前言
哈希算法在程序开发中的很多地方都能看到他的身影,但是哈希有他的局限性,比如如果两个key哈希到同一个位置的时候,此时就不好处理。本节我们介绍一下常规处理方式。
1. 什么是哈希算法
哈希算法将任意长度的二进制值映射为较短的固定长度的二进制值,这个小的二进制值称为哈希值。哈希值是一段数据唯一且极其紧凑的数值表现形式。一般用于快速查找和加密算法。
简单解释:哈希(Hash)算法,即散列函数。它是一种单向密码体制,即它是一个从明文到密文的不可逆的映射,只有加密过程 没有解密过程。同时,哈希函数可以将任意长度的输入经过变化以后得到固定长度的输出。哈希函数的这种单向特征和输出数据长度固定的特征使得它可以生成消息或者数报。
2. 哈希算法在分布式场景中的应用场景
Hash算法在很多分布式集群产品中都有应⽤,⽐如分布式集群架构Redis、Hadoop、ElasticSearch,Mysql分库分表,Nginx负载均衡等。
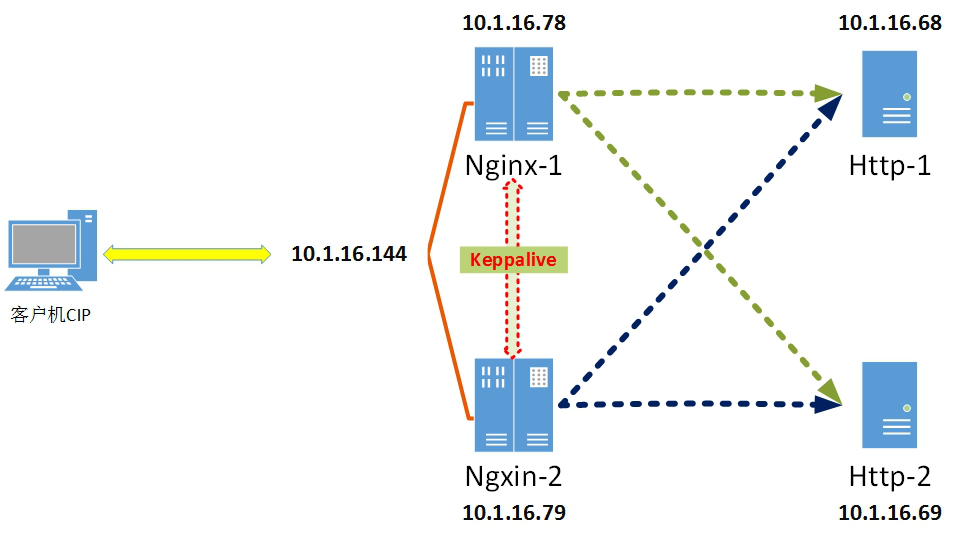
2.1 请求的负载均衡
nginx的ip_hash策略,通过对ip地址或者sessionid进⾏计算哈希值,哈希值与服务器数量进⾏取模运算,得到的值就是当前请求应该被路由到的服务器编号,如此,同⼀个客户端ip发送过来的请求就可以路由到同⼀个⽬标服务器,实现会话粘滞
2.2 分布式存储
以分布式内存数据库Redis为例,集群中有redis1,redis2,redis3 三台Redis服务器。那么,在进⾏数据存储时,<key1,value1>数据存储到哪个服务器当中呢?针对key进⾏hash处理hash(key1)%3=index, 使⽤余数index锁定存储的具体服务器节点。
分库分表的数据库可以同样用类似逻辑处理。
3. 哈希算法存在的问题
3.1 哈希碰撞
index = HashCode (Key) % Array.length
int index=Math.abs("Hello".hashCode())%10; (0-9)
以上面的demo为例,对象Hash的前提是hashCode()方法,那么HashCode()的作用就是保证对象返回唯一hash值,但当两个对象计算值一样时,这就发生了碰撞冲突。
当我们对某个元素进行哈希运算,得到一个存储地址,然后要进行插入的时候,发现已经被其他元素占用了,其实这就是所谓的哈希冲突,也叫哈希碰撞。
简单来说,就是两个不同的待存储元素,经过哈希函数计算后得到的存储位置一样,这样两个存储元素就冲突了。举个极端的例子,当长度为10 的数组要存储11个元素的时候,那么哈希碰撞一定会发生。
