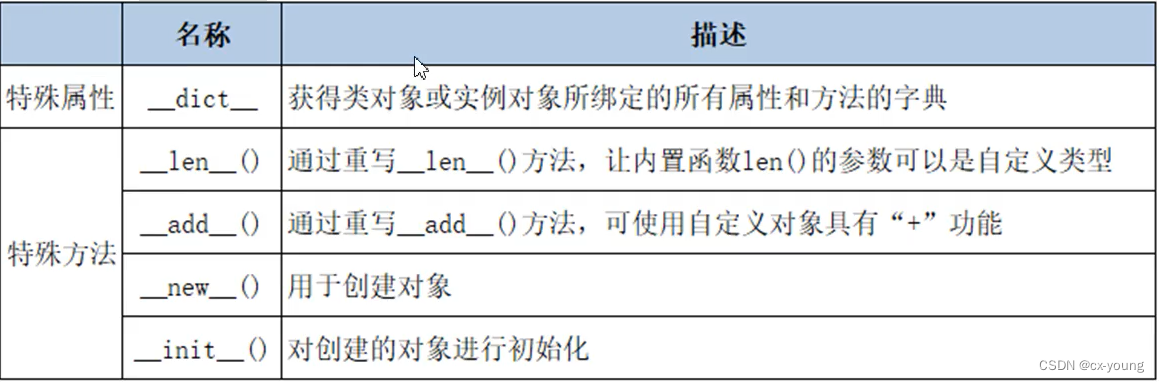
长期以来,研究人员进行自然语言处理研究主要依赖各种机器学习模型,以及手工设计的特征,但这样做带来的隐患是由于语言信息被稀疏表征表示,会出现维度诅咒之类的问题。而随着近年来词嵌入(低维、分布式表征)的普及和成功,和传统机器学习模型(如SVM、Logistic回归)相比,基于神经网络的模型在各种语言相关任务上取得了优异的成果。下面简要介绍几种基于神经网络方法的自然语言处理技术。
1. 神经语言模型(2001年)
语言建模是在给定先前单词的情况下预测文本中的下一个单词的任务。这可能是最简单的语言处理任务,具有具体的实际应用,如智能键盘和电子邮件回复建议(Kannan等人,2016)。语言建模有着悠久的历史,经典的方法是基于n元语法,并使用平滑来处理看不见的n元语法(Kneser and Ney,1995)。
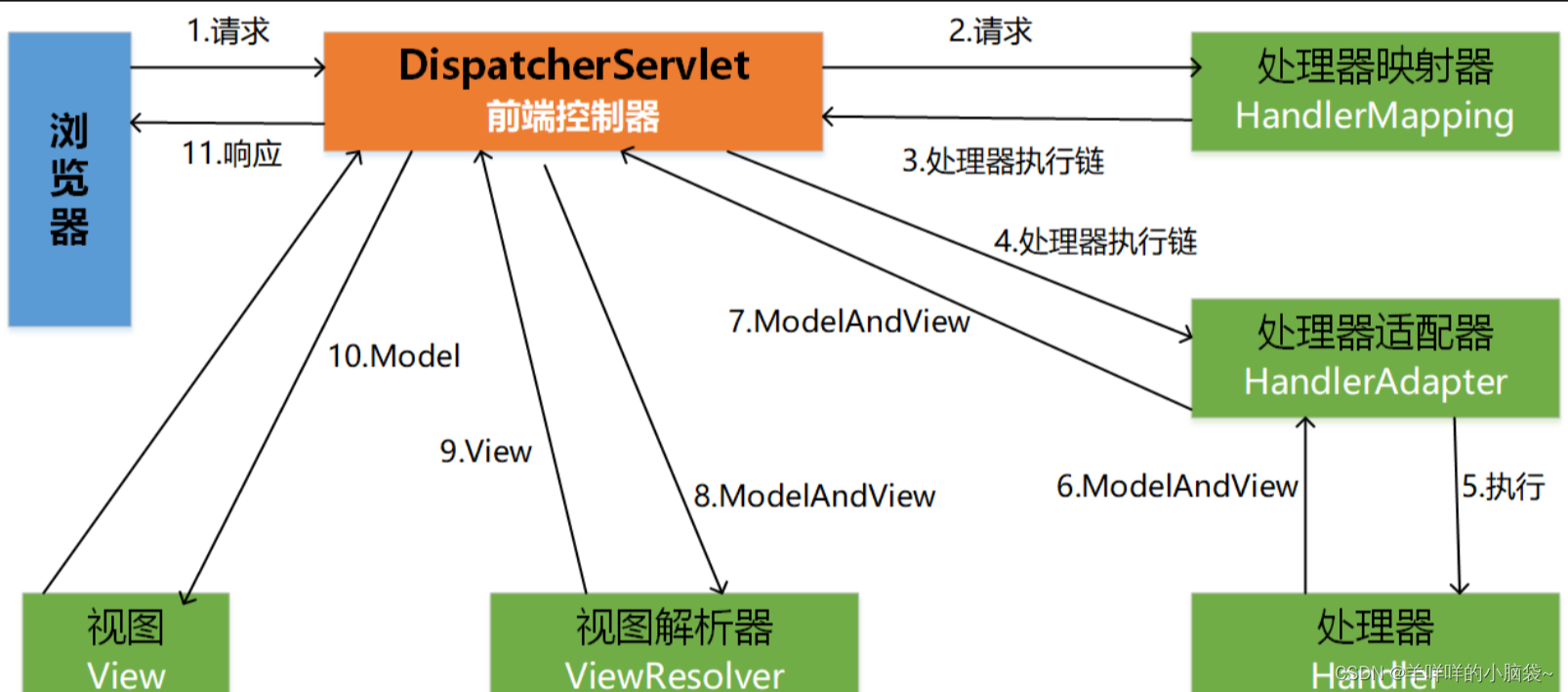
第一个神经语言模型(Neural Language Models)是Bengio等人在2001年提出的前馈神经网络,如图8.1所示。
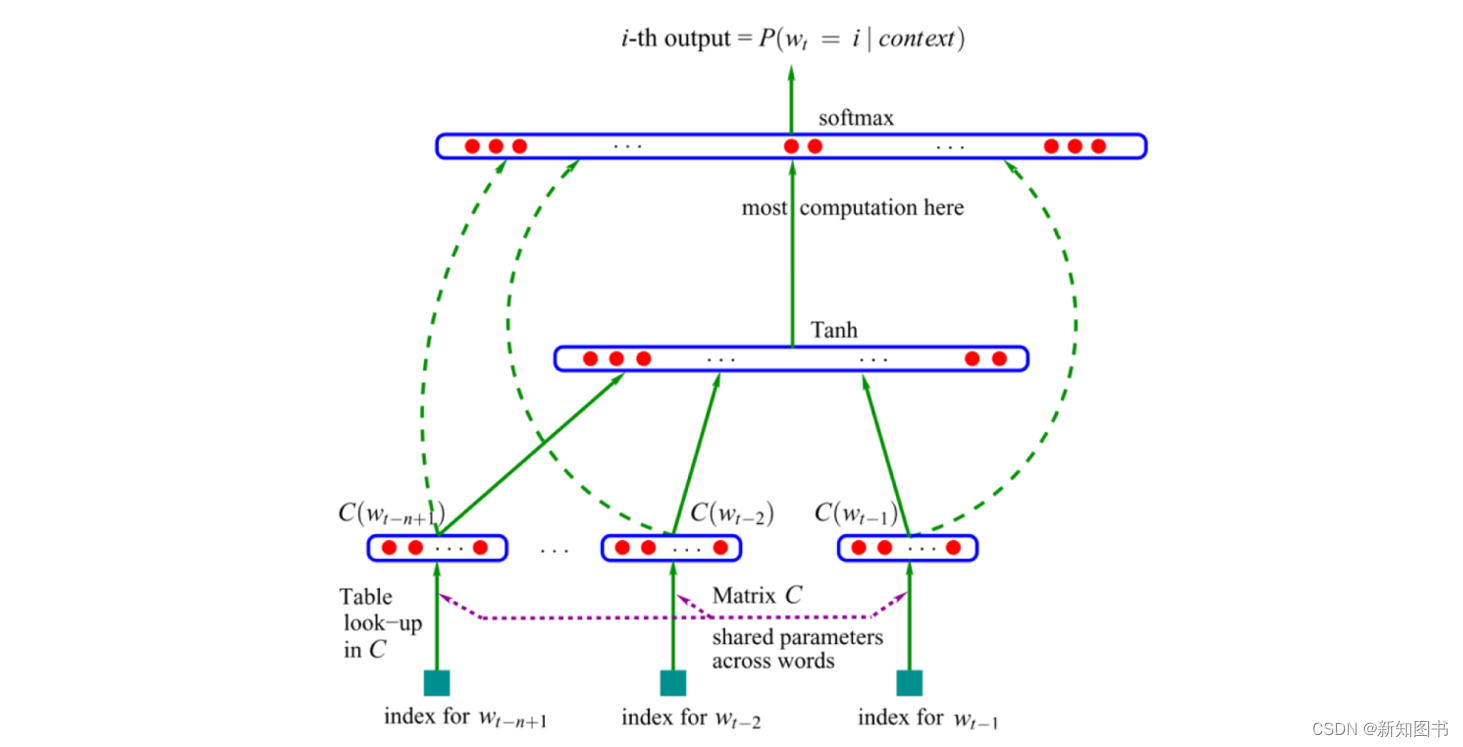
图8.1 前馈神经网络语言模型
该模型用前n个单词的输入向量表示为输入,在表C中进行查找。现在,这样的向量被称为词嵌入。这些词嵌入级联后被输入一个隐藏层中,该隐藏层的输出又被输入Softmax层。
语言建模通常是应用RNN时的第一步,它是无监督学习的一种形式,也称为预测性学习。语言建模最值得注意的方面可能是,尽管它很简单,但它是后续许多技术发展的核心,例如:
- 词嵌入模型:Word2Vec的目标是简化语言建模。
- 序列到序列(Sequence-to-Sequence)模型:这种模型通过一次预测一个单词来生成输出序列。
- 预先训练的语言模型:这些方法使用来自语言模型的表述进行迁移学习。
2. 多任务学习(2008年)
