学习目标/Target
掌握网站转化率统计实现思路
了解如何生成用户浏览网页数据
掌握如何创建Spark连接并读取数据集
掌握利用Spark SQL统计每个页面访问次数
掌握利用Spark SQL获取每个用户浏览网页的顺序
掌握利用Spark SQL合并同一用户浏览的网页
掌握利用Spark SQL统计每个单跳的次数
掌握利用Spark SQL计算页面单跳转化率
掌握将数据持久化到HBase数据库
熟悉通过Spark On YARN运行程序
概述
网站转化率(conversion rate)是指用户进行了相应目标行动的访问次数与总访问次数的比率。这里所指的相应目标行动可以是用户登录、用户注册、用户浏览、用户购买等一系列用户行为,因此网站转化率是一个广义的概念。页面单跳转化率是网站转化率的一种统计形式,通过统计页面单跳转化率,来优化页面布局及营销策略,使访问网站的用户可以更深层次的浏览网站。本章我们将对用户浏览网页数据进行分析,从而统计出页面单跳转化率。
1. 数据集分析
通过编写的Java程序模拟生成用户浏览网页数据作为数据集,数据集中的每一行数据代表一个用户的浏览行为,所有浏览行为都与页面-和用户有关。
{ "actionTime":"2020-07-22 06:34:02", "sessionid":"98ac879b5a0a4a4eb117dffd84da1ff4", "pageid":3, "userid":8 }
actionTime: 用户访问页面的时间;
sessionid:用于标识用户行为的唯一值;
pageid:用户浏览网页的ID;
userid:用户ID;
2.实现思路分析
当用户浏览网页时,通过当前浏览页面(A)跳转到另一个页面(B),此用户行为被称为一次A→B的单跳。如计算A→B的页面单跳转化率,则计算公式如下。
A→B页面单跳转化率=A→B的单跳总数/A总访问次数
计算页面单跳转化率需要两部分数据,分别是A→B的单跳总数和A总访问次数。
A总访问次数可以通过聚合操作获取,A→B的单跳总数实现思路如下。
根据用户ID和访问时间对数据集进行排序操作,获取每个用户浏览网页的顺序。
根据用户ID对排序后的数据进行分组操作,将同一用户浏览的网页进行合并。
对分组后的数据进行转换操作,将同一用户浏览的网页按照浏览顺序转换为单跳形式。
对转换后的数据进行聚合操作统计每个单跳的总数,其中包括A→B的单跳总数。
页面单跳转化率统计实现过程。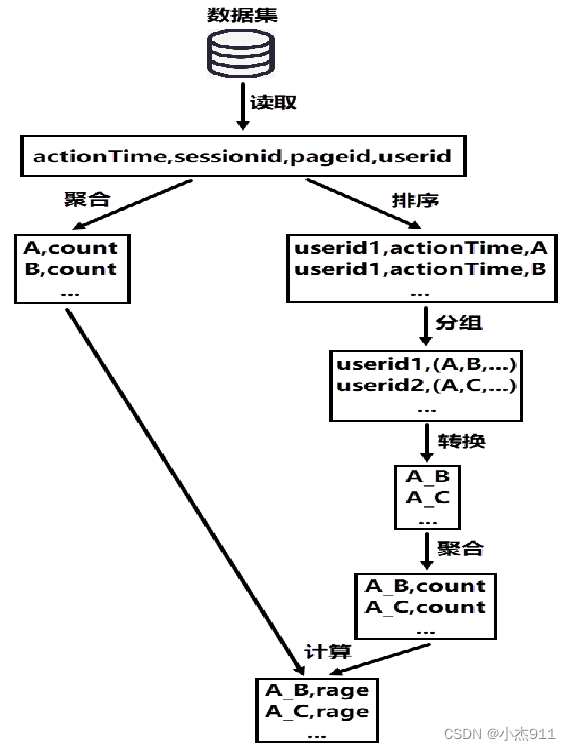
3.实现网站转化率统计
3.1 生成用户浏览网页数据
在项目SparkProject的 java目录新建Package包“cn.itcast.conversion”,用于存放实现网站转化率统计的Java文件。在包“cn.itcast.conversion”中创建文件GenerateData.java,用于模拟生成用户浏览网页数据。
选中文件GenerateData.java并单击右键,在弹出的菜单栏选择“Run.GenerateData.main()”运行程序,生成用户浏览网页数据。
程序运行完成后在“D:\\sparkdata”目录中会生成JSON文件user_conversion.json,该文件包含用户浏览网页数据。
3.2 修改pom.xml文件
由于实现网站转化率统计是通过Spark SQL程序实现,所以需要在项目SparkProject的pom.xml文件中添加Spark SQL依赖。
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.3.2</version>
</dependency>
3.3 创建Spark连接并读取数据集
在项目SparkProject的包“cn.itcast.conversion”中创建文件PageConversion.java,用于实现网站转化率统计。
public class PageConversion {
public static void main(String[] arg){
//实现Spark SQL程序
}
在文件PageConversion.java的main()方法中创建SparkSession对象,用于实现Spark SQL程序。
SparkSession spark = SparkSession
.builder()
//设置Application名称为page_conversion
.appName("page_conversion")
.getOrCreate();
在文件PageConversion.java的main()方法中,调用SparkSession对象的read().json()方法读取外部JSON文件,将JSON文件中的数据加载到userConversionDS。
Dataset<Row> userConversionDS = spark.read().json(arg[0]);
