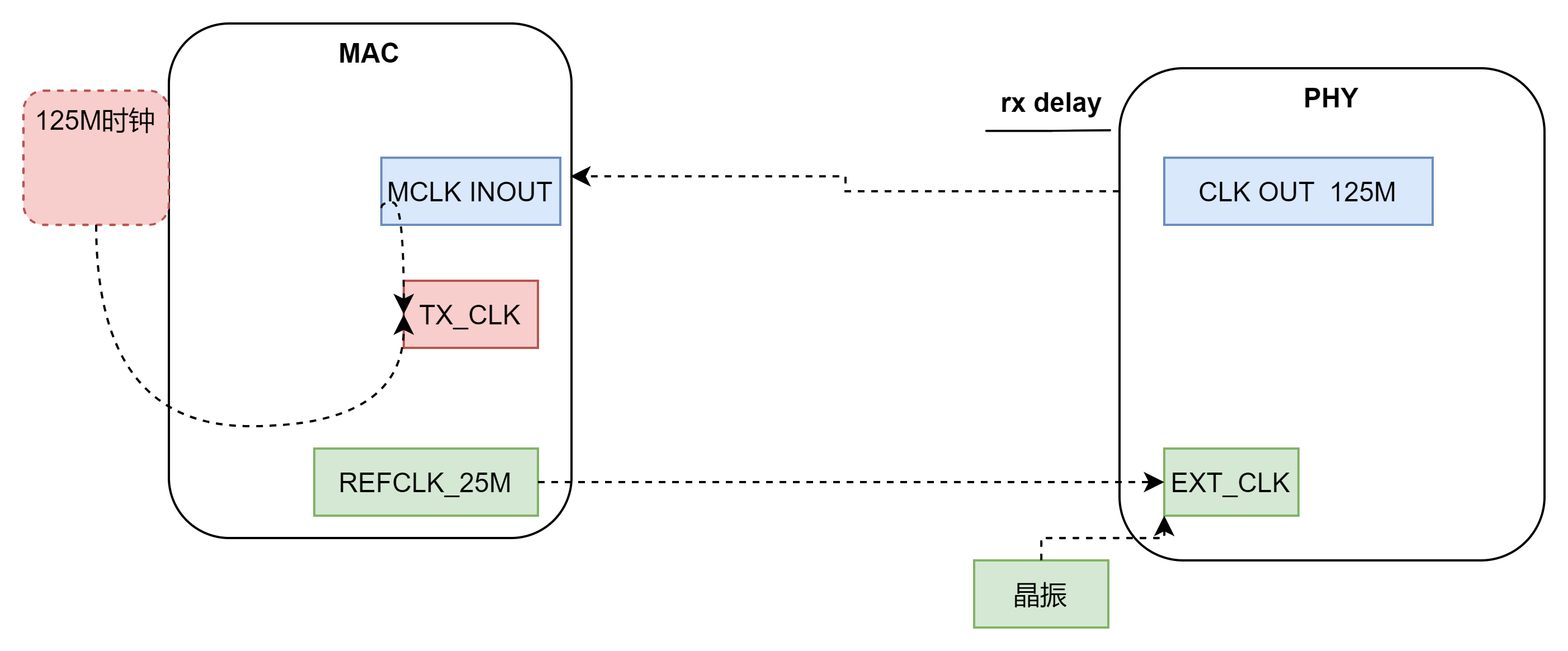
肺炎是一种由感染引起的严重呼吸道疾病,特别是在高危人群中,可能会出现危及生命的并发症。必须尽快诊断和治疗肺炎,以最大限度地提高患者康复的机会。
诊断过程并不容易,需要一些医学实验室工具和先进的医疗技能,但我们可以使用深度学习和计算机视觉来构建一个快速简便的工具,帮助医生检测肺炎。
我们可以使用称为OpenCV(https://opencv.org/)(开源计算机视觉)的开源计算机视觉和机器学习软件库创建用于图像和视频分析的应用程序,例如 X 射线结果。Open CV 是一个用于执行计算机视觉、机器学习和图像处理的开源库。
在本课中,我们将了解如何使用 OpenCV 识别胸部 X 光图像中的肺炎。
安装 OpenCV
安装 OpenCV 是初始阶段。根据你的操作系统,有多种安装 OpenCV 的方法。以下是一些受欢迎的选择:
Windows:在OpenCV (https://opencv.org/releases/) 主网站上使用预构建的二进制文件。
Linux:可以使用 Linux 发行版中包含的包管理器安装 OpenCV。在终端中运行以下指令,例如,在 Ubuntu 上:
Install libopencv-dev with sudo apt-getMac OS:可以使用 Homebrew 设置 OpenCV,应在终端中输入以下代码。
Brew install opencv加载 OpenCV 后,你可以使用以下 Python 代码检查它是否正常工作。
import cv2
print(cv2.__version__)如果正确安装了 OpenCV,你应该会在终端中看到版本号。
下载数据集
接下来可以下载将用于训练我们的肺炎检测算法的数据集。在本练习中,我们将使用来自 Kaggle 的胸部 X 光图片(肺炎)数据集。
数据集:https://www.kaggle.com/paultimothymooney/chest-xray-pneumonia
数据集中共有 5,856 张胸部 X 光图像,分为肺炎和正常两类。
你必须注册 Kaggle 帐户并同意数据集的条款才能获取数据集。完成后,在终端中键入以下命令以获取数据集:
kaggle datasets download -d paultimothymooney/chest-xray-pneumonia将下载包含信息的 ZIP 文件。在你的本地计算机上创建一个子文件夹并提取 ZIP 文件。
准备数据
然后必须为我们的肺炎识别模型的训练准备数据。为了从当前样本中创建更多训练样本,我们将采用一种称为数据增强的方法。
这样做是为了提高模型的性能并更快地构建模型。为了创建同一图片的不同版本,数据增强涉及对图像应用随机变换,例如旋转、缩放和翻转。
我们将制作两个目录来准备数据:一个用于训练图片,一个用于验证图像。80%的图片将用于训练,20%用于验证。
这是准备信息的代码:
import os
import shutil
import random
# Define the paths
input_dir = 'path/to/input/dir'
train_dir = 'path/to/train/dir'
val_dir = 'path/to/val/dir'
# Create the directories
os.makedirs(train_dir, exist_ok=True)
os.makedirs(val_dir, exist_ok=True)
# Get the list of images
image_paths = []
for root, dirs, files in os.walk(input_dir):
for file in files:
if file.endswith('.jpeg'):
image_paths.append(os.path.join(root, file))
# Shuffle the images
random.shuffle(image_paths)
# Split
split_idx = int(0.8 * len(image_paths))
train_image_paths = image_paths[:split_idx]
val_image_paths = image_paths[split_idx:]现在将图像复制到目录中。将“path/to/input/dir”更改为你在此代码中提取信息的目录路径。要分别保存训练和验证图像的目录的路径应替换为“path/to/train/dir”和“path/to/val/dir”。
努力跟踪和重现复杂的实验参数?工件是 Comet 工具箱中帮助简化模型管理的众多工具之一。
