【大模型慢学】GPT起源以及GPT系列采用Decoder-only架构的原因探讨 - 知乎本文回顾GPT系列模型的起源论文并补充相关内容,中间主要篇幅分析讨论为何GPT系列从始至终选择采用Decoder-only架构。 本文首发于微信公众号,欢迎关注:AI推公式最近ChatGPT系列越来越火爆,不只在计算机圈内,其…![]() https://zhuanlan.zhihu.com/p/625184011为什么现在的LLM都是Decoder only的架构? - 知乎相比encoder-decoder架构,只使用decoder有什么好处吗?
https://zhuanlan.zhihu.com/p/625184011为什么现在的LLM都是Decoder only的架构? - 知乎相比encoder-decoder架构,只使用decoder有什么好处吗?![]() https://www.zhihu.com/question/588325646/answers/updatedGPT本质是文字接龙。
https://www.zhihu.com/question/588325646/answers/updatedGPT本质是文字接龙。

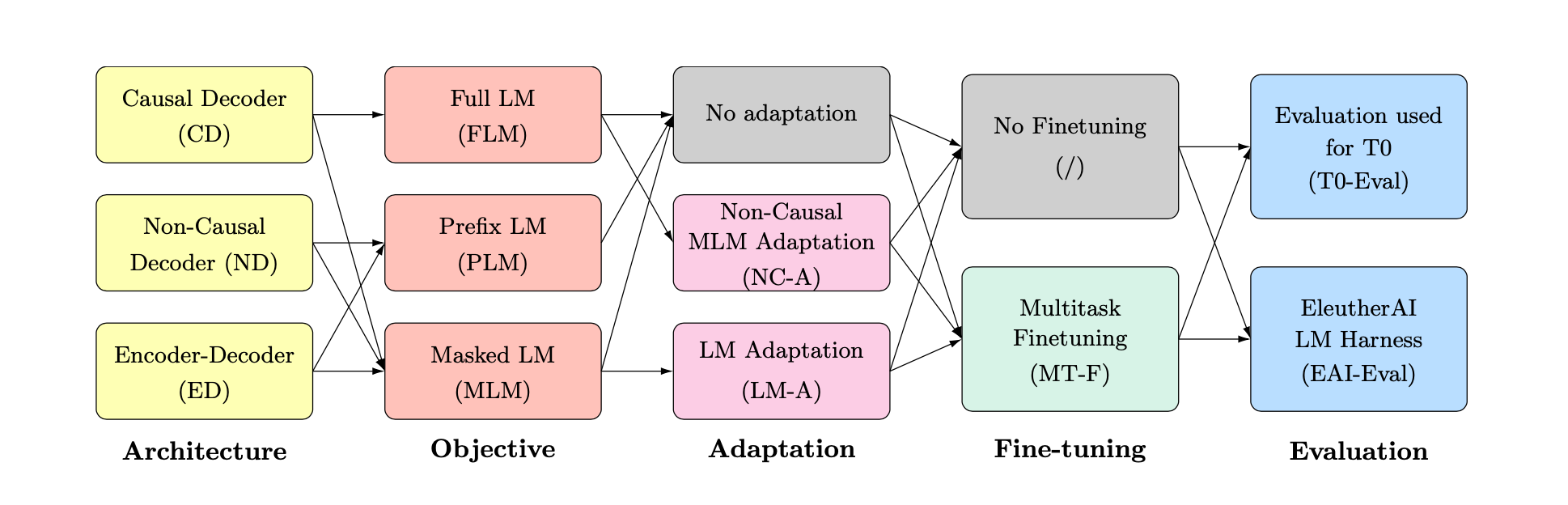
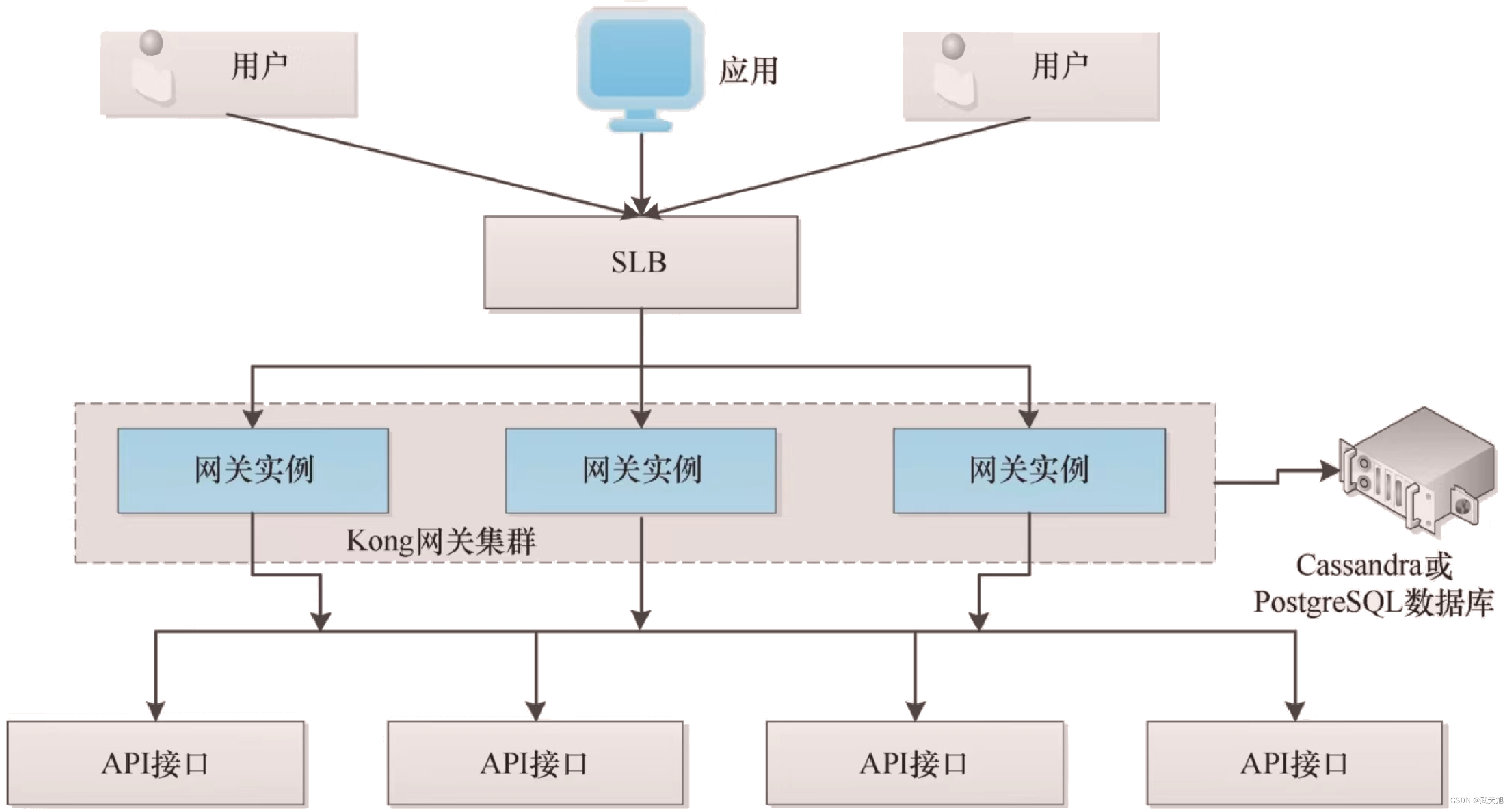
