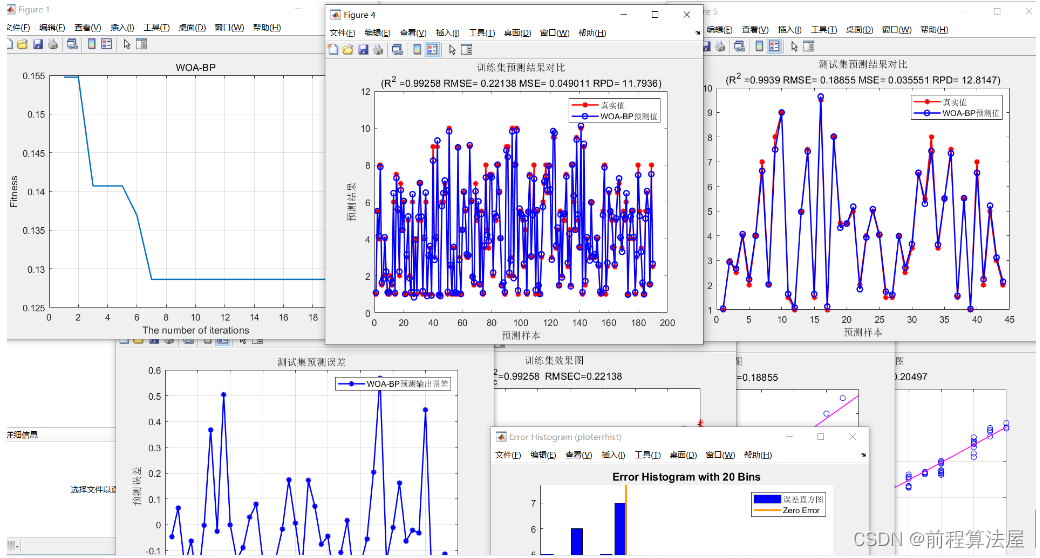
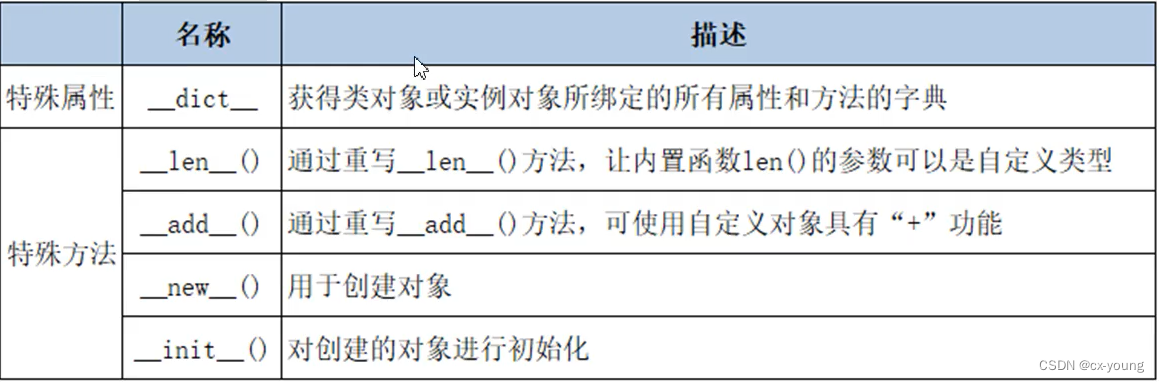
前言:MyBatis-Plus 集成百度的uid-generator ,实现业务实体在insert 实体时,可以自动获取全局id,完成数据保存;
1 uid-generator 全局id 生成的方式了解:
Snowflake算法描述:指定机器 & 同一时刻 & 某一并发序列,是唯一的。据此可生成一个64 bits的唯一ID(long)。默认采用上图字节分配方式:

-
sign(1bit):固定1bit符号标识,即生成的UID为正数;
-
delta seconds (28 bits):当前时间,相对于时间基点"2016-05-20"的增量值,单位:秒,最多可支持约8.7年;
-
worker id (22 bits):机器id,最多可支持约420w次机器启动。内置实现为在启动时由数据库分配,默认分配策略为用后即弃,后续可提供复用策略。
-
sequence (13 bits):每秒下的并发序列,13 bits可支持每秒8192个并发。
以上参数均可通过Spring进行自定义;可以看到uid-generator 是一种优化后的雪花算法;官方文档;
2 搭建uid-generator 服务:
2.1 需要创建一个数据库,并创建WORKER_NODE表:
CREATE TABLE `WORKER_NODE` (
`ID` bigint NOT NULL AUTO_INCREMENT COMMENT 'auto increment id',
`HOST_NAME` varchar(64) NOT NULL COMMENT 'host name',
`PORT` varchar(64) NOT NULL COMMENT 'port',
`TYPE` int NOT NULL COMMENT 'node type: ACTUAL or CONTAINER',
`LAUNCH_DATE` date NOT NULL COMMENT 'launch date',
`MODIFIED` timestamp NOT NULL COMMENT 'modified time',
`CREATED` timestamp NOT NULL COMMENT 'created time',
PRIMARY KEY (`ID`)
) ENGINE=InnoDB AUTO_INCREMENT=15 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='DB WorkerID Assigner for UID Generator';
WORKER_NODE表的作用:
因为uid-generator 本质是优化的雪花id生成算法,此WORKER_NODE 用来在每次服务启动时,都可以向WORKER_NODE表插入一条数据,并使用返回的数据主键id ,作为workId 来参与全局id 的生成;
2.2 引入百度uid-generator jar:因为项目中已经集成了这里-MyBatis-Plus,所以排除掉uid-generator的jar包,避免冲突;
<dependency>
<groupId>com.xfvape.uid</groupId>
<artifactId>uid-generator</artifactId>
<version>0.0.4-RELEASE</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>log4j-over-slf4j</artifactId>
</exclusion>
<exclusion>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
</exclusion>
<exclusion>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
</exclusion>
<exclusion>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
</exclusion>
</exclusions>
</dependency>
2.3 生成 WORKER_NODE表对应的实体,service 和mapper 及mapper.xml:
WorkerNode 实体:
package com.example.uidtake.domain;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import java.util.Date;
import java.util.concurrent.TimeUnit;
@Data
@TableName("WORKER_NODE")
public class WorkerNode {
private static final long serialVersionUID = 1L;
@TableId(value = "id", type = IdType.AUTO)
private Integer id;
private String hostName;
private String port;
private Integer type;
private Date launchDate;
private Date modified;
private Date created;
}
WorkerNodeMapper:
package com.example.uidtake.mapper;
import com.example.uidtake.domain.WorkerNode;
import org.apache.ibatis.annotations.Param;
import org.springframework.stereotype.Repository;
@Repository
public interface WorkerNodeMapper {
int addWorkerNode(WorkerNode workerNodeEntity);
WorkerNode getWorkerNodeByHostPort(@Param("host") String host, @Param("port") String port);
}
WorkerNodeMapper.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.uidtake.mapper.WorkerNodeMapper">
