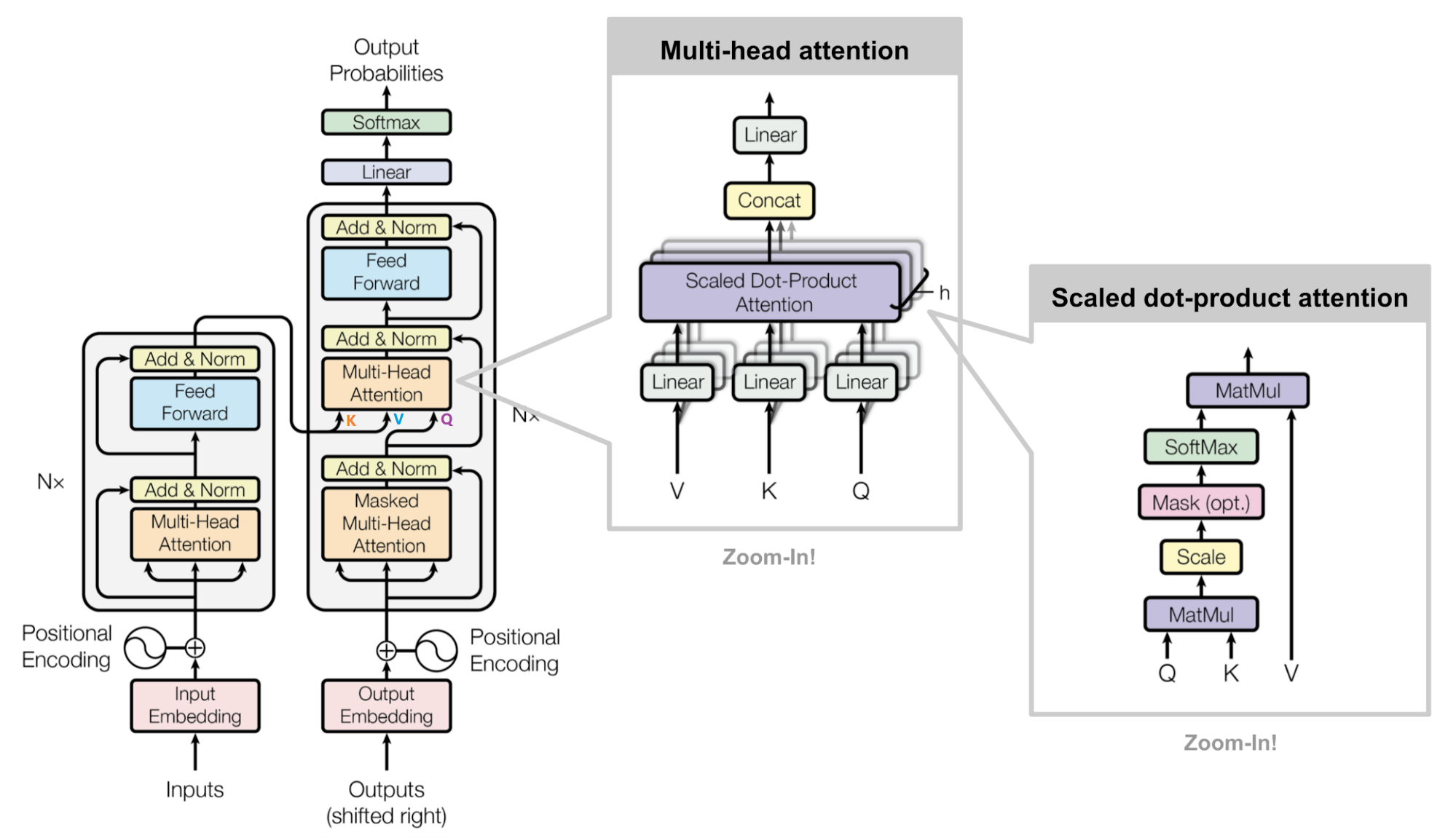
Transformer 网络架构架构由 Ashish Vaswani 等人在 Attention Is All You Need 一文中提出,并用于机器翻译任务,和以往网络架构有所区别的是,该网络架构中,编码器和解码器没有采用 RNN 或 CNN 等网络架构,而是采用完全依赖于注意力机制的架构。网络架构如下所示:
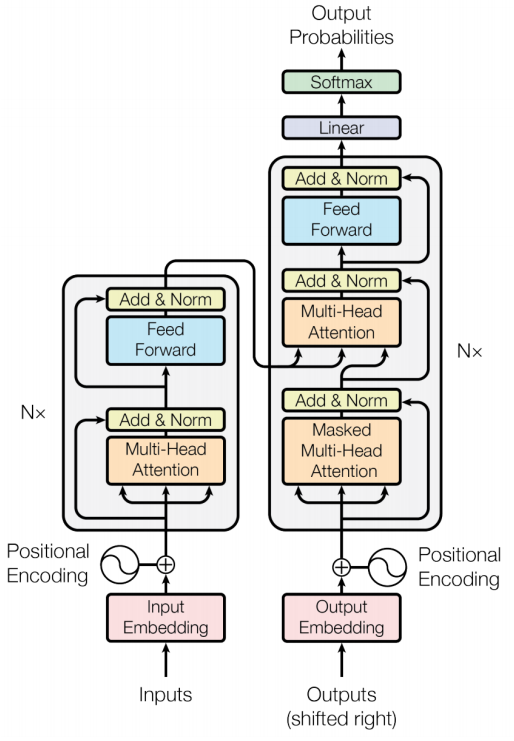
Transformer 改进了 RNN 被人诟病的训练慢的特点,利用 self-attention 可以实现快速并行。下面的章节会详细介绍 Transformer 的各个组成部分。
Transformer 主要由 encoder 和 decoder 两部分组成。在 Transformer 的论文中,encoder 和 decoder 均由 6 个 encoder layer 和 decoder layer 组成,通常我们称之为 encoder block。
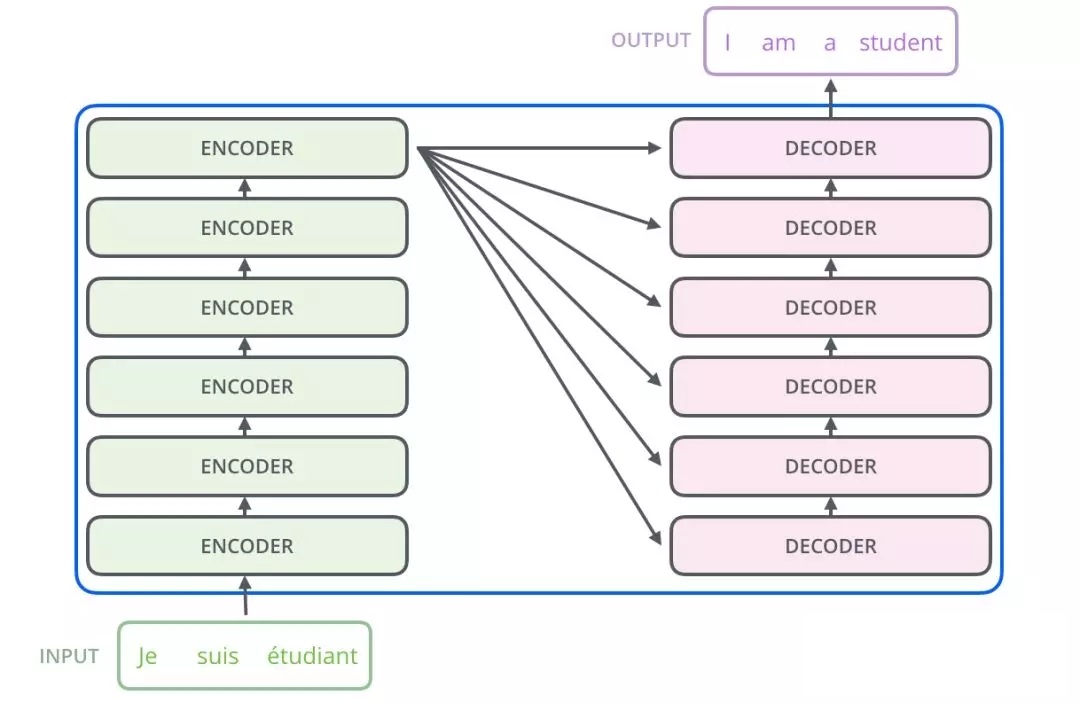
transformer 结构
每一个 encoder 和 decoder 的内部简版结构如下图
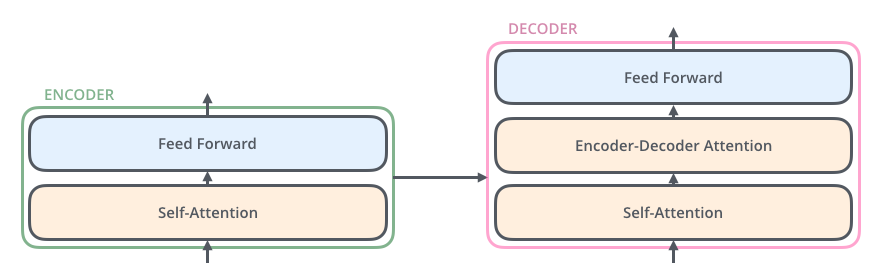
transformer 的 encoder 或者 decoder 的内部结构
对于 encoder,包含两层,一个 self-attention 层和一个前馈神经网络,self-attention 能帮助当前节点不仅仅只关注当前的词,从而能获取到上下文的语义。
decoder 也包含 encoder 提到的两层网络,但是在这两层中间还有一层 attention 层,帮助当前节点获取到当前需要关注的重点内容。
首先,模型需要对输入的数据进行一个 embedding 操作,enmbedding 结束之后,输入到 encoder 层,self-attention 处理完数据后把数据送给前馈神经网络,前馈神经网络的计算可以并行,得到的输出会输入到下一个 encoder。
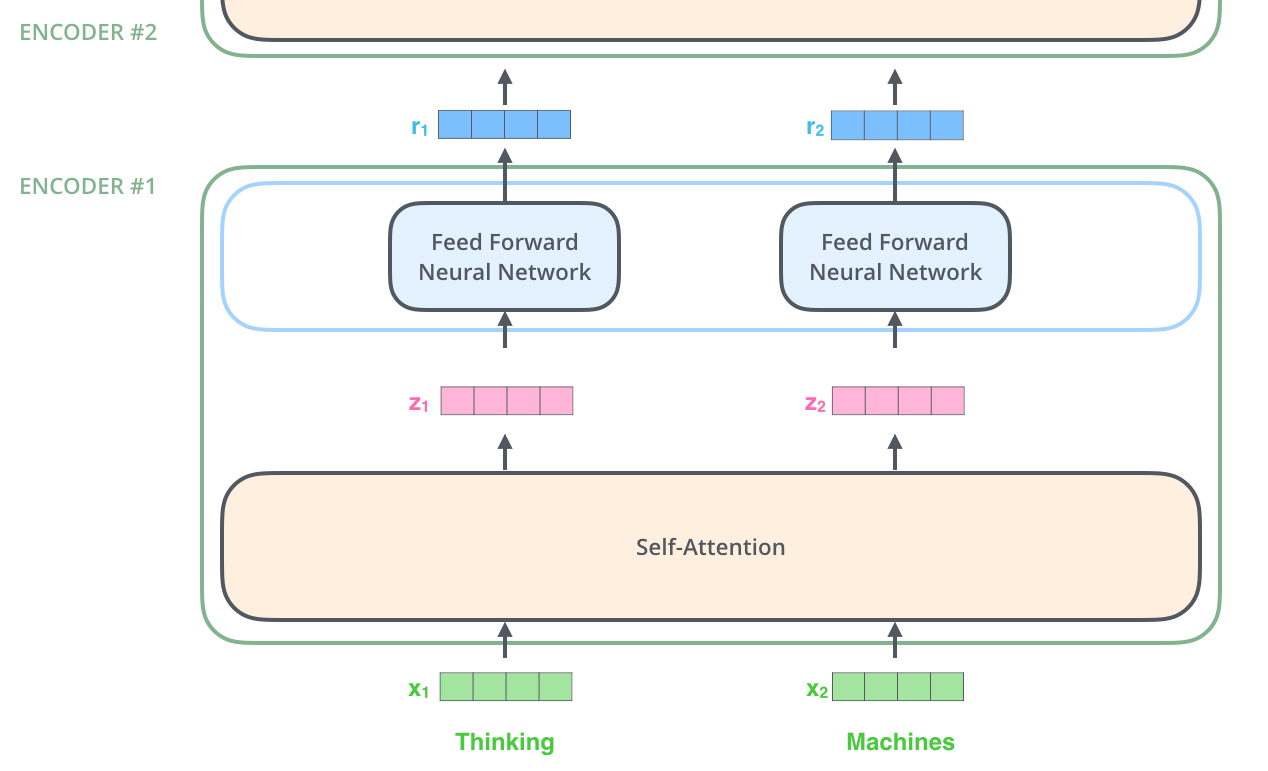
embedding 和 self-attention
3.2 Transformer 的结构
Transformer 的结构解析出来如下图表示,包括 Input Embedding, Position Embedding, Encoder, Decoder。
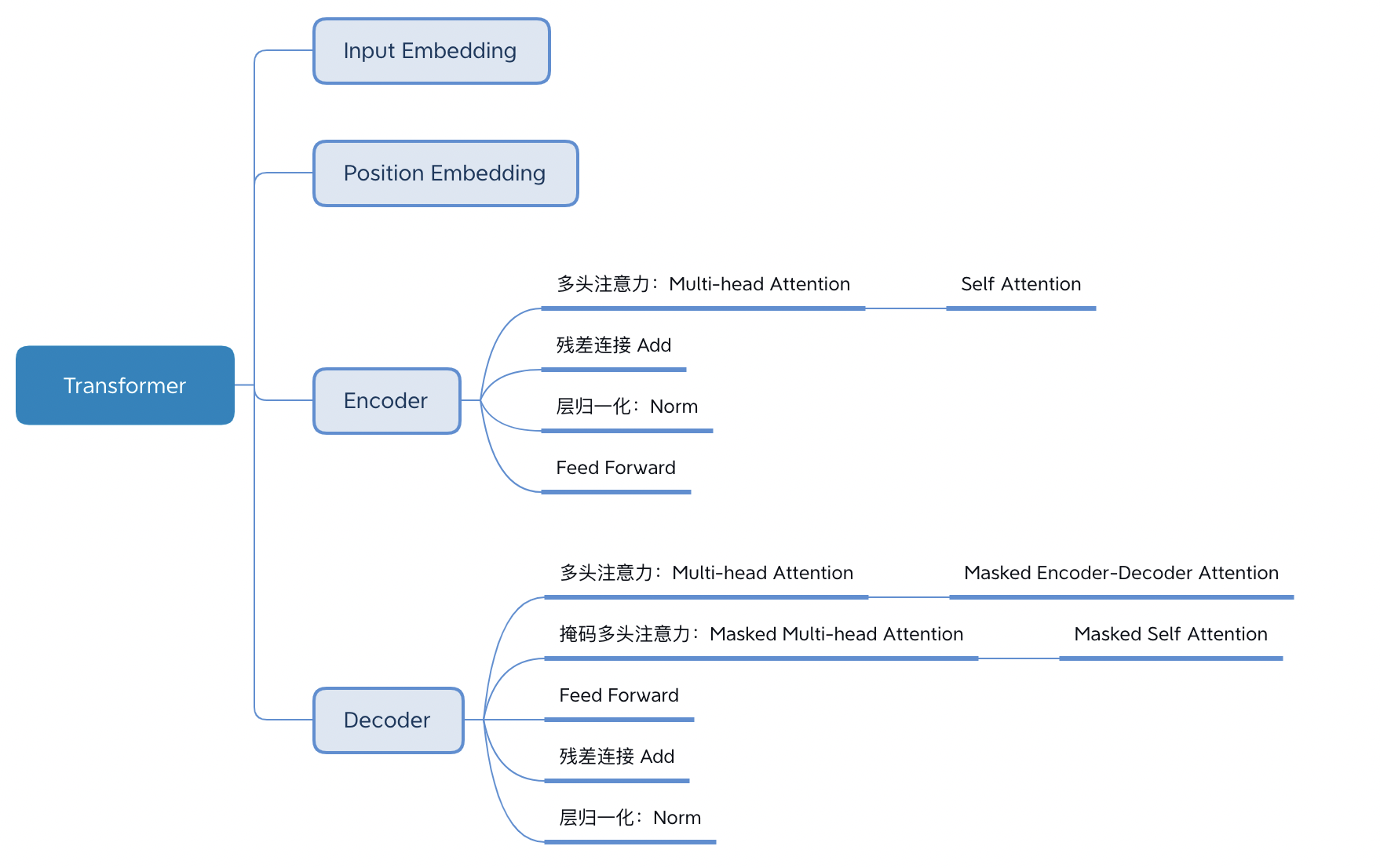
3.2.1 Embedding
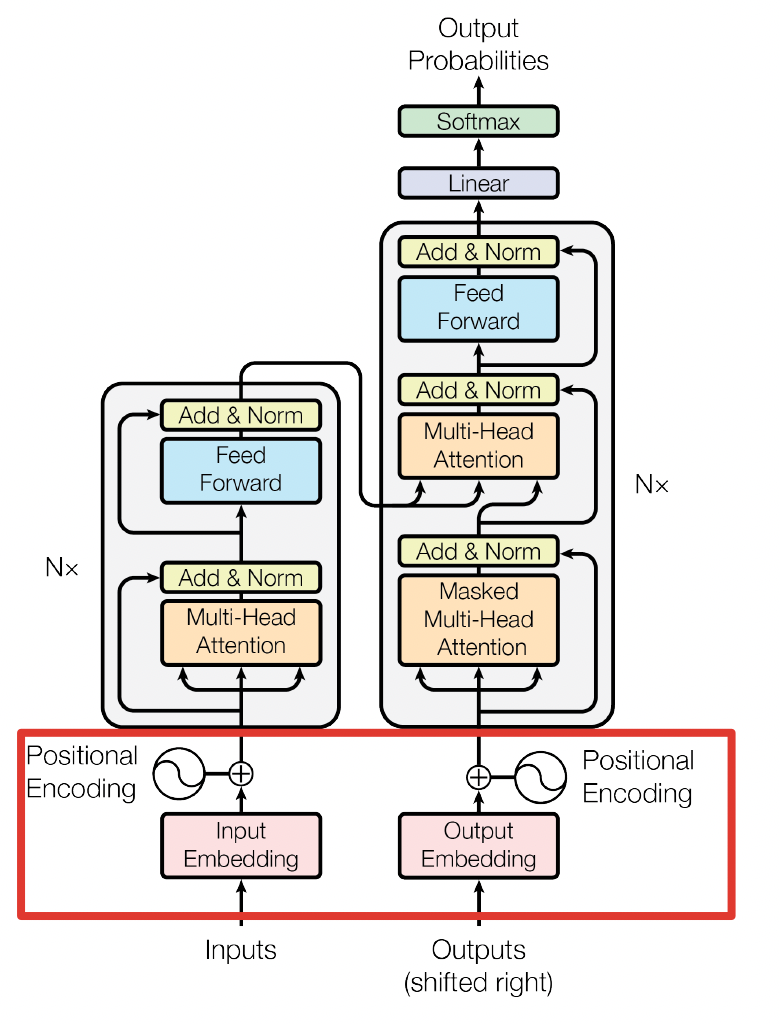
字向量与位置编码的公式表示如下:
