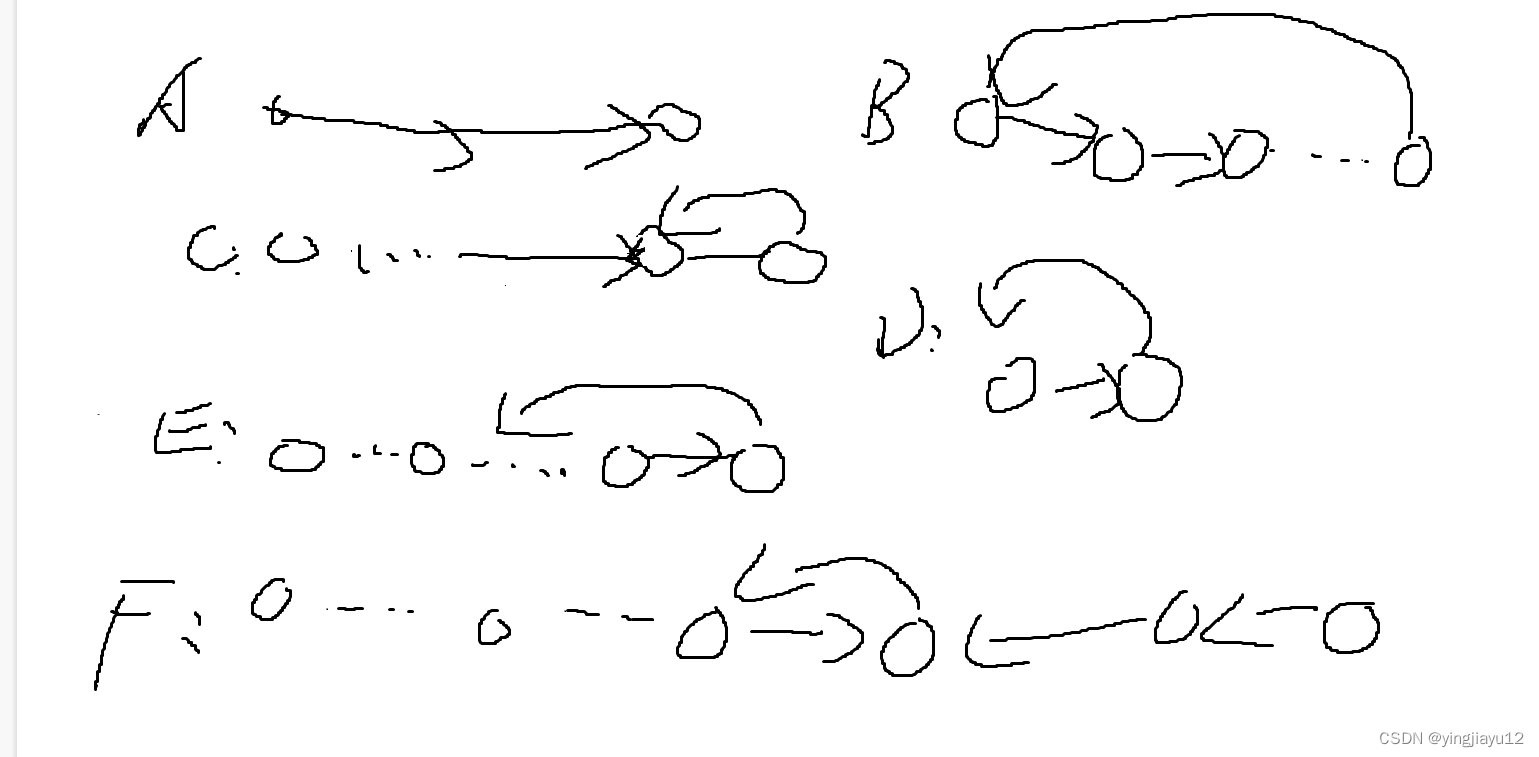文章目录
- 1. 前言
- 2. 背景
- 3. ARM32 中断向量表 和 中断处理流程
- 3.1 ARM32 中断向量表
- 3.2 ARM32 中断处理流程
- 4. ARM32 各CPU模式下的栈配置
- 4.1 SVC模式下各CPU栈配置(内核栈配置)
- 4.1.1 BOOT CPU SVC模式栈配置(内核栈配置)
- 4.1.2 非 BOOT CPU SVC模式栈配置(内核栈配置)
- 4.2 中断异常模式下各CPU栈配置
- 4.2.1 系统启动阶段的中断异常模式下各CPU栈配置
- 4.2.2 中断异常发生时各异常模式CPU栈配置
- 4.3 User模式栈配置(用户空间栈配置)
- 4.3.1 启动新程序时的堆栈配置流程
- 4.3.2 子进程堆栈配置流程
- 4.3.3 线程堆栈配置流程
- 4.3.4 其它情形的栈配置
- 5. 观察和调整进程栈空间
- 5.1 观察进程栈空间
- 5.2 调整进程栈空间
- 6. 参考资料
1. 前言
限于作者能力水平,本文可能存在谬误,因此而给读者带来的损失,作者不做任何承诺。
2. 背景
本文基于 ARM32 架构 + Linux 4.14 内核源码 进行分析。
3. ARM32 中断向量表 和 中断处理流程
看到这里,读者可能产生了疑问,栈的使用和中断有什么关系?这里先给出答案:应用的 各CPU 的内核模式栈(即 CPU SVC 模式栈),是在系统启动阶段进行配置;应用的用户栈(即 CPU User 模式栈),是在系统创建应用进程时进行配置;而除 CPU SVC/User 模式的栈外,其它异常模式的栈,在系统启动阶段为每个CPU配置了一个很小空间的栈,但是这个小空间,对于处理异常是不够的,于是在进入各异常模式向量后、在正式处理异常之前,将 CPU 模式切换到 SVC 模式,进而借用 CPU SVC 模式栈(即各 CPU 的内核栈)进行异常处理。有一个例外的是 ARM32 CPU 的 System 模式不被 Linux 使用,所以也不涉及到栈的配置。
由于在 CPU 异常模式下进行了栈配置,自然就涉及到中断处理流程,所以在这里先简单介绍下 ARM32 中断向量的组织结构,以及中断的处理简要流程。
3.1 ARM32 中断向量表
在 ARM32 架构的 Linux 内核代码,中断向量组织可以认为是一个二维数组 vectors[8][16]。vectors[8][16] 数组的第一维索引是如下CPU 异常模式:
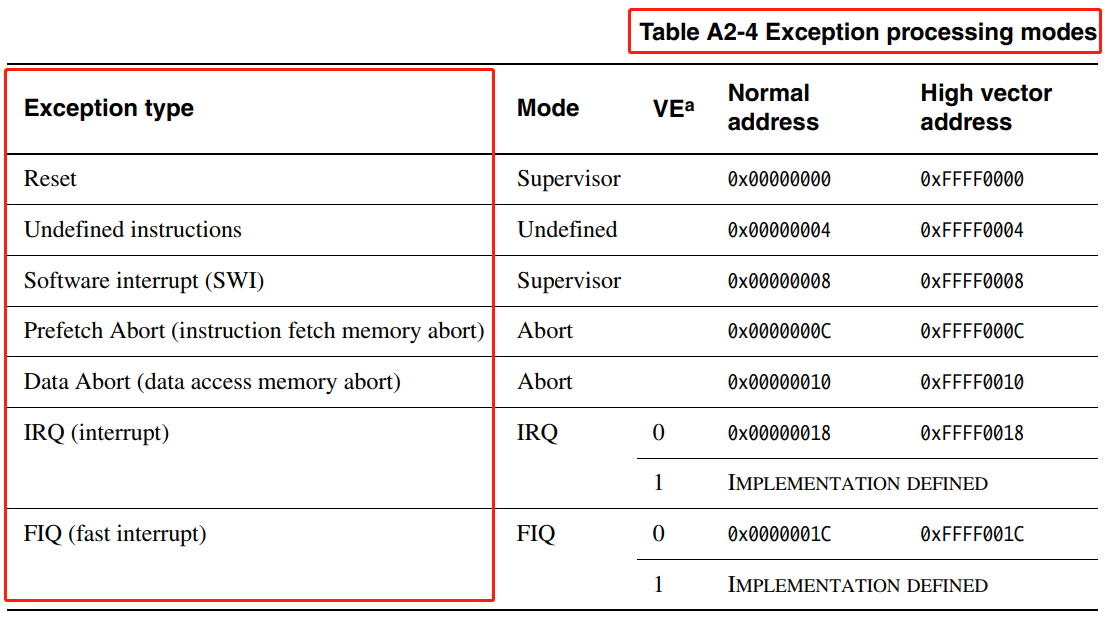
vectors[8][16] 数组的第二维索引是如下CPU 模式的低4位:
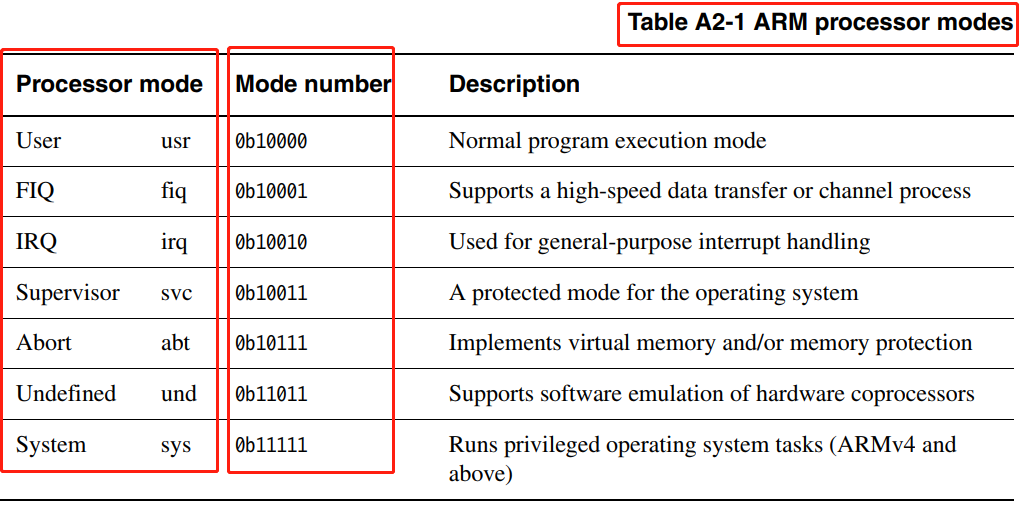
注意,第二维索引 是以上图中 Mode number ,即以 ARM32 CPU 模式的低4位为索引,ARM32 CPU 没有实现所有 5 位 CPU 模式的所有位模式组合,因此向量表的有些第二维的入口是非法的,定义为 __irq_invalid 。来看 ARM32 CPU 中断向量表 的具体定义,先看向量表第一维的组织形式:
/* arch/arm/kernel/entry-armv.S */
/* 中断向量表第一维:按 CPU 异常模式 组织 */
.section .vectors, "ax", %progbits
.L__vectors_start:
W(b) vector_rst
W(b) vector_und
W(ldr) pc, .L__vectors_start + 0x1000
W(b) vector_pabt
W(b) vector_dabt
W(b) vector_addrexcptn
W(b) vector_irq
W(b) vector_fiq再看向量表的第二维组织形式:
/* arch/arm/kernel/entry-armv.S */
/* reset 异常向量表 */
vector_rst:
ARM( swi SYS_ERROR0 )
THUMB( svc #0 )
THUMB( nop )
b vector_und
/* Undefined 异常向量表 */