在文件PageConversion.java的main()方法中,调用DataSet的createOrReplaceTempView()方法,将userConversionDS创建为全局临时视图conversion_table。
userConversionDS.createOrReplaceTempView("conversion_table");
3.4 统计每个页面访问次数
在文件PageConversion.java的main()方法中,调用SparkSession的sql()方法统计每个页面访问次数,将统计结果加载到pageIdPvDS。
Dataset<Row> pageIdPvDS = spark
.sql("select pageid,count(*) as pageid_count " +
"from conversion_table " +
"group by pageid");
3.5 获取每个用户浏览网页的顺序\
在文件PageConversion.java的main()方法中,调用SparkSession的sql()方法对每个用户浏览网页的顺序进行排序,将排序结果加载到useridGroupSortDS。
Dataset<Row> useridGroupSortDS = spark
.sql("select userid,actionTime,pageid " +
"from conversion_table " +
"order by userid,actionTime");
在文件PageConversion.java的main()方法中,调用DataSet的createOrReplaceTempView()方法,将useridGroupSortDS创建为全局临时视图conversion_group_sort_table。
useridGroupSortDS.createOrReplaceTempView("conversion_group_sort_table");
3.6 合并同一用户浏览的网页
在文件PageConversion.java的main()方法中,调用SparkSession的sql()方法对同一用户浏览的网页进行合并,将合并结果加载到pageConversionRDD。为了后续使用flatMap()算子对合并后的数据进行扁平化处理,这里通过SparkSession的toJavaRDD()方法将DataSet转为JavaRDD。
JavaRDD<Row> pageConversionRDD = spark.sql("select userid," + "concat_ws(',',collect_list(pageid)) as column2s " + "from conversion_group_sort_table " + "group by userid").toJavaRDD();
3.7 统计每个单跳的次数
在文件PageConversion.java的main()方法中,使用flatMap()算子对pageConversionRDD进行扁平化处理,根据用户浏览网页的顺序将相邻网页拼接为单跳,将处理结果加载到rowRDD。
JavaRDD<Row> rowRDD = pageConversionRDD.flatMap(new FlatMapFunction<Row, Row>() { @Override public Iterator<Row> call(Row row) throws Exception {
List<Row> list = new ArrayList<>();
String[] page = row.get(1).toString().split(",");
String pageConversionStr = "";
for (int i = 0;i<page.length-1;i++){
if (!page[i].equals(page[i+1])){
pageConversionStr = page[i]+"_"+page[i+1];
list.add(RowFactory.create(pageConversionStr));
}
}
return list.iterator();
}
});
在文件PageConversion.java的main()方法中,调用SparkSession的createDataFrame()方法和 registerTempTable()方法,将存储单跳数据的rowRDD注册临时表page_conversion_table。
