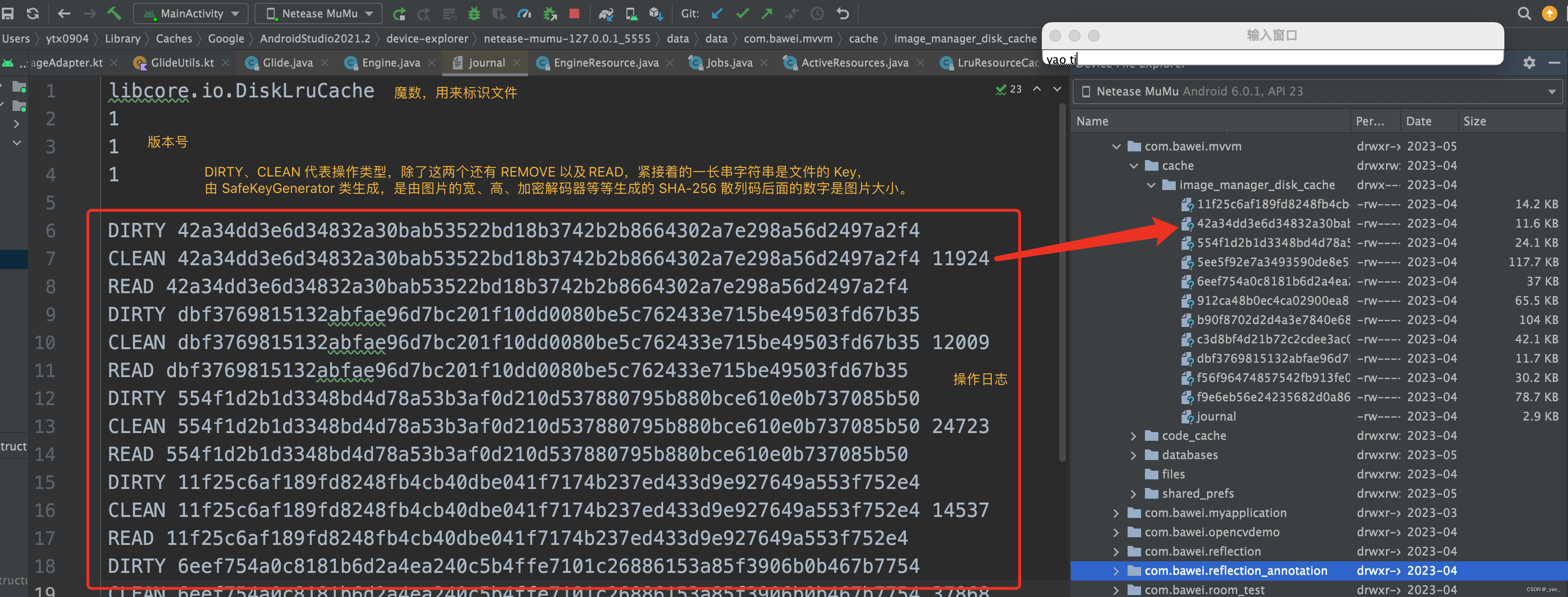
待coding:
moco
pcl
文章目录
- Semantic Representation for Dialogue Modeling
- PCL: Peer-Contrastive Learning with Diverse Augmentations for Unsupervised Sentence Embeddings
- 深度网络的公理归因 Axiomatic Attribution for Deep Networks
- NLU模型的捷径学习行为
- MoCo: Momentum Contrast 无监督学习
- 深度互学习-Deep Mutual Learning:三人行必有我师
- TRANS-ENCODER 自监督的Sentence Bi & Cross Encoder
- Mirror-Bert
- 相关背景
- 方法介绍
- Self-guided contrastive learning for BERT sentence representations
- Label Denoise论文总结——Co-training系列
- CLEAR: Contrastive Learning for Sentence Representation
- ESimCSE
- RankCSE
- 数据增强
- Conditional BERT Contextual Augmentation
- Augmented SBERT
- ViLBERT
- faster r-cnn
- 多模态特征融合
- 双线性特征融合
- 对比学习
- 语义计算
Semantic Representation for Dialogue Modeling
抽象意义表征(Abstract Meaning Representation)(AMR)来帮助对话建模
Dialogue-based sentence representation
https://zhuanlan.zhihu.com/p/437790124
节点到词的关系映射:An AMR Aligner Tuned by Transition-based Parser
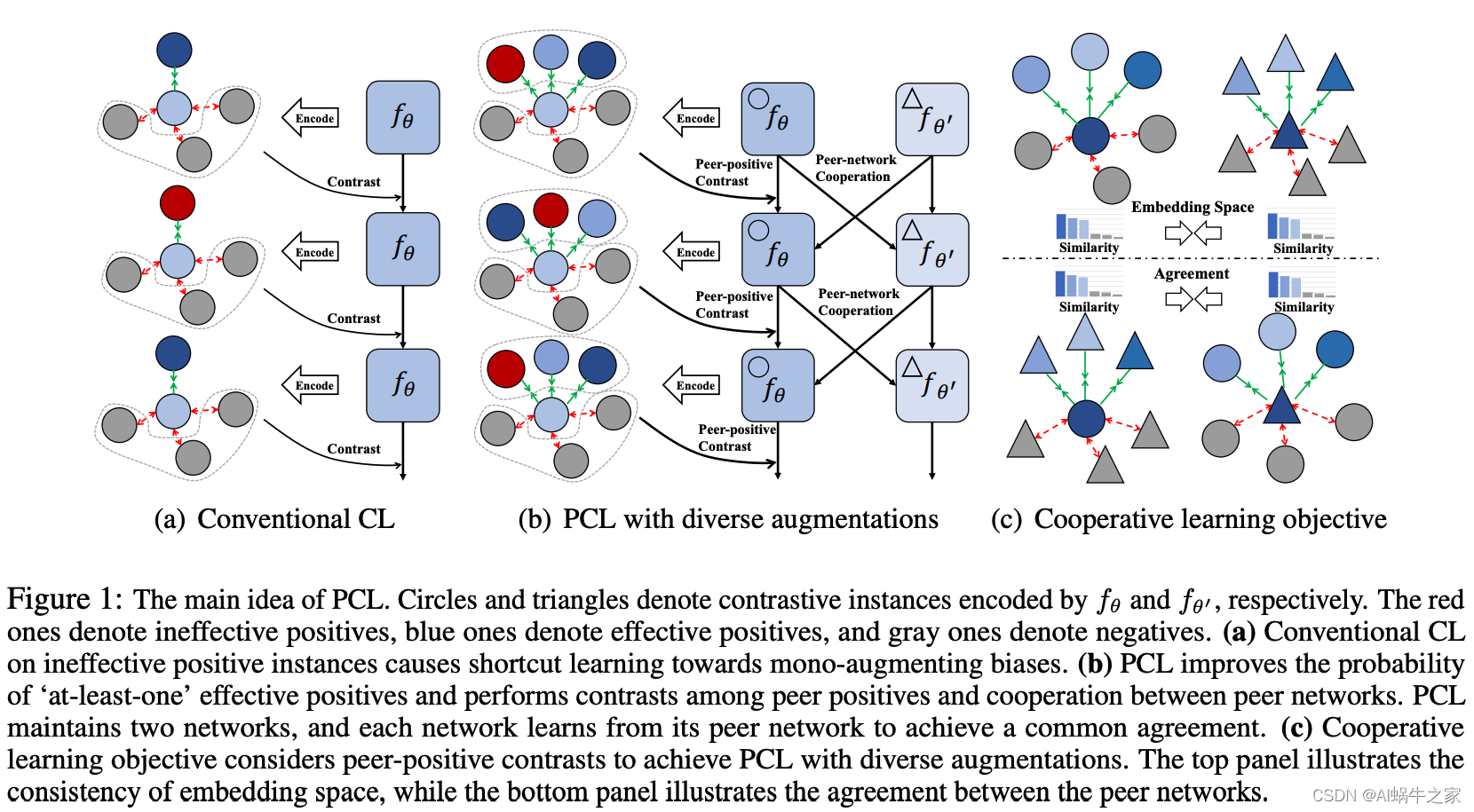
PCL: Peer-Contrastive Learning with Diverse Augmentations for Unsupervised Sentence Embeddings
两种对比学习找正样本的方法——离散(Discrete augmentation format)和连续(Continuous augmentation format):
- Discrete augmentation format:直接通过字符或者n-gram的方式修改正样本,比如同义词替换、字词shuffing、字词删减、回译;
- Continuous augmentation format:通过隐变量的方式,比如SimCSE中两次dropout
motivation:
目前模型要么采用离散的方式,要么采用连续方式,但是都用的是单一的增强方式(mono-augmenting format)并且增强策略有限,这导致上述方法都存在“学习捷径”。例如依赖两次dropout的正样本训练出来的模型倾向于通过句子长度判断。