vector_stub und, UND_MODE /* vector_und */
.long __und_usr @ 0 (USR_26 / USR_32) /* User 模式 未定义指令异常 入口 */
.long __und_invalid @ 1 (FIQ_26 / FIQ_32)
.long __und_invalid @ 2 (IRQ_26 / IRQ_32)
.long __und_svc @ 3 (SVC_26 / SVC_32) /* SVC 模式 未定义指令异常 入口 */
.long __und_invalid @ 4
.long __und_invalid @ 5
.long __und_invalid @ 6
.long __und_invalid @ 7
.long __und_invalid @ 8
.long __und_invalid @ 9
.long __und_invalid @ a
.long __und_invalid @ b
.long __und_invalid @ c
.long __und_invalid @ d
.long __und_invalid @ e
.long __und_invalid @ f
/* 预取(Prefetch)异常向量表 */
vector_stub pabt, ABT_MODE, 4 /* vector_pabt */
.long __pabt_usr @ 0 (USR_26 / USR_32)
.long __pabt_invalid @ 1 (FIQ_26 / FIQ_32)
.long __pabt_invalid @ 2 (IRQ_26 / IRQ_32)
.long __pabt_svc @ 3 (SVC_26 / SVC_32)
.long __pabt_invalid @ 4
.long __pabt_invalid @ 5
.long __pabt_invalid @ 6
.long __pabt_invalid @ 7
.long __pabt_invalid @ 8
.long __pabt_invalid @ 9
.long __pabt_invalid @ a
.long __pabt_invalid @ b
.long __pabt_invalid @ c
.long __pabt_invalid @ d
.long __pabt_invalid @ e
.long __pabt_invalid @ f
/* 数据异常(Data Abort)向量表 */
vector_stub dabt, ABT_MODE, 8 /* vector_dabt */
.long __dabt_usr @ 0 (USR_26 / USR_32)
.long __dabt_invalid @ 1 (FIQ_26 / FIQ_32)
.long __dabt_invalid @ 2 (IRQ_26 / IRQ_32)
.long __dabt_svc @ 3 (SVC_26 / SVC_32)
.long __dabt_invalid @ 4
.long __dabt_invalid @ 5
.long __dabt_invalid @ 6
.long __dabt_invalid @ 7
.long __dabt_invalid @ 8
.long __dabt_invalid @ 9
.long __dabt_invalid @ a
.long __dabt_invalid @ b
.long __dabt_invalid @ c
.long __dabt_invalid @ d
.long __dabt_invalid @ e
.long __dabt_invalid @ f
/* 地址异常(Address Exception)向量表 */
vector_addrexcptn:
b vector_addrexcptn
/* IRQ 异常向量表 */
vector_stub irq, IRQ_MODE, 4 /* vector_irq */
.long __irq_usr @ 0 (USR_26 / USR_32)
