提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 一、正则表达式概述
- 二、基本的正则表达式
- 三、操作演示
一、正则表达式概述
- 正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
正则表达式的特点:
①.灵活性、逻辑性和功能性非常强;
②.可以迅速地用极简单的方式达到字符串的复杂控制。
③.对于刚接触的人来说,比较晦涩难懂。
正则表达式的组成:
由普通字符与元字符组成
普通字符 :包括大小写字母、数字、标点符号及一些其他符号。
字符 :是指在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符在目标对象中的出现模式。
正则表达式和通配符的区别:
通配符:在Linux中,一般配合find命令用于对文件目录,文件名的查找
正则表达式:匹配文件内容,用于精确筛选信息,可以配合grep,egrep,awk,sed命令进行搭配使用,查找时,也比通配符更加精确
二、基本的正则表达式
| 元字符 | 说明 |
|---|---|
| \ | 转义字符,用于取消特殊符号的含义 |
| ^ | 匹配字符串开始的位置 |
| $ | 匹配字符串结束的位置 |
| . | 匹配除\n之外的任意的一个字符 |
| * | 匹配前面子表达式0次或者多次 |
| [list] | 匹配list列表中的一个字符 |
| [^list] | 匹配任意非list列表中的一个字符 |
| {n} | 匹配前面的子表达式n次 |
| {n,} | 匹配前面的子表达式不少于n次 |
| {n,m} | 匹配前面的子表达式n到m次 |
| \w | 匹配包括下划线的任何单词字符 |
| \W | 匹配任何非单词字符 |
| \d | 匹配一个数字字符 |
| \D | 匹配一个非数字字符 |
| \s | 空白符 |
| \S | 非空白符 |
| + | 匹配前面子表达式1次以上 |
| ? | 匹配前面子表达式0次或者1次 |
| () | 将括号中的字符串作为一个整体 |
| 丨 | 以或的方式匹配字符串 |
三、操作演示
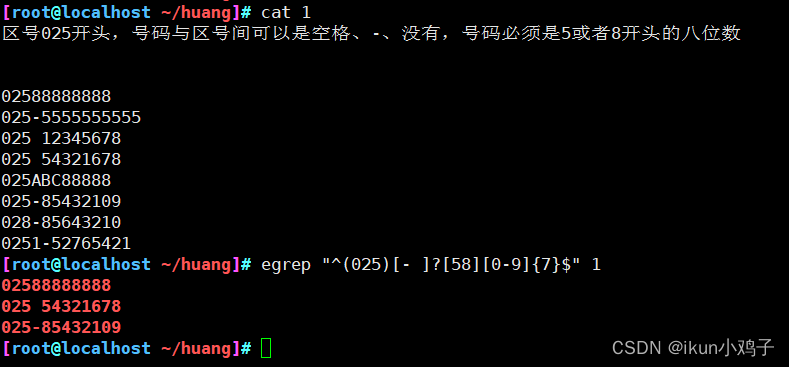
示例一:
匹配025开头的区号
区号与后面的号码以"-"或者 空格 或者 为空
电话号码要以 5 或者 8 开头的八位数
egrep "^(025)[- ]?[58][0-9]{7}$" t
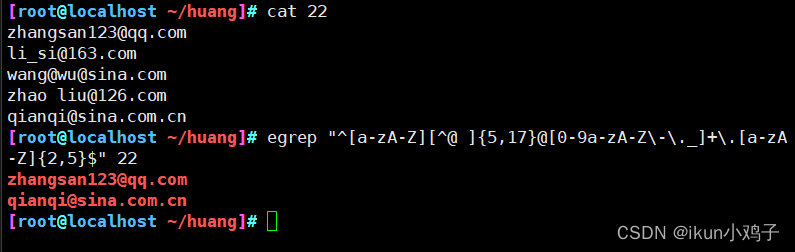
示例二:
用户名@子域名.[二级域名].顶级域
要求:
1.用户名@:长度要求在6-18位,任意大小写英文,任意数字,除了@符号和空格以外的其他任意符号字符,开头只能是_或者字母
2.子域名:[二级域名]:长度任意,符号只能包含-_.
3.顶级域名:长度在2-5,任意大小写英文
egrep "^[a-zA-Z][^@ ]{5,17}@[0-9a-zA-Z\-\._]+\.[a-zA-Z]{2,5}$" 2