<resultMap id="BaseResultMap"
type="com.example.uidtake.domain.WorkerNode">
<id column="ID" jdbcType="BIGINT" property="id"/>
<result column="HOST_NAME" jdbcType="VARCHAR" property="hostName"/>
<result column="PORT" jdbcType="VARCHAR" property="port"/>
<result column="TYPE" jdbcType="INTEGER" property="type"/>
<result column="LAUNCH_DATE" jdbcType="DATE" property="launchDate"/>
<result column="MODIFIED" jdbcType="TIMESTAMP" property="modified"/>
<result column="CREATED" jdbcType="TIMESTAMP" property="created"/>
</resultMap>
<insert id="addWorkerNode" useGeneratedKeys="true" keyProperty="id"
parameterType="com.example.uidtake.domain.WorkerNode">
INSERT INTO WORKER_NODE
(HOST_NAME,
PORT,
TYPE,
LAUNCH_DATE,
MODIFIED,
CREATED)
VALUES (#{hostName},
#{port},
#{type},
#{launchDate},
NOW(),
NOW())
</insert>
<select id="getWorkerNodeByHostPort" resultMap="BaseResultMap ">
SELECT ID,
HOST_NAME,
PORT,
TYPE,
LAUNCH_DATE,
MODIFIED,
CREATED
FROM WORKER_NODE
WHERE HOST_NAME = #{host}
AND PORT = #{port}
</select>
</mapper>
service:
IWorkerNodeService:
package com.example.uidtake.worker.service;
public interface IWorkerNodeService {
public long genUid();
}
WorkerNodeServiceImpl:
package com.example.uidtake.worker.service.impl;
import com.example.uidtake.worker.service.IWorkerNodeService;
import com.xfvape.uid.UidGenerator;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
@Service
public class WorkerNodeServiceImpl implements IWorkerNodeService {
@Resource
private UidGenerator uidGenerator;
@Override
public long genUid() {
return uidGenerator.getUID();
}
}
2.4 定义uid 生成的bean:
DisposableWorkerIdAssigner:
package com.example.uidtake.worker;
import com.example.uidtake.domain.WorkerNode;
import com.example.uidtake.mapper.WorkerNodeMapper;
import com.xfvape.uid.utils.DockerUtils;
import com.xfvape.uid.utils.NetUtils;
import com.xfvape.uid.worker.WorkerIdAssigner;
import com.xfvape.uid.worker.WorkerNodeType;
import org.apache.commons.lang.math.RandomUtils;
import org.springframework.stereotype.Component;
import org.springframework.transaction.annotation.Transactional;
import javax.annotation.Resource;
import java.util.Date;
public class DisposableWorkerIdAssigner implements WorkerIdAssigner {
@Resource
private WorkerNodeMapper workerNodeMapper;
@Override
@Transactional
public long assignWorkerId() {
WorkerNode workerNode = buildWorkerNode();
workerNodeMapper.addWorkerNode(workerNode);
return workerNode.getId();
}
private WorkerNode buildWorkerNode() {
WorkerNode workNode = new WorkerNode();
if (DockerUtils.isDocker()) {
workNode.setType(WorkerNodeType.CONTAINER.value());
workNode.setHostName(DockerUtils.getDockerHost());
workNode.setPort(DockerUtils.getDockerPort());
workNode.setLaunchDate(new Date());
} else {
workNode.setType(WorkerNodeType.ACTUAL.value());
workNode.setHostName(NetUtils.getLocalAddress());