阅读我们的 PetCam 场景以了解更多信息:https://www.comet.com/site/blog/debugging-your-machine-learning-models-with-comet-artifacts/?utm_source=heartbeat&utm_medium=referral&utm_campaign=AMS_US_EN_AWA_heartbeat_CTA
训练模型
使用我们在前一阶段创建的训练图像,我们现在必须训练肺炎检测模型。我们模型的核心将是一个名为 VGG16 的预训练卷积神经网络 (CNN) 。
流行的 CNN 架构 VGG16 在经过大量图像数据集的训练后,在众多图像识别任务上取得了最先进的成功。
下面是训练模型的代码:
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense, GlobalAveragePooling2D
from tensorflow.keras.applications import VGG16
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# Define the input shape of the images
input_shape = (224, 224, 3)
# Load the VGG16 model
base_model = VGG16(weights='imagenet', include_top=False, input_shape=input_shape)
# Add a global average pooling layer
x = base_model.output
x = GlobalAveragePooling2D()(x)
# Add a fully connected layer
x = Dense(128, activation='relu')(x)
# Add the output layer
output = Dense(1, activation='sigmoid')(x)
# Define the model
model = Model(inputs=base_model.input, outputs=output)
# Freeze the layers of the VGG16 model
for layer in base_model.layers:
layer.trainable = False
# Compile the model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Define the data generators for training and validation
train_datagen = ImageDataGenerator(rescale=1./255,
rotation_range=10,
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.1,
zoom_range=0.1,
horizontal_flip=True,
fill_mode='nearest')
val_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(train_dir,
target_size=input_shape[:2],
batch_size=32,
class_mode='binary')
val_generator = val_datagen.flow_from_directory(val_dir,
target_size=input_shape[:2],
batch_size=32,
class_mode='binary')
# Train the model
model.fit(train_generator,
steps_per_epoch=len(train_generator),
epochs=10,
validation_data=val_generator,
validation_steps=len(val_generator))首先,我们将 ImageNet 数据集中的预训练权重加载到 VGG16 模型中。我们还包括一个具有 sigmoid 激活函数的输出层、一个具有 128 个神经元的完全连接层和一个全局平均池化层。VGG16 模型的层被冻结,使用 Adam 算法和二元交叉熵损失来构建模型。之后,我们指定用于训练和验证的数据生成器,以扩充数据并将像素值重新缩放到 [0, 1] 范围。
使用拟合方法以及训练和验证数据生成器,我们训练模型 10 个时期。
评估模型
为了确定模型在训练后对新数据的泛化能力如何,我们必须评估其在测试集上的表现。为了评估模型,我们将使用数据集的测试集。此外,我们将显示一些正确和错误分类图像的插图。