StructType schema = DataTypes.createStructType(new StructField[]{ DataTypes.createStructField( "page_conversion",DataTypes.StringType,true) }); spark.createDataFrame(rowRDD, schema).registerTempTable("page_conversion_table");
在文件PageConversion.java的main()方法中,使用SparkSession的sql()方法统计每个单跳的次数,根据统计结果创建全局临时视图page_conversion_count_table。
spark.sql(
"select page_conversion," +
"count(*) as page_conversion_count " +
"from page_conversion_table " +
"group by page_conversion")
.createOrReplaceTempView("page_conversion_count_table");
3.8 计算页面单跳转化率
通过页面单跳转化率的计算公式得知,若要计算单跳A→B的页面单跳转化率,首先需要获取页面A的访问次数,然后需要获取单跳A→B的次数,最终将这两部分数据代入页面单跳转化率的计算公式中计算单跳A→B的页面单跳转化率。 在计算每个单跳的页面单跳转化率之前,需要将每个页面与每个单跳进行一一对应,也就是说如果计算单跳A→B的页面单跳转化率,那么代入页面单跳转化率计算公式中的一定是页面A的访问次数,而不能是页面B或C的访问次数。
在文件PageConversion.java的main()方法中,使用SparkSession的sql()方法拆分单跳为起始页面和结束页面,将拆分后的数据加载到pageConversionCountDS。
Dataset<Row> pageConversionCountDS = spark
.sql("select page_conversion_count," +
"split(page_conversion,'_')[0] as start_page," +
"split(page_conversion,'_')[1] as last_page " +
"from page_conversion_count_table");
在文件PageConversion.java的main()方法中,使用join()算子对pageIdPvDS(存储每个页面访问的次数)和pageConversionCountDS(存储每个单跳拆分后的数据)进行连接,根据连接结果创建全局临时视图page_conversion_join。
pageConversionCountDS.join(
pageIdPvDS,
new Column("start_page").equalTo(new Column("pageid")), "left").createOrReplaceTempView("page_conversion_join");
在文件PageConversion.java的main()方法中,使用SparkSession的sql()计算页面单跳转化率,将计算结果加载到resultDS。
Dataset<Row> resultDS = spark .sql("select " +
"concat(pageid,'_',last_page) as conversion," +
"round(" +
"CAST(page_conversion_count AS DOUBLE)/CAST(pageid_count AS DOUBLE)" +
",3) as rage " +
"from page_conversion_join");
3.9 数据持久化
在PageConversion类中添加方法conversionToHBase(),用于将页面单跳转化率统计结果持久化到HBase数据库中,该方法包含参数dataset,表示需要向方法中传递页面单跳转化率统计结果数据。
public static void conversionToHBase(Dataset<Row> dataset) throws IOException { HbaseUtils.createTable("conversion","page_conversion");
String[] column = {"convert_page","convert_rage"};
dataset.foreach(new ForeachFunction<Row>() {
@Override
public void call(Row row) throws Exception {
String conversion = row.get(0).toString();
String rage = row.get(1).toString();
String[] value ={conversion,rage};