3.2 哈希碰撞常见解决方式
3.2.1 开放寻址法
开放寻址法的原理是当一个Key通过哈希函数获得对应的数组下标已被占用时,就寻找下一个空档位置。
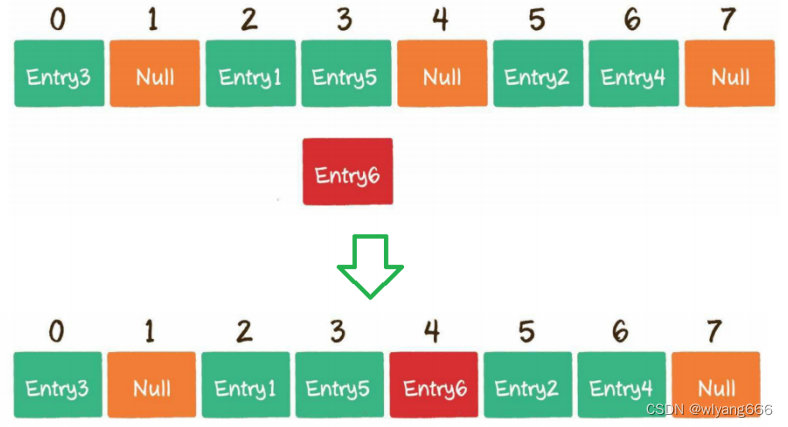
在Java中,ThreadLocal所使用的就是开放寻址法
3.2.2 拉链法
数组的每一个元素不仅是一个Entry对象,还是一个链表的头节点。每一个Entry对象通过next指针指向它的下一个Entry节点。当新来的Entry映射到与之冲突的数组位置时,只需要插入到对应的链表中即可,默认next指向null
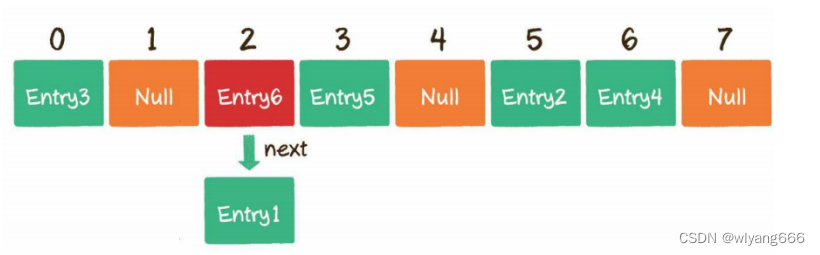
在Java中,HashMap所使用的就是链表法。(这里留意java8中,当节点元素过多的时候,为避免链表过长,链表会调整为红黑树)
3.3 分布式环境中的问题
我们知道哈希算法中很重要的两个因素,一个是哈希表,一个是哈希函数,哈希函数的好坏决定数据能不能均衡的分布在哈希表中,如果哈希算法不好的话,可能很多值会路由到同一个位置,造成频繁的哈希碰撞。极端情况会导致哈希表退化为单链表。
哈希表的长度也是很重要的因素,如果太短的话,可能会导致很多元素挂在链表上,最终退化为单链表,如果长度过长的话,会造成内存空间的浪费。
在分布式环境中,常见的场景是服务的扩容缩容,以上面提到的例子为例,比如mysql存储到瓶颈了,我们需要扩容mysql节点,此时就需要扩容。比如双十一的时候,我们为了支持更多的请求处理,在nginx后面加了多台tomcat 服务器处理请求,在双十一过后,请求没那么多,我们可以选择释放部分服务器资源,节省服务器成本。
3.4 本质
通过上面举例子可以看到,哈希算法用的好,确实可以提高我们的查询效率。但是不管是在jdk中的hashmap扩容缩容,还是我们分布式场景中的服务器资源扩容缩容,其实本质上都是对哈希表的扩容缩容。而固定的哈希函数在扩容缩容的时候,需要存储的元素重新哈希计算元素的在扩容后的哈希表中的位置。
那么,有没有其他办法,在哈希表扩容缩容的时候,不重新计算所有元素位置呢,就是下面的一致性哈希算法。
4. 一致性哈希算法
⾸先有⼀条直线,直线开头和结尾分别定为为1和2的32次⽅减1,这相当于⼀个地址,对于这样⼀条线,弯过来构成⼀个圆环形成闭环,这样的⼀个圆环称为hash环。我们把服务器的ip或者主机名求hash值然后对应到hash环上,那么针对客户端⽤户,也根据它的ip进⾏hash求值,对应到环上某个位置,然后如何确定⼀个客户端路由到哪个服务器处理呢?