多任务学习(Multi-Task Learning,MTL)是在多个任务上训练的模型之间共享参数的一种通用方法。在神经网络中,通过将不同层的权重捆绑在一起就可以很容易地做到这一点。多任务学习的思想最早是由Rich Caruana于1993年提出的,并被应用于道路跟踪和肺炎预测(Caruana,1998)。直观地说,多任务学习鼓励模型学习对许多任务有用的表示法。这对于学习常规的低级表示、集中模型的注意力或在训练数据数量有限的设置中特别有用。
2008年,Collobert和Weston将多任务学习首次应用于自然语言处理的神经网络,在它们的模型中,查询表(Lookup Tables)在两个接受不同任务训练的模型之间共享,如图8.2所示。
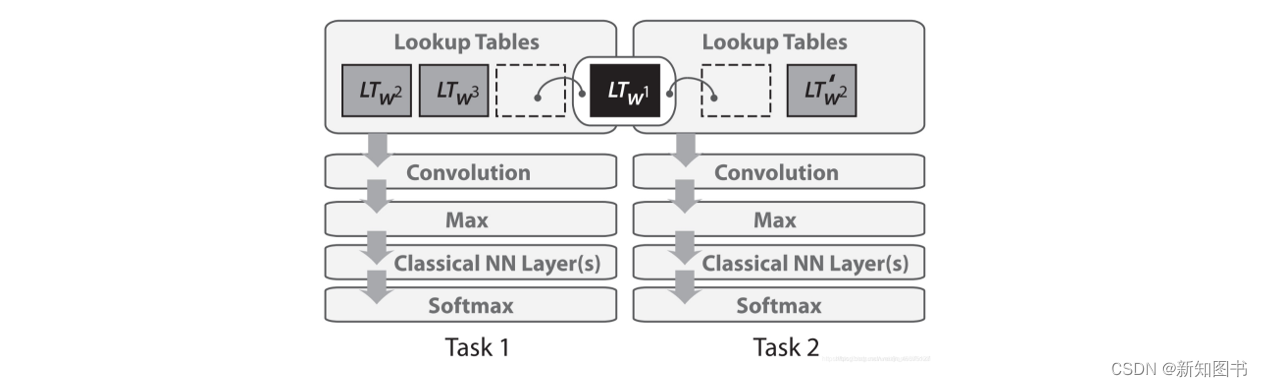
图8.2 查询表的多任务学习
多任务学习现在被广泛用于各种自然语言处理任务,随着越来越多的人在多任务上对模型进行评估,以衡量其泛化能力,多任务学习变得越来越重要,最近提出了多任务学习的专用基准(Wang等人,2018;McCann等人,2018)。
3. 词嵌入(2013年)
文本的稀疏向量表示,即所谓的词袋模型,在自然语言处理领域有着悠久的历史,基于词嵌入的密集向量表示法也早在2001年开始得到使用。
所谓词嵌入,通俗来讲,是指将一个词语(Word)转换为一个向量(Vector)表示,所以词嵌入有时又被叫作Word2Vec。词嵌入是一种基于分布假设(出现在类似语境中具有相似含义的词)的分布向量,它的作用是把一个维数为所有词的数量的高维空间嵌入一个维数低得多的连续向量空间中。通常情况下,词嵌入会在任务上进行预训练,用浅层神经网络基于上下文预测单词。
2013年,米科洛夫(Mikolov)等人提出连续词袋(Continuous Bag Of Words,CBOW)和跳过语法(Skip-Gram)模型,成为词嵌入模型中的两个主要模型,它的主要创新是通过去除隐藏层并接近目标来使这些词嵌入的训练更有效率,便能使大规模的词嵌入训练成为可能。