X = E m b e d d i n g L o o k u p ( X ) + P o s i t i o n E n c o d i n g X=Embedding Lookup(X)+Position Encoding X=EmbeddingLookup(X)+PositionEncoding
- Input Embedding
可以将 Input Embedding 看作是一个 lookup table,对于每个 word,进行 word embedding 就相当于一个 lookup 操作,查出一个对应结果。
- Position Encoding
Transformer 模型中还缺少一种解释输入序列中单词顺序的方法。为了处理这个问题,transformer 给 encoder 层和 decoder 层的输入添加了一个额外的向量 Positional Encoding,维度和 embedding 的维度一样,这个向量采用了一种很独特的方法来让模型学习到这个值,这个向量能决定当前词的位置,或者说在一个句子中不同的词之间的距离。这个位置向量的具体计算方法有很多种,论文中的计算方法如下
P E ( p o s , 2 i ) = s i n ( p o s / 1000 0 2 i / d m o d e l ) PE(pos,2i)=sin(pos/10000^{2i}/d_{model}) PE(pos,2i)=sin(pos/100002i/dmodel)
P E ( p o s , 2 i + 1 ) = c o s ( p o s / 1000 0 2 i / d m o d e l ) PE(pos,2i+1)=cos(pos/10000^{2i}/d_{model}) PE(pos,2i+1)=cos(pos/100002i/dmodel)
其中 pos 是指当前词在句子中的位置,i 是指向量中每个值的 index,可以看出,在偶数位置,使用正弦编码,在奇数位置,使用余弦编码.
3.2.2 Encoder
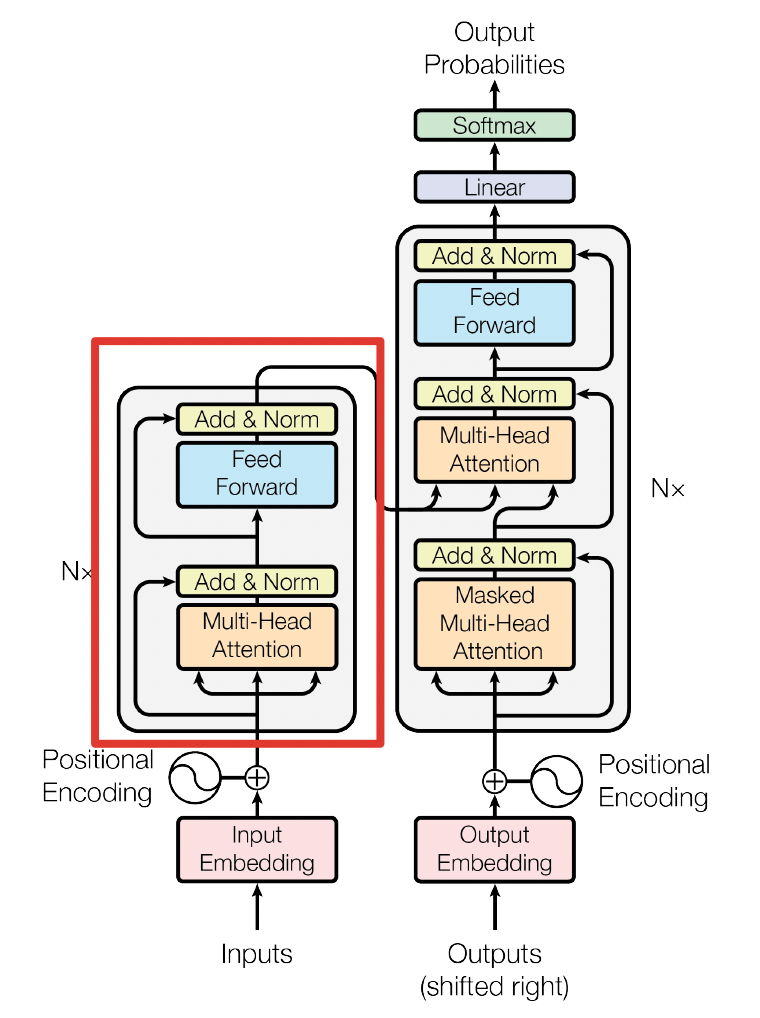
用公式把一个 Transformer Encoder block 的计算过程整理一下
- 自注意力机制
Q = X W Q Q=XW_{Q} Q=XWQ
K = X W K K=XW_{K} K=XWK
V = X W V V=XW_{V} V=XWV
X a t t e n t i o n = s e l f A t t e n t i o n ( Q , K , V ) X_{attention}=selfAttention(Q,K,V) Xattention=selfAttention(Q,K,V)
- self-attention 残差连接与 Layer Normalization