.long __irq_invalid @ 1 (FIQ_26 / FIQ_32)
.long __irq_invalid @ 2 (IRQ_26 / IRQ_32)
.long __irq_svc @ 3 (SVC_26 / SVC_32)
.long __irq_invalid @ 4
.long __irq_invalid @ 5
.long __irq_invalid @ 6
.long __irq_invalid @ 7
.long __irq_invalid @ 8
.long __irq_invalid @ 9
.long __irq_invalid @ a
.long __irq_invalid @ b
.long __irq_invalid @ c
.long __irq_invalid @ d
.long __irq_invalid @ e
.long __irq_invalid @ f
/* FIQ 异常向量表 */
vector_stub fiq, FIQ_MODE, 4 /* vector_fiq */
.long __fiq_usr @ 0 (USR_26 / USR_32)
.long __fiq_svc @ 1 (FIQ_26 / FIQ_32)
.long __fiq_svc @ 2 (IRQ_26 / IRQ_32)
.long __fiq_svc @ 3 (SVC_26 / SVC_32)
.long __fiq_svc @ 4
.long __fiq_svc @ 5
.long __fiq_svc @ 6
.long __fiq_abt @ 7
.long __fiq_svc @ 8
.long __fiq_svc @ 9
.long __fiq_svc @ a
.long __fiq_svc @ b
.long __fiq_svc @ c
.long __fiq_svc @ d
.long __fiq_svc @ e
.long __fiq_svc @ f3.2 ARM32 中断处理流程
发生中断异常后,系统自动将执行流程跳转到中断上述向量表 .L__vectors_start 中,对应异常模式的向量表入口,如发生了 IRQ 中断,则会进入到向量表 .L__vectors_start 中 vector_irq 向量表项;然后再根据 CPU 的模式是 SVC 还是 User ,分别跳转到第二维中断向量表 vector_stub irq, IRQ_MODE, 4 的 __irq_svc(SVC模式) 或 __irq_usr(User 模式) 入口进行执行;在处理完中断后,再返回到被中断的程序继续执行。这就是中断执行的主干流程,更多关于中断处理流程的细节,可参考 Linux: 中断实现简析 。
4. ARM32 各CPU模式下的栈配置
4.1 SVC模式下各CPU栈配置(内核栈配置)
4.1.1 BOOT CPU SVC模式栈配置(内核栈配置)
/* arch/arm/kernel/head-common.S */
__INIT
__mmap_switched: /* 此处代码运行于 MMU 开启状况 */
adr r3, __mmap_switched_data /* r3 = __mmap_switched_data 虚拟地址 */
...
/*
* r4 = &processor_id (arch/arm/kernel/setup.c)
* r5 = &__machine_arch_type (arch/arm/kernel/setup.c)
* r6 = &__atags_pointer (arch/arm/kernel/setup.c)
* r7 = &cr_alignment (arch/arm/kernel/entry-armv.S)
* sp = 当前 CPU 的 swapper 进程内核栈指针
*/
ARM( ldmia r3, {r4, r5, r6, r7, sp})
...
b start_kernel /* 跳转到 start_kernel() 执行 */
align 2
.type __mmap_switched_data, %object
__mmap_switched_data:
...
/* 当前 CPU 的 swapper 进程内核栈指针 */