知识点小百科:
- Shortcut Learning:
预训练语言模型如BERT在许多NLU任务上展现出了出色的性能,但最近的研究表明,这类模型倾向于利用数据集的bias,尝试利用“捷径(shortcuts)”去获得较高的评测性能,而不是真正地理解语言。这往往会导致模型在OOD样本上较差的泛化性能,以及面对对抗攻击时较差的鲁棒性。
具体的考虑分类任务:给定样本 x x x,模型需要学习一个映射 f ( x ) f(x) f(x) 去预测标签 y y y。在训练过程中,如果一些词或短语与某个标签 y y y 共现的次数高于其他词,模型就会捕获这类特征用于预测。根据独立同分布的假设,训练、验证和测试集均采样自同一个数据分布,因此即使模型捕获了这类捷径特征用于预测,在测试集中指标也不会很差。然而,当暴露于分布外数据(OOD samples)和对抗样本(adversarial samples)的时候,模型就会表现出较差的泛化性和鲁棒性,因为他们不一定和训练集的数据具有相同的shortcuts。
method
同时采用多种增强正样例的方法(离散+连续),但是采用多种增强方式也有双刃剑(double-edged sword)——多种增强方式可能导致无法保证样本质量。我们提出了一个brand-new peer-contrastive learning framework,它不仅可以执行普通的正反对比,还可以执行正反对比。
we propose a brand-new peer-contrastive learning framework that not only performs the vanilla positive-negative contrast but a positive-positive contrast.
深度网络的公理归因 Axiomatic Attribution for Deep Networks
-
人类怎么做归因
人类做归因通常是依赖于反事实直觉。当人类将某些责任归因到一个原因上,隐含地会将缺失该原因的情况作为比较的基线(baseline)。例如,想睡觉的原因是困了,那么不困的时候就不想睡觉。 -
深度网络的归因
基于人类归因的原理,深度网络归因也需要一个基线(baseline)输入来模拟原因缺失的情况。在许多深度网络中,输入空间天然存在着一个baseline。例如,在目标识别网络中,纯黑图像就是一个基线。下面给出深度网络归因的正式定义:
假设存在一个函数 F F F: R n → [ 0 , 1 ] R^n \to [0,1] Rn→[0,1],其表示一个神经网络。该网络的输入是 x = ( x 1 , . . . , x n ) ∈ R n x=(x_1,...,x_n) \in R^n x=(x1,...,xn)∈Rn,那么 x x x相较于基线输入 x ′ ∈ R n x'\in R^n x′∈Rn的归因是一个向量 A F ( x , x ′ ) = ( a 1 , . . . , a n ) ∈ R n A_F(x,x')=(a_1,...,a_n) \in R^n AF(x,x′)=(a1,...,an)∈Rn,其中 a i a_i ai是输入 x i x_i xi对预测结果F(x)的贡献。 -
归因的意义
