MMDet3d样本均衡

文章目录
- MMDet3d样本均衡
- CBGSDataset
- 训练时数据是200帧,后面处理时,dataloader中数据变成了460帧,怎么均衡的?
- 思考
- 抽帧数计算
- 某个类别帧数为0
- Reference
- 欢迎关注公众号【三戒纪元】
CBGSDataset
**CBGS (Class-balanced Grouping and Sampling)**中的样本均衡策略
CBGS : 三维点云物体检测的类平衡分组和采样(新自动驾驶数据集nScenes第一名算法)
两种策略解决样本不均衡问题:
一、DS Sampling (作者提出)
基本思想是把占比较小的类别进行复制,制作出较大数据集,然后针对每个类别用固定比例random sample这个大的数据集,组合出最终数据集,最终数据集的类别密度(类别数量/样本总数)是相近的,这方法可以减缓样本不平均问题。
二、GT-AUG (SECOND引用)
把某一样本中的物体点云数据,放到另一个样本中,过程中需要计算摆放位置是否合理。(详见原文)
训练时数据是200帧,后面处理时,dataloader中数据变成了460帧,怎么均衡的?
mmdet3d中存储帧数据使用了class CBGSDataset做的样本均衡
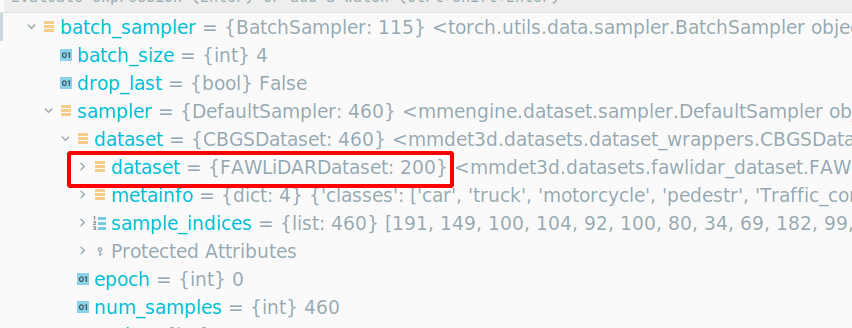
FAWLiDARDataset是200帧,包装到 CBGSDataset 是460帧,设置的batch_size = 4 ,因此迭代次数为
460
4
=
115
\frac{460}{4} = 115
4460=115,训练20轮,总共 $ 20 * 115 = 2300$ 次训练
具体得到 CBGSDataset 类里面看(/home/qiancj/anaconda3/envs/mmdet3d_env_py38/lib/python3.8/site-packages/mmengine/dataset/dataset_wrapper.py):
具体函数调用为:__init__ —> self.full_init() —> self.sample_indices = self._get_sample_indices(self.dataset)
其中,_get_sample_indices(self.dataset) 具体实现为:
def _get_sample_indices(self, dataset: BaseDataset) -> List[int]:
"""Load sample indices according to ann_file.
Args:
dataset (:obj:`BaseDataset`): The dataset.
Returns:
List[dict]: List of indices after class sampling.
"""
# 获取障碍物类别:['car', 'truck', 'motorcycle', 'pedestr', 'Traffic_cone']
classes = self.metainfo['classes']
# 建立 种类-id 字典:{'car': 0, 'truck': 1, 'motorcycle': 2, 'pedestr': 3, 'Traffic_cone': 4}
cat2id = {name: i for i, name in enumerate(classes)}
# 每个建立字典 cat_id:[], 每个id对应一个list
class_sample_idxs = {cat_id: [] for cat_id in cat2id.values()}
# 遍历 dataset 中每一帧
for idx in range(len(dataset)):
# 获取每一帧内包含的种类 id。如第0帧有car 和 truck, 获取到的sample_cat_ids 为{0,1}
sample_cat_ids = dataset.get_cat_ids(idx)
# 当前帧包含目标障碍物,则将帧号存入class_sample_idxs中
# class_sample_idxs 存储每个 类别id 所在的帧号列表
for cat_id in sample_cat_ids:
if cat_id != -1:
# Filter categories that do not need to be cared.
# -1 indicates dontcare in MMDet3D.
class_sample_idxs[cat_id].append(idx)
# 每个类别id 所在帧的总数
duplicated_samples = sum(
[len(v) for _, v in class_sample_idxs.items()])
# 每个类别id 对应帧数占总帧数的比例
class_distribution = {
k: len(v) / duplicated_samples
for k, v in class_sample_idxs.items()
}
# 样本帧序号
sample_indices = []
# 每个类别占总类别的比例,此处0.2
frac = 1.0 / len(classes)
# frac/每个类别所占帧数,帧数少的该值会变大
ratios = [frac / v for v in class_distribution.values()]
# 从每个类所在的帧里class_sample_idxs.values(),抽取int(len(cls_inds) *ratio) 帧
for cls_inds, ratio in zip(list(class_sample_idxs.values()), ratios):
sample_indices += np.random.choice(cls_inds,
int(len(cls_inds) *
ratio)).tolist()
return sample_indices
从代码可以看出来,先计算每个类别所存在的总帧数,然后计算每个类别占总帧数的比例,然后对每个类别所在的帧数进行随机抽帧,保证每个类别的抽帧数一致,也就是抽帧后每个类别所在的帧数是相同的,保证了样本的均衡性。
所以如果某个类别只存在3帧,为了达到和其他类别帧数匹配,就会在最终样本中复制多份这3帧数据,以实现样本均衡。
思考
抽帧数计算
这里计算感觉逻辑有点乱,又是计算 frac,ratios,又是计算抽帧数,不足抽帧数的就复制已有的帧。
手动推导了一遍公式,最终抽帧数可以简化为
抽帧数
=
总帧数
类别数量
=
d
u
p
l
i
c
a
t
e
d
_
s
a
m
p
l
e
s
l
e
n
(
c
l
a
s
s
e
s
)
抽帧数 = \frac{总帧数}{类别数量} \\ = \frac{duplicated\_samples}{len(classes)}
抽帧数=类别数量总帧数=len(classes)duplicated_samples
某个类别帧数为0
如果样本数比较少,有的类别帧数为0,即所有帧中都不包含该障碍物,当计算ratios时除数会为0
ratios = [frac / v for v in class_distribution.values()]
Reference
CBGS : 三维点云物体检测的类平衡分组和采样(新自动驾驶数据集nScenes第一名算法)