论文信息
name_en: Speak Foreign Languages with Your Own Voice: Cross-Lingual Neural Codec Language Modeling
name_ch: 用你自己的声音说外语:跨语言神经编解码器语言建模
paper_addr: http://arxiv.org/abs/2303.03926
date_read: 2023-04-25
date_publish: 2023-03-07
tags: [‘深度学习’,‘语音合成’]
author: Ziqiang Zhang,Microsoft
code: https://github.com/microsoft/unilm
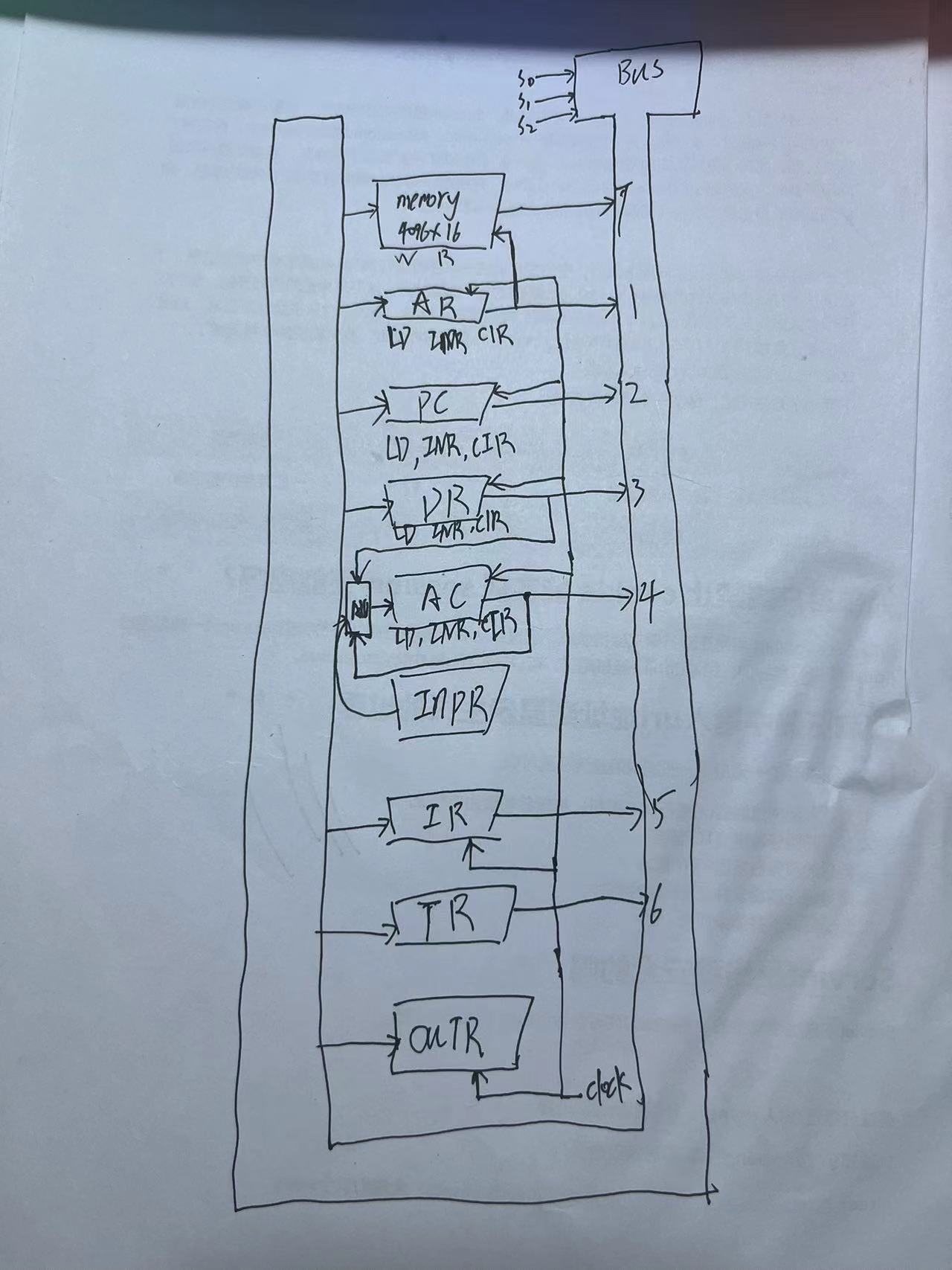
1 读后感
对 VALL-E 的扩展,以源语言语音和目标语言文本为提示,预测目标语言语音的声学标记序列,可用于从语音到语音的翻译任务。它可以生成目标语言的高质量语音,同时保留看不见的说话者的声音、情感和声学环境。有效缓解了外国口音问题,可以通过语言ID来控制。
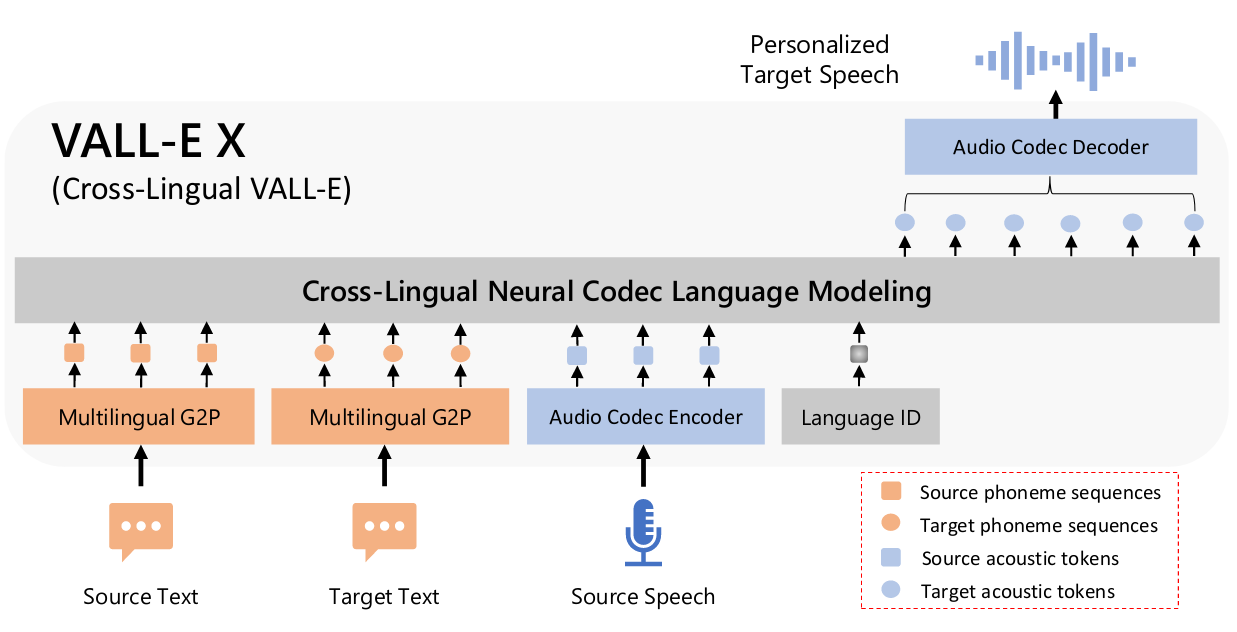
以从源文本和目标文本中导出的音素序列,以及从音频编解码器模型中导出的源声学标记作为提示,生成目标语音。

2 介绍
主要贡献
