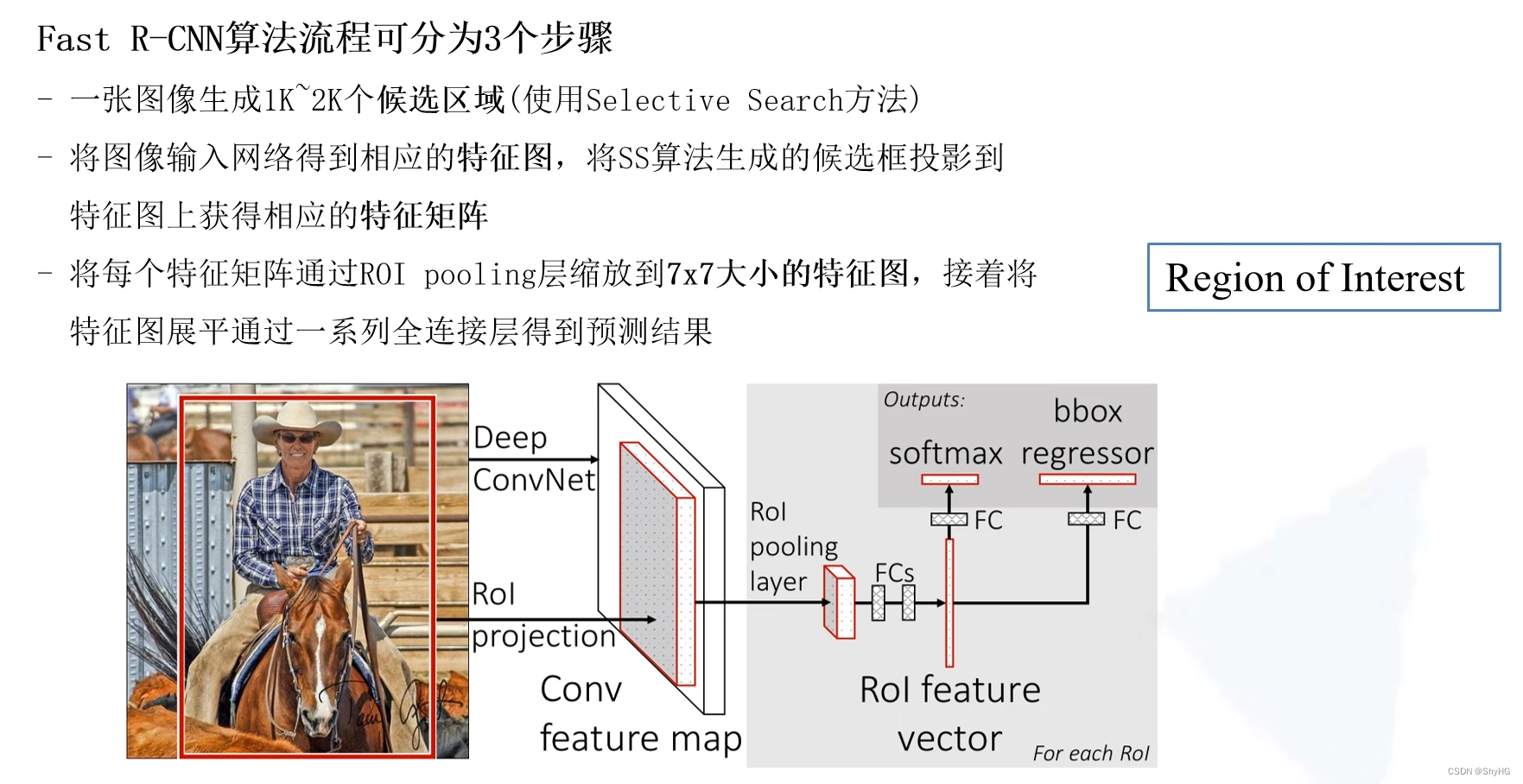
- RCNN的CNN部分使用AlexNet作为backbone来提取特征,Fast RCNN使用了VGG16来作为backbone
- RCNN将2000个框送入网络提取特征,Fast RCNN是将图像送入CNN来提取特征得到一个特征图
- 将SS(Selective Search)算法获取的提议框映射到上面的特征图上,获取相应的每个框的特征
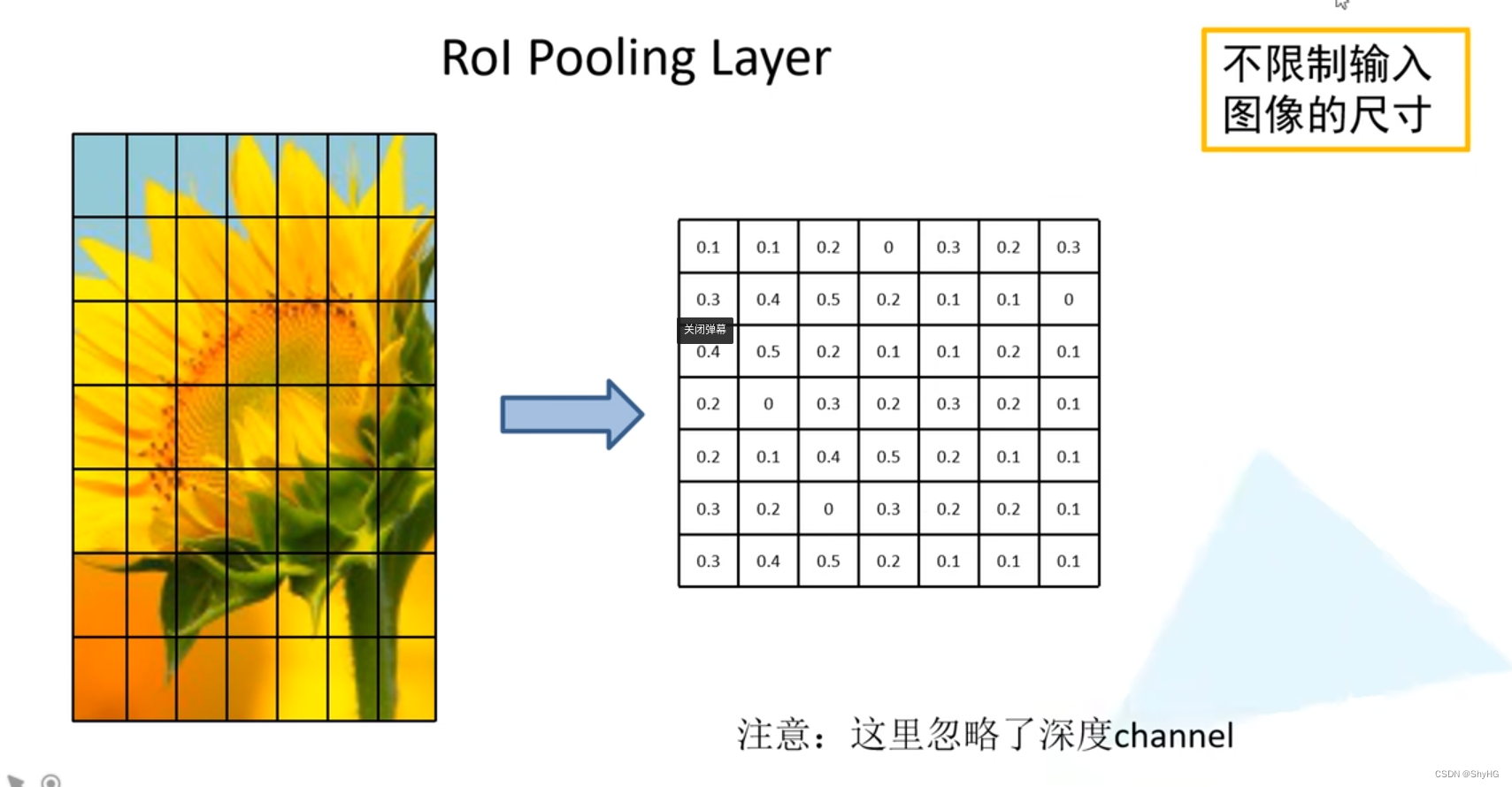
- 将每个框的特征图使用ROI pooling进行缩放,固定到统一的尺寸
- RCNN在获取结果的时候使用育训练的SVM分类器,而这里直接根据特征输出类别信息