X a t t e n t i o n = L a y e r N o r m ( X a t t e n t i o n ) X_{attention}=LayerNorm(X_{attention}) Xattention=LayerNorm(Xattention)
- FeedForward,其实就是两层线性映射并用激活函数激活,比如说 RELU
X h i d d e n = L i n e a r ( R E L U ( L i n e a r ( X a t t e n t i o n ) ) ) X_{hidden}=Linear(RELU(Linear(X_{attention}))) Xhidden=Linear(RELU(Linear(Xattention)))
- FeedForward 残差连接与 Layer Normalization
X h i d d e n = X a t t e n t i o n + X h i d d e n X_{hidden}=X_{attention}+X_{hidden} Xhidden=Xattention+Xhidden
X h i d d e n = L a y e r N o r m ( X h i d d e n ) X_{hidden}=LayerNorm(X_{hidden}) Xhidden=LayerNorm(Xhidden)
其中: X h i d d e n ∈ R b a t c h s i z e ∗ s e q l e n ∗ e m b e d d i m X_{hidden} \in R^{batch_size*seq_len*embed_dim} Xhidden∈Rbatchsize∗seqlen∗embeddim
3.2.3自注意力机制
- 首先,自注意力机制(self-attention)会计算出三个新的向量,在论文中,向量的维度是 512 维,我们把这三个向量分别称为 Query、Key、Value,这三个向量是用 embedding 向量与一个矩阵相乘得到的结果,这个矩阵是随机初始化的,维度为(64,512)注意第二个维度需要和 embedding 的维度一样,其值在反向传播的过程中会一直进行更新,得到的这三个向量的维度是 64 低于 embedding 维度的。
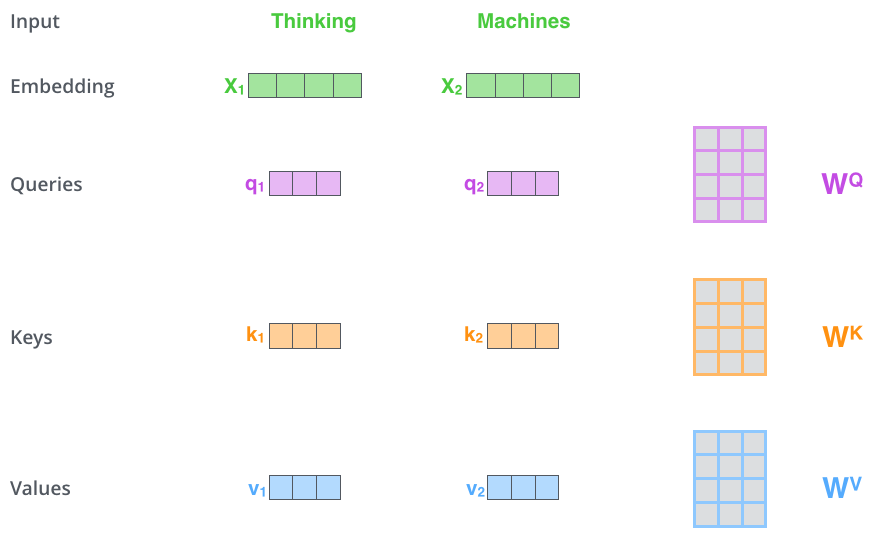
Query Key Value
2、计算 self-attention 的分数值,该分数值决定了当我们在某个位置 encode 一个词时,对输入句子的其他部分的关注程度。这个分数值的计算方法是 Query 与 Key 做点乘,以下图为例,首先我们需要针对 Thinking 这个词,计算出其他词对于该词的一个分数值,首先是针对于自己本身即 q1·k1,然后是针对于第二个词即 q1·k2
