事务相关的元组结构
元组结构中包含很多pg的mvcc所必要的信息,下面的内容将梳理xmin,xmax,t_ctid,cmin,cmax,combo cid,tuple id的含义和关系
物理结构

HeapTupleHeaderData相当于tuple的header,其结构在src/include/access/htup_details.h中定义
typedef struct HeapTupleFields
{
TransactionId t_xmin; /* 插入事务的ID */
TransactionId t_xmax; /* 擅长或锁定事务的ID */
union
{
CommandId t_cid; /* 插入或删除的命令ID */
TransactionId t_xvac; /* VACUUM FULL的事务ID */
} t_field3;
} HeapTupleFields;
typedef struct DatumTupleFields
{
...
} DatumTupleFields;
struct HeapTupleHeaderData
{
union
{
HeapTupleFields t_heap;
DatumTupleFields t_datum;
} t_choice;
ItemPointerData t_ctid; /* 当前元组或更新元组的TID */
...
};
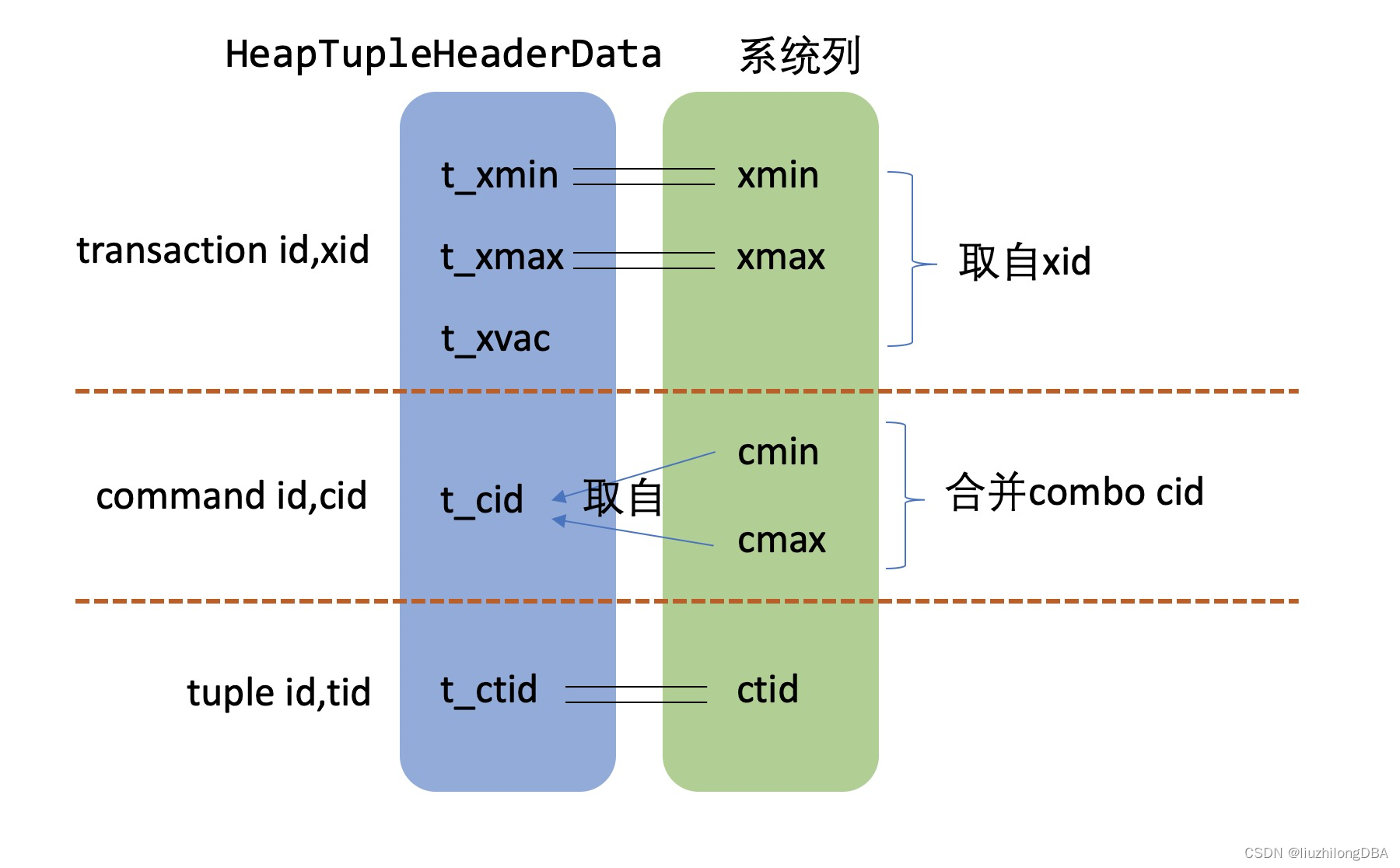
HeapTupleHeaderData中有5个定义对MVCC及其重要。其中x代表transaction,c代表command,t代表tuple,便于分类理解
t_xmin:表示插入该元组的事务IDt_xmax:表示删除该元组的事务ID或者回滚事务ID。如果没有被删除或更新元组,xmax是0;如果删除或更新元组后回滚,xmax是回滚事务ID。t_xvac:元组被vacuum时设置的xid,此时元组已脱离了原来的事务t_cid:表示命令标识(command id,cid),一个事务可以包含多个SQL,事务中的命令从0开始编号,cid依次递增。CommandId是uint32类型,最大支持2^32 - 1个命令,为了节省资源,而且查询不会影响行的事务顺序,查询不会增加cid(这点类似事务id分配)t_ctid:保存指向自身或新元组标识符(tid),tid是标识表中元组的,是元组的物理地址。如果一条记录被修改多次,那么该记录会存在多个版本。各个版本通过t_cid串联,形成一个版本链。通过这个版本链,可以找到最新的版本
系统列
每个元组都有6个系统列(每个tuple都有,可以直接查到),它们是tableoid,xmin,xmax,cmin,cmax,ctid 。tableoid是表的oid,在查询和dml时是不会变化的,这里重点讲其余5个系统列
lzldb=# select xmin,xmax,cmin,cmax,ctid from lzl1;
xmin | xmax | cmin | cmax | ctid
------+------+------+------+-------
616 | 619 | 0 | 0 | (0,3)
cmin:插入元组的cid,command idcmax:删除元组的cid,command id
其中xmin,xman,xvac是物理存储的,定义在struct HeapTupleFields中,但是cmin和cmax没有定义在HeapTupleFields结构体中的,结构体有关于command的t_cid,cmin、cmax就是从t_cid取数
