文章目录
- 前言
- 一、PyPDF2库是什么?
- 二、安装PyPDF2库
- 三、查看PyPDF2库版本
- 四、使用方法
- 1.引入库
- 2.定义pdf路径
- 3.打开PDF文件
- 4.创建PDF阅读器对象
- 5.获取PDF文件中的页数
- 6.遍历每一页
- 7.获取当前页内容
- 8.提取当前页文本
- 9.打印当前页文本
- 10.效果
- 总结
前言
一、PyPDF2库是什么?
PyPDF2是一个用于处理PDF文件的Python库,它提供了许多用于读取和操作PDF文件的功能。它可以对PDF文件进行合并、分割、旋转、提取页面、加密和解密等操作,也可以添加文本、图像和水印等元素到PDF文件中。
PyPDF2库允许开发人员通过Python代码轻松地处理PDF文件,因为它提供了一些简单易用的接口,同时它也非常灵活,可以根据需要进行自定义操作。对于需要处理PDF文件的Python应用程序,PyPDF2是一个非常实用的工具库。
二、安装PyPDF2库
pip install PyPDF2
三、查看PyPDF2库版本
pip show PyPDF2
Name: PyPDF2
Version: 3.0.1
Summary: A pure-python PDF library capable of splitting, merging, cropping, and transforming PDF files
Home-page:
Author:
Author-email: Mathieu Fenniak biziqe@mathieu.fenniak.net
License:
Requires: typing_extensions
Required-by:
四、使用方法
1.引入库
import PyPDF2
2.定义pdf路径
local = '/Users/kkstar/Downloads/'
3.打开PDF文件
with open(local+'demo.pdf', 'rb') as pdf_file:
4.创建PDF阅读器对象
pdf_reader = PyPDF2.PdfReader(pdf_file)
5.获取PDF文件中的页数
num_pages = len(pdf_reader.pages)
6.遍历每一页
for page_num in range(num_pages):
7.获取当前页内容
page = pdf_reader.pages[page_num]
8.提取当前页文本
page_text = page.extract_text()
9.打印当前页文本
print(page_text)
10.效果
大家好,我是空空star,这是第一页。
大家好,我是空空star,这是第二页。
大家好,我是空空star,这是第三页。
Process finished with exit code 0
总结
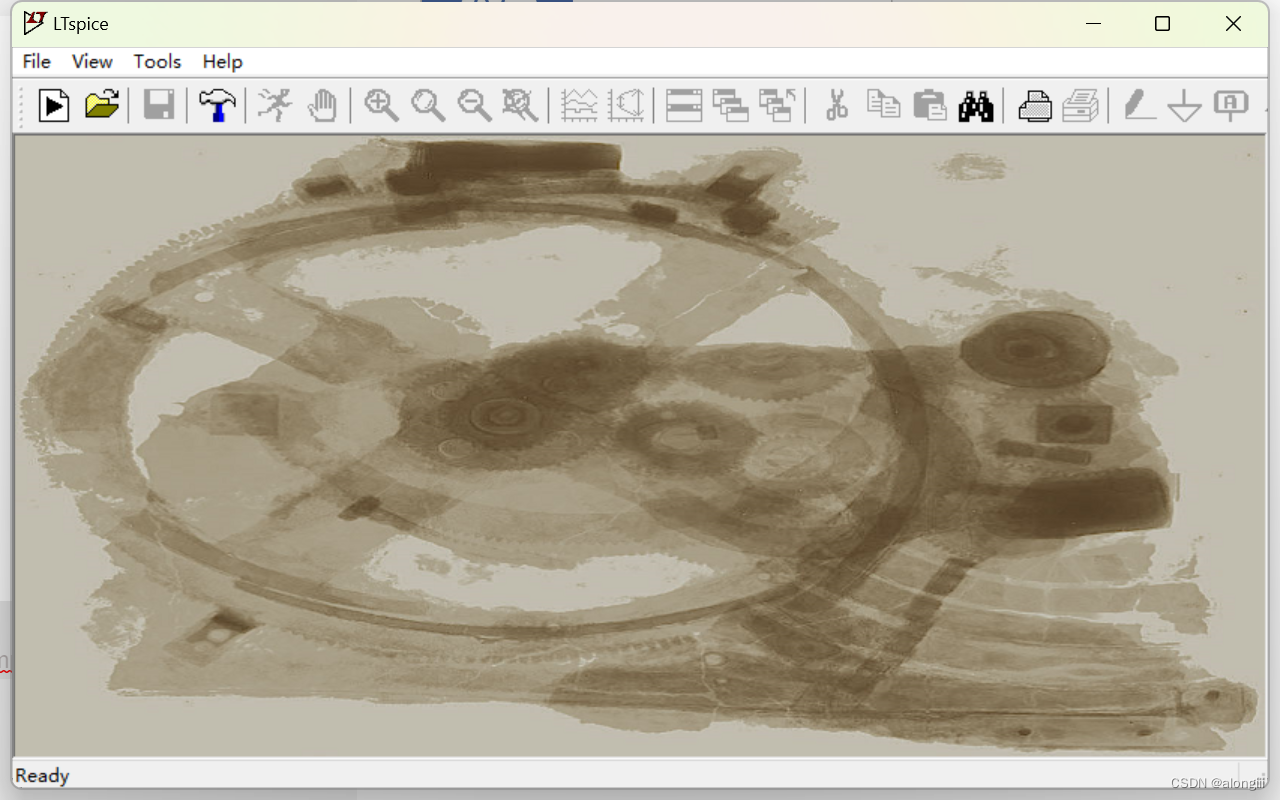
需要提取的pdf截图