首先,在使用图像神经网络预测病情的场景中,归因能够帮助医生了解是哪部分导致模型认为该患者生病了;其次,可以利用深度网络归因来为基于规则的系统提供洞见;最后,还可以利用归因来为推荐结构提供依据。 -
应用积分梯度法
1.选择基线
1.1 应用积分梯度法的关键步骤是选择一个好的基线,基线在模型中的得分最好接近0,这样有助于对归因结果的解释。
1.2 基线必须代表一个完全没有信息的样本,这样才能区别出原因是来自输入还是基线。
1.3 在图像任务中可以选择全黑图像,或者由噪音组成的图像。在文本任务中,使用全0的embedding是一个较好的选择。
1.4 图像中的全黑图像也代表着一种有意义的输入,但是文本中的全0向量完全没有任何有效的意义。
2.计算积分梯度
积分梯度可以通过求和来高效地做近似计算,只需要将基线 x ′ x' x′至 x x x直线上足够间隔点的梯度相近即可。
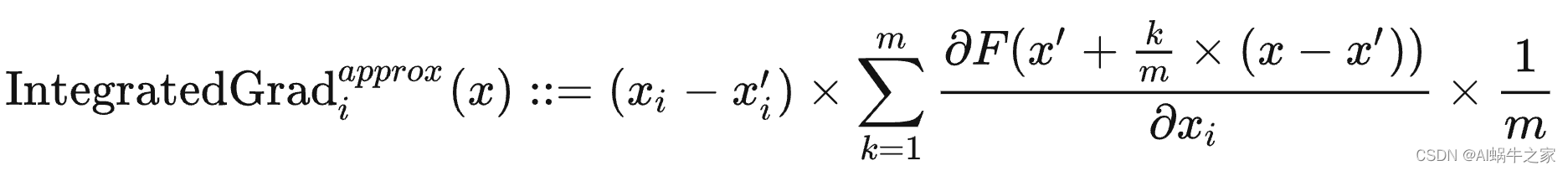
其中, m m m是近似的阶数(泰勒展开的阶数), m m m越大则越近似,但计算量也越大。
在实践中, m m m为20到300之间即可。
NLU模型的捷径学习行为
Towards Interpreting and Mitigating Shortcut Learning Behavior of NLU Models
https://zhuanlan.zhihu.com/p/363904438
MoCo: Momentum Contrast 无监督学习
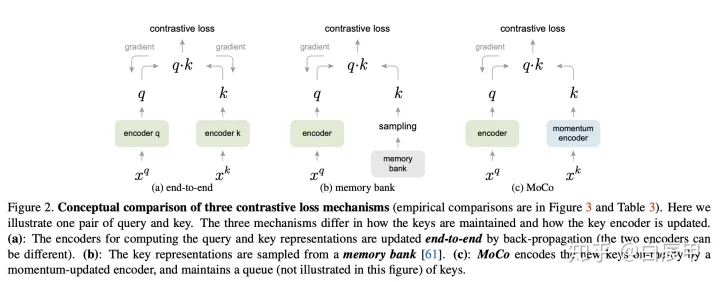
https://zhuanlan.zhihu.com/p/158023072
深度互学习-Deep Mutual Learning:三人行必有我师
https://zhuanlan.zhihu.com/p/71192348
模型蒸馏算法由Hinton等人在2015年提出,利用一个预训练好的大网络当作教师来提供小网络额外的知识即平滑后的概率估计,实验表明小网络通过模仿大网络估计的类别概率,优化过程变得更容易,且表现出与大网络相近甚至更好的性能。然而模型蒸馏算法需要有提前预训练好的大网络,且大网络在学习过程中保持固定,仅对小网络进行单向的知识传递,难以从小网络的学习状态中得到反馈信息来对训练过程进行优化调整。
我们尝试探索一种能够学习到更强大小网络的训练机制—深度互学习,即采用多个网络同时进行训练,每个网络在训练过程中不仅接受来自真值标记的监督,还参考同伴网络的学习经验来进一步提升泛化能力。在整个过程中,两个网络之间不断分享学习经验,实现互相学习共同进步。
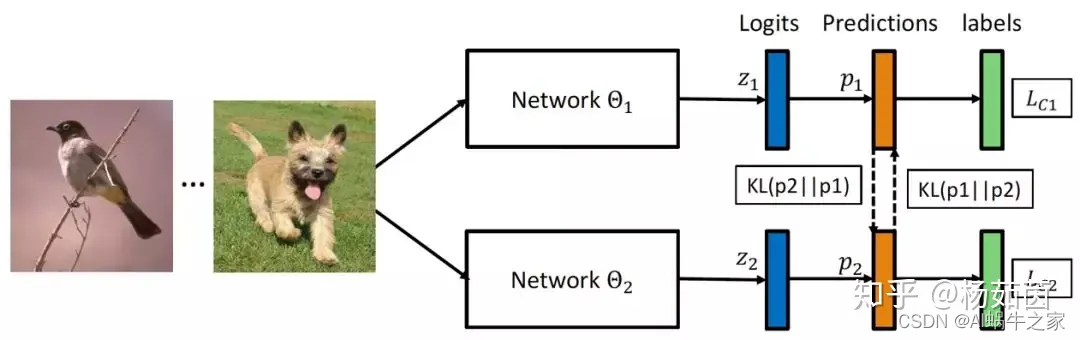

我们提出的互学习算法也很容易扩展到多网络学习和半监督学习场景中。当有K个网络时,深度互学习学习每个网络时将其余K-1个网络分别作为教师来提供学习经验。另外一种策略是将其余K-1个网络融合后得到一个教师来提供学习经验 。在半监督互学习场景中,我们对有标签的数据计算监督损失和交互损失,而针对无标签数据我们仅计算交互损失来帮助网络从训练数据中挖掘更多有用信息。
一般来说小网络从互学习训练中获益更多,比如Resnet-32和MobileNet。尽管WRN-28-10网络参数量很大,与其它网络进行互学习训练依然可以获得性能提升。因此,不同于模型蒸馏算法需要预训练大网络来帮助小网络提升性能,我们提出的深度互学习算法也可以帮助参与训练的大网络来提升其性能。