• 提出 VALL-E X 条件跨语言语言模型,以源语言语音和目标语言文本为提示,预测目标语言声学标记。
• 多语言上下文学习框架,能保持看不见的说话者的声音、情感和语音背景,仅依赖源语言中的一个句子提示。
• 显著减少外国口音问题,这是一个众所周知的跨语言问题。
• 将VALL-E X 应用于零样本跨语言文本到语音合成和零样本语音到语音翻译任务。在说话人相似度、语音质量、翻译质量、语音自然度和人类评估方面击败强基线。
3 方法
除了模型本身,结合使用 G2P Tool 将文本转换成音素,以及最后使用 Encodec 生成音频数据。
3.1 模型构架
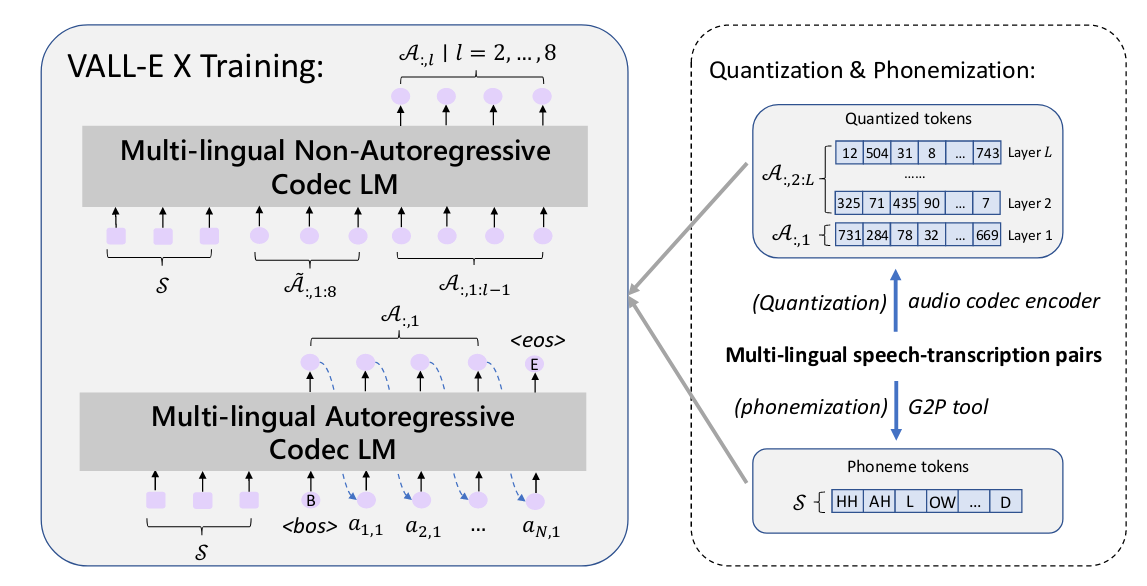
由一个自回归的多语音编码器和一个非自回归的编码器组成。
多语言声学标记 (A) 和音素序列 (S) 分别使用编码器和 G2P 工具从语音和转录中转换而来。在训练期间,使用来自不同语言的配对 S 和 A 来优化这两个模型。本文中语义标记指音素序列。
3.2 多语言训练
利用了双语语音转录 (ASR) 语料库,成对的 (Ss, As) 和 (St, At) 来训练多语言模型。
另外,利用语言 ID 来指导 VALL-E X 中特定语言的语音生成。因为是用多语言数据训练的,如果不指定ID,可能会混淆为特定语言选择合适的声学标记。例如汉语是声调语言,而英语是非声调语言。这在引导正确的说话风格和缓解口音问题方面出奇地有效,具体来说,将语言 ID 嵌入到密集向量中,并将它们添加到声学标记的嵌入中。