按照顺时针⽅向找最近的服务器节点。
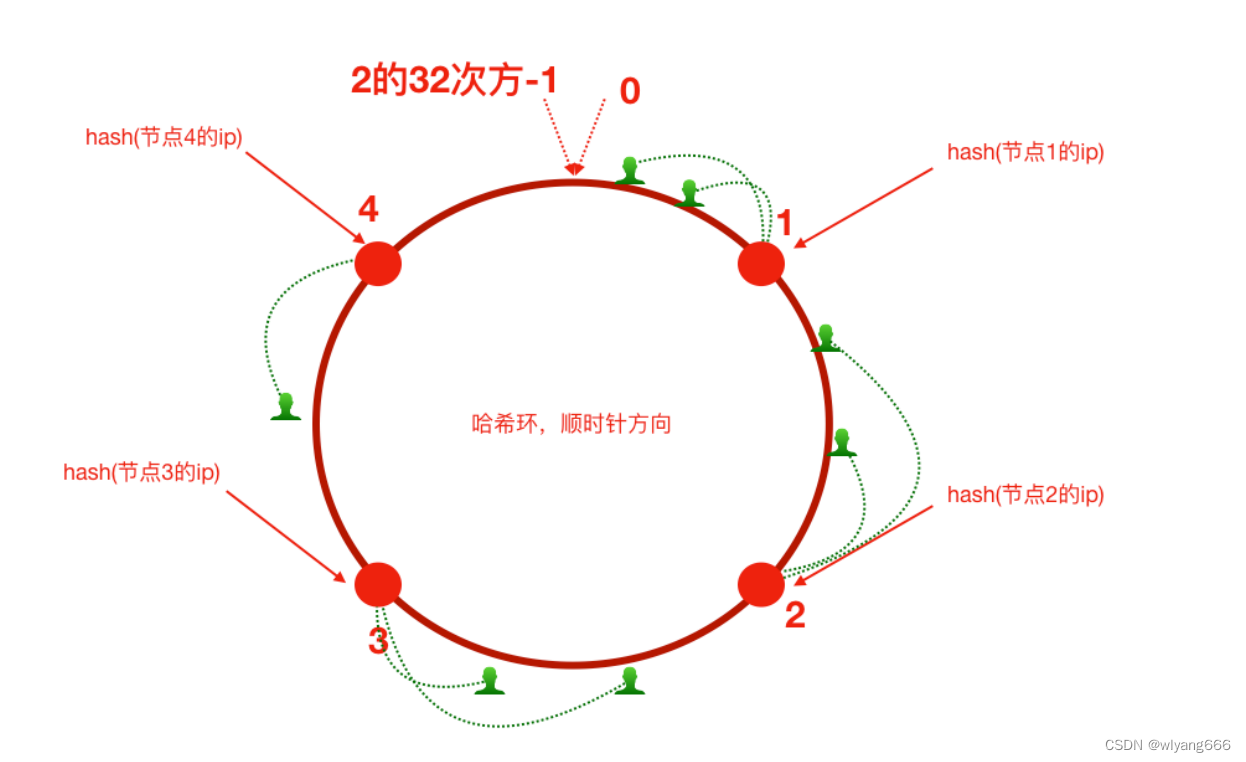
假如将服务器3下线,服务器3下线后,原来路由到3的客户端重新路由到服务器4,对于其他客户端没有影响只是这⼀⼩部分受影响(请求的迁移达到了最⼩,这样的算法对分布式集群来说⾮常合适的,避免了⼤量请求迁移 )
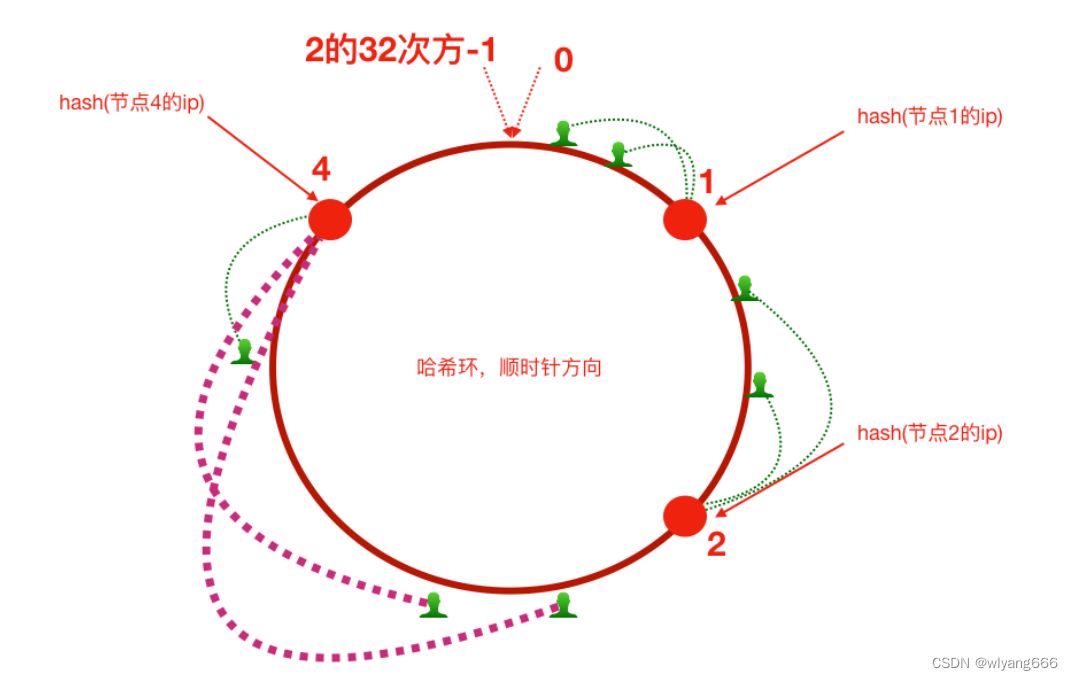
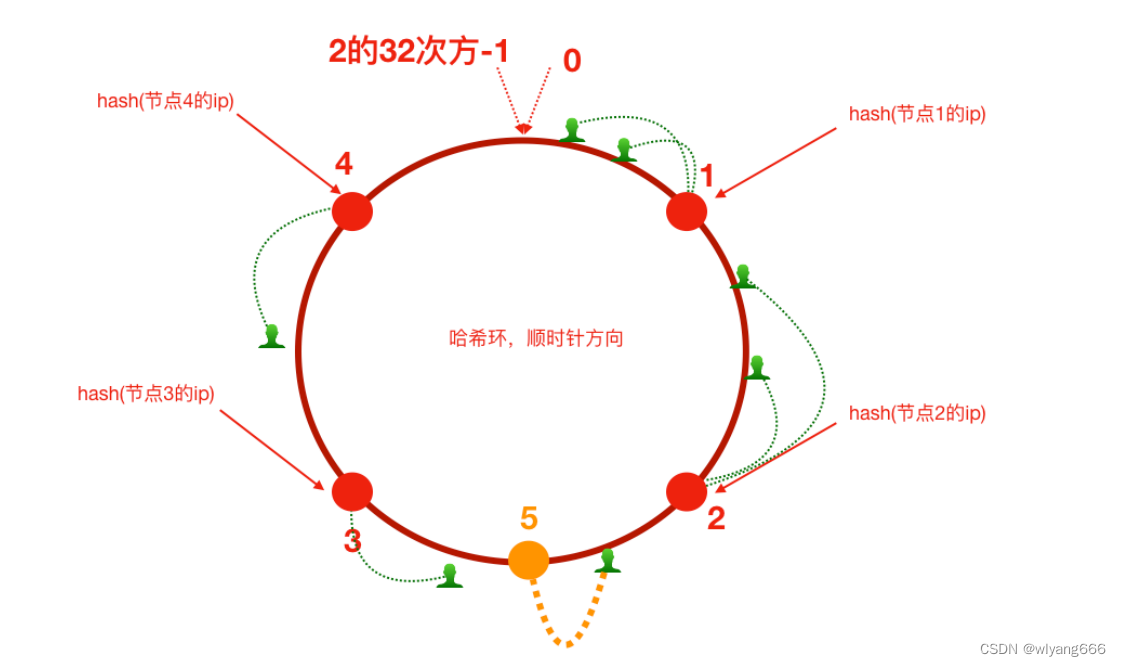
增加服务器5之后,原来路由到3的部分客户端路由到新增服务器5上,对于其他客户端没有影响只是这⼀⼩部分受影响(请求的迁移达到了最⼩,这样的算法对分布式集群来说⾮常合适的,避免了⼤量请求迁移 )
5. 手写一致性哈希算法
5.1 普通哈希
package org.wanlong.hash;
/**
* @author wanlong
* @version 1.0
* @description: 普通哈希
* @date 2023/5/23 13:37
*/
public class GeneralHash {
public static void main(String[] args) {
// 定义客户端IP
String[] clients = new String[]
{"102.178.122.12", "23.243.63.2", "8.8.8.8"};
// 定义服务器数量
int serverCount = 3;// (编号对应0,1,2)
// hash(ip)%node_counts=index
//根据index锁定应该路由到的tomcat服务器
for (String client : clients) {
int hash = Math.abs(client.hashCode());
int index = hash % serverCount;
System.out.println("客户端:" + client + " 被路由到服务器编号为:"
+ index);
}
}
}
5.2 一致性哈希
package org.wanlong.hash;
import java.util.SortedMap;
import java.util.TreeMap;
/**
* @author wanlong
* @version 1.0
* @description: 一致性哈希
* @date 2023/5/23 13:40
*/
public class ConsistHash {
public static void main(String[] args) {
//step1 初始化:把服务器节点IP的哈希值对应到哈希环上
// 定义服务器ip
String[] tomcatServers = new String[]
{"23.23.0.0", "7.4.3.1", "7.6.6.8", "6.6.7.7"};