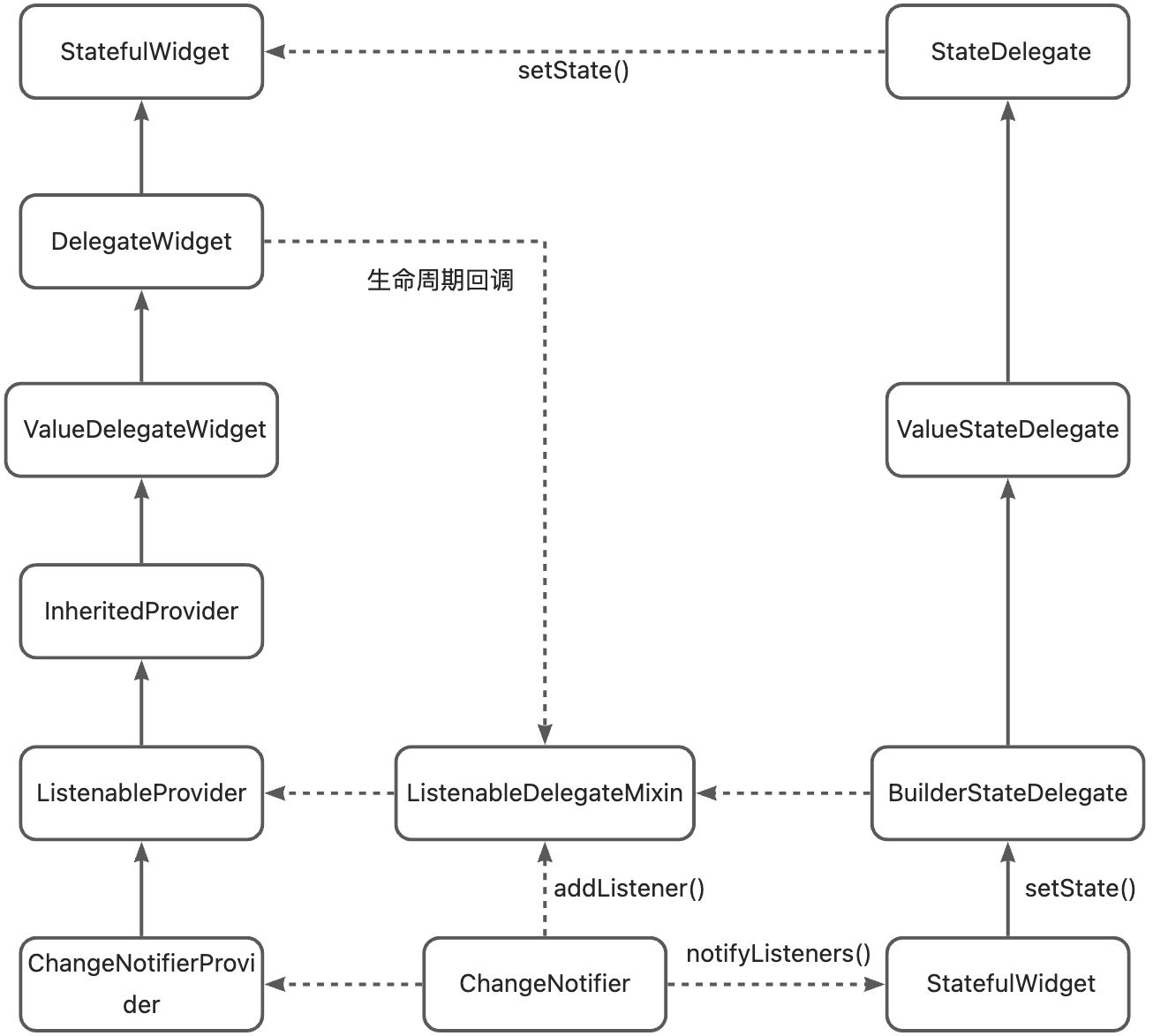
目前公认的大语言模型具有zero-shot泛化能力,但是大模型各种各样,从模型架构到预训练目标差异巨大,因此通过排列组合来做对比实验。上图就是模型架构、预训练目标、adaptation、multitask finetuning四个变量的排列组合。
训练LM的架构包括:
encoder-decoder,T5,ED。
decoder-only,GPT,主流是causal decoder,简称CD,只有前向注意力。
prefix LM:采样一段文本,然后选择一个随机点将其拆分为前缀和目标部分,前缀作为输入,目标作为输出。又叫non-causal decoder-only,简称ND,输入的前一部分是双向注意力,后一部分是单向注意力。
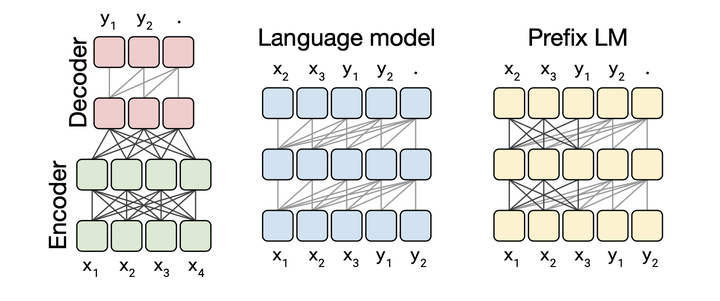

预训练目标:
full language modeling,FLM,完整的一段话从头到尾基于上文预测下一个token,GPT系列,和CD搭配。
prefix language modeling,PLM,一段话分成两部分,前一部分作为输入,预测后一部分,和ED,ND搭配。
masked language modeling,MLM,训练bert时的完形填空,遮盖住文本中一部分token,让模型通过上下文猜测遮盖部分的token,可以像T5一样将任务改造成text2text形式,input和target都是一段文本,可以适配ND和ED,如果将input和target拼接起来,就可以适配CD。

adaptation:
对大模型进行改造,比如T5的预训练目标是MLM,不是一个很好的生成模型,把目标改成PLM或FLM,继续训练,和微调不同,再次训练用的数据不是下游数据,而是额外的无监督文本数据。FLM预训练的CD模型,通过切换掩码变成ND模型,在通过MLM目标改造,可以用于完形填空,前者交language modeling adaptation(LM-A),后者称为non-causal MLM adaptation(NC-A)。
multitask finetuning:
多任务微调,在一百多个已知任务的prompt数据做微调,能极大提升预训练模型在未知任务上的zero-shot能力。
结论:
1.如果大模型只做无监督预训练,CD+FLM的zero-shot效果最佳。
2.无监督预训练+multitask finetuning,ED+MLM效果最佳。
3.CD+FLM获得最佳语言模型,进过ND MLM adaptation,再通过multitask,效果最佳。
为什么只用decoder-only?
苏建林:理论上encoder的双向注意力会存在低秩,带来表达能力下降,decoder-only的attention是满秩的,encoder-decoder在某些场景更好,大概只是因为其多了一倍参数。