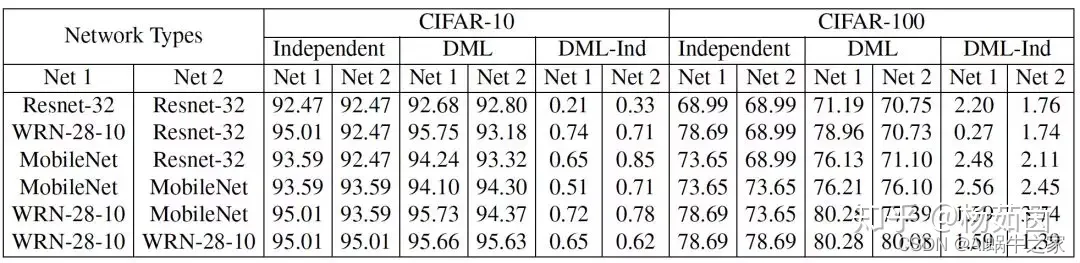
们从图3看出增加网络数量可以提升互学习策略下的单个网络性能,这说明更多教师网络提供了更多学习经验,帮助网络学习到更好的特征。另一方面,多网络互学习中多个独立教师(DML)的性能会优于融合教师(DML_e),这说明多个不同教师网络可以提供更多样化的学习经验,更有益于每个网络的学习。
异构网络效果会怎么样呢?
TRANS-ENCODER 自监督的Sentence Bi & Cross Encoder
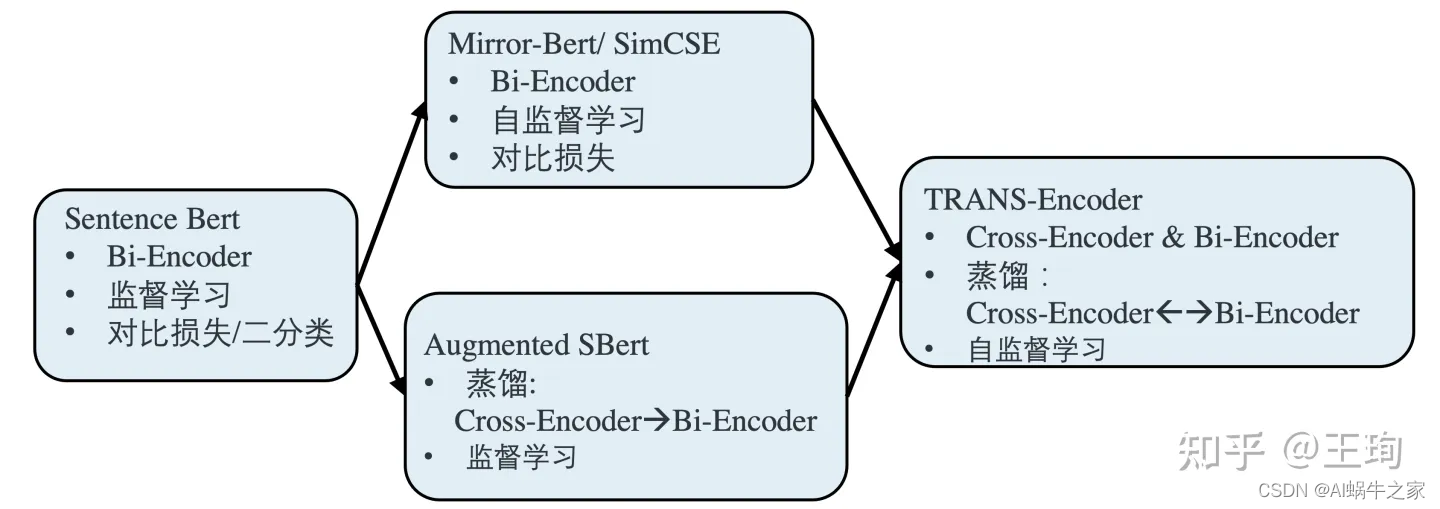
动机:
既然自监督效果卓越,已经在Bi-Encoder上打平甚至超越了监督学习了,而Cross-Encoder一般来说,其效果又是强于Bi-Encoder,那么不禁想,为什么不强强联合,自监督学习一个Cross-Encoder出来呢。
问题:
那么难点来了,自监督的学习一个Cross-Encoder是没有现成的自监督框架的,如果我们硬是要照搬SimCSE/Mirror-Bert, 将一个句子,和其augmentaion拼接起来输入Cross-Encoder,让模型判断是否相似,这个正例对于模型有点过于简单了,负例也是同理。模型很难在这样的自监督任务设计上学到有效信息;Bi-encoder之所以可以是因为两个句子是分别过模型的,在最后的输出才计算相似度,这个任务对Bi-encoder是有一定的难度的。
方案:
解决问题的办法,在于结合知识蒸馏和自监督学习,按照上图,我们首先按照自监督学习训练一个强力的Bi-Encoder 模型,然后,以该Bi-Encoder模型为师,知识蒸馏去训练一个Cross-Encoder,值得注意的是,虽然Cross-Encoder是学生,但是其本身模型架构的能力上限是强于其老师Bi-Encoder,因此可以做到青出于蓝而胜于蓝,在知识蒸馏之后,其模型效果优于Bi-Encoder。这个就是模型的第一步:Bi-Encoder —> Cross-Encoder。
那么,接下来第二步就简单了,我们有了一个强于Bi-Encoder的Cross-Encoder 语义相似性模型,那么和Augmented SBert类似,可以以Cross-Encoder为师,知识蒸馏增强Bi-Encoder 。至此康庄大道已在眼前,以上两个步骤,可以循环往复,迭代进行;两个模型,互为老师,教学相长,一起变强。
若干小细节:
该文章构思巧妙而又简单: 在损失函数上,Bi-Encoder -> Cross-Encoder的损失函数为二元交叉熵损失BCE;Cross-Encoder -> Bi-Encoder的损失函数为均方误差损失MSE。同时,在网络设计上,也很优雅,其中Bi-Encoder和Cross-Encoder共享网络结构,其区别仅仅在于Bi-Encoder输入为单个句子, 而Cross-Encoder的输入为[CLS] sent1 [SEP] sent2 [SEP]。文章的方法在各个benchmark上取得了很大的效果提升。
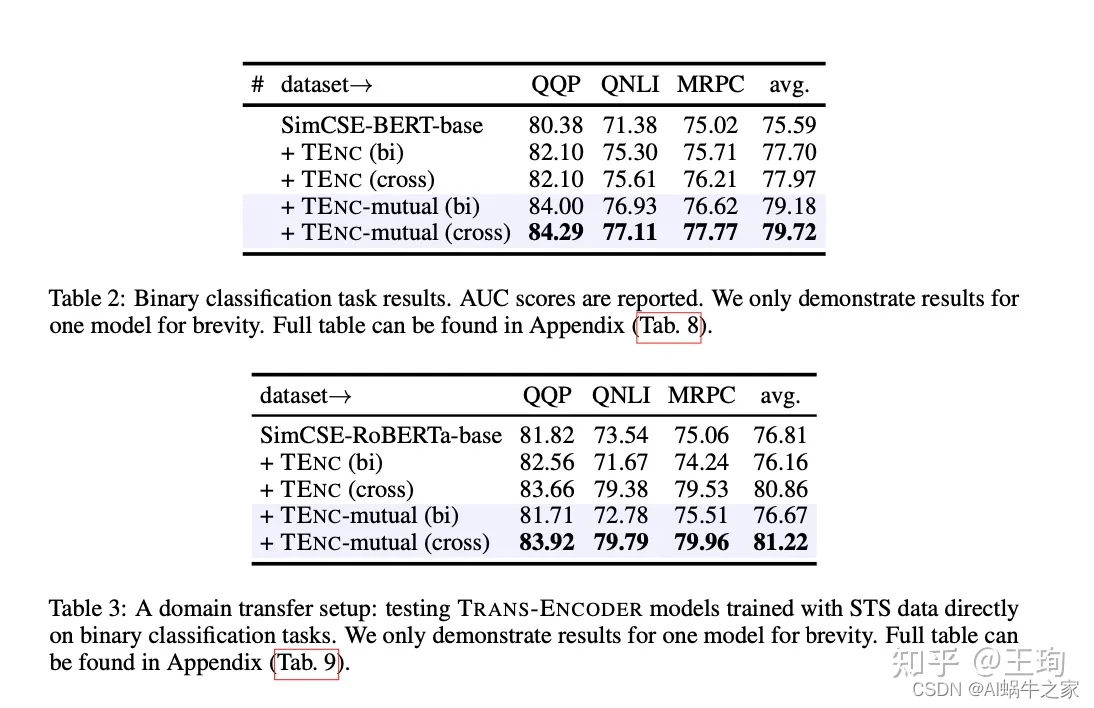
参考:
TRANS-ENCODER:自蒸馏和互蒸馏的无监督句对模型
论文分享-自监督的Sentence Bi & Cross Encoder