.long init_thread_union + THREAD_START_SP @ sp
.size __mmap_switched_data, . - __mmap_switched_data4.1.2 非 BOOT CPU SVC模式栈配置(内核栈配置)
/* arch/arm/kernel/smp.c */
/* 非 BOOT CPU 启动流程中 */
__cpu_up(cpu, idle)
...
/* 配置 @cpu (非 BOOT CPU) 的首进程 swapper 的内核栈空间 */
secondary_data.stack = task_stack_page(idle) + THREAD_START_SP;
...之后的 非 BOOT CPU 启动流程__cpu_up() -> ... -> secondary_startup:
/* arch/arm/kernel/head.S */
ENTRY(secondary_startup)
...
/*
* Use the page tables supplied from __cpu_up.
*/
adr r4, __secondary_data /* r4 = __secondary_data 的当前物理地址 */
/*
* r5 = __secondary_data 的链接虚拟地址
* r7 = secondary_data 的链接虚拟地址
* r12 = __secondary_switched 的链接虚拟地址
*/
ldmia r4, {r5, r7, r12} @ address to jump to after
...
/* r13 = __secondary_switched 的链接虚拟地址, __enable_mmu 后跳转到此处执行 */
mov r13, r12 @ __secondary_switched address
...
ENDPROC(secondary_startup)之后会经历 secondary_startup -> __turn_mmu_on :
/* arch/arm/kernel/head.S */
ENTRY(__turn_mmu_on)
...
/*
* BOOT CPU: r13 = __mmap_switched
* 非 BOOT CPU: r13 = __secondary_switched 的链接虚拟地址
*/
mov r3, r13
/*
* BOOT CPU: 返回到 __mmap_switched 处
* 非 BOOT CPU: 返回到 __secondary_switched 处
*/
ret r3
__turn_mmu_on_end:
ENTRY(__secondary_switched)
/* 配置非 BOOT CPU SVC 模式栈(即内核栈) */
ldr sp, [r7, #12] @ get secondary_data.stack
mov fp, #0
b secondary_start_kernel
ENDPROC(__secondary_switched)4.2 中断异常模式下各CPU栈配置
4.2.1 系统启动阶段的中断异常模式下各CPU栈配置
start_kernel()
setup_arch()
setup_processor()
cpu_init()/* arch/arm/kernel/setup.c */
void notrace cpu_init(void)
{
#ifndef CONFIG_CPU_V7M
unsigned int cpu = smp_processor_id();
struct stack *stk = &stacks[cpu];
if (cpu >= NR_CPUS) {
pr_crit("CPU%u: bad primary CPU number\n", cpu);
BUG();
}
/*
* This only works on resume and secondary cores. For booting on the
* boot cpu, smp_prepare_boot_cpu is called after percpu area setup.