CBOW模型的目标是基于给定上下文和给定窗口大小预测目标单词(Input Word)的条件概率,即用多个上下文单词来预测一个中心目标单词。而Skip-Gram模型则刚好相反,它的目标是在给定一个中心目标单词的情况下,预测多个上下文,如图8.3所示。
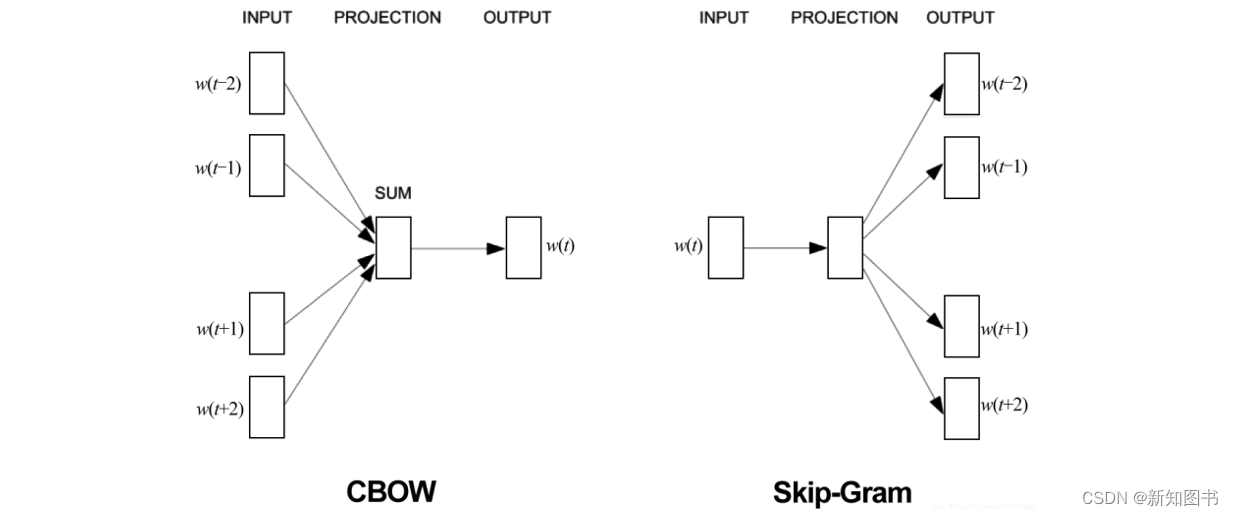
图8.3 词嵌入的两种模型
虽然这些词嵌入模型在概念上与使用前馈神经网络学习的词嵌入在概念上没有区别,但是在一个非常大的语料库上训练之后,它们就能够捕获诸如性别、动词时态和国家-首都关系等单词之间的特定关系,如图8.4所示。
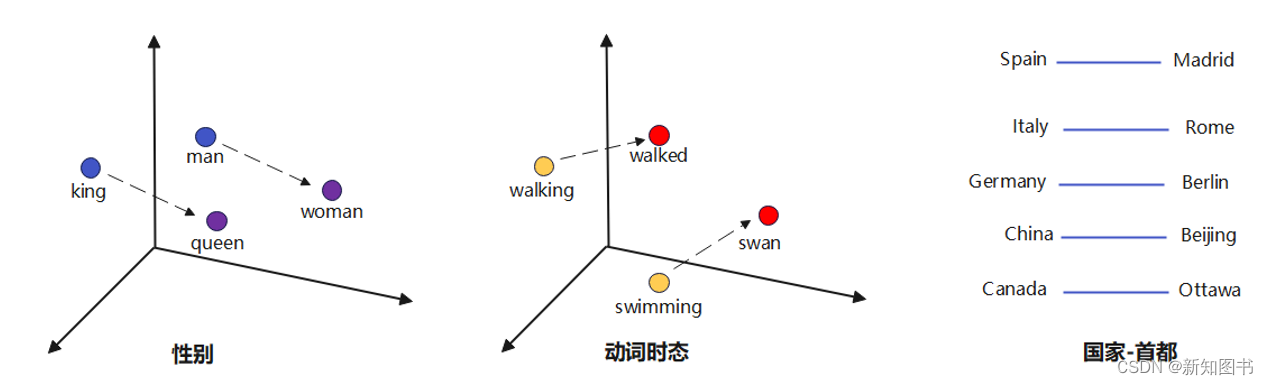
图8.4 词嵌入捕获的关系
尽管Word2Vec捕捉到的关系具有直观且近乎神奇的性质,但后来的研究表明,Word2Vec本身并没有什么特殊之处:词嵌入也可以通过矩阵因式分解来学习(Pennington等人,2014;Levy and Goldberg,2014),经过适当的调整,SVD和LSA等经典矩阵因式分解方法取得了类似的结果(Levy等人,2015)。从那时起,人们在探索词嵌入的不同方面做了大量工作,尽管有了许多发展,Word2Vec仍然是一个流行的选择,并在今天得到了广泛的使用。
4. 自然语言处理NLP的神经网络(2013年)
2013年和2014年是自然语言处理问题开始引入神经网络模型的时期,3种主要类型的神经网络得到了广泛的应用:循环神经网络、卷积神经网络和递归神经网络。
1)循环神经网络
循环神经网络(RNN)是一种专门处理序列信息的神经网络,它循环往复地把前一步的计算结果作为条件,放进当前的输入中,这些序列通常由固定大小的标记向量表示,按顺序逐个输入循环神经元。RNNs是处理自然语言处理中普遍存在的动态输入序列的一个最佳的技术方案,相比CNN,RNN的优势是能把之前处理好的信息并入当前计算,这使它适合在任意长度的序列中对上下文依赖性进行建模。
