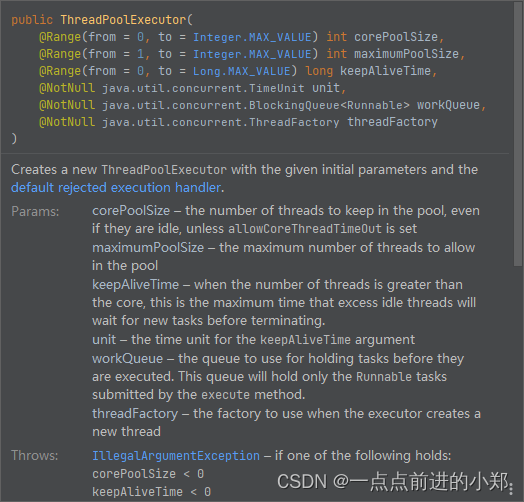
机器学习是一门研究如何让计算机从数据中学习和推理的科学。机器学习算法是实现机器学习的具体方法,它们可以根据不同的目标、数据类型和应用场景进行分类和比较。本文将介绍机器学习算法的基本概念、分类和评价标准,以及一些常用的机器学习算法的原理和特点。

机器学习算法的基本概念
机器学习算法可以看作是一种从输入到输出的映射函数,它可以根据给定的数据集(训练集)来调整自身的参数,使得输出能够尽可能地符合预期的结果(标签或目标函数)。机器学习算法的核心问题是如何找到最优的参数,以及如何评估参数的好坏。
为了解决这些问题,机器学习算法通常需要以下几个要素:
- 模型:模型是机器学习算法的数学表达式,它定义了输入和输出之间的关系,以及参数的含义和范围。模型可以是线性的、非线性的、概率的、确定性的等等,不同的模型有不同的复杂度和适用性。
- 目标函数:目标函数是机器学习算法的优化目标,它衡量了模型输出和预期结果之间的差距,也称为损失函数或代价函数。目标函数可以是平方误差、交叉熵、对数似然等等,不同的目标函数有不同的性质和优缺点。
- 优化算法:优化算法是机器学习算法的求解方法,它通过迭代更新参数来最小化或最大化目标函数,也称为学习算法或训练算法。优化算法可以是梯度下降、牛顿法、随机梯度下降等等,不同的优化算法有不同的收敛速度和稳定性。
- 超参数:超参数是机器学习算法中需要人为设定的参数,它们影响了模型的结构、复杂度和泛化能力,也称为调节参数或元参数。超参数可以是学习率、正则化系数、隐藏层个数等等,不同的超参数有不同的敏感度和范围。
机器学习算法的分类
机器学习算法可以根据不同的标准进行分类,其中最常见的是根据学习方式和任务类型进行分类。

根据学习方式分类
根据学习方式,机器学习算法可以分为以下三类:
- 监督学习:监督学习是指给定输入和输出之间存在明确的对应关系,也就是说,每个输入都有一个正确的或期望的输出。监督学习的目标是让模型能够从训练集中学习到这种对应关系,并能够泛化到未知的输入上。监督学习的典型应用有分类、回归、序列标注等。
- 无监督学习:无监督学习是指给定输入之间不存在明确的对应关系,也就是说,没有预先定义好的输出或标签。无监督学习的目标是让模型能够从训练集中发现输入数据的内在结构或规律,并能够对未知的输入进行合理的处理。无监督学习的典型应用有聚类、降维、生成等。
- 强化学习:强化学习是指给定输入和输出之间存在动态的交互关系,也就是说,每个输入都会产生一个反馈或奖励。强化学习的目标是让模型能够从训练集中学习到如何根据当前的状态选择最优的行为,并能够最大化累积的奖励。强化学习的典型应用有控制、游戏、导航等。
根据任务类型分类
根据任务类型,机器学习算法可以分为以下四类:
- 分类:分类是指将输入数据分配到预先定义好的类别中,也就是说,输出是离散的或有限的。分类可以是二分类(只有两个类别)或多分类(有多个类别)。分类的典型应用有垃圾邮件检测、人脸识别、情感分析等。
- 回归:回归是指预测输入数据的连续值或实数值,也就是说,输出是连续的或无限的。回归可以是线性回归(输出和输入之间存在线性关系)或非线性回归(输出和输入之间存在非线性关系)。回归的典型应用有房价预测、股票预测、年龄估计等。
- 聚类:聚类是指将输入数据分组到没有预先定义好的类别中,也就是说,输出是未知的或无标签的。聚类可以是硬聚类(每个数据只属于一个类别)或软聚类(每个数据可以属于多个类别)。聚类的典型应用有客户分群、图像分割、社交网络分析等。
- 生成:生成是指根据输入数据产生新的数据,也就是说,输出是新颖的或创造性的。生成可以是条件生成(根据给定的条件生成数据)或无条件生成(不需要任何条件生成数据)。生成的典型应用有图像生成、文本生成、语音合成等。
机器学习算法的评价标准
机器学习算法的评价标准是指用来衡量机器学习算法的性能和效果的指标,它们可以从不同的角度和层面进行分析和比较。机器学习算法的评价标准可以分为以下三类:
- 准确性:准确性是指机器学习算法的输出和预期结果之间的一致程度,也就是说,模型能够正确地完成任务的能力。准确性可以用不同的指标来衡量,例如准确率、召回率、F1值、均方误差等等,不同的指标有不同的含义和适用场景。
- 速度:速度是指机器学习算法的运行时间或效率,也就是说,模型能够快速地完成任务的能力。速度可以用不同的指标来衡量,例如训练时间、预测时间、复杂度等等,不同的指标有不同的计算方法和影响因素。