使用下面的代码评估模型并显示一些实例。
import numpy as np
import matplotlib.pyplot as plt
# Define the path to the test directory
test_dir = 'path/to/input/dir/chest_xray/test'
# Define the data generator for test
test_datagen = ImageDataGenerator(rescale=1./255)
test_generator = test_datagen.flow_from_directory(test_dir,
target_size=input_shape[:2],
batch_size=32,
class_mode='binary',
shuffle=False)
# Evaluate the model on the test set
loss, accuracy = model.evaluate(test_generator, steps=len(test_generator))
print(f'Test accuracy: {accuracy:.2f}')
# Get the predictions and true labels
predictions = model.predict(test_generator, steps=len(test_generator))
predictions = np.squeeze(predictions)
true_labels = test_generator.labels
# Get the image filenames
filenames = test_generator.filenames
# Find the indices of the correctly and incorrectly classified images
correct_indices = np.where((predictions >= 0.5) == true_labels)[0]
incorrect_indices = np.where((predictions >= 0.5) != true_labels)[0]
# Plot some correctly classified images
plt.figure(figsize=(10, 10))
for i, idx in enumerate(correct_indices[:9]):
plt.subplot(3, 3, i+1)
img = plt.imread(os.path.join(test_dir, filenames[idx]))
plt.imshow(img, cmap='gray')
plt.title('PNEUMONIA' if predictions[idx] >= 0.5 else 'NORMAL')
plt.axis('off')
# Plot some incorrectly classified images
plt.figure(figsize=(10, 10))
for i, idx in enumerate(incorrect_indices[:9]):
plt.subplot(3, 3, i+1)
img = plt.imread(os.path.join(test_dir, filenames[idx]))
plt.imshow(img, cmap='gray')
plt.title('PNEUMONIA' if predictions[idx] >= 0.5 else 'NORMAL')
plt.axis('off')
plt.show()在这段代码中,我们创建了一个测试和评估集数据生成器来评估模型。我们还获得了测试集的预测和真实标签,并找到了正确和错误分类图像的索引。然后,使用 Matplotlib,我们绘制了一些正确和错误分类图像的实例。
结论
在本教程中,我们使用 OpenCV 和 TensorFlow 构建了一个肺炎检测模型。我们使用 OpenCV 读取、处理和可视化图像,并使用 TensorFlow 训练和测试模型。该模型成功地以高精度对大多数测试集的图像进行了分类。
计算机视觉可以成为医疗诊断的巨大资产。虽然它们不能替代训练有素的医疗保健提供者,但它们可以缩短诊断时间并提高诊断准确性。你可以在此处查看更多 CV 医疗用例:https://arxiv.org/pdf/2203.15269.pdf
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 woshicver」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