简单的RNN容易出现梯度消失和梯度爆炸现象,这意味着难以学习和难以调整较早层中的参数,存在长期依赖问题。为了解决这个问题,研究人员陆续提出了LSTM、ResNets、门控循环单元(Gated Recurrent Unit,GRU)、独立RNN(Independent RNN)等多种变体。在应用方面,简单循环网络(Simple Recurrent Network,SRN)从诞生之初就被应用于语音识别任务,但表现并不理想,因此在20世纪90年代早期有研究尝试将SRN与其他概率模型相结合以提升其可用性,随后双向RNN(Bidirectional RNN,Bi-RNN)和双向LSTM的出现提升了RNN对自然语言处理的能力,2010年以后,随着深度学习方法的成熟、数值计算能力的提升以及各类特征学习技术的应用,拥有复杂构筑的深度循环神经网络(Deep RNN,DRNN)开始在自然语言处理中展现出优势,成为语音识别、语言建模等应用的重要算法。目前,RNN一直是各类自然语言处理研究的常规选择,比如机器翻译、图像字幕和语言建模等。
2)卷积神经网络
随着卷积神经网络(CNN)在计算机视觉中的广泛应用,它们也开始应用于自然语言处理。2014年,Yoon Kim针对CNN的输入层做了一些变形,提出了文本分类模型textCNN。与传统图像的CNN网络相比,textCNN在网络结构上没有任何变化,甚至更加简单。自然语言是一维数据,用于文本的卷积神经网络其实只有一层卷积,过滤器(卷积核)只需要沿时间维度移动,并进行一维池化,最后将输出外接Softmax函数来分类。
CNN的优点在于它比RNN更加可并行化,因为每个时间步的状态仅依赖于局部上下文(通过卷积运算),而不是RNN中的所有过去状态。CNN可以用更广泛的接受域扩展,使用扩张的卷积来捕捉更广泛的上下文(Kalchbrenner等人,2016)。
CNN基本上就是一种基于神经的方法,它可以被看作是基于单词或N-Gram提取更高级别特征的特征函数。如今,CNN提取的抽象特征已经被有效应用于情感分析、机器翻译和问答系统等更多的文本处理任务中。
