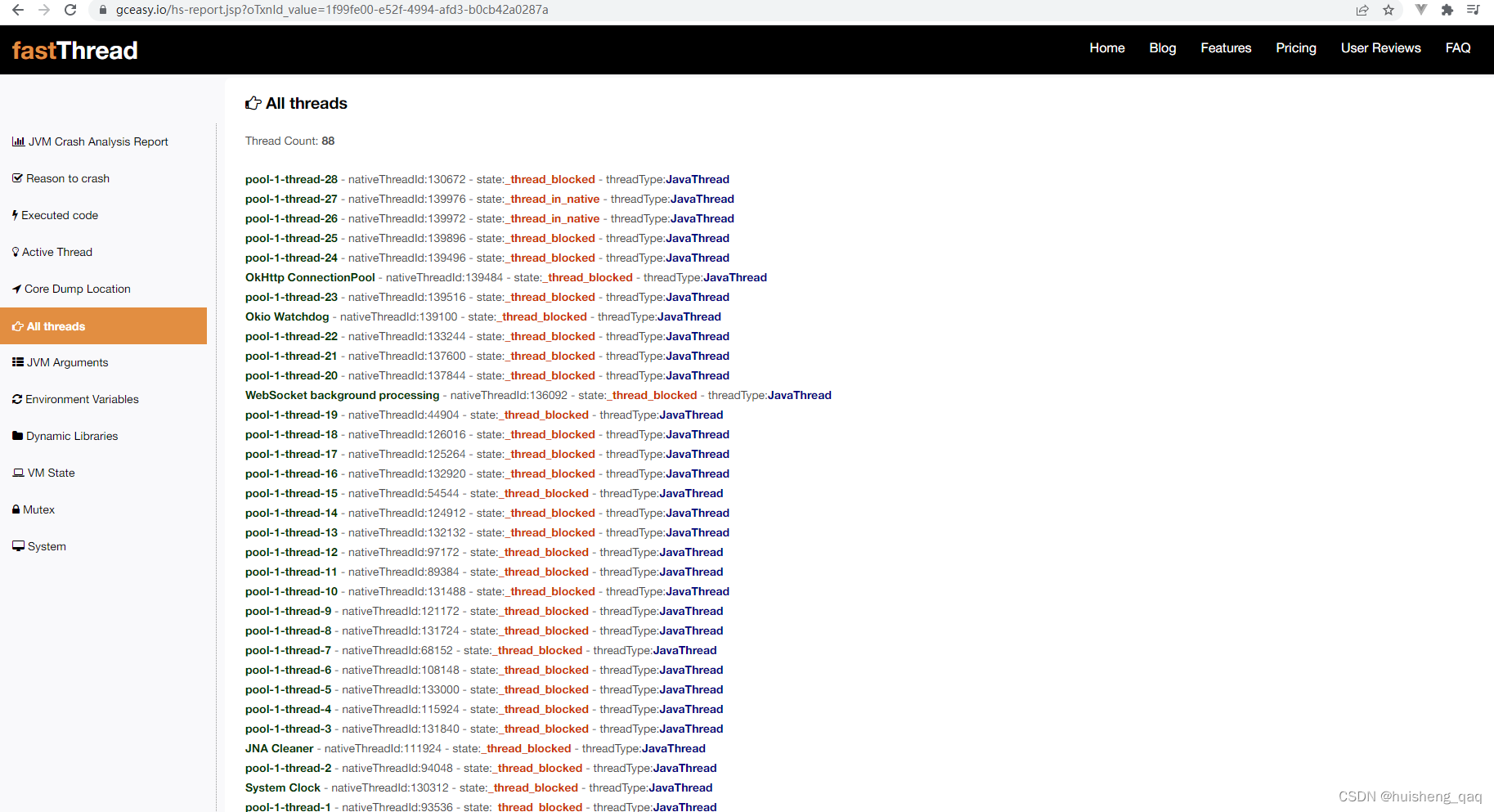
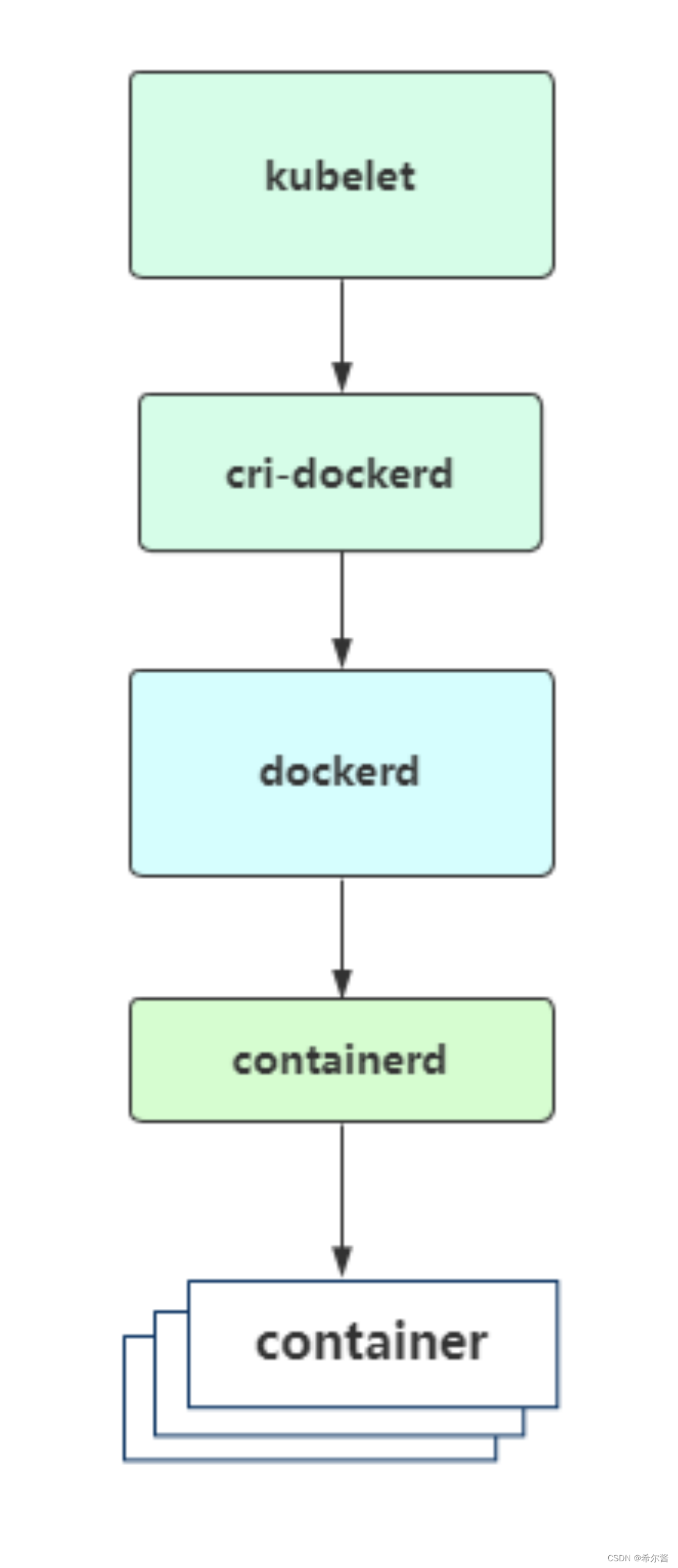
一、SQL语句的分类(任何一条sql语句以分号结尾;SQL语句不区分大小写)
DQL(数据查询语言):查询语句,凡是select都是DQL。
DML(数据操作语言):insert、delete、update,对表当中的数据进行增删改。
DDL(数据定义语言):create、drop、alter,对表结构的增删改。
TCL(事务控制语言):commit提交事务,rollback回滚事务。
DCL(数据控制语言):grant授权,revoke撤销权限等。
二、MySQL命令(不是SQL语句)
MySQL指令在windows黑窗口(dos)中使用,注意要先设置好环境变量。
1.启动MySQL服务:net start mysql
2.登录:mysql -u<用户名,一般为root> -p<密码>
说明:登录成功会现实"mysql<“。
3.查看所有的数据库:show databases;
4.创建一个数据库(注意是MySQL命令,不是SQL语句):create database <数据库名>;
5.查询当前使用的数据库:select database();
6.删除数据库:drop database <数据库名>;
7.查看表结构:desc <表名>;

