一、前言
在一些简单系统中,我们可以直接使用数据库ID自增方式来标识和保存数据,但是随着系统的逐渐复杂,数据量的日益增多,我们可能需要对数据表、数据库实现分库分表。单纯的使用数据库的ID自增无法满足业务场景了,所以我们必须找到一种方式来生成一个全局唯一的ID。我们可以先想一下,这个生成的ID的系统需要满足什么条件呢?
1.必须是全局唯一的:如果在一个订单系统中,订单号是重复的那将是灾难的。
2.高性能:生成ID,可以说是一个业务逻辑实现非常小的环节,如果在这个环节浪费很多时间,那么势必会对业务逻辑造成影响,也是不可取的。
3.高可用:让系统99.9%是可用的
4.简单:简单是我们设计一个功能应该是一直追求的。
二、实现原理
数据库号段:顾名思义就是一个数据的一个范围,例如(100,200],这个100到200就可以称为一个号段。我们可以一次向数据库申请一个号段,然后加载到内存中,然后用自增的方式生成这个ID,如果这个号段用完了,再向数据库申请另一个新的号段。
1、数据表的设计:
| id | biz_type | max_id | tep | version |
|---|---|---|---|---|
| 1 | 0001 | 100 | 2000 | 0 |
biz_type::业务标识,不同业务使用不同的号段
max_id:当前最大的可用ID
tep:每次生成ID的范围长度
version:版本号,乐观锁,每次更新加上版本号,保证并发更新的准确性
2、使用步骤:
- 查询当前的max_id信息:select id, biz_type, max_id, step, version from tiny_id_info where biz_type=‘0001’;
- 计算新的max_id: new_max_id = max_id + step
- 更新DB中的max_id:update tiny_id_info set max_id=#{new_max_id} , verison=version+1 where id=#{id} and max_id=#{max_id} and version=#{version}
- 如果更新成功,则可用号段获取成功,新的可用号段为(max_id, new_max_id]
- 如果更新失败,则号段可能被其他线程获取,回到步骤a,进行重试。
三、高可用架构
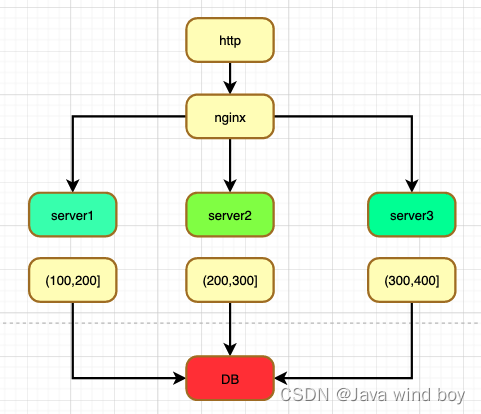
ID生成系统对外提供http服务,请求经过负载均衡选择一个server,从事先加载好的号段中生成一个ID,如果没有号段或者号段已经用完,再向DB按照上边的步骤获取一个新的号段,多个server通过version乐观锁保证生成的号段不会重复。
四、问题与优化
- 假如某一个server重启或者宕机
那么这个server生成的号段就作废了,而且只是浪费一部分号段,对这个ID生成系统没影响。 - DB挂了怎么办
DB挂了,我们依然可以通过缓存加载的号段对外提供服务,不过这个时间是有限的,如果缓存的号段都用完了,那么就无法对外提供服务了。我们想要彻底解决这个问题,DB就不能是单机的。 - DB不是单机的,怎么保证不会生成重复ID呢?
其实这个解决方案还是挺简单的,我们只需要在上边设计的数据表里新增字段。假如有A、B两个DB,那么我们就设定一个标识字段,让A生成偶数号段,B生成奇数号段即可。