- 样本策略:并不是完全使用SS算法提供的2000个框来提取特征,而是根据策略进行采样,这样一方面保证正负样本平衡另一方面减少计算量

- ROI Pooling:这里首先将特征图划分成7*7的大小,然后对每一个单元运用最大池化采样,最后输出特征图的尺寸为7*7,这种方法支持不同尺寸的输入,而不需要固定的尺寸
-
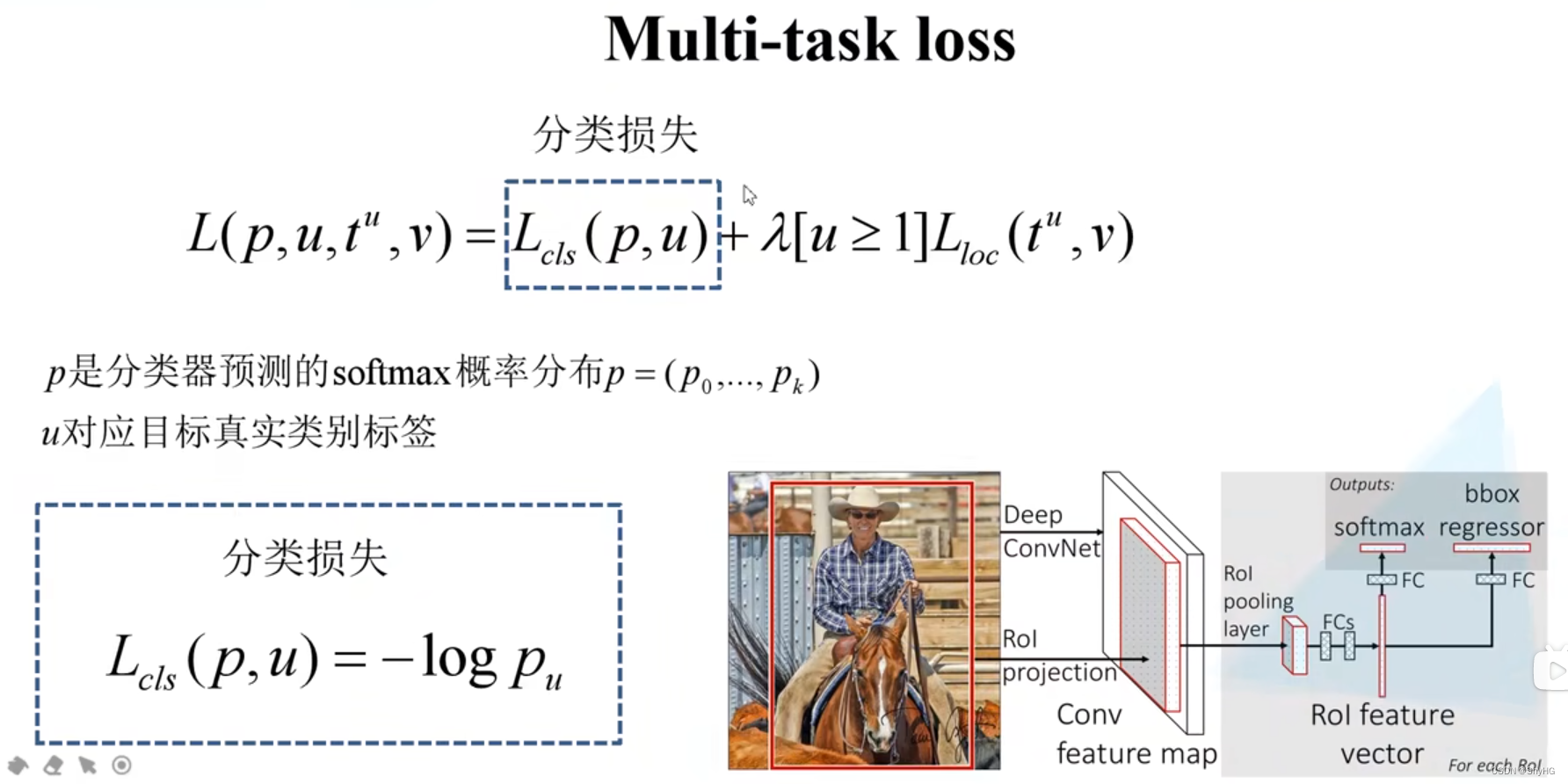
获取完特征之后便开始分类,这里的输出size为N+1,这里的输出经过softmax处理(和为1)
-
分类器:

-
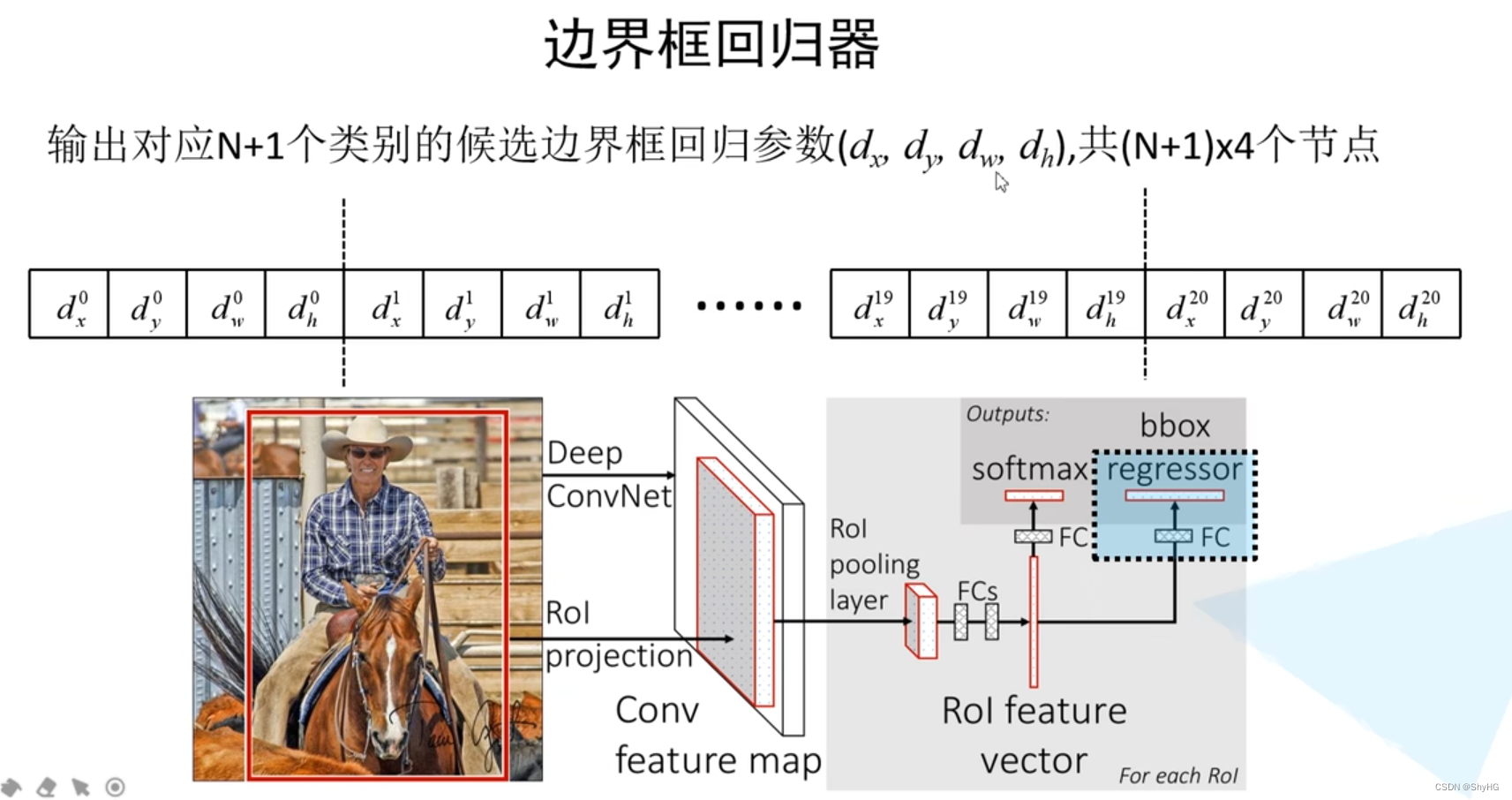
回归器:
-
基于回归器对先验框做调整,注意网络的输出,用网络的输出来调整先验框的值(这个和后边YOLO系列的等anchor based方法都基本一致)
-