SortedMap<Integer, String> hashServerMap = new TreeMap<>();
for (String tomcatServer : tomcatServers) {
// 求出每⼀个ip的hash值,对应到hash环上,存储hash值与ip的对应关系
int serverHash = Math.abs(tomcatServer.hashCode());
// 存储hash值与ip的对应关系
hashServerMap.put(serverHash, tomcatServer);
}
//step2 针对客户端IP求出hash值
// 定义客户端IP
String[] clients = new String[]
{"8.8.8.8","709.7.8.1","787.4.2.5"};
for(String client : clients) {
int clientHash = Math.abs(client.hashCode());
//step3 针对客户端,找到能够处理当前客户端请求的服务器(哈希环上顺时针最近)
// 根据客户端ip的哈希值去找出哪⼀个服务器节点能够处理()
SortedMap<Integer, String> integerStringSortedMap =
hashServerMap.tailMap(clientHash);
if(integerStringSortedMap.isEmpty()) {
// 取哈希环上的顺时针第⼀台服务器
Integer firstKey = hashServerMap.firstKey();
System.out.println("==========>>>>客户端:" + client + " 被 路由到服务器:" + hashServerMap.get(firstKey));
}else{
Integer firstKey = integerStringSortedMap.firstKey();
System.out.println("==========>>>>客户端:" + client + " 被 路由到服务器:" + hashServerMap.get(firstKey));
}
}
}
}
5.3 一致性哈希包含虚拟节点
package org.wanlong.hash;
import java.util.SortedMap;
import java.util.TreeMap;
/**
* @author wanlong
* @version 1.0
* @description: 包含虚拟节点的一致性哈希
* @date 2023/5/23 13:41
*/
public class ConsistentHashWithVirtual {
public static void main(String[] args) {
//step1 初始化:把服务器节点IP的哈希值对应到哈希环上
// 定义服务器ip
String[] tomcatServers = new String[]