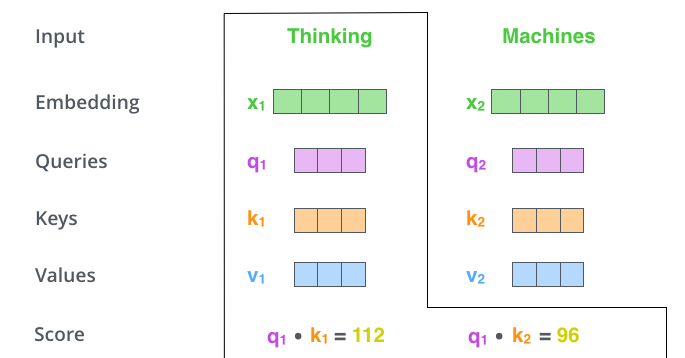
Query Key Value
3、接下来,把点乘的结果除以一个常数,这里我们除以 8,这个值一般是采用上文提到的矩阵的第一个维度的开方即 64 的开方 8,当然也可以选择其他的值,然后把得到的结果做一个 softmax 的计算。得到的结果即是每个词对于当前位置的词的相关性大小,当然,当前位置的词相关性肯定会会很大
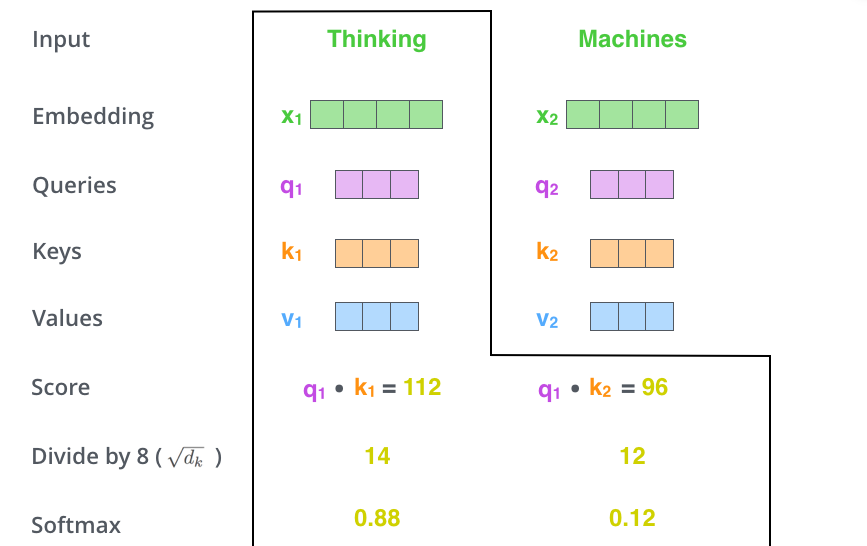
softmax
4、下一步就是把 Value 和 softmax 得到的值进行相乘,并相加,得到的结果即是 self-attetion 在当前节点的值。
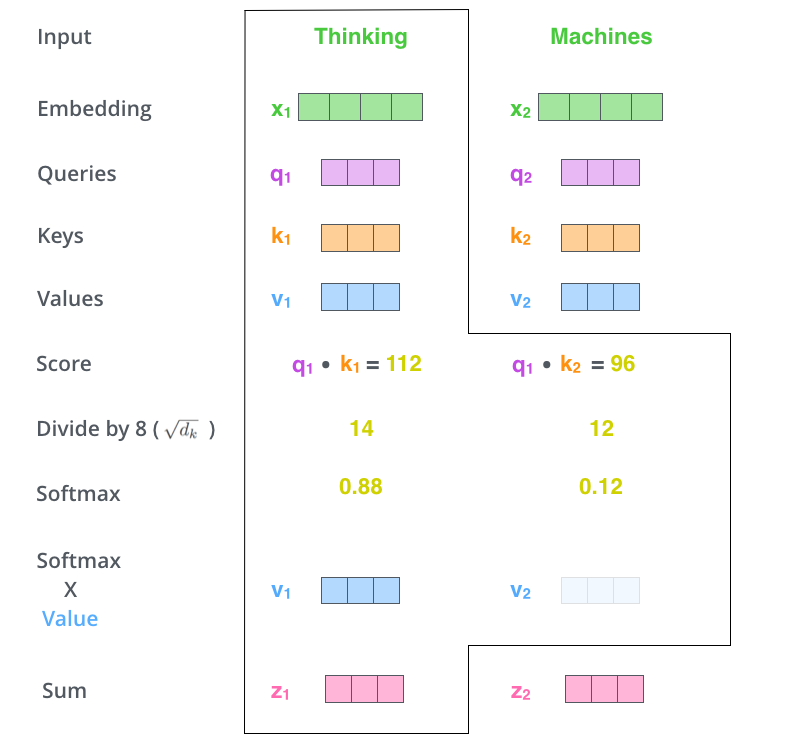
dot product
在实际的应用场景,为了提高计算速度,我们采用的是矩阵的方式,直接计算出 Query, Key, Value 的矩阵,然后把 embedding 的值与三个矩阵直接相乘,把得到的新矩阵 Q 与 K 相乘,乘以一个常数,做 softmax 操作,最后乘上 V 矩阵
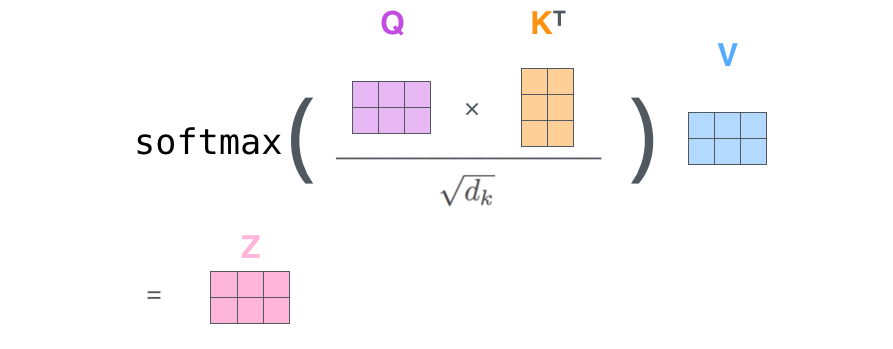
scaled dot product attention
这种通过 query 和 key 的相似性程度来确定 value 的权重分布的方法被称为 scaled dot-product attention。
用公式表达如下:
Q = X W Q Q=XW_{Q} Q=XWQ
K = X W K K=XW_{K} K=XWK
V = X W V V=XW_{V} V=XWV
X a t t e n t i o n = s e l f A t t e n t i o n ( Q , K , V ) X_{attention}=selfAttention(Q,K,V) Xattention=selfAttention(Q,K,V)
3.2.4 Self-Attention 复杂度
Self-Attention 时间复杂度: O ( n 2 ⋅ d ) O(n^2 \cdot d) O(n2⋅d) ,这里,n 是序列的长度,d 是 embedding 的维度。
Self-Attention 包括三个步骤:相似度计算,softmax 和加权平均,它们分别的时间复杂度是:
相似度计算可以看作大小为 (n,d) 和(d,n)的两个矩阵相乘: ( n , d ) ∗ ( d , n ) = ( n 2 ⋅ d ) (n,d) *(d,n) =(n^2 \cdot d) (n,d)∗(d,n)=(n2⋅d),得到一个 (n,n) 的矩阵
softmax 就是直接计算了,时间复杂度为: O ( n 2 ) O(n^2) O(n2)