*/
set_my_cpu_offset(per_cpu_offset(cpu)); // TODO: per CPU 相关
/*
* arch/arm/mm/proc-v7.S, cpu_v7_proc_init
* ...
*/
cpu_proc_init();
/*
* Define the placement constraint for the inline asm directive below.
* In Thumb-2, msr with an immediate value is not allowed.
*/
#ifdef CONFIG_THUMB2_KERNEL
#define PLC "r"
#else
#define PLC "I"
#endif
/*
* setup stacks for re-entrant exception handlers
*/
__asm__ (
"msr cpsr_c, %1\n\t" /* CPU 切换到 IRQ 模式 */
"add r14, %0, %2\n\t"
"mov sp, r14\n\t" /* 设置 IRQ 模式堆栈 */
"msr cpsr_c, %3\n\t" /* CPU 切换到 Abort 模式 */
"add r14, %0, %4\n\t"
"mov sp, r14\n\t" /* 设置 ABT 模式堆栈 */
"msr cpsr_c, %5\n\t" /* CPU 切换到 Undefined 模式 */
"add r14, %0, %6\n\t"
"mov sp, r14\n\t" /* 设置 UND 模式堆栈 */
"msr cpsr_c, %7\n\t" /* CPU 切换到 FIQ 模式 */
"add r14, %0, %8\n\t"
"mov sp, r14\n\t" /* 设置 FIQ 模式堆栈 */
"msr cpsr_c, %9" /* CPU 切回 SVC 模式 */
:
: "r" (stk), /* %0 */
PLC (PSR_F_BIT | PSR_I_BIT | IRQ_MODE), /* %1 */
"I" (offsetof(struct stack, irq[0])), /* %2 */
PLC (PSR_F_BIT | PSR_I_BIT | ABT_MODE), /* %3 */
"I" (offsetof(struct stack, abt[0])), /* %4 */
PLC (PSR_F_BIT | PSR_I_BIT | UND_MODE), /* %5 */
"I" (offsetof(struct stack, und[0])), /* %6 */
PLC (PSR_F_BIT | PSR_I_BIT | FIQ_MODE), /* %7 */
"I" (offsetof(struct stack, fiq[0])), /* %8 */
PLC (PSR_F_BIT | PSR_I_BIT | SVC_MODE) /* %9 */
: "r14");
#endif
}上面的代码,为每个 CPU 的各异常模式 IRQ, Abort, Undefined, FIQ ,配置了定义在 stacks[] 中的栈空间,看一下 stacks[] 定义:
/*
* 除 User,System,SVC 3个模式外的堆栈.
* User,SVC 3个模式的堆栈,分别由应用程序,或 各 CPU 启动阶段各自设置,
* 而 Linux 内核模式不适用 System 模式。
*/
struct stack {
u32 irq[3];
u32 abt[3];
u32 und[3];
u32 fiq[3];
} ____cacheline_aligned;
#ifndef CONFIG_CPU_V7M
static struct stack stacks[NR_CPUS]; /* 每 CPU、每模式(除 SVC/System/User 模式外)的 堆栈 */
#endif看到了吧,每个 CPU 的各异常模式的栈空间大小为 3 个 u32 大小,总共 12 字节,对于异常处理流程,这个真是太小了。我们继续看下一小节,看 ARM32 Linux 内核是怎么处理这个问题的。
4.2.2 中断异常发生时各异常模式CPU栈配置
异常发生是,会跳转到中断向量表中去执行。假设发生了一个 IRQ 中断,将跳转到 vector_irq 处执行:
vector_stub irq, IRQ_MODE, 4 /* vector_irq */
.long __irq_usr @ 0 (USR_26 / USR_32)
.long __irq_invalid @ 1 (FIQ_26 / FIQ_32)
.long __irq_invalid @ 2 (IRQ_26 / IRQ_32)
.long __irq_svc @ 3 (SVC_26 / SVC_32)
...汇编宏 vector_stub 定义了 vector_irq 中断向量,但关于 vector_stub 一些至关重要的细节,我们在前面没有展开,这里补充一下:
.macro vector_stub, name, mode, correction=0
.align 5
vector_\name:
.if \correction
sub lr, lr, #\correction
.endif
/*
* 刚进入中断异常时,使用的是各模式独立的栈,除 User/SVC/System 模式的栈,
* 其它在各 CPU 启动阶段初始化:
* start_kernel()
* setup_arch()
* setup_processor()
* cpu_init()
* // static struct stack stacks[NR_CPUS];
* User 模式的栈,由 C 启动代码初始化;
* SVC 模式的栈是各 CPU 启动阶段,或进程切换是,设置为进程内核栈;