cmin,cmax的源码还是在src/include/access/htup_details.h中
/* SetCmin is reasonably simple since we never need a combo CID */
#define HeapTupleHeaderSetCmin(tup, cid) \
do { \
Assert(!((tup)->t_infomask & HEAP_MOVED)); \
(tup)->t_choice.t_heap.t_field3.t_cid = (cid); \
(tup)->t_infomask &= ~HEAP_COMBOCID; \
} while (0)
/* SetCmax must be used after HeapTupleHeaderAdjustCmax; see combocid.c */
#define HeapTupleHeaderSetCmax(tup, cid, iscombo) \
do { \
Assert(!((tup)->t_infomask & HEAP_MOVED)); \
(tup)->t_choice.t_heap.t_field3.t_cid = (cid); \
if (iscombo) \
(tup)->t_infomask |= HEAP_COMBOCID; \
else \
(tup)->t_infomask &= ~HEAP_COMBOCID; \
} while (0)
/*
* HeapTupleHeaderGetRawCommandId will give you what's in the header whether
* it is useful or not. Most code should use HeapTupleHeaderGetCmin or
* HeapTupleHeaderGetCmax instead, but note that those Assert that you can
* get a legitimate result, ie you are in the originating transaction!
*/
#define HeapTupleHeaderGetRawCommandId(tup) \
( \
(tup)->t_choice.t_heap.t_field3.t_cid \
)
combocid
在8.3以前cmin和cmax是分开的。后来考虑到同事务对一条数据既插入又删除的情况比较少,而且事务结束后cmin、cmax都不需要,同时为了节省header空间,cmin、cmax合并到一起称为combo command id即combocid
combocid源码位置src/backend/utils/time/combocid.c
/* Key and entry structures for the hash table */
typedef struct
{
CommandId cmin;
CommandId cmax;
} ComboCidKeyData;
/* comboid的结构为cmin和cmax*/
static CommandId
GetComboCommandId(CommandId cmin, CommandId cmax)
{
...