加权平均可以看作大小为 (n,n) 和(n,d)的两个矩阵相乘: ( n , d ) ∗ ( d , n ) = ( n 2 ⋅ d ) (n,d) *(d,n) =(n^2 \cdot d) (n,d)∗(d,n)=(n2⋅d),得到一个 (n,d) 的矩阵
因此,Self-Attention 的时间复杂度是: O ( n 2 ⋅ d ) O(n^2 \cdot d) O(n2⋅d)
3.2.5 Multi-head Attention
不仅仅只初始化一组 Q、K、V 的矩阵,而是初始化多组,tranformer 是使用了 8 组,所以最后得到的结果是 8 个矩阵。
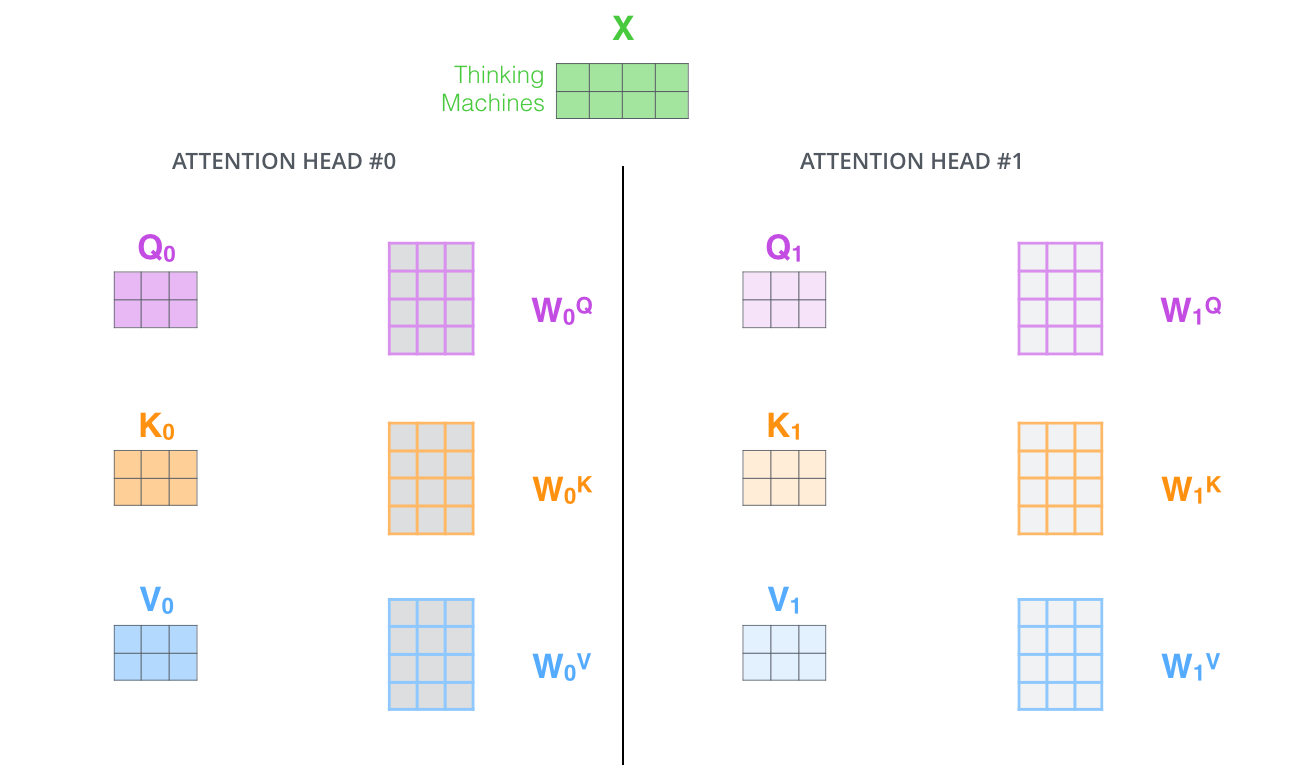
multi-head attention
multi-head 注意力的全过程如下,首先输入句子,“Thinking Machines”, 在 embedding 模块把句子中的每个单词变成向量 X,在 encoder 层中,除了第 0 层有 embedding 操作外,其他的层没有 embedding 操作;接着把 X 分成 8 个 head,
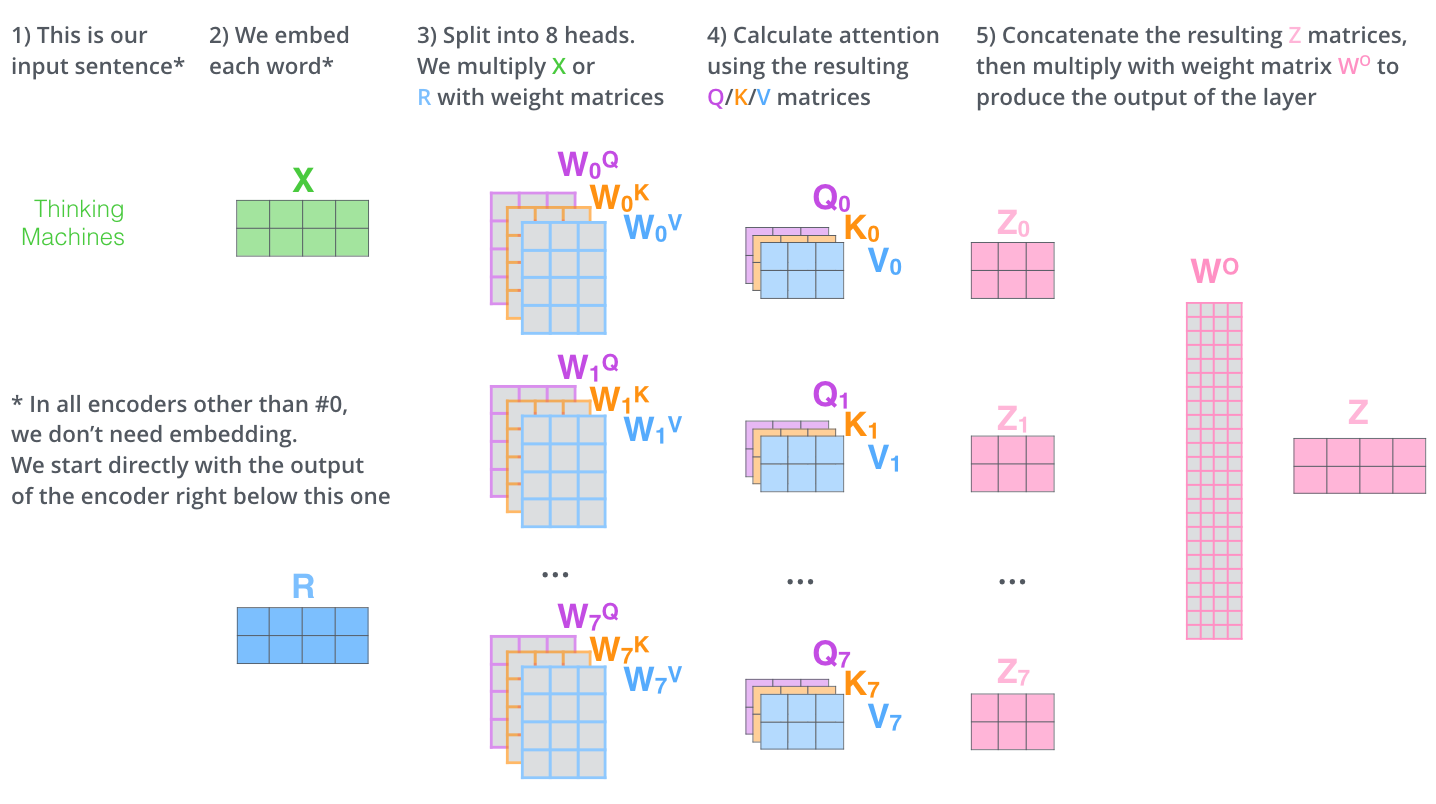
multi-head attention 总体结构
3.2.6 Multi-Head Attention 复杂度
多头的实现不是循环的计算每个头,而是通过 transposes and reshapes,用矩阵乘法来完成的。
Transformer/BERT 中把 d ,也就是 hidden_size/embedding_size 这个维度做了 reshape 拆分。并将 num_attention_heads 维度 transpose 到前面,使得 Q 和 K 的维度都是 (m,n,a),这里不考虑 batch 维度。
这样点积可以看作大小为 (m,n,a) 和(m,a,n)的两个张量相乘,得到一个 (m,n,n) 的矩阵,其实就相当于 (n,a) 和(a,n)的两个矩阵相乘,做了 m 次,时间复杂度是:
O ( n 2 ⋅ m ⋅ a ) = O ( n 2 ⋅ d ) O(n^2 \cdot m \cdot a)=O(n^2 \cdot d) O(n2⋅m⋅a)=O(n2⋅d)
因此 Multi-Head Attention 时间复杂度也是 O ( n 2 ⋅ d ) O(n^2 \cdot d) O(n2⋅d),复杂度相较单头并没有变化,主要还是 transposes and reshapes 的操作,相当于把一个大矩阵相乘变成了多个小矩阵的相乘。
3.2.7 残差连接
经过 self-attention 加权之后输出,也就是 Attention(Q,K,V) ,然后把他们加起来做残差连接