这里为什么宽高是基于指数e的,一种可能的解释是 d x , d y d_x,d_y dx,dy可能是负值,为了保证最终的宽高都为正值?我觉得不太对,具体原因尚未可知,或许就是简单的一种范式吧,反正可以学习可以调整,形式不重要,哈哈哈。

-
损失计算,分类损失,就是log损失,也就是softmax交叉熵损失
-
知识点回顾
-
如果采用onehot编码,最终的多分类交叉熵的计算方式就是 l o g ( x ) log(x) log(x),注意,只有标签是采用onehot编码表示的,概率输出还是原始softmax的结果
onehot:[0,0,...,1,.....0] sofmax:[0.1,0.3,...,0.4,...0.1] 那么Loss=-log(0.4)

- 损失计算,边界框回归损失
- 注意这里的
v
x
v_x
vx几个数字并不是标注结果,
t
x
u
t^u_x
txu也不是输出的坐标或者宽高,他们都是中间值,经过计算才到最终的结果,标签的计算方式是通过标注结果反推,预测的结果直接由网络输出
v x ( g t ) = G x ^ − P x P w v_x(gt) = \frac{\hat{G_x} - P_x}{P_w} vx(gt)=PwGx^−Px - 这里有个
[
u
≥
1
]
[u\geq\;1]
[u≥1],含义是正样本+指示函数,只有正样本的时候才是1,这部分才参与计算损失函数
 - 速度瓶颈在SS算法上,后面的CNN模块还是挺快的,所以Faster RCNN就重点来解决这个问题咯
- 速度瓶颈在SS算法上,后面的CNN模块还是挺快的,所以Faster RCNN就重点来解决这个问题咯