HbaseUtils.putsToHBase("conversion",conversion+rage,"page_conversion",column,value);
}
});
}
在文件PageConversion.java的main()方法中,调用conversionToHBase()方法并传入参数resultDS,用于在Spark SQL程序中实现conversionToHBase()方法,将页面单跳转化率统计结果数据持久化到HBase数据库中的数据表conversion。
try {
conversionToHBase(resultDS);
} catch (IOException e) {
e.printStackTrace(); }
HbaseConnect.closeConnection();
spark.close();
4.运行程序
在IntelliJ IDEA中将页面单跳转化率统计程序封装成jar包,并上传到集群环境中,通过spark-submit将程序提交到YARN中运行。
封装jar包:
由于在封装各区域热门商品Top3分析程序jar包时,将程序主类指向了“cn.itcast.top3.AreaProductTop3”,因此这里需要将pom.xml文件中的程序主类修改为“cn.itcast.conversion.PageConversion”。根据封装热门品类Top10分析程序jar包的方式封装页面单跳转化率统计程序。将封装完成的jar包重命名为“PageConversion”,通过远程连接工具SecureCRT将PageConversion.jar上传到虚拟机Spark01的/export/SparkJar/目录下。
将数据集上传到本地文件系统:
使用远程连接工具SecureCRT连接虚拟机Spark01,在存放数据文件的目录/export/data/SparkData/(该目录需提前创建)下执行“rz”命令,将数据集user_conversion.json上传至本地文件系统。
在HDFS创建存放数据集的目录:
将数据集上传到HDFS前,需要在HDFS的根目录创建目录page_conversion,用于存放数据集user_conversion.json。
hdfs dfs -mkdir /page_conversion
上传数据集到HDFS:
将目录/export/data/SparkData/下的数据集user_conversion.json上传到HDFS的page_conversion目录下,具体命令如下。
hdfs dfs -put /export/data/SparkData/user_conversion.json /page_conversion
提交页面单跳转化率统计程序到YARN集群:
通过Spark安装目录中bin目录下的shell脚本文件spark-submit提交页面单跳转化率统计程序到YARN集群运行。
spark-submit \
--master yarn \
--deploy-mode cluster \
--num-executors 3 \
--executor-memory 2G \
--class cn.itcast.conversion.PageConversion \
/export/SparkJar/PageConversion.jar /page_conversion/user_conversion.json
查看程序运行结果:
在虚拟机Spark01执行“hbase shell”命令,进入HBase命令行工具。
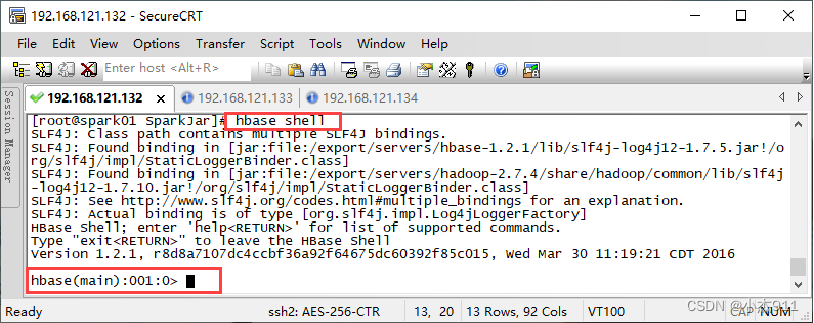
在HBase命令行工具中执行“list”命令,查看HBase数据库中的所有数据表。
> list
TABLE conversion
查看程序运行结果
在HBase命令行工具执行“scan 'conversion'”命令,查看数据表conversion中所有数据。
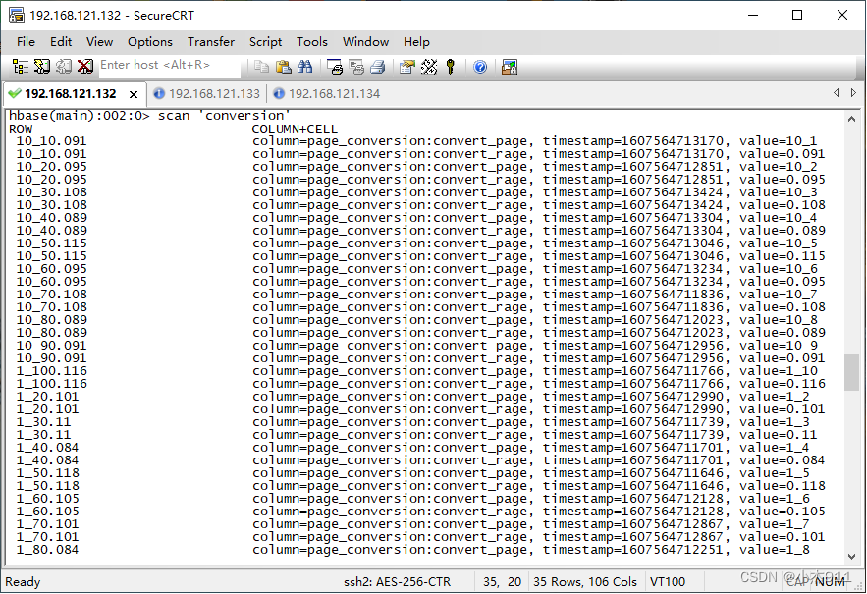
本文主要讲解了如何通过用户浏览网页数据实现网站转化率统计,首先我们对数据集进行分析,使读者了解用户浏览网页数据的数据结构。接着通过实现思路分析,使读者了解网站转化率统计的实现流程。然后通过IntelliJ IDEA开发工具实现网站转化率统计程序并将统计结果存储到HBase数据库,使读者掌握运用Java语言编写Spark SQL和HBase程序的能力。最后封装网站转化率统计程序并提交到集群运行,使读者掌握运用IntelliJ IDEA开发工具封装Spark SQL程序以及Spark ON YARN模式运行Spark SQL程序的方法。
](https://img-blog.csdnimg.cn/b091d34c87e74c39b3f8be09ad52c4e9.png)