X h i d d e n = X e m b e d d i n g + s e l f A t t e n t i o n ( Q , K , V ) X_{hidden}=X_{embedding}+self Attention(Q,K,V) Xhidden=Xembedding+selfAttention(Q,K,V)
除了 self-attention 这里做残差连接外,feed forward 那个地方也需要残差连接,公式类似:
X h i d d e n = X f e e d f o r w a r d + X h i d d e n X_{hidden}=X_{feed_forward}+X_{hidden} Xhidden=Xfeedforward+Xhidden
3.2.8 Layer Normalization
Layer Normalization 的作用是把神经网络中隐藏层归一为标准正态分布,也就是独立同分布,以起到加快训练速度,加速收敛的作用 X h i d d e n = L a y e r N o r m ( X h i d d e n ) X_{hidden}=LayerNorm(X_{hidden}) Xhidden=LayerNorm(Xhidden)
其中: X h i d d e n ∈ R b a t c h s i z e ∗ s e q l e n ∗ e m b e d d i m X_{hidden} \in R^{batch_size*seq_len*embed_dim} Xhidden∈Rbatchsize∗seqlen∗embeddim
LayerNorm 的详细操作如下:
μ L = 1 m ∑ i = 1 m x i \mu_{L}=\dfrac{1}{m}\sum_{i=1}^{m}x_{i} μL=m1i=1∑mxi
上式以矩阵为单位求均值;
δ 2 = 1 m ∑ i = 1 m ( x i − μ ) 2 \delta^{2}=\dfrac{1}{m}\sum_{i=1}^{m}(x_{i}-\mu)^2 δ2=m1i=1∑m(xi−μ)2
上式以矩阵为单位求方差
L N ( x i ) = α x i − μ L δ 2 + ϵ + β LN(x_{i})=\alpha \dfrac{x_{i}-\mu_{L}}{\sqrt{\delta^{2}+\epsilon}}+\beta LN(xi)=αδ2+ϵxi−μL+β
然后用每一列的每一个元素减去这列的均值,再除以这列的标准差,从而得到归一化后的数值,加 ϵ \epsilon ϵ是为了防止分母为 0. 此处一般初始化 α \alpha α为全 1,而 β \beta β为全 0.
3.2.9 Feed Forward

将 Multi-Head Attention 得到的向量再投影到一个更大的空间(论文里将空间放大了 4 倍)在那个大空间里可以更方便地提取需要的信息(使用 Relu 激活函数),最后再投影回 token 向量原来的空间