但CNN的一个缺点是无法建模长距离依赖关系,而这些依赖关系对所有NLP任务都是很重要的。为了解决这个问题,现在研究人员已经把CNN和时延神经网络(TDNN)结合在一起,由后者在训练期间实现更大的上下文范围。另外,动态卷积神经网络(DCNN)也已经在不同任务上取得了成功,比如情绪预测和问题分类,它的特殊之处在于池化层,它用了一种动态K-Max池化,能让卷积核在句子建模过程中动态地跨越可变范围,使句子中相隔甚远的两个词之间都能产生语义联系。
总体而言,CNN对于自然语言处理也是有用的,因为它可以在上下文窗口中挖掘语义线索,但它在处理连贯性和长距离语义关系时,还有一定欠缺。相较之下,RNN是一个更好的选择。
3)递归神经网络
广泛地讲,递归神经网络(Recursive Neural Network)是两类人工神经网络的总称,分别是时间递归神经网络(Recurrent Neural Network,RNN)和结构递归神经网络(Recursive Neural Network),前者即循环神经网络。接下来所讲的递归神经网络专指后者。
与循环神经网络类似,递归神经网络也是对连续数据建模的一种机制。自然语言本质上是层次化的,恰好可以被看成是递归结构:单词被组合成高阶短语和从句,这些短语和从句本身可以根据一组生产规则递归地组合。受将句子视为树而不是序列的语言学思想启发,研究者们提出了递归神经网络。在这种结构中,通过自下而上地构建序列的表示形式,非终端节点由其所有子节点的表征来表示,如图8.5所示。
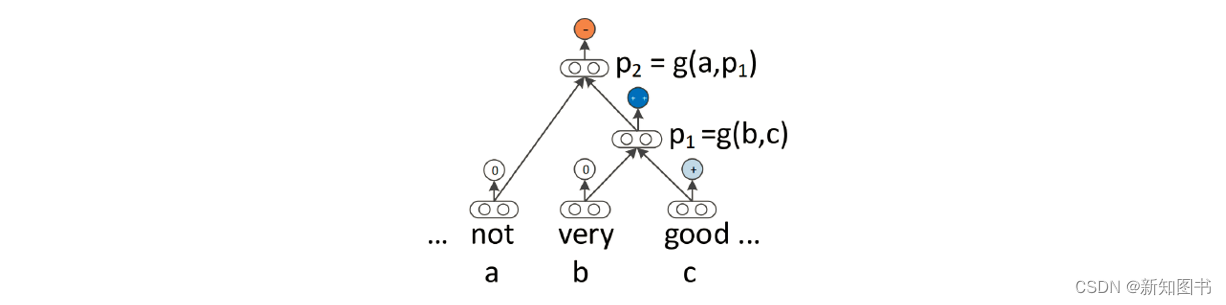
图8.5 递归神经网络的表示形式
5. 序列到序列模型(2014年)
2014年,Sutskever等人提出了序列到序列(Sequence-to-Sequence,Seq2Seq)学习模型,这是使用神经网络将一个序列映射到另一个序列的通用框架。在该框架中,编码器神经网络逐个符号地处理句子符号,并将其压缩成矢量表示;然后解码器神经网络基于编码器状态逐个符号地预测输出符号,在每个步骤将先前预测的符号作为输入,如图8.6所示。