{"23.23.0.0", "7.4.3.1", "7.6.6.8", "6.6.7.7"};
SortedMap<Integer, String> hashServerMap = new TreeMap<>();
// 定义针对每个真实服务器虚拟出来⼏个节点
int virtaulCount = 3;
for (String tomcatServer : tomcatServers) {
// 求出每⼀个ip的hash值,对应到hash环上,存储hash值与ip的对应关系
int serverHash = Math.abs(tomcatServer.hashCode());
// 存储hash值与ip的对应关系
hashServerMap.put(serverHash, tomcatServer);
// 处理虚拟节点
for (int i = 0; i < virtaulCount; i++) {
int virtualHash = Math.abs((tomcatServer + "#" + i).hashCode());
hashServerMap.put(virtualHash, "----由虚拟节点" + i + "映射过 来的请求:" + tomcatServer);
}
}
//step2 针对客户端IP求出hash值
// 定义客户端IP
String[] clients = new String[]
{"8.8.8.8","709.7.8.1","787.4.2.5"};
for (String client : clients) {
int clientHash = Math.abs(client.hashCode());
//step3 针对客户端,找到能够处理当前客户端请求的服务器(哈希环上顺时针最近)
// 根据客户端ip的哈希值去找出哪⼀个服务器节点能够处理()
SortedMap<Integer, String> integerStringSortedMap =
hashServerMap.tailMap(clientHash);
if (integerStringSortedMap.isEmpty()) {
// 取哈希环上的顺时针第⼀台服务器
Integer firstKey = hashServerMap.firstKey();
System.out.println("==========>>>>客户端:" + client + " 被 路由到服务器:" + hashServerMap.get(firstKey));
} else {
Integer firstKey = integerStringSortedMap.firstKey();
System.out.println("==========>>>>客户端:" + client + " 被 路由到服务器:" + hashServerMap.get(firstKey));
}
}
}
}
6. 参考文档
部分图片案例来源
以上,本人菜鸟一枚,如有错误,请不吝指正。