F F N ( x ) = R e L U ( W 1 x + b 1 ) W 2 + b 2 FFN(x)=ReLU(W_{1}x+b_{1})W_{2}+b_{2} FFN(x)=ReLU(W1x+b1)W2+b2
借鉴 SVM 来理解:SVM 对于比较复杂的问题通过将特征其投影到更高维的空间使得问题简单到一个超平面就能解决。这里 token 向量里的信息通过 Feed Forward Layer 被投影到更高维的空间,在高维空间里向量的各类信息彼此之间更容易区别。
3.3 Decoder

和 Encoder 一样,上面三个部分的每一个部分,都有一个残差连接,后接一个 Layer Normalization。Decoder 的中间部件并不复杂,大部分在前面 Encoder 里我们已经介绍过了,但是 Decoder 由于其特殊的功能,因此在训练时会涉及到一些细节,下面会介绍 Decoder 的 Masked Self-Attention 和 Encoder-Decoder Attention 两部分,其结构图如下图所示

decoder self attention
3.2.10 Masked Self-Attention
传统 Seq2Seq 中 Decoder 使用的是 RNN 模型,因此在训练过程中输入因此在训练过程中输入 t 时刻的词,模型无论如何也看不到未来时刻的词,因为循环神经网络是时间驱动的,只有当 t 时刻运算结束了,才能看到 t+1 时刻的词。而 Transformer Decoder 抛弃了 RNN,改为 Self-Attention,由此就产生了一个问题,在训练过程中,整个 ground truth 都暴露在 Decoder 中,这显然是不对的,我们需要对 Decoder 的输入进行一些处理,该处理被称为 Mask。
Mask 非常简单,首先生成一个下三角全 0,上三角全为负无穷的矩阵,然后将其与 Scaled Scores 相加即可,之后再做 softmax,就能将 -inf 变为 0,得到的这个矩阵即为每个字之间的权重。
3.3.2 Masked Encoder-Decoder Attention¶
其实这一部分的计算流程和前面 Masked Self-Attention 很相似,结构也一摸一样,唯一不同的是这里的 K,V 为 Encoder 的输出,Q 为 Decoder 中 Masked Self-Attention 的输出
Masked Encoder-Decoder Attention
3.2.11 Decoder 的解码
下图展示了 Decoder 的解码过程,Decoder 中的字符预测完之后,会当成输入预测下一个字符,知道遇见终止符号为止。