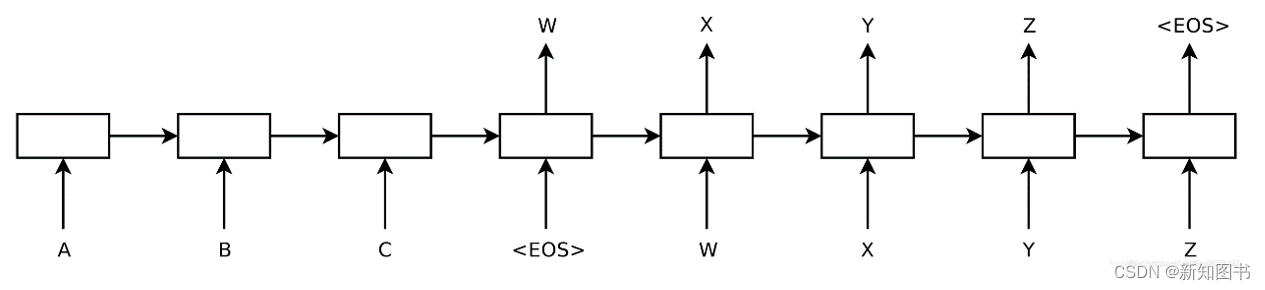
图8.6 序列到序列模型框架
从广义上讲,序列到序列模型的目的是将输入序列(源序列)转换为新的输出序列(目标序列),这种方式不会受限于两个序列的长度,换句话说,两个序列的长度可以任意。
Seq2Seq模型的思想最早由Bengio等人在论文Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation中初次提出,随后Sutskever等人在文章Sequence to Sequence Learning with Neural Networks中提出改进模型,即为目前常说的Seq2Seq模型。
由于其灵活性,这个框架现在是自然语言生成任务的首选框架,机器翻译被证明是这个框架的杀手级应用。2016年,谷歌宣布开始用神经机器翻译模型取代其基于短语的整体式机器翻译模型(Wu等人,2016)。
6. 注意力机制(2015年)
Seq2Seq模型的主要瓶颈是需要将源序列的全部内容压缩为一个固定大小的向量,当输入序列的长度过大时,需要足够大的RNN和足够长的训练时间才能很好地实现,因此需要寻找一种更高效的实现方法,注意力机制的应用因此而生。
注意力机制的思想认为输出的目标序列的某个部分往往只与输入序列的部分特点相关,因此可以把注意力(Attention)集中到与当前输出相关的输入上。
注意力机制最早是在视觉图像领域提出来的,这方面的研究工作很多,研究历史也比较悠久。2015年,Bahdanau等人第一次提出将注意力机制应用到NLP领域中。
从本质上说,注意力机制的作用对象是基于编码器-解码器框架的RNN,它能让解码器利用最后的隐藏状态,以及基于输入隐藏状态序列计算的信息(如上下文向量),这对于需要上下文对齐的任务特别有效。