上图中表示表dept有三个字段,分别为DEPTNO、DNAME、LOC。
8.使用该数据库:use <数据库名>;
9.查看当前使用的数据库中有哪些表:show tables;
10.初始化数据:source <.sql文件的全目录>
例如:
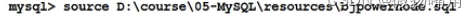
说明:.sql文件被称为"sql脚本”,是一种普通文本文件,该文件中编写了大量的sql语句。直接使用source命令可以执行sql脚本。sql脚本中的数据量太大的时候,无法打开,直接使用source命令完成初始化。
11.退出mysql:可使用\q、quit或exit。(不需要加分号)
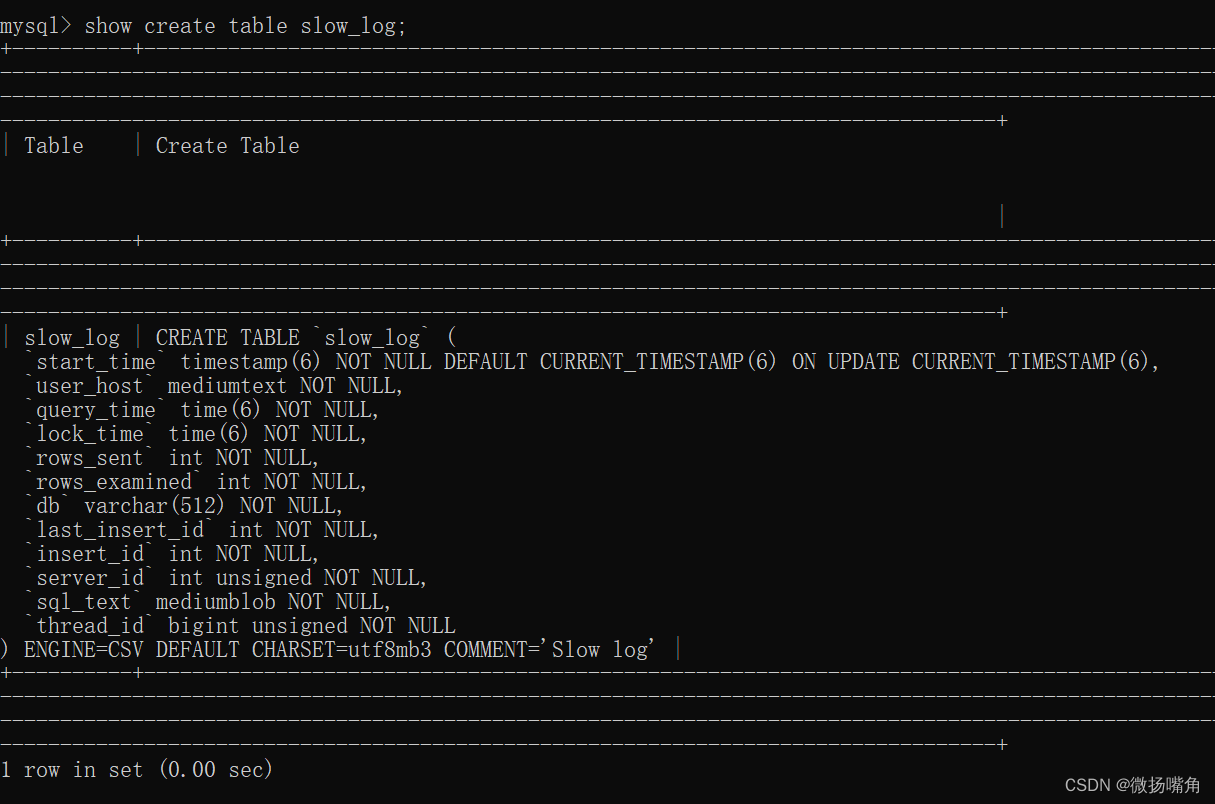
12.查看创建表的语句:show create table <表名>;
例如:
三、SQL查询语句
1.简单查询语句
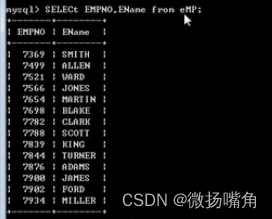
语法格式:select 字段名1,字段名2,字段名3,… from 表名;
例如:
再如:
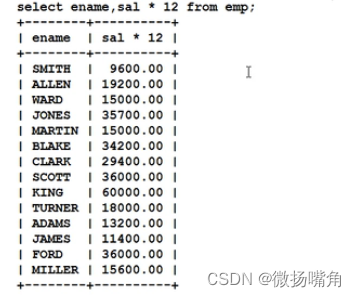
从上图中可以看出,select语句中的字段可以参与数学运算。
注意:在sql语句中的数学运算中如果有一个或多个字段数值为null,则数学运算结果为null。
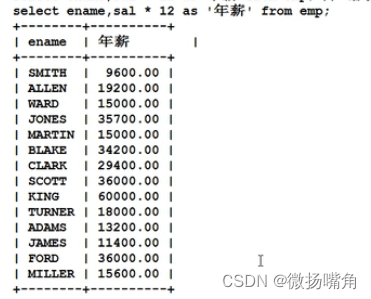
此外,可以给使用了数学运算的字段重命名,使用"as <别名>",as关键字可以省略:
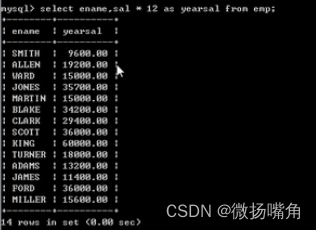
若是使用了中文命名字段可以用单引号括起来:
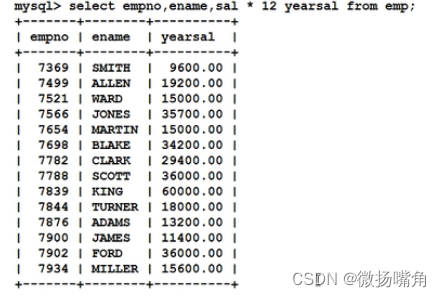
省略as关键字:
2.条件查询语句
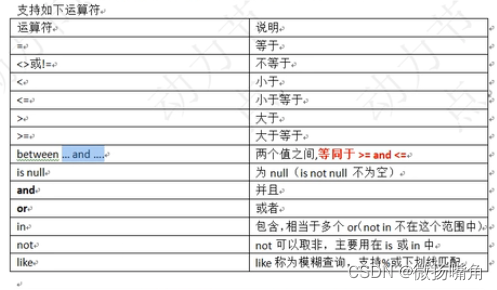
语法格式:select 字段,字段,… from 表名 where 条件;
执行顺序:先from,后where,最后select。
示例一:


注意:ename的属性字段类型为varchar,在sql语句中值需要使用单引号括起来。

注意:between…and…一定是小数据在前,大数据在后。
补充:where中and的优先级大于or。如果运算符的优先级不确定可以在sql语句中加小括号。
示例二(and与or 的优先级):

示例三(条件查询in):

注意:也可以使用“not in”。
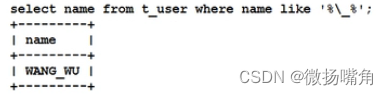
示例四(模糊查询like):
在模糊查询中,必须掌握两个特殊的符号,一个是%,一个是 (下划线)。%代表任意多个字符,(下划线)代表任意1个字符。

如果需要有下划线字符,使用转义字符:
3.排序(升序、降序)
先执行from,再执行where,再执行select,最后执行order by。

注意:多个字段同时排序时,从左到右考虑(越靠前的字段越起主导作用),只有前面的字段相同时才接着考虑后面的字段。

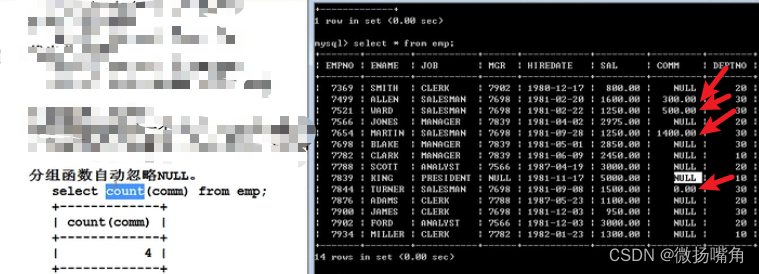
4.分组函数
分组函数的特点为输入多行,输出的结果为1行,即分组函数是多行处理函数(相对于单行处理函数而言)。