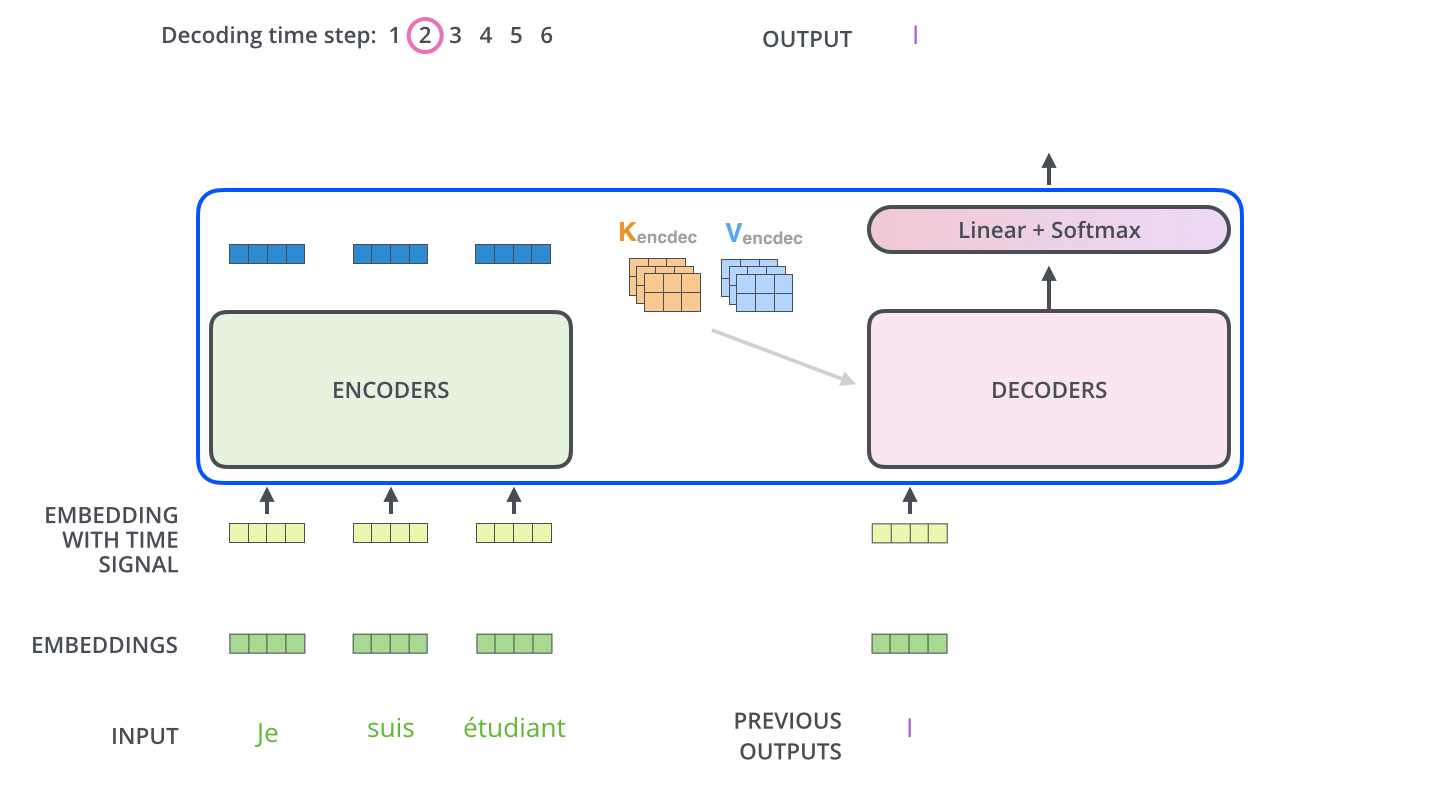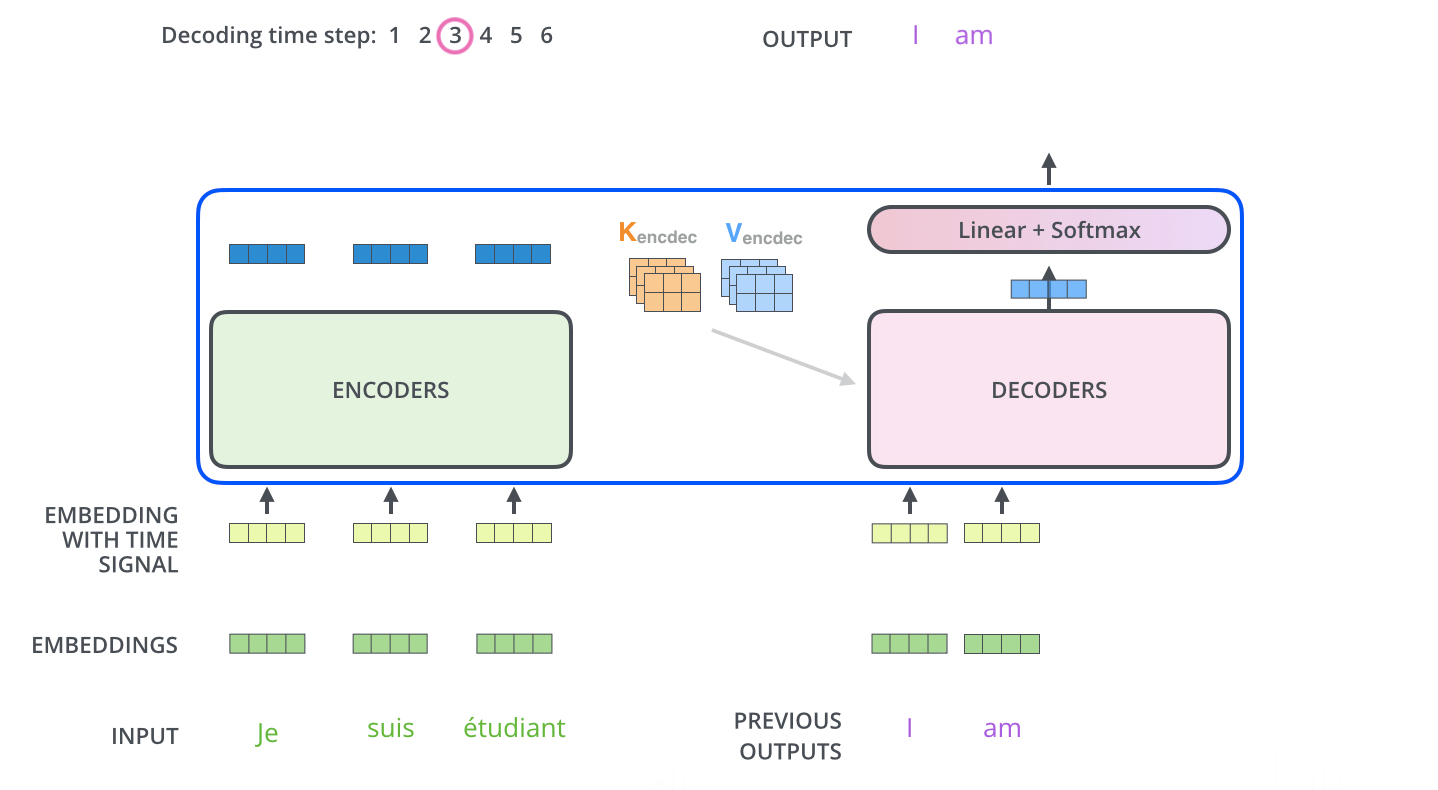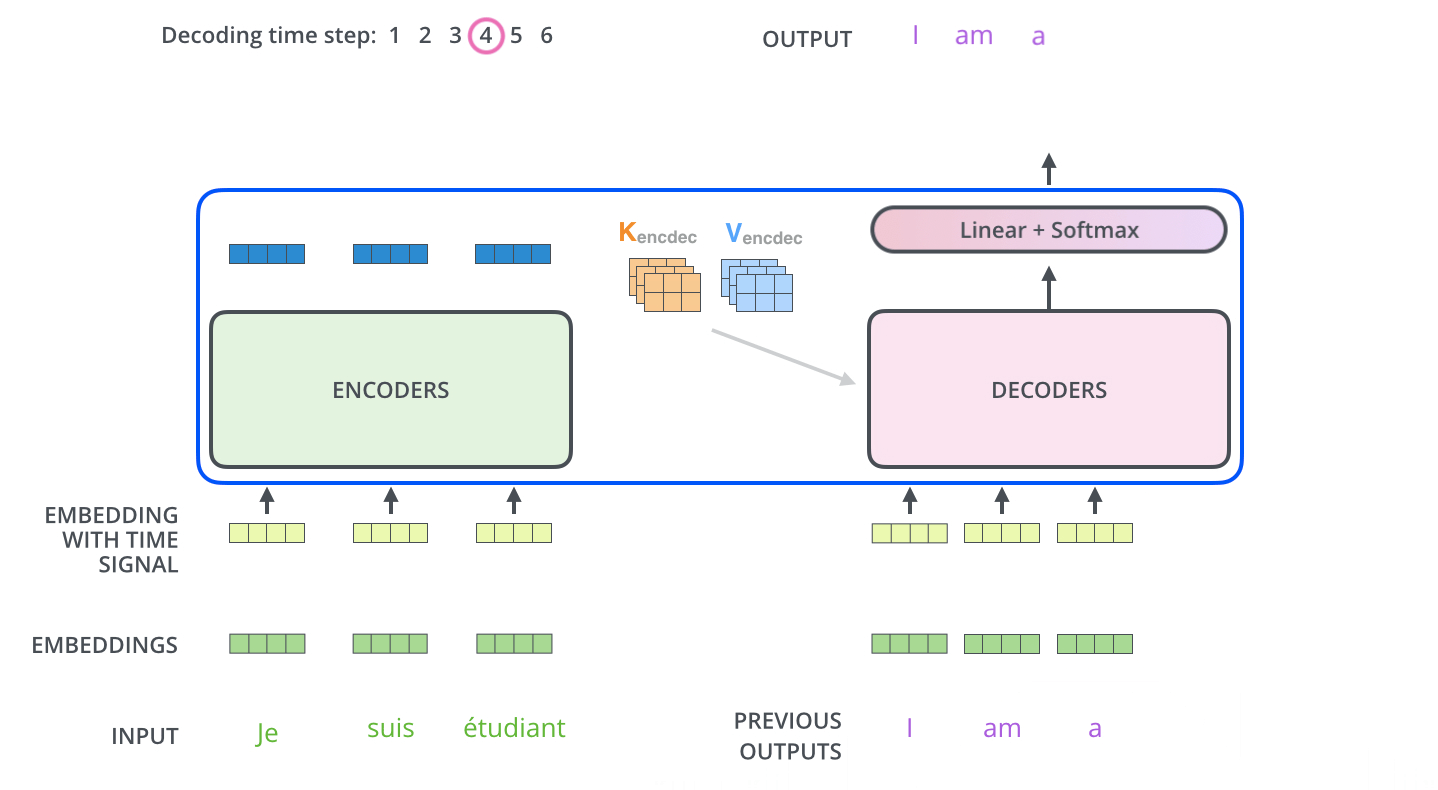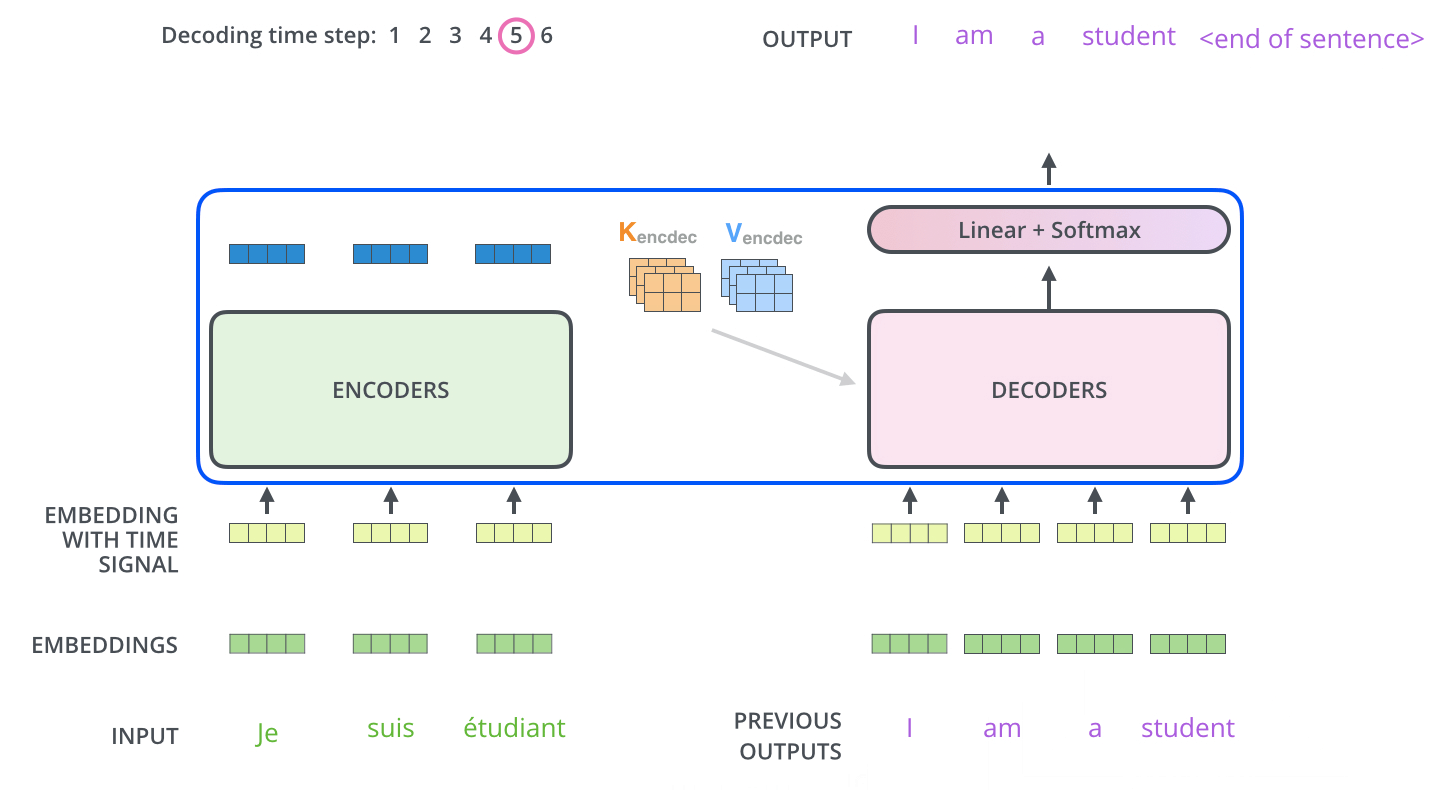
3.3 Transformer 的最后一层和 Softmax
线性层是一个简单的全连接的神经网络,它将解码器堆栈生成的向量投影到一个更大的向量,称为 logits 向量。如图 linear 的输出
softmax 层将这些分数转换为概率(全部为正值,总和为 1.0)。选择概率最高的单元,并生成与其关联的单词作为此时间步的输出。如图 softmax 的输出。

3.4 Transformer 的权重共享
Transformer 在两个地方进行了权重共享:
- (1)Encoder 和 Decoder 间的 Embedding 层权重共享;
《Attention is all you need》中 Transformer 被应用在机器翻译任务中,源语言和目标语言是不一样的,但它们可以共用一张大词表,对于两种语言中共同出现的词(比如:数字,标点等等)可以得到更好的表示,而且对于 Encoder 和 Decoder,嵌入时都只有对应语言的 embedding 会被激活,因此是可以共用一张词表做权重共享的。
论文中,Transformer 词表用了 bpe 来处理,所以最小的单元是 subword。英语和德语同属日耳曼语族,有很多相同的 subword,可以共享类似的语义。而像中英这样相差较大的语系,语义共享作用可能不会很大。
但是,共用词表会使得词表数量增大,增加 softmax 的计算时间,因此实际使用中是否共享可能要根据情况权衡。
- (2)Decoder 中 Embedding 层和 FC 层权重共享;
Embedding 层可以说是通过 onehot 去取到对应的 embedding 向量,FC 层可以说是相反的,通过向量(定义为 x)去得到它可能是某个词的 softmax 概率,取概率最大(贪婪情况下)的作为预测值。
那哪一个会是概率最大的呢?在 FC 层的每一行量级相同的前提下,理论上和 x 相同的那一行对应的点积和 softmax 概率会是最大的(可类比本文问题 1)。
因此,Embedding 层和 FC 层权重共享,Embedding 层中和向量 x 最接近的那一行对应的词,会获得更大的预测概率。实际上,Decoder 中的 Embedding 层和 FC 层有点像互为逆过程。
通过这样的权重共享可以减少参数的数量,加快收敛。
3.4 小结
本文详细介绍了 Transformer 的细节,包括 Encoder,Decoder 部分,输出解码的部分,Transformer 的共享机制等等。
- 参考文献
Attention Is All You Need