1 Field属性
Field是文档中的域,包括Field名和Field值两部分,一个文档可以包括多个Field,Document只是Field的一个承载体,Field值即为要索引的内容,也是要搜索的内容。
- 是否分词(tokenized)
是:作分词处理,即将Field值进行分词,分词的目的是为了索引。
比如:商品名称、商品描述等,这些内容用户要输入关键字搜索,由于搜索的内容格式大、内容多需要分词后将语汇单元建立索引
否:不作分词处理
比如:商品id、订单号、身份证号等
是否索引(indexed)
是:进行索引。将Field分词后的词或整个Field值进行索引,存储到索引域,索引的目的是为了搜索。
比如:商品名称、商品描述分析后进行索引,订单号、身份证号不用分词但也要索引,这些将来都要作为查询条件。
否:不索引。
比如:图片路径、文件路径等,不用作为查询条件的不用索引。
是否存储(stored)
是:将Field值存储在文档域中,存储在文档域中的Field才可以从Document中获取。
比如:商品名称、订单号,凡是将来要从Document中获取的Field都要存储。
否:不存储Field值
比如:商品描述,内容较大不用存储。如果要向用户展示商品描述可以从系统的关系数据库中获取。
2 Field常用类型
下边列出了开发中常用 的Filed类型,注意Field的属性,根据需求选择:
| Field类 | 数据类型 | Analyzed是否分词 | Indexed是否索引 | Stored是否存储 | 说明 |
| StringField(FieldName,FieldValue,Store.YES)) | 字符串 | N | Y | Y或N | 这个Field用来构建一个字符串Field,但是不会进行分词,会将整个串存储在索引中,比如(订单号,身份证号等)是否存储在文档中用Store.YES或Store.NO决定 |
| FloatPoint(FieldName, FieldValue) | Float型 | Y | Y | N | 这个Field用来构建一个Float数字型Field,进行分词和索引,不存储, 比如(价格) 存储在文档中 |
| DoublePoint(FieldName,FieldValue) | Double型 | Y | Y | N | 这个Field用来构建一个Double数字型Field,进行分词和索引,不存储 |
| LongPoint(FieldName, FieldValue) | Long型 | Y | Y | N | 这个Field用来构建一个Long数字型Field,进行分词和索引,不存储 |
| IntPoint(FieldName, FieldValue) | Integer型 | Y | Y | N | 这个Field用来构建一个Integer数字型Field,进行分词和索引,不存储 |
| StoredField(FieldName, FieldValue) | 重载方法,支持多种类型 | N | N | Y | 这个Field用来构建不同类型Field不分析,不索引,但要Field存储在文档中 |
| TextField(FieldName, FieldValue,Store.NO) 或 TextField(FieldName,reader) | 字符串或流 | Y | Y | Y或N | 如果是一个Reader, lucene猜测内容比较多,会采用Unstored的策略. |
| NumericDocValuesField(FieldName,FieldValue) | 数值 | - | - | - | 配合其他域排序使用 |
3 Field修改
3.1 修改分析
图书id:
是否分词:不用分词,因为不会根据商品id来搜索商品
是否索引:不索引,因为不需要根据图书ID进行搜索
是否存储:要存储,因为查询结果页面需要使用id这个值。
图书名称:
是否分词:要分词,因为要根据图书名称的关键词搜索。
是否索引:要索引。
是否存储:要存储。
图书价格:
是否分词:要分词,lucene对数字型的值只要有搜索需求的都要分词和索引,因 为lucene对数字型的内容要特殊分词处理,需要分词和索引。
是否索引:要索引
是否存储:要存储
图书图片地址:
是否分词:不分词
是否索引:不索引
是否存储:要存储
图书描述:
是否分词:要分词
是否索引:要索引
是否存储:因为图书描述内容量大,不在查询结果页面直接显示,不存储。
不存储是不在lucene的索引域中记录,节省lucene的索引文件空间。
如果要在详情页面显示描述,解决方案:
从lucene中取出图书的id,根据图书的id查询关系数据库(MySQL)中book表得到描述信息。
3.2 代码修改
