消息队列的作用
解耦、削峰、 异步(非必要逻辑异步运行,加快响应速度)
kafka
首先有个topic的概念,类似于表。
Partition 分区:一个topic下面有多个分区,这些分区会存储到不同的服务器上面,或者说,其实就是在不同的主机上建了不同的目录。多个分区多个线程,多个线程并行处理肯定会比单线程好得多。Topic 也是逻辑概念,而 Partition 就是分布式存储单元。
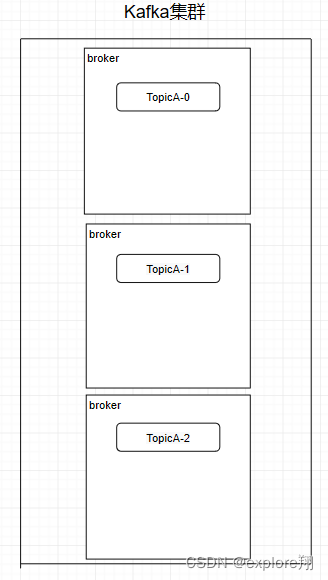
Replica 副本机制:Partition 为了保证数据安全,所以每个 Partition 可以设置多个副本。
而且其实每个副本都是有角色之分的,它们会选取一个副本作为 Leader,而其余的作为 Follower。
我们的生产者在发送数据的时候,是直接发送到 Leader Partition 里面,然后 Follower Partition 会去 Leader 那里自行同步数据,消费者消费数据的时候,也是从 Leader 那去消费数据的。
Consumer Group 消费者组:
我们在消费数据时会在代码里面指定一个 group.id,这个 id 代表的是消费组的名字。不同组可有唯一的一个消费者去消费同一主题的数据。
Kafka 也是主从式的架构,主节点就叫 Controller,其余的为从节点,Controller 是需要和 Zookeeper 进行配合管理整个 Kafka 集群。
broker分布式部署,就需要一个注册中心来进行统一管理。Zookeeper用一个专门节点保存Broker服务列表,也就是 /brokers/ids。broker在启动时,向Zookeeper发送注册请求,Zookeeper会在/brokers/ids下创建这个broker节点,如/brokers/ids/[0…N],并保存broker的IP地址和端口。
这个节点临时节点,一旦broker宕机,这个临时节点会被自动删除。
Zookeeper也会为topic分配一个单独节点,每个topic都会以/**brokers/topics/[topic_name]**的形式记录在Zookeeper。一个topic的消息会被保存到多个partition,这些partition跟broker的对应关系也需要保存Zookeeper。当分区的leader故障转移也需要zookeeper参与。
消费者组也会向Zookeeper进行注册,Zookeeper会为其分配节点来保存相关数据,节点路径为/consumers/{group_id}
Controller的选举工作依赖于Zookeeper,选举成功后,Zookeeper会创建一个/controller临时节点。
控制器用来监听分区变化(元数据变化,Leader故障,增减分区)、topic变化、broker变化。
kafka缺点就是:需要同时部署两个系统。而且分区增加时,Zookeeper集群压力变大,达到一定级别后,监听延迟增加,给Kafaka的工作带来了影响。并且单个控制节点如果节点故障,新的Controller选举成功后,会重新从Zookeeper拉取元数据进行初始化,并且需要通知其他所有的broker更新ActiveControllerId。老的Controller需要关闭监听、事件处理线程和定时任务。分区数非常多时,这个过程非常耗时,而且这个过程中Kafka集群是不能工作的。
(有新的采用多个控制节点,用raft协议保证他们的一致性)
Kafka 性能好在什么地方?