* 另外,Linux 不适用 System 模式。
* 可以看到,各 CPU 在 cpu_init() 设置的栈:
* struct stack {
* u32 irq[3];
* u32 abt[3];
* u32 und[3];
* u32 fiq[3];
* } ____cacheline_aligned;
* 各模式(除 User/System/SVC 模式外)仅有 3 个 u32 的空间,从
* 下面的代码可以看到,这3个 u32 用来存储当前的 {r0, lr, spsr},
* 如进入 Undefined 模式,则对应 CPU 的:
* stack::und[0] = r0 (被 und 中断时 r0 的值, r0 所有模式共用)
* stack::und[1] = lr_und
* stack::und[2] = spsr_und (被 und 中断模式下的 cpsr)
* 就这样,当前异常模式下的 3 个 u32 空间,已经被消耗光了,
* 接下来如果还要使用栈空间,该怎么办? 答案是,代码将 CPU 切换
* 到 SVC 模式,复用 SVC 模式的栈空间。
*/
stmia sp, {r0, lr} @ save r0, lr
mrs lr, spsr /* lr = spsr_und (被异常中断模式的 cpsr, 如 cpsr_usr) */
str lr, [sp, #8] @ save spsr
/* 切换到 SVC 模式,复用 SVC 模式的栈空间 */
mrs r0, cpsr
eor r0, r0, #(\mode ^ SVC_MODE | PSR_ISETSTATE)
msr spsr_cxsf, r0 /* 切换到 SVC 模式 */
/*
* 仅保留 spsr (被异常中断模式的 cpsr) 低 4 位,即
* CPU 模式低 4 位,用来索引异常模式向量表 .vectors ,
* 以定义异常模式向量入口。
*/
and lr, lr, #0x0f
/*
* 现在 CPU 已经位于 SVC 模式,sp 也指向了 SVC 模式的内核栈.
* 因为接下来会复用 SVC 模式栈空间, 可能修改 sp 的值,所以先保存 SVC 的 sp 指针到 r0
*/
mov r0, sp /* r0 = SVC 模式栈指针当前值 */
/*
* 定位异常向量表入口, 根据前面的代码:
* and lr, lr, #0x0f
* 以及此处使用
* pc + (lr << 2)
* 来定义为异常向量入口,因为此时 pc 指向下一条指令
* movs pc, lr
* 索引这要求当前异常模式的向量表,必须紧跟着
* movs pc, lr
* 指令,中间不能存在任何空隙。
*/
ARM( ldr lr, [pc, lr, lsl #2] ) /* lr = CPU 当前异常模式向量入口 (如 __und_svc / __und_usr) */
/* 跳转到异常向量入口 (如 __und_svc / __und_usr) */
movs pc, lr @ branch to handler in SVC mode
ENDPROC(vector_\name)看到了吧,异常处理的代码,会先保存 r0,lr,spsr_xxx 到 cpu_init() 配置的异常模式栈上,然后将 CPU 模式切换到 SVC 模式,然后使用 SVC 模式的栈(内核栈),进行异常处理流程。上述分析中,涉及到多核CPU启动过程,细节可参考 Linux: 多核CPU启动流程简析 。
4.3 User模式栈配置(用户空间栈配置)
4.3.1 启动新程序时的堆栈配置流程
bash 通过 fork + exec() 系统调用来启动一个新程序:系统调用返回用户空间前,配置了堆栈空间;系统调用返回用户空间时,将设置配置好的堆栈指针值到 sp 寄存器。来看细节:
/* fs/exec.c */
/* 只看 exec() 系统调用过程,这是重点 */
static int do_execveat_common(int fd, struct filename *filename,
struct user_arg_ptr argv,
struct user_arg_ptr envp,
int flags)
{
...
struct linux_binprm *bprm;
...
...
bprm = kzalloc(sizeof(*bprm), GFP_KERNEL);
...
/*
* 为可执行程序创建新的进程地址空间管理数据并初始化
* . 为新程序创建并初始化内存管理对象 mm_struct: 创建页目录表等
* . 为新程序初始化栈空间: [STACK_TOP_MAX - PAGE_SIZE, STACK_TOP_MAX]
* @bprm->p 指向 栈空间第1个可用位置 STACK_TOP_MAX - sizeof(void *)
*/
retval = bprm_mm_init(bprm);
...
/* 将可执行程序文件名压入程序栈 bprm->p (相应的移动栈指针 bprm->p 到下一个可用位置) */
retval = copy_strings_kernel(1, &bprm->filename, bprm);
bprm->exec = bprm->p; /* 指向可执行程序文件名 */
retval = copy_strings(bprm->envc, envp, bprm); /* 拷贝环境变量 */
/* 将程序用户参数压入程序栈 (相应的移动栈指针 bprm->p 到下一个可用位置) */
retval = copy_strings(bprm->argc, argv, bprm);
...
/* 调用具体类型的程序加载器, 来加载新程序 */
retval = exec_binprm(bprm); /* 以 ELF 格式程序加载为例: -> load_elf_binary() */
...
return retval;
...