Mirror-Bert
相关背景
对比学习训练,使用InfoNCE[1]损失函数作为训练目标,旨在一个batch内拉近和当前句子相似句子的表示,推开不相似句子的表示,由余弦相似度来度量句子表示之间的距离。在对比学习中,构造出多样且高质量的正例对是关键,这里列出了图一中近期各对比学习方法使用的正例构造方法,主要分为2个层面:
- 文本输入层面的修改
随机删除词(ConSERT[2],CLEAR[3])
随机删除连续词(ConSERT,CLEAR,Mirror-BERT)
打乱输入顺序(ConSERT,CLEAR)
同义词替换(CLEAR) - 特征层面构造不同视角
随机掩盖某一维特征(ConSERT)
两次不同的Dropout结果(ConSERT,SimCSE,Mirror-BERT)
增加噪声扰动(ConSERT)
由2个不同模型提供不同视角的特征(Self-Guide Contrastive Learning[4],CT[5])
方法介绍
本文Mirror-BERT主要使用了随机删除连续词和dropout策略来构造正例,dropout也被其他工作证明为简单有效的对比学习正例构造方式。从近期对比学习的相关工作来看,不对原句做过多的破坏能保证构造正例的质量,在不考虑训练效率的情况下,额外训练一个模型提供另一视角下的句子表示也被证明有效。

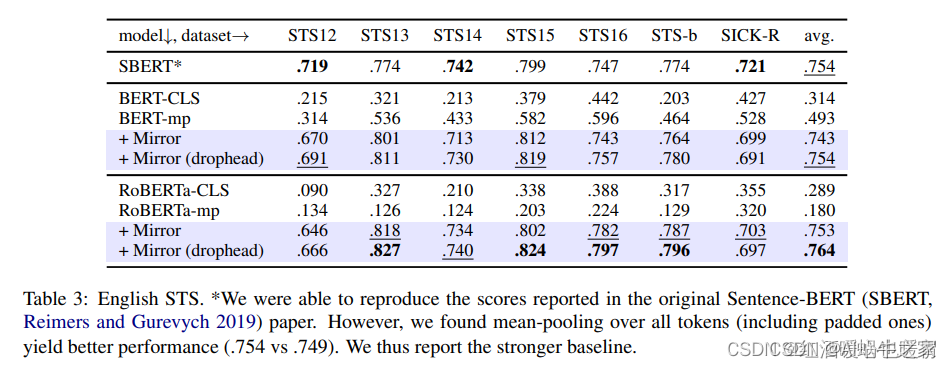
比较关注STS的结果,与SimCSE相比,平均结果没有SimCSE好,部分任务略优。
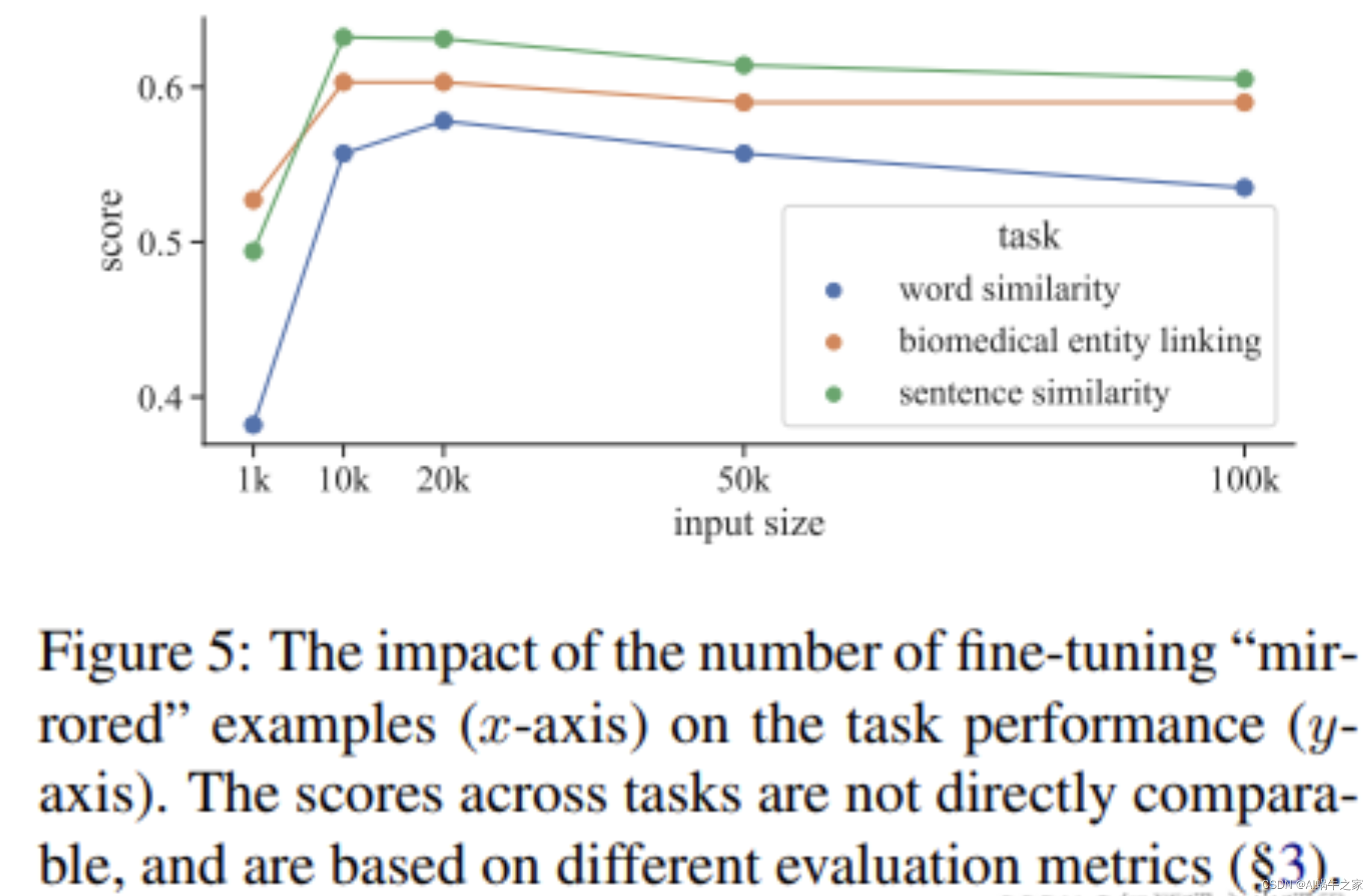
Mirror各个不同的任务中都用了10k的数据,我印象中SimCSE用的数据较多,经过查验:We randomly sample 1 0 6 10^610
6
sentences from English Wikipedia and fine-tune BERT base with learning rate = 3e-5, N = 64. In all our experiments, no STS training sets are used。但是看下图,Mirror-Bert 在10k-20k的时候大部分任务都能取到最好的结果
在STS任务上做的消融试验,span mask起的作用更大一些,但是两者一起用的时候效果最好。其中drophead method: it randomly prunes attention heads at MLM training as a regularisation step
Mirror-BERT Improves Isotropy?看样子是的

从数据增强的角度看,SimCSE的确是它的一个特例,但是SimCSE将对比方法延伸到有监督和无监督两种,且效果的确比Mirror-Bert好,还是danqi女神的作品,如果只想读一篇,我更推荐看SimCSE。
参考链接:
Fast, Effective, and Self-Supervised:Mirror-BERT
Self-guided contrastive learning for BERT sentence representations
来自首尔大学,讨论的问题是如何在不引入外部资源或者显示的数据增强的情况下,利用BERT自身的信息去进行对比,从而获得更高质量的句子表示?