- 泛化性:泛化性是指机器学习算法的适应性或稳定性,也就是说,模型能够在未知或变化的数据上保持良好的性能的能力。泛化性可以用不同的指标来衡量,例如过拟合、欠拟合、偏差、方差等等,不同的指标有不同的原因和解决方法。
机器学习算法的评价标准通常需要根据具体的任务和数据来选择和调整,以达到最佳的效果。一般来说,机器学习算法需要在准确性、速度和泛化性之间进行权衡和平衡,以避免出现过高或过低的情况。
机器学习算法的常用例子
机器学习算法有很多种类和变体,不可能在本文中一一介绍。下面,我们将举一些常用的机器学习算法的例子,简要介绍它们的原理和特点。
- 线性回归:线性回归是一种最简单的监督学习算法,它假设输出和输入之间存在线性关系,也就是说,模型是一个线性函数。线性回归的目标函数是最小化平方误差,也就是让模型输出和真实值之间的差值的平方和最小。线性回归的优化算法可以是最小二乘法、梯度下降法等等。线性回归的优点是简单易懂,计算效率高,缺点是不能处理非线性关系,容易受到异常值和多重共线性的影响。
- 逻辑回归:逻辑回归是一种常用的监督学习算法,它用于解决二分类问题,也就是说,输出是0或1。逻辑回归将线性回归的输出通过一个非线性函数(如Sigmoid函数)映射到0到1之间,也就是说,模型是一个概率函数。逻辑回归的目标函数是最大化对数似然,也就是让模型输出和真实值之间的对数概率之和最大。逻辑回归的优化算法可以是梯度下降法、牛顿法等等。逻辑回归的优点是易于实现和解释,能够给出概率估计,缺点是不能处理多分类问题,容易受到数据不平衡和过拟合的影响。
- 支持向量机:支持向量机是一种强大的监督学习算法,它用于解决分类和回归问题,也就是说,输出可以是离散的或连续的。支持向量机的核心思想是找到一个超平面(或超曲面),使得不同类别的数据之间有最大的间隔,也就是说,模型是一个判别函数。支持向量机的目标函数是最小化结构风险,也就是让模型输出和真实值之间的误差最小,并加上一个正则化项来控制模型复杂度。支持向量机的优化算法可以是序列最小优化法、核技巧等等。支持向量机的优点是具有良好的泛化能力,能够处理高维和非线性数据,缺点是计算复杂度高,需要调节多个超参数。
- K-均值聚类:K-均值聚类是一种最常用的无监督学习算法,它用于解决聚类问题,也就是说,输出是未知的或无标签的。K-均值聚类的核心思想是将数据划分为K个簇(或类别),使得每个簇内部的数据相似度高,而不同簇之间的数据相似度低,也就是说,模型是一个划分函数。K-均值聚类的目标函数是最小化簇内平方误差,也就是让每个数据点和其所属簇的中心点(或质心)之间的距离的平方和最小。K-均值聚类的优化算法是一种贪心算法,它通过随机初始化K个中心点,然后交替地进行两个步骤:第一步是将每个数据点分配到距离它最近的中心点所属的簇中;第二步是重新计算每个簇的中心点,直到收敛或达到最大迭代次数。K-均值聚类的优点是简单易实现,能够快速收敛,缺点是需要预先指定K的值,容易受到初始中心点和异常值的影响。
- 生成对抗网络:生成对抗网络是一种新颖的无监督学习算法,它用于解决生成问题,也就是说,输出是新颖的或创造性的。生成对抗网络的核心思想是构建两个相互竞争的神经网络:一个是生成器(Generator),它负责根据随机噪声生成数据;另一个是判别器(Discriminator),它负责判断输入数据是真实的还是生成的。生成对抗网络的目标函数是最大化生成器和判别器之间的对抗损失,也就是让生成器能够欺骗判别器,而让判别器能够识别出真假数据。生成对抗网络的优化算法可以是随机梯度下降法、Adam等等。生成对抗网络的优点是能够生成高质量和多样性的数据,缺点是训练过程不稳定,容易出现模式崩溃和梯度消失等问题。
机器学习算法的总结和展望
机器学习算法是一门涉及多个领域和方面的综合性科学,它有着广泛的应用和前景。本文介绍了机器学习算法的基本概念、分类和评价标准,以及一些常用的机器学习算法的原理和特点。当然,这些内容只是机器学习算法的冰山一角,还有很多更深入和更复杂的知识和技术没有涉及到。如果你对机器学习算法感兴趣,你可以通过阅读相关的书籍、论文、博客等资源来进一步学习和探索。
机器学习算法是一个不断发展和变化的领域,它面临着许多挑战和机遇。随着数据量的增加、计算能力的提升、理论的完善、应用的拓展,机器学习算法将会有更多的创新和突破,也将会带来更多的价值和影响。我们期待着机器学习算法能够在未来为人类社会带来更多的便利和福祉。