}ELF 程序加载过程中,重新设定堆栈空间位置和大小:
/* fs/binfmt_elf.c */
static int load_elf_binary(struct linux_binprm *bprm)
{
...
/*
* 随机化栈顶后, 重新设定程序栈空间位置和大小.
* 如果栈空间位置和大小发生了变化:
* . 将之前压入到栈上的程序名和参数移动到新栈空间的相应位置;
* . 相应的调整栈空间 VMA (bprm->vma) 和 栈指针 bprm->p
*/
retval = setup_arg_pages(bprm, randomize_stack_top(STACK_TOP),
executable_stack);
...
/* N.B. passed_fileno might not be initialized? */
current->mm->end_code = end_code;
current->mm->start_code = start_code;
current->mm->start_data = start_data;
current->mm->end_data = end_data;
current->mm->start_stack = bprm->p; /* 程序启动前, 栈指针位置 */
...
/*
* 启动 程序 或 解释器程序:
* 程序 或 解释器程序初始化后, 然后进入程序代码开始运行。
*
* 注意到,这里最主要的动作是赋值了用户模式下的 PC SP 等寄存器,
* 程序代码真正运行起来是在系统调用 sys_execve*() 返回用户空间之后。
*/
start_thread(regs, elf_entry, bprm->p);
retval = 0;
...
out_ret:
return retval;
}看一下 start_thread() 到底做了什么工作:
/* arch/arm/include/asm/processor.h */
#define start_thread(regs,pc,sp) \
({ \
memset(regs->uregs, 0, sizeof(regs->uregs)); \
if (current->personality & ADDR_LIMIT_32BIT) \
regs->ARM_cpsr = USR_MODE; \
else \
regs->ARM_cpsr = USR26_MODE; \
if (elf_hwcap & HWCAP_THUMB && pc & 1) \
regs->ARM_cpsr |= PSR_T_BIT; \
regs->ARM_cpsr |= PSR_ENDSTATE; \
regs->ARM_pc = pc & ~1; /* pc */ \
/* 设置程序用户态堆栈指针 */ \
regs->ARM_sp = sp; /* sp */ \
nommu_start_thread(regs); \
})start_thread() 并不会像它的名字一样,将新进程调度起来。新程序真正调度起来,是在系统调用返回用户空间时完成的,此时会配置用户空间的堆栈指针 sp 寄存器:
/* arch/arm/kernel/entry-armv.S */
/*
* Register switch for ARMv3 and ARMv4 processors
* r0 = previous task_struct, r1 = previous thread_info, r2 = next thread_info
* previous and next are guaranteed not to be the same.
*/
ENTRY(__switch_to)
add ip, r1, #TI_CPU_SAVE
ARM( stmia ip!, {r4 - sl, fp, sp, lr} ) @ Store most regs on stack
ldr r4, [r2, #TI_TP_VALUE]
ldr r5, [r2, #TI_TP_VALUE + 4]
......
mov r0, r5
/* 加载新进程的寄存器(包括 sp, pc),然后切换到新进程运行 */
ARM( ldmia r4, {r4 - sl, fp, sp, pc} ) @ Load all regs saved previously
ENDPROC(__switch_to)应该了解的是,前面只是配置了进程堆栈的虚拟地址空间,而真正的物理内存分配,是在写入时触发缺页中断完成的。
4.3.2 子进程堆栈配置流程
可以通过 fork() 系统调用来创建子进程,这些进程会在创建时复制父进程的地址空间(包含堆栈);然后在写入时发生写时拷贝(COW: Copy-On-Write),进而建立进程自己独立的内存空间。来看细节:
/* kernel/fork.c */
sys_fork()
_do_fork()
copy_process()
copy_mm()
copy_thread_tls()
copy_thread() /* 细节见 4.3.3 */
static int copy_mm(unsigned long clone_flags, struct task_struct *tsk)
{
struct mm_struct *mm, *oldmm;
...
oldmm = current->mm;
...
/* initialize the new vmacache entries */
vmacache_flush(tsk);
mm = dup_mm(tsk);
...
good_mm:
tsk->mm = mm;
tsk->active_mm = mm;
return 0;
}
static struct mm_struct *dup_mm(struct task_struct *tsk)
{
struct mm_struct *mm, *oldmm = current->mm;
mm = allocate_mm();
memcpy(mm, oldmm, sizeof(*mm));
if (!mm_init(mm, tsk, mm->user_ns))
goto fail_nomem;
err = dup_mmap(mm, oldmm);
...
return mm;
}4.3.3 线程堆栈配置流程
不同于上小节通过 fork() 系统调用创建的进程,应用编程中,我们常见到使用 pthread_create() 来创建线程(传递 CLONE_VM 标志位给系统调用 clone()),这些线程会共享主线程(线程组leader)的地址空间:
/* kernel/fork.c */
sys_clone()
_do_fork()
copy_process()
copy_mm()
static int copy_mm(unsigned long clone_flags, struct task_struct *tsk)
{
struct mm_struct *mm, *oldmm;
...
oldmm = current->mm;
...