文中对比的是:BERT的中间层表示和最后的CLS的表示。模型包含两个BERT,一个BERT的参数是固定的,用于计算中间层的表示,其计算分两步:(1) 使用MAX-pooling获取每一层的句子向量表示 (2)使用均匀采样的方式从N层中采样一个表示;另一个BERT是要fine-tune的,用于计算句子CLS的表示。同一个句子的通过两个BERT获得两个表示,从而形成正例,负例则是另一个句子的中间层的表示或者最后的CLS的表示。

Label Denoise论文总结——Co-training系列
在标签去噪的研究中,有一类希望通过选择clean instances/clean sets去更新网络参数的方法。一般认为loss比较小的数据比较可靠,可以认为是clean sets。
参考链接:
Label Denoise论文总结——Co-training系列
CLEAR: Contrastive Learning for Sentence Representation
CLEAR设计了mask language modal去表征词级别的特征,用对比学习表征句子级别的特征。对比学习将相同句子数据增强以后的结果拉近(作为正例),将不同句子以及不同句子的数据增强拉远(作为负例)。通过将句意相似的句子彼此拉近的方式,更好的学习句子级别的语义信息。
该文章的贡献如下:
1,设计了四种数据增强的方式random-words-deletion随机词语删除,spans-deletion随机连续token删除, synonym-substitution同义词替换, reordering重新排序。
2,设计了对比学习的思路更好的对句子级别的语义进行表征。
3,在很多下游任务上取得了很好的效果。
效果其实跟最新的比起来效果一般:

ESimCSE
通过对比学习,进行自监督的方法,使用计算交叉熵为loss通过softmax分类来学习正负样本相似度。ESimCSE是SimCSE升级版。SimCSE是通过dropout两个句子产生两个相似的正负样本进行对比学习,来学习到文本匹配之间的关系。ESimCSE解决了SimCSE遗留的两个问题:
1、SimCSE通过dropout构建的正例对包含相同长度的信息(原因:Transformer的Position Embedding),会使模型倾向于认为相同或相似长度的句子在语义上更相似;
2、更大的batch size会导致SimCSE性能下降;
ESimCSE构建正例对的方法:**Word Repetition(单词重复)**和 **Momentum Contrast(动量对比学习)**扩展负样本对。
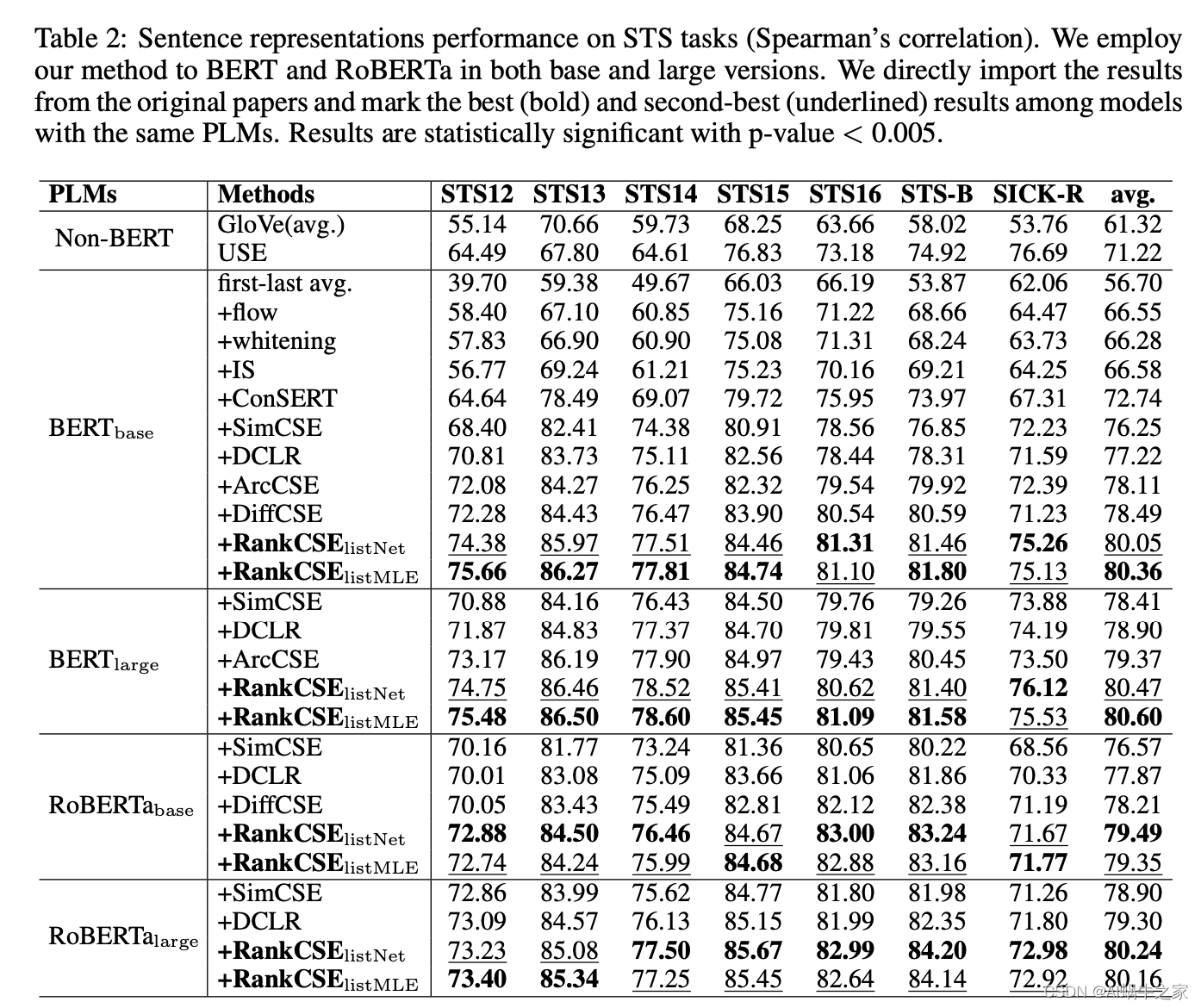
RankCSE
非官方代码实现:https://github.com/perceptiveshawty/RankCSE
对比学习不仅需要考虑样本之间是否为正负对,还需要思考更加细粒度的相似程度关系。锚点对正负样本的打分不能仅仅通过 InfoNCE 去拉开正样本和所有负样本的表示,还需要加入排序信息。
(1) standard contrastive learning objective (§4.2);
(2) ranking consistency loss which ensures ranking consistency between two representations with different dropout masks (§4.3);
(3) ranking distillation loss which distills listwise ranking knowledge from the teacher

两种排序:保证两次 dropout 排序的一致性;用教师模型将样本间排序信息蒸馏给学生模型;
-
常规对比学习损失:
ζ i n f o N C E = − ∑ i = 1 N l o g e x p ( d ( f ( x i ) , f ( x i ) ′ ) / τ 1 ∑ j = 1 N e x p ( d ( f ( x i ) , f ( x j ) ′ ) / τ 1 ) \zeta_{infoNCE} = -\sum_{i=1}^N log\frac{exp(d(f(x_i),f(x_i)')/\tau_1}{\sum_{j=1}^N exp(d(f(x_i),f(x_j)')/\tau_1)} ζinfoNCE=−i=1∑Nlog∑j=1Nexp(d(f(xi),f(xj)′)/τ1)exp(d(f(xi),f(xi)′)/τ1 -
一致性排序: 对齐两次 forward 的 infoNCE 分母,具体而言,对于一个样本,对齐的两个排序分布为该样本第一次前向传播的 emb 和所有 inbatch 样本第二次前向传播的 emb 计算的排序分布和反转后的排序分布。将这两个分布计算 JS 散度。
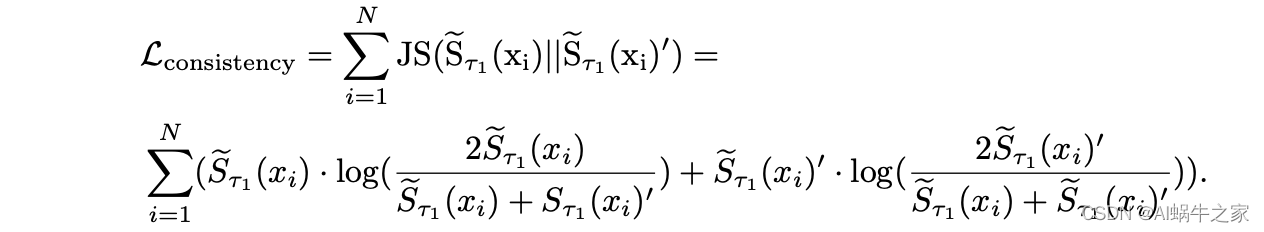
-
教师排序蒸馏: 使用训练好的 simcse 作为教师,得到每个样本第一次前向传播的 emb 和所有 inbatch 样本第二次前向传播的 emb 计算的排序分布作为软标签,使用 list-wise 的方法蒸馏。 注意由于锚点和正样本分数太高,丢弃这部分分数。 蒸馏时,使用两个教师模型的标签按照权重混合。排序的loss可以表示如下:
ζ r a n k = ∑ i = 1 N r a n k ( S ( x i ) , S T ( x i ) ) \zeta_{rank} = \sum_{i=1}^Nrank(S(x_i),S^T(x_i)) ζrank=i=1∑Nrank(S(xi),ST(xi))
其中,N表示的是batch内的样本数,注意不是某个query对应的doc数量
具体的,蒸馏损失可以使用 ListNet 或者 ListMLE:- 其中ListNet用的是Top1的简化版本 :
ζ L i s t N e t = − ∑ i = 1 N s o f t m a x ( S T ( x i ) / τ 3 ∗ l o g ( s o f t m a x ( S ( x i ) / τ 2 ) ) \zeta_{ListNet} = - \sum_{i=1}^Nsoftmax(S^T(x_i)/\tau_3 * log(softmax(S(x_i)/\tau_2)) ζListNet=−i=1∑Nsoftmax(ST(xi)/τ3∗log(softmax(S(xi)/τ2)) - ListMLE直接根据groundtruth的顺序最大化最大似然估计,所以只是用到了teacher模型打分之后得出来的排名,没有直接用模型打分。
ζ L i s t M L E = − ∑ i = 1 N l o g ( π i T ∣ S ( x i ) , τ 2 ) ) \zeta_{ListMLE} = -\sum_{i=1}^N log(\pi_i^T|S(x_i),\tau_2)) ζListMLE=−i=1∑Nlog(πiT∣S(xi),τ2))
π i T \pi_i^T πiT表示老师模型的排序情况,具体详见下面定义部分。另外注意这里模型预测分数并没有softmax做归一化。
其中,部分定义如下:

- 其中ListNet用的是Top1的简化版本 :
最终的损失为 :
ζ
f
i
n
a
l
=
ζ
i
n
f
o
N
C
E
+
β
ζ
c
o
n
s
i
s
t
e
n
c
y
+
γ
ζ
r
a
n
k
\zeta_{final} = \zeta_{infoNCE}+\beta\zeta_{consistency}+\gamma\zeta_{rank}
ζfinal=ζinfoNCE+βζconsistency+γζrank
最终结果
数据增强
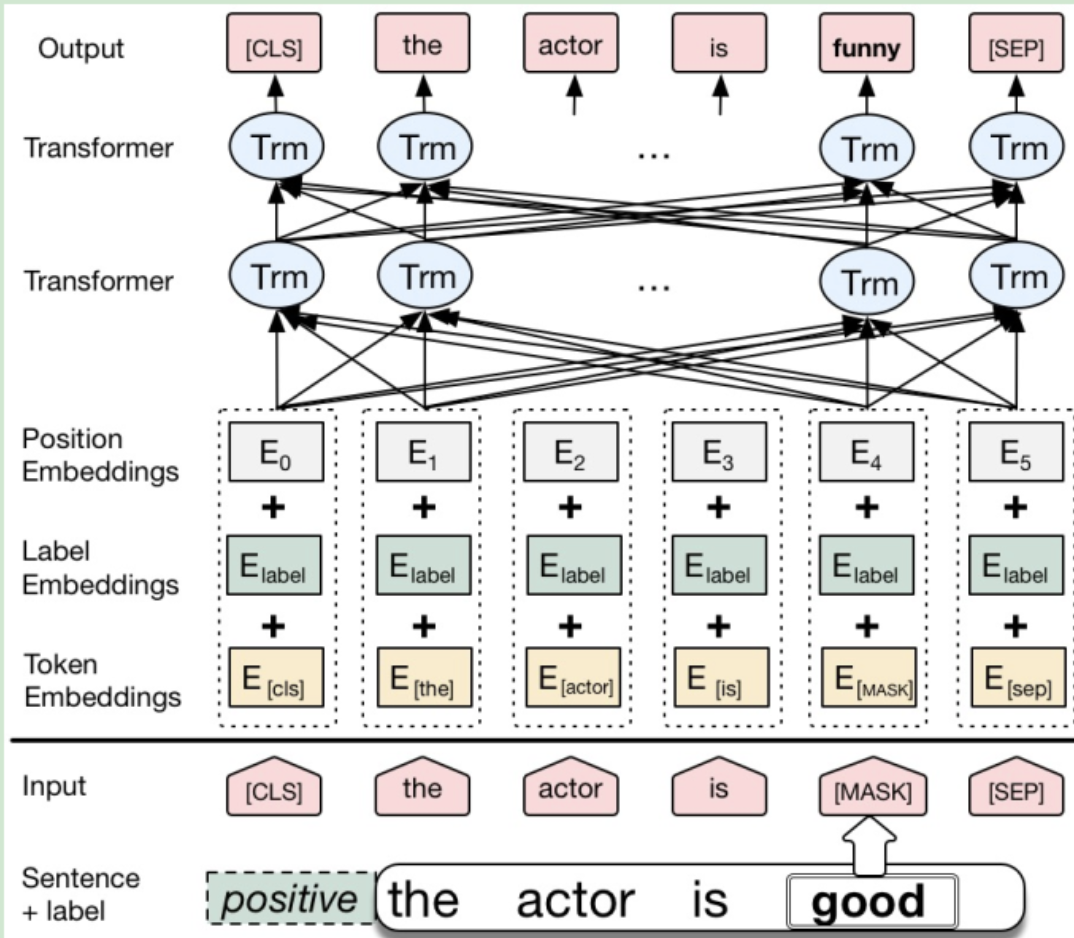
Conditional BERT Contextual Augmentation
CBert 的模型结构与 Bert 完全一致,区别仅在于“输入的表征” 与 “训练过程”。在CBert 中, 标签信息是通过 Segmentation Embedding 表示的,Bert 原文中Segmentation Embedding 只有两个值,在 CBert 中需调整为 num_classes。通过该种方式,将标签信息融入到 MLM 任务中,实现了在预测替换词时,不仅考虑上下文,还考虑了标签信息,这就是论文中命名的 Conditional MLM。
训练过程方面与 Bert 也十分相似,只是 CBert 在“标注的训练语料”上 Fine-Tune 时,采用的是 CMLM 任务, 而不是 MLM任务。
最后一步就是对训练数据进行增强,将 Fine-Tune 后的 CBert 在训练语料上进行 Conditional MLM 任务,注意在预测替换词时,不应该选取概率最大对应的词,而应该在TopN范围(或其它有效方式)内随机选择一个替换词,以提高数据分布的多样性。
https://blog.csdn.net/weixin_44815943/article/details/124122407
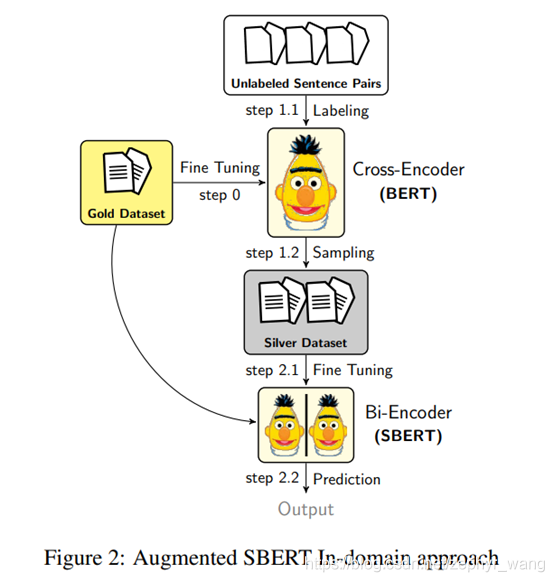
Augmented SBERT
采用cross-encoder弱标注所有可能的句子对组合会导致巨大的开销,甚至可能导致模型表现力下降。所以我们需要合适的采样策略,减少弱标注的句子对,提升模型表现力。
(1) Random Sampling (RS)
(2) Kernel Density Estimation (KDE):目的是保证silver 数据和gold数据的分布保持一致。为此,我们弱标注大量随机的句子对后,但只保留一定的组合。如对于分类任务,只保留positive的句子对;对于回归任务,使用 kernel density estimation (KDE)来估计连续的对于分数s的密度函数Fgold(s) and Fsilver(s)。
不过,KDE采样策略计算效率不好,需要大量随机的采样。我们后面没有采用该方法。
(3) BM25 Sampling (BM25):采用Okapi BM25算法。我们利用ElasticSearch。对每个句子提取最相似的k个句子。然后这些句子对使用cross-encoder弱标注,并都被当做silver数据使用。该方法运行效率很高。本文推荐此方法。
(4) Semantic Search Sampling (SS):BM25的一个缺点是只能找到词汇重叠的句子,所以同义词,其没有或者只有很少重叠的句子不会被选择。该方法,我们使用cosine-similarity选择最相似的k个语句。也可以采用Faiss。
(5) BM25 + Semantic Search Sampling (BM25- S.S.)