workNode.setPort(System.currentTimeMillis() + "-" + RandomUtils.nextInt(100000));
workNode.setLaunchDate(new Date());
}
return workNode;
}
}
WorkerNodeConfig :
package com.example.uidtake.config;
import com.example.uidtake.worker.DisposableWorkerIdAssigner;
import com.xfvape.uid.UidGenerator;
import com.xfvape.uid.impl.CachedUidGenerator;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class WorkerNodeConfig {
@Bean("disposableWorkerIdAssigner")
public DisposableWorkerIdAssigner disposableWorkerIdAssigner() {
DisposableWorkerIdAssigner disposableWorkerIdAssigner = new DisposableWorkerIdAssigner();
return disposableWorkerIdAssigner;
}
@Bean("cachedUidGenerator")
public UidGenerator uidGenerator(DisposableWorkerIdAssigner disposableWorkerIdAssigner) {
CachedUidGenerator cachedUidGenerator = new CachedUidGenerator();
cachedUidGenerator.setWorkerIdAssigner(disposableWorkerIdAssigner);
// 初始时间设置
cachedUidGenerator.setEpochStr("2023-01-01");
// 时间位数设置
cachedUidGenerator.setTimeBits(29);
// 机器位数设置
cachedUidGenerator.setWorkerBits(21);
// 序列号位数设置
cachedUidGenerator.setSeqBits(13);
// 以上配置,可以使用约16年,支持209万次的启动,每秒支持8192个序列id
return cachedUidGenerator;
}
}
测试类:UidTakeApplicationTests:
package com.example.uidtake;
import com.example.uidtake.worker.service.IWorkerNodeService;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
@SpringBootTest
class UidTakeApplicationTests {
@Autowired
private IWorkerNodeService workerNodeService;
@Test
void contextLoads() {
System.out.println("workerNodeService.genUid() = " + workerNodeService.genUid());
}
}
2.5 uid-generator的生成:
项目在每次启动时都会向容器注入WorkerNodeConfig bean 对象,在注入cachedUidGenerator 的bean时,通过为CachedUidGenerator 设置时间,机器位,序列号位,完成对原有数据的覆盖;
通过定义WorkerIdAssigner ,使得最终执行到我们自己定义的DisposableWorkerIdAssigner 类并执行,assignWorkerId的方法,assignWorkerId方法完成向WORKER_NODE 插入一条数据,并将插入成功的数据id 作为 workId 进行返回;
3 搭建uid 消费者服务:
消费uid-generator实现思路:MyBatis-Plus在定义业务实体的主键时,可以通过type = IdType.ASSIGN_ID,实现MyBatis-Plus为业务实体使用雪花算法生成唯一主键,MyBatis-Plus默认通过DefaultIdentifierGenerator 类的nextId 方法完成id 的生成,那么只要我们覆盖原有的DefaultIdentifierGenerator 并重写nextId 方法就可以实现自定义id 的生成; 在nextId 中只要实现 访问 uid-generator 生成id 的服务,来获取全局id,就实现了MyBatis-Plus集成百度分布式全局id(uid-generator);
本文通过feign 接口来调用uid-generator 生成id 的服务;
3.1 新建api maven 模块,并定义接口:
UidTakeService:
package org.example.api.service;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.GetMapping;
@FeignClient(name = "uid-take", fallback = UidTakeFeignServiceFallBack.class)
public interface UidTakeService {
@GetMapping("getUid")
Long getUid();
}
feign 接口调用失败处理类UidTakeFeignServiceFallBack:
package org.example.api.service;
import org.springframework.stereotype.Component;
@Component
public class UidTakeFeignServiceFallBack implements UidTakeService {
@Override
public Long getUid() {
return null;
}
}
3.1 覆盖MyBatis-Plus原有的DefaultIdentifierGenerator 类,并重写nextId 方法:
在java根目录创建package : com.baomidou.mybatisplus.core.incrementer