3.3 多语言推理
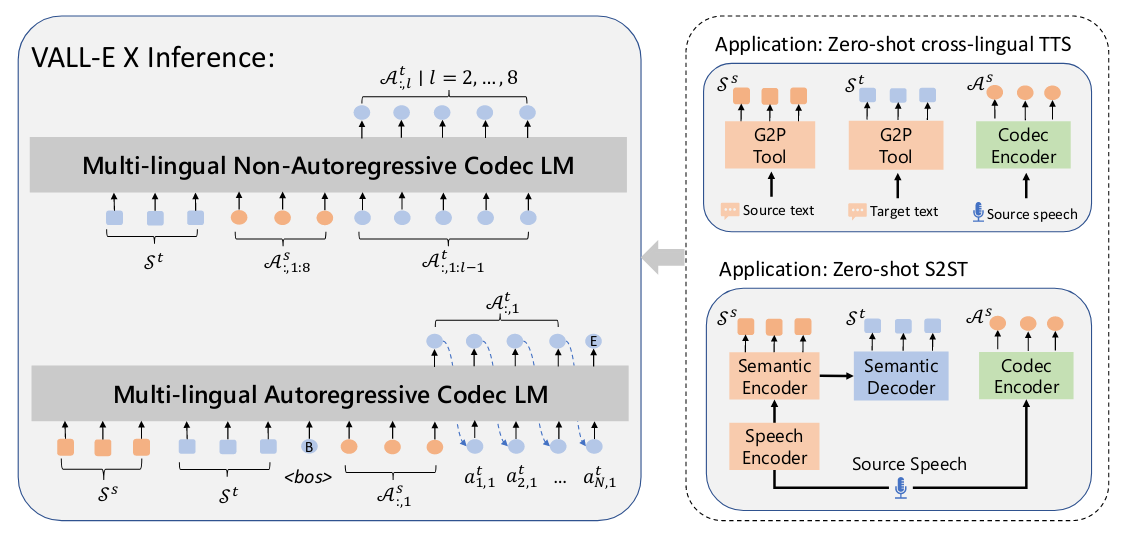
自回归和非自回归模型的输入不同;右侧显示了语音到语音翻译的过程。
给定源语音 Xs,语音识别和翻译模型首先从语义编码器生成源音素 Ss,从语义解码器生成目标音素 St。此外,使用 EnCodec 编码器将 X 压缩为源声学标记 As。然后,将 Ss、St 和 As 连接起来,作为 VALL-E X 的输入,以生成目标语音的声学标记序列。使用 EnCodec 的解码器将生成的声学标记转换为最终的目标语音。
4 相关知识
- SpeechUT: SpeechUT是一种跨模态预训练模型,用于将语音和文本连接起来。它使用隐藏单元作为接口来对齐语音和文本,并将语音编码器和文本解码器的表示与共享单元编码器连接起来。
- G2P Tool 把是 Grapheme-to-Phoneme 工具的缩写,是一种将单词的字素转换为音素的工具。它使用循环神经网络实现。




![[答疑]UML精粹里和你视频里说的不太一样](https://img-blog.csdnimg.cn/img_convert/3d2a599f693e61eb96599b288a040fc1.png)