if (clone_flags & CLONE_VM) { /* clone() / vfork(): 共享主线程(线程组leader)的地址空间 */
mmget(oldmm); /* 增加地址空间 mm_struct 引用计数 */
mm = oldmm;
goto good_mm;
}
...
good_mm:
tsk->mm = mm;
tsk->active_mm = mm;
return 0;
}新线程共享了主线程(线程组leader)的地址空间,也就意味着共享了堆栈空间,这显然是不行的:线程组内线程 A 将堆栈指针 sp 放置了位置 P1,这时候切换到线程 B 执行,线程 B 将堆栈指针 sp 切换到比 P1 地址更大的 P2(假设堆栈由高地址向低地址增长),然后一通写,当再切回到线程 A 的时候,线程 A 发现自己栈上数据已经被写乱了,因为线程 A 和 B 共享了堆栈空间。 这时候该怎么办?Linux 内核为这种情形预留了方案:可以通过预先分配线程栈空间,然后将分配的栈空间地址和大小传递给 clone() 系统调用 来解决。来看具体细节,首先 glibc 的 pthread 在创建线程时,用 mmap() 调用预分配一段进程虚拟地址空间,作为新线程的栈空间:
pthread_create()
/* 用 mmap() 从进程地址空间,划分一段虚拟地址空间,用作新线程栈空间 */
allocate_stack (iattr, &pd, &stackaddr, &stacksize)
mem = __mmap (NULL, size, (guardsize == 0) ? prot : PROT_NONE,
MAP_PRIVATE | MAP_ANONYMOUS | MAP_STACK, -1, 0);
...
pd->stackblock = mem;
...
*stacksize = stacktop - pd->stackblock;
*stack = pd->stackblock;
/* 将栈空间范围传递给 clone() 系统调用 */
create_thread (pd, iattr, &stopped_start, stackaddr, stacksize, &thread_ran);
const int clone_flags = (CLONE_VM | CLONE_SETTLS | ...);
...
struct clone_args args =
{
...
/* 指定新线程的栈空间虚拟地址范围 */
.stack = (uintptr_t) stackaddr,
.stack_size = stacksize,
...
};
__clone_internal (&args, &start_thread, pd); /* 调用系统调用 clone() */接着看系统调用 clone() 是怎么处理线程栈空间的:
/* kernel/fork.c */
sys_clone()
_do_fork()
copy_process()
copy_mm()
copy_thread_tls(clone_flags, stack_start, stack_size, p, tls)
copy_thread(clone_flags, sp, arg, p)/* arch/arm/kernel/process.c */
int
copy_thread(unsigned long clone_flags, unsigned long stack_start,
unsigned long stk_sz, struct task_struct *p)
{
struct thread_info *thread = task_thread_info(p);
struct pt_regs *childregs = task_pt_regs(p);
memset(&thread->cpu_context, 0, sizeof(struct cpu_context_save));
...
if (likely(!(p->flags & PF_KTHREAD))) { /* 非内核线程 */
*childregs = *current_pt_regs(); /* 复制父进程的寄存器 */
childregs->ARM_r0 = 0; /* 子进程 fork()/vfork()/clone() 返回值为 0 */
if (stack_start) /* 有线程独立的栈空间吗 */
childregs->ARM_sp = stack_start; /* 设置线程独立的栈空间: sp 指针指向该栈空间 */
} else {
...
}
/*
* 子进程从 fork()/vfork()/clone() 系列系统调用返回到 ret_from_fork,
* 然后从 ret_from_fork 返回用户空间。如:
* sys_fork() -> ... -> wake_up_new_task() -> ... -> ret_from_fork -> 用户空间
* 进入内核空间时,会将用户空间寄存器保存到内核栈上;从内核返回用户空间时,会进行
* 对应的出栈操作,所以这里的 sp 指向将要出栈的寄存器空间。
*/
thread->cpu_context.pc = (unsigned long)ret_from_fork;
thread->cpu_context.sp = (unsigned long)childregs;
...
return 0;
}更多关于系统调用的实现细节,可参考 Linux系统调用实现简析 。
4.3.4 其它情形的栈配置
还没说到的情形就只有 vfork() 了,虽然 vfork() 父子进程共享地址空间,但由于父进程在子进程退出之前都不会运行,所以情形就简单了,反正父子进程不存在冲突访问。更多关于 vfork() 的细节可参考 Linux: vfork() 程序异常退出问题分析 。
5. 观察和调整进程栈空间
5.1 观察进程栈空间
可以通过命令 ulimit -s 来观察系统中全局默认的进程栈大小,同样也可以通过该命令配置系统中全局默认的进程栈大小。进程自身的资源限制状况(包括堆栈)也可以通过 /proc/<PID>/limits 进行观察。getrlimit(), pctrl() 接口可以用来获取系统资源的配置状况。
5.2 调整进程栈空间
setrlimit() 可以用来配置系统全局资源限制,进而可以影响进程栈空间大小,pctrl(PR_SET_MM) 也是类似的接口。
6. 参考资料
《ARM Architecture Reference Manual.pdf》