当前注意力机制已经被成功应用于机器翻译、文本摘要、阅读理解、图像字幕、对话生成、情感分析、语篇分析等许多NLP领域。虽然已经有研究人员提出了各种不同形式和类型的注意力机制,但未来它仍然是NLP领域的重点研究方向之一。
7. 基于记忆的增强神经网络(2015年)
注意力可以看作是模糊记忆的一种形式,记忆由模型过去的隐藏状态组成,模型选择从记忆中检索需要的内容。研究者们又进一步提出了许多具有更明确记忆的模型,引入结构化的记忆模块,将和任务相关的短期记忆保存在记忆中,需要时再进行读取,这种装备外部记忆的神经网络也称为记忆网络(MN)或记忆增强神经网络(MANN)。这些网络模型有不同的变体,如神经图灵机、记忆网络和端到端记忆网络、动态记忆网络、神经微分计算机和循环实体网络。在这些模型中,记忆的概念是非常通用的:知识库或表都可以充当记忆,而记忆也可以根据整个输入或它的特定部分去填充。
基于记忆的模型通常应用于一些特定任务中,它们在问答系统、语言建模、POS标记和情感分析等任务上都有不错的表现。
8. 预训练模型(2018年)
预训练模型最早于2015年被提出,直到2018年,它们才被证明在一系列不同的NLP任务中都是有益的。2018年6月,OpenAI上发表的Improving Language Understanding by Generative Pre-Training论文把预训练模型推向了一个新的高潮。2018年10月,Google AI在Arxiv上发表了BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding论文,BERT的全称是Bidirectional Encoder Representation from Transformers,它是第一个用于预训练NLP模型的无监督方法、深度双向系统,可以支持用户在短短几个小时内(在单个GPU上)使用BERT训练出自己的NLP模型。BERT是一个非常有用的框架,可以很好地在各种NLP任务中使用。随后,更多的BERT变种和预训练模型纷纷发布,如Google的 Transformer-XL、OpenAI的GPT、语言模型嵌入(Embeddings from Language Models,ELMO)、Stanford NLP等。