新建DefaultIdentifierGenerator 类:
package com.baomidou.mybatisplus.core.incrementer;
import com.example.uidconsumer.util.ApplicationContextUtils;
import org.example.api.service.UidTakeService;
import javax.annotation.Resource;
public class DefaultIdentifierGenerator implements IdentifierGenerator {
@Resource
private UidTakeService uidTakeService;
@Override
public Long nextId(Object entity) {
// 如果uidTakeService 获取不到,则从容器中在次获取bean
if (null == uidTakeService ){
uidTakeService =ApplicationContextUtils.getBean(UidTakeService.class);
}
return uidTakeService.getUid();
}
}
效果如下:
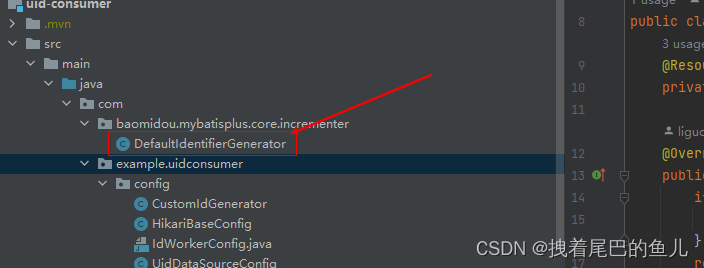
ApplicationContextUtils:
package com.example.uidconsumer.util;
import com.example.uidconsumer.UidConsumerApplication;
public class ApplicationContextUtils {
public static <T> T getBean(String beanName){
return (T) UidConsumerApplication.applicationContext.getBean(beanName);
}
public static <T> T getBean(Class classz){
return (T) UidConsumerApplication.applicationContext.getBean(classz);
}
}
UidConsumerApplication 启动类:
package com.example.uidconsumer;
import org.example.api.constant.BaseConstant;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.openfeign.EnableFeignClients;
import org.springframework.context.ConfigurableApplicationContext;
@SpringBootApplication
@EnableFeignClients(basePackages = BaseConstant.FEIGN_PACKAGE)
public class UidConsumerApplication {
public static ConfigurableApplicationContext applicationContext;
public static void main(String[] args) {
applicationContext = SpringApplication.run(UidConsumerApplication.class, args);
}
}
3.2 在uid-generator 生成id 的服务 增加api 的依赖,并提供 生成uid 的生成:
TakeUidController:
package com.example.uidtake.controller;
import com.example.uidtake.worker.service.IWorkerNodeService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class TakeUidController {
@Autowired
private IWorkerNodeService workerNodeService;
@GetMapping("getUid")
public Long getUid() {
return workerNodeService.genUid();
}
}
4 总结:
- uid-generator 是-MyBatis-Plus默认雪花算法的优化版,它提供了自定义时间戳,以及自定义时间位数,机器位数,序列号位数的方法,可以覆盖掉原有的参数;
- uid-generator 使用RingBuffer数组来盛放生成的id,默认可以一次生成65536个id,在剩余未使用的id 小于65536/2 时,会触发补充id 的方法;
- uid-generator 默认的时间戳是28位,可以支持约 2^28 /3600/24/365 = 8.5 年的使用,如果超过这个时间, 生成id会与8.5年前生成的id 有重合,如果需要支持更长的时间使用,需要通过CachedUidGenerator 类中的setTimeBits 方法来调整时间戳的位数,多增加一位则意味着可以使用 8.5 *2 年;
- uid-generator 可以通过setEpochStr 设置id 生成时间的开始位置,如 设置cachedUidGenerator.setEpochStr(“2023-01-01”);为id 生成起始时间;
- uid-generator 默认的机器位数为22,因为每次启动都会向WORKER_NODE 重新插入一条数据,并使用插入成功的数据id 作为workId,参与id 的生成;默认可以重启 2^22 = 4,194,304 次,如果超过改次数,则生成的workId 又会从1开始;
- uid-generator的序列号默认为13 位,每秒最多可以生成 2^13 = 8,192 个id,如果每秒超过8,192个id,则会阻塞到下一秒,继续id 的生成
- uid-generator 和雪花算法一样都是使用了long 的64位,来生成id,最大可以支持2^64 的id 生成,可以根据自己的业务动态的调整,时间位,机器位,序列号位;
项目git 连接:
https://codeup.aliyun.com/61cd21816112fe9819da8d9c/baidu-uid.git
5 参考:
5.1 百度全局分布式id;
5.2 MyBatis-Plus 自定义ID生成器;