文章目录
- 0、十大经典排序算法
- 0.1 关于时间复杂度
- 0.2 关于稳定性
- 1、冒泡排序(Bubble Sort)
- 1.1 冒泡排序简介
- 1.2 冒泡排序思路
- 1.3 冒泡排序代码实现
- 2、快排
- 2.1 快排简介
- 2.2 快排思路
- 2.3 快排代码实现
0、十大经典排序算法
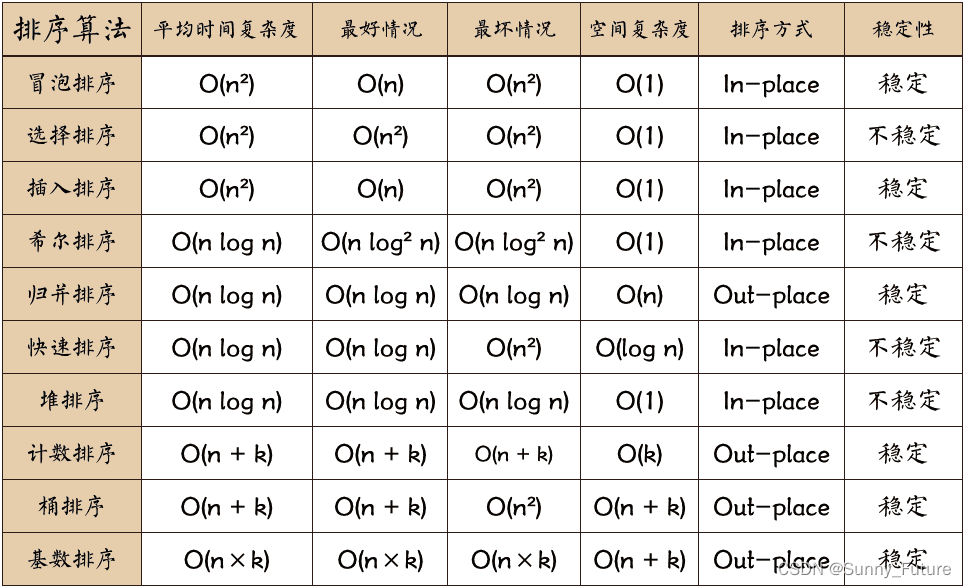
0.1 关于时间复杂度
- 平方阶 (O(n2)) 排序 各类简单排序:直接插入、直接选择和冒泡排序。
- 线性对数阶 (O(nlog2n)) 排序 快速排序、堆排序和归并排序;
- O(n1+§)) 排序,§ 是介于 0 和 1 之间的常数。 希尔排序
- 线性阶 (O(n)) 排序 基数排序,此外还有桶、箱排序。
0.2 关于稳定性
稳定的排序算法:冒泡排序、插入排序、归并排序和基数排序。
不是稳定的排序算法:选择排序、快速排序、希尔排序、堆排序。
1、冒泡排序(Bubble Sort)
1.1 冒泡排序简介
冒泡排序(Bubble Sort)也是一种简单直观的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
1.2 冒泡排序思路
-
比较相邻的元素。如果第一个比第二个大,就交换他们两个。
-
对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
-
针对所有的元素重复以上的步骤,除了最后一个。
-
持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
1.3 冒泡排序代码实现
def bubble_sort(arr):
for i in range(len(arr)):
for j in range(len(arr)):
if arr[i] < arr[j]:
arr[i], arr[j] = arr[j], arr[i]
return arr
2、快排
2.1 快排简介
快速排序是由东尼·霍尔所发展的一种排序算法。在平均状况下,排序 n 个项目要 Ο(nlogn) 次比较。在最坏状况下则需要 Ο(n2) 次比较,但这种状况并不常见。事实上,快速排序通常明显比其他 Ο(nlogn) 算法更快,因为它的内部循环(inner loop)可以在大部分的架构上很有效率地被实现出来。
快速排序使用分治法(Divide and conquer)策略来把一个串行(list)分为两个子串行(sub-lists)。
快速排序又是一种分而治之思想在排序算法上的典型应用。本质上来看,快速排序应该算是在冒泡排序基础上的递归分治法。
快速排序的最坏运行情况是 O(n²),比如说顺序数列的快排。但它的平摊期望时间是 O(nlogn),且 O(nlogn) 记号中隐含的常数因子很小,比复杂度稳定等于 O(nlogn) 的归并排序要小很多。所以,对绝大多数顺序性较弱的随机数列而言,快速排序总是优于归并排序。
2.2 快排思路
-
从数列中挑出一个元素,称为 “基准”(pivot);
-
重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
-
递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序;
递归的最底部情形,是数列的大小是零或一,也就是永远都已经被排序好了。虽然一直递归下去,但是这个算法总会退出,因为在每次的迭代(iteration)中,它至少会把一个元素摆到它最后的位置去。
2.3 快排代码实现
def quick_sort(arr):
if len(arr) < 2:
return arr
else:
p = arr[0]
less = [i for i in arr[1:] if i <= p]
great = [i for i in arr[1:] if i > p]
return quick_sort(less) + [p] + quick_sort(great)