预训练模型可以用较少的数据进行学习,在使用预训练模型时只需要使用未标记的数据,因此对于标记数据比较困难的低资源语言来说,预训练模型特别有用。这一突破使得每个人都能轻松地开启NLP任务,尤其是那些没有时间和资源从头开始构建NLP模型的人,所以使用预训练模型处理NLP任务是目前非常热门的研究方向。
9. 其他技术
1)变分自动编码器
现今,NLP领域最流行的深度生成模型有变分自动编码器(Variational Auto-Encoder,VAE)和生成对抗神经网络(GAN),它们能在潜在空间生成逼真的句子,并从中发现丰富的自然语言结构。
VAE作为一个生成模型,通过在隐藏的潜在空间上施加先验分布,能使生成的句子更接近人类自然语言表述。
2)对抗学习
对抗学习方法已经在机器学习领域掀起了风暴,在NLP中也有不同形式的应用。
对抗学习(Generative Adversarial Network,GAN)本身十分灵活,所以它在很多NLP任务上都有用武之地。比如,和标准自编码器相比,一个基于RNN的VAE生成模型可以产生形式更多样化、表述更规整的句子;而基于GAN的模型能把结构化变量(如时态、情绪)结合进来,生成更符合语境的句子。
3)强化学习
强化学习(Reinforcement Learning,RL)已被证明对具有时间依赖性的任务有效,近年来它在自然语言生成任务中崭露头角,在文本生成、图像字幕和机器翻译中表现出色。
以上我们简单介绍了基于神经网络的NLP应用模型,介绍了深度学习、强化学习在NLP任务上的可能性,也知道了注意力机制和记忆增强网络在提高NLP神经网络模型性能上的能力,通过结合这些技术,已经能够让计算机处理复杂的自然语言任务了。下面我们将结合文本序列处理中常见的机器翻译任务,介绍深度学习算法在文本序列处理中的具体应用。
本文节选自《Python深度学习原理、算法与案例》,内容发布获得作者和出版社授权。