https://blog.csdn.net/zephyr_wang/article/details/119581505
ViLBERT
https://zhuanlan.zhihu.com/p/264488613
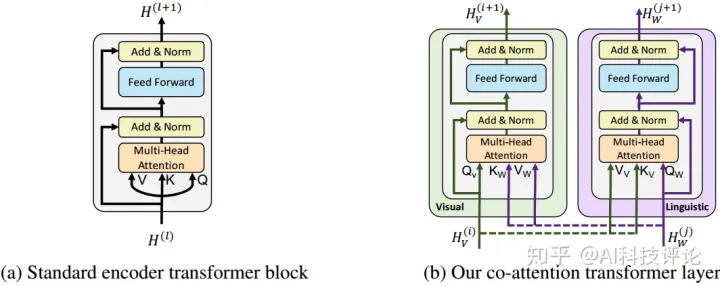

2.1 共注意力Transformer层
本文引入的共注意力transformer层如Figure 1b所示。给定vision和language特征,图像模态的keys和values输入到文本模态的attention 单元(反之亦然),attention单元为每一个模态基于另一种模态产生attention-pooled特征,在vision流中表现为基于图像条件的语言attention,在语言流中即语言条件下的vision attention。与BERT一样,attention特征与初始化输出residual 相加。
2.2 图像representation
基于一个pretrain的object-detection网络生成图像rpn及其视觉特征。与单词不同,图像的区域是无须的,这篇论文使用一个5-dim的vector对区域进行位置编码,5个元素分别为normal后的bounding boxes的左上角和右下角的坐标以及图像区域的覆盖占比,然后用一个映射将之与视觉特征维数匹配并sum。使用一个特定的图像token作为图像序列的开始,并用它的输出表征整个图像。
2.3 预训练任务
训练ViLBERT时采用了2个预训练的任务:
(1)遮蔽多模态建模
与标准BERT一样,对词和图像rpn输入大约15%进行mask,通过余下的输入序列对mask掉的元素进行预测。对图像进行mask时,0.9的概率是直接遮挡,另外0.1的概率保持不变。文本的mask与bert的一致。vilbert并不直接预测被mask的图像区域特征值,而是预测对应区域在语义类别上的分布,使用pretrain的object-detection模型的输出作为ground-truth,以最小化这两个分布的KL散度为目标。
(2)预测多模态对齐
如图4-b所示,其目标是预测图像-文本对是否匹配对齐,即本文是否正确的描述了图像。以图像特征序列的起始IMG token和文本序列的起始CLS token的输出作为视觉和语言输入的整体表征。借用vision-and-language模型中另一种常见结构,将IMG token的输出和CLS token的输出进行element-wise product作为最终的总体表征。再利用一个线性层预测图像和文本是否匹配。

faster r-cnn
https://zhuanlan.zhihu.com/p/31426458
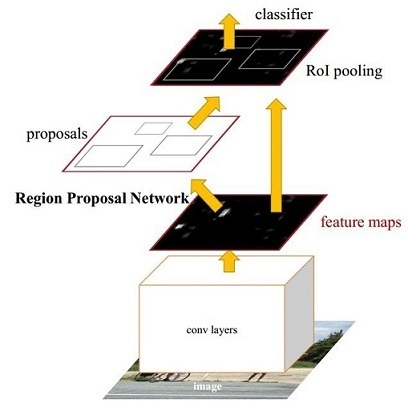
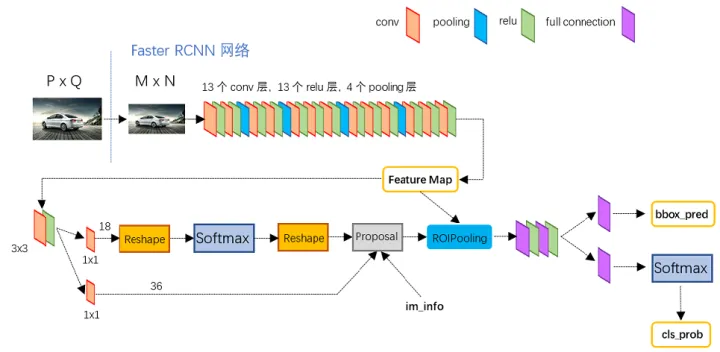
Faster RCNN其实可以分为4个主要内容:
Conv layers。作为一种CNN网络目标检测方法,Faster RCNN首先使用一组基础的conv+relu+pooling层提取image的feature maps。该feature maps被共享用于后续RPN层和全连接层。
Region Proposal Networks。RPN网络用于生成region proposals。该层通过softmax判断anchors属于positive或者negative,再利用bounding box regression修正anchors获得精确的proposals。
Roi Pooling。该层收集输入的feature maps和proposals,综合这些信息后提取proposal feature maps,送入后续全连接层判定目标类别。
Classification。利用proposal feature maps计算proposal的类别,同时再次bounding box regression获得检测框最终的精确位置。
多模态特征融合
多模态融合fusion的各种操作
双线性特征融合
双线性池化(Bilinear Pooling)详解、改进及应用
Bilinear Attention Networks 笔记
双线性注意力网络模型《Bilinear Attention Networks》

对比学习
https://www.cnblogs.com/xyzhrrr/p/15864522.html
对比学习在语义表征中的应用:SBERT/SimCSE/ConSERT/ESimCSE复现
语义计算
句子语义表示方法效果对比
Sentence Embedding 现在的 sota 方法是什么?