对之前编写的testCreateIndex()方法进行修改。
代码片段
/**
* 创建索引库
*/
@Test
public void createIndexTest() throws Exception {
//1. 采集数据
SkuService skuService = new SkuServiceImpl();
List<Sku> skuList = skuService.querySkuList();
//文档集合
List<Document> docList = new ArrayList<>();
for (Sku sku : skuList) {
//2. 创建文档对象
Document document = new Document();
//创建域对象并且放入文档对象中
/**
* 是否分词: 否, 因为主键分词后无意义
* 是否索引: 是, 如果根据id主键查询, 就必须索引
* 是否存储: 是, 因为主键id比较特殊, 可以确定唯一的一条数据, 在业务上一般有重要所用, 所以存储
* 存储后, 才可以获取到id具体的内容
*/
document.add(new StringField("id", sku.getId(), Field.Store.YES));
/**
* 是否分词: 是, 因为名称字段需要查询, 并且分词后有意义所以需要分词
* 是否索引: 是, 因为需要根据名称字段查询
* 是否存储: 是, 因为页面需要展示商品名称, 所以需要存储
*/
document.add(new TextField("name", sku.getName(), Field.Store.YES));
/**
* 是否分词: 是(因为lucene底层算法规定, 如果根据价格范围查询, 必须分词)
* 是否索引: 是, 需要根据价格进行范围查询, 所以必须索引
* 是否存储: 是, 因为页面需要展示价格
*/
document.add(new IntPoint("price", sku.getPrice()));
document.add(new StoredField("price", sku.getPrice()));
/**
* 是否分词: 否, 因为不查询, 所以不索引, 因为不索引所以不分词
* 是否索引: 否, 因为不需要根据图片地址路径查询
* 是否存储: 是, 因为页面需要展示商品图片
*/
document.add(new StoredField("image", sku.getImage()));
/**
* 是否分词: 否, 因为分类是专有名词, 是一个整体, 所以不分词
* 是否索引: 是, 因为需要根据分类查询
* 是否存储: 是, 因为页面需要展示分类
*/
document.add(new StringField("categoryName", sku.getCategoryName(), Field.Store.YES));
/**
* 是否分词: 否, 因为品牌是专有名词, 是一个整体, 所以不分词
* 是否索引: 是, 因为需要根据品牌进行查询
* 是否存储: 是, 因为页面需要展示品牌
*/
document.add(new StringField("brandName", sku.getBrandName(), Field.Store.YES));
//将文档对象放入到文档集合中
docList.add(document);
}
//3. 创建分词器, StandardAnalyzer标准分词器, 对英文分词效果好, 对中文是单字分词, 也就是一个字就认为是一个词.
Analyzer analyzer = new IKAnalyzer();
//4. 创建Directory目录对象, 目录对象表示索引库的位置
Directory dir = FSDirectory.open(Paths.get("E:\\dir"));
//5. 创建IndexWriterConfig对象, 这个对象中指定切分词使用的分词器
IndexWriterConfig config = new IndexWriterConfig(analyzer);
//6. 创建IndexWriter输出流对象, 指定输出的位置和使用的config初始化对象
IndexWriter indexWriter = new IndexWriter(dir, config);
//7. 写入文档到索引库
for (Document doc : docList) {
indexWriter.addDocument(doc);
}
//8. 释放资源
indexWriter.close();
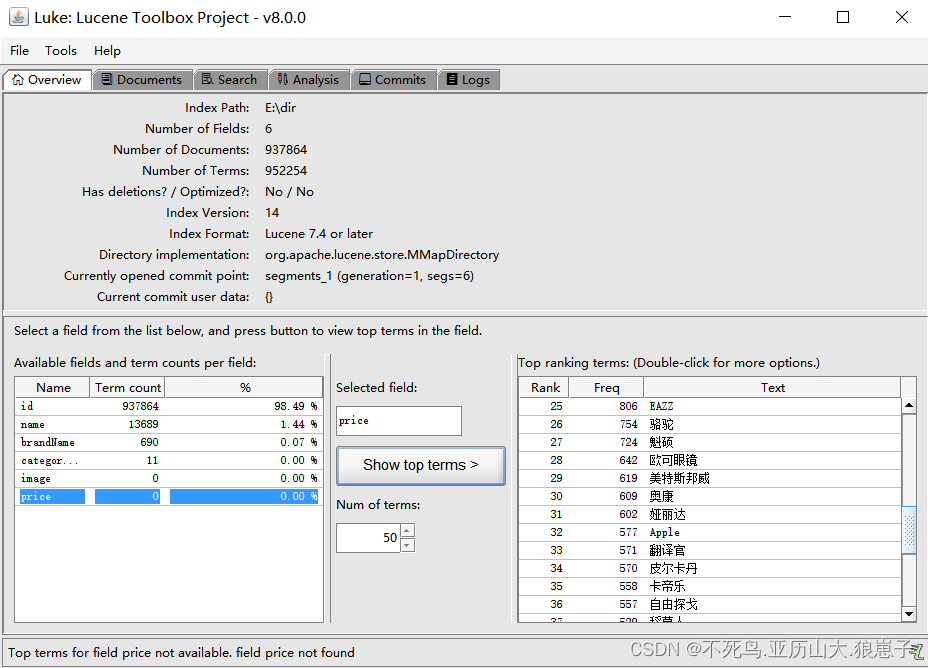
}使用luke查看索引的建立情况