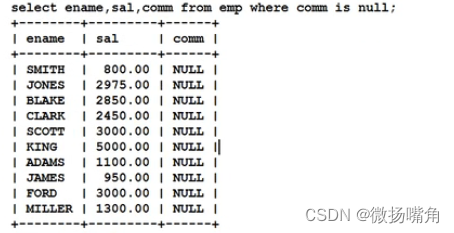
注意:分组函数自动忽略null,即分组函数中指定的字段为null的记录不会被处理。
单行处理函数,示例ifnull()函数。例如:
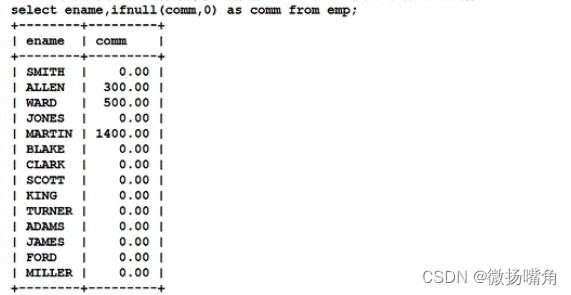
上例中,若comm的值为null则用0代替。
注意:SQL语句中分组函数不可以直接出现在where子句中(原因介绍了group by后解释)。
例如:

上图中的正确写法(子查询后序文章说明):

补充:count(*)与count(<字段名>)的区别为前者为统计的记录总数,后者为统计的指定字段不为null的记录个数。
5.group by和having
注意:先from,再group by,最后select。
group by:按照某个字段或某些字段进行分组。
having:having是对分组之后的数据进行再次过滤。

补充:分组函数一般会和group by联合使用,并且任何一个分组函数都是在group by语句执行结束之后才会执行的。当没有group by时,整张表的数据会自成一组。
解释:分组函数不能直接在where子句中是因为group by在where子句之后执行,而分组函数在group by子句之后执行。
再例:

但下述代码有问题:

注意:使用了group by语句后,select后只允许出现参加分组的字段和分组函数。
上图中的sql语句在oracle中会报错,但是在mysql中不会报错(oracle语法严谨,mysql语法松散)。虽然mysql语句不会报错,但是select后返回的ename是随机的,无意义。
补充:多个字段联合分组
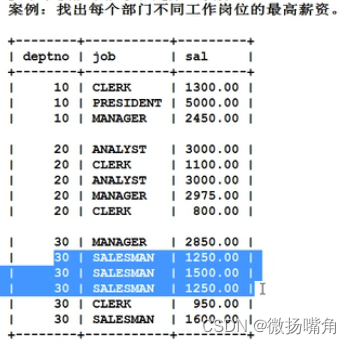
要求是相同部门、相同工作岗位为一组,所以分组需考虑两个字段,sql语句如下:

having字段的使用
示例:

其实上述sql语句也可以写成如下形式,且执行效率更高:

因为最大值也可以在where时就进行过滤。但如果是找出“每个部门的平均薪资大于2000”就不能使用where进行过滤,必须使用having子句进行过滤:
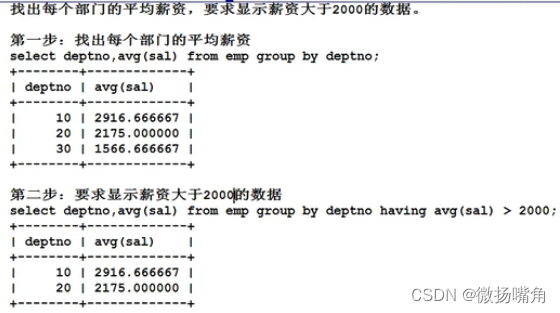
group by和having的区别:
where子句是作用在from子句中执行结果的多个记录上,没有from子句就不能有where子句。having子句是作用在group by子句的执行结果的多个记录上,没有group by子句就不能有having子句。
6.去除重复记录
在select 与字段序列中间加一个distinct关键字即可:
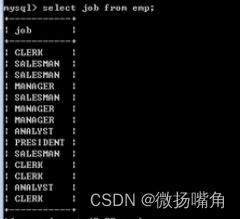

再例:

总结:select子句的执行顺序。
语法格式:
select 字段名1 [别名1],字段名2 [别名1],…
from 表名
where …
group by …
having …
order by …
执行顺序为:先from,再where,再group by,再having,再select,最后order by输出。