1、磁盘顺序写。随机写的话是在文件的某个位置修改数据,性能会较低。
2、零拷贝技术。下面是非零拷贝,数据要从内核状态拷贝到kafka进程空间,再拷贝到socket的缓存。耗时比较高。
Kafka 利用了 Linux 的 sendFile 技术(NIO),省去了进程切换和一次数据拷贝,让性能变得更好。内核的数据直接发送到网卡了。
零拷贝技术要多说一点。C++的vector也涉及到零拷贝,比如emplace_back是零拷贝,因为不用拷贝一个临时对象,采用的是右值引用?尤其是当涉及到很大的数据拷贝非常消耗时空资源
而这里网络中的零拷贝:
传统的:read首先DMA从磁盘拷贝到内核页缓存,再拷贝到用户空间。write先从用户拷贝到socket内核缓存,再拷贝到网卡;
mmap:零拷贝的一种。主要思想是把内核空间和用户态共享,就不用拷贝到用户态,上下文切换。
sendfile:Linux2.1内核开始引入了sendfile函数,用于将文件通过socket传送。主要优化是在内核socket缓冲区中记录当前要发生的数据在page buffer中的位置和偏移量。这样直接从page buf就可以发到网卡,没有拷贝的过程。

3、日志分段存储 Kafka 规定了一个分区内的 .log 文件最大为 1G,做这个限制目的是为了方便把 .log 加载到内存去操作。 其实redis对于主从复制时RDB文件的大小也会有限制,不然加载到内存很慢。
4、Kafka 的网络设计
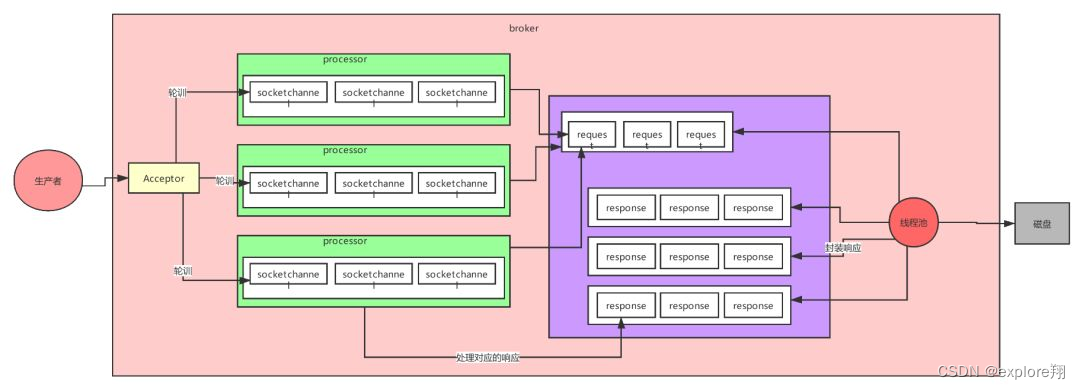
加强版的 Reactor 网络线程模型。是一个三层的设计 prosessors-qequest-线程池。
acceptor不进行处理而是封装成channel给processors。然后消费者线程去消费这些 socketChannel 时,会获取一个个 Request 请求,里面包含了数据,然后线程池来读取。
所以如果我们需要对 Kafka 进行增强调优,增加 Processor 并增加线程池里面的处理线程,就可以达到效果。
ngix
是一个http代理和反向代理的web服务器,内存少15MB启动快高并发。还可以实现负载均衡和动静分离。
应用场景:
1、做http服务器,静态的网站,例如说:我们使用的OpenVPN。
2、反向代理实现负载均衡。当网站的访问量达到一定程度后,单台服务器不能满足用户的请求时,需要用多台服务器集群可以使用nginx做反向代理,并且多台服务器可以平均分担负载。它会让客户端感觉不到,依然输入原来的网址。
3、安全配置防火墙功能
处理请求的流程:
启动时读取配置文件得到需要监听的ip,port。然后主进程会创建好套接字(socket,bind,listen)
然后fork出很多子进程,竞争accept新的连接,这个时候客户端就可以和ngix建立三次握手了。某一个子进程会 accept 成功,得到这个建立好的连接的 Socket ,然后创建 nginx 对连接的封装
接着,设置读写事件处理函数,并添加读写事件来与客户端进行数据的交换。最后,Nginx 或客户端来主动关掉连接,到此,一个连接就寿终正寝了
高并发的原因:因为webserver是IO密集型的,主要是网络IO。所以也是用到了IO复用+异步非阻塞IO
也是用到了单线程+epoll和redis一样。
动静分离根据静态资源的特点将其做缓存操作,这就是网站静态化处理的核心思路
严格意义上,可以理解成使用nginx处理静态页面,tomcat或PHP处理动态页面。静态资源就是多次访问,源代码不变的(CSS,jpg、js)动态资源:当用户多次访问这个资源,资源的源代码可能会发送改变。
当然,因为现在七牛、阿里云等 CDN 服务已经很成熟,主流的做法,是把静态资源缓存到 CDN 服务中,从而提升访问速度。
相比本地的 Nginx 来说,CDN 服务器由于在国内有更多的节点,可以实现用户的就近访问。并且,CDN 服务可以提供更大的带宽,不像我们自己的应用服务,提供的带宽是有限的。