/*
* 当第一次使用到combo cid时才会生成hash表
*/
if (comboHash == NULL)
{
HASHCTL hash_ctl;
/* 生成数组、hash表 */
comboCids = (ComboCidKeyData *)
MemoryContextAlloc(TopTransactionContext,
sizeof(ComboCidKeyData) * CCID_ARRAY_SIZE);
sizeComboCids = CCID_ARRAY_SIZE;
usedComboCids = 0;
memset(&hash_ctl, 0, sizeof(hash_ctl));
...
comboHash = hash_create("Combo CIDs",
CCID_HASH_SIZE,
&hash_ctl,
HASH_ELEM | HASH_BLOBS | HASH_CONTEXT);
}
...
}
combocid存放在hash表中。当事务第一次使用combocid时,会在内存中开辟一小块地方存放combocid。
所以这几个command id的关系和调用过程:combocid->(cmin,cmax)->(t_ctid,t_ctid)
简单的事务相关id和系统列关系
看了这么多id和源码,似乎有点乱。为了便于理解和记忆,梳理一下这些事务id、command id、tuple id的关系
事务的初步体验
在没有工具和插件的条件下,初步体验一下这几个系统列在事务中的变化
lzldb=# select xmin,xmax,cmin,cmax,ctid from lzl1;
xmin | xmax | cmin | cmax | ctid
------+------+------+------+-------
622 | 0 | 0 | 0 | (0,1)
lzldb=# begin ;
BEGIN
lzldb=*# update lzl1 set a=2;
UPDATE 1
--更新后,xmin+1,ctid+1,这里其实出现了新的tuple
lzldb=*
select xmin,xmax,cmin,cmax,ctid from lzl1;
xmin | xmax | cmin | cmax | ctid
------+------+------+------+-------
623 | 0 | 0 | 0 | (0,2)
lzldb=*# rollback;
ROLLBACK
--xmax会记录回滚事务id
--xmin,ctid又回到了旧值,其实旧tuple不怎么变化
lzldb=# select xmin,xmax,cmin,cmax,ctid from lzl1;
xmin | xmax | cmin | cmax | ctid
------+------+------+------+-------
622 | 623 | 0 | 0 | (0,1)
lzldb=# update lzl1 set a=2;
UPDATE 1
--再次更新,tuple号跳过了2,直接到3
lzldb=# select xmin,xmax,cmin,cmax,ctid from lzl1;
xmin | xmax | cmin | cmax | ctid
------+------+------+------+-------
624 | 0 | 0 | 0 | (0,3)
元组header与事务
pageinspect插件
直接看行的变化是看不到旧的tuple的,所以需要pageinsect插件。pageinsect插件是pg自带的第三方插件,可以展示数据页面的具体内容。为了观察tuple是如何支持事务的,需要用到get_raw_page()和heap_page_items()两个函数。
get_raw_page():返回指定块的二进制值。其中fork有main、fsm、vm、init几个值。main是数据文件主文件,fsm是free space map块文件,vm是可见性映射快文件,init是初始化的块,如果不指定fork默认为main
heap_page_items():显示一个堆页面上的所有行指针,即使因为mvcc看不到的行也会被展示。
一般把get_raw_page()当做参数传入heap_page_items()以展示元组的header、pointer信息和数据本身
heap_tuple_infomask_flags:将十进制的infomask,infomask2值转换成其含义(标识),输出2列:所有单标识和联合标识。(infomask后面会介绍)
lzldb=# create extension pageinspect;
CREATE EXTENSION
lzldb=# select t_xmin,t_xmax,t_field3 as t_cid,t_ctid from heap_page_items(get_raw_page('lzl1',0));
t_xmin | t_xmax | t_cid | t_ctid
--------+--------+-------+--------
633 | 0 | 0 | (0,1)
lp(line pointer)
line pointer直译是行指针的意思,实际上是页面中的行指针编号,相当于在页面中标记了一个元组。t_ctid看上去更像是tuple id,但是ctid只是(表的page号,行指针编号)的组合,ctid可以指向下个lp 。
例如对一个元组做一次update,会增加一个元组,新元组的lp编号+1,旧tuple的ctid指向新tuple的lp,新tuple的ctid指向自己
lzldb=# select lp,t_ctid from heap_page_items(get_raw_page('lzl1',0));
lp | t_ctid
----+--------
1 | (0,1)
(1 row)
lzldb=# update lzl1 set a=2;
UPDATE 1
lzldb=# select lp,t_ctid from heap_page_items(get_raw_page('lzl1',0));
lp | t_ctid
----+--------
1 | (0,2)
2 | (0,2)
lp源码在src/include/storage/itemid.h中,ItemIdData结构保存了元组的offset位置,状态,长度
typedef struct ItemIdData
{
unsigned lp_off:15, /* 元组在页面的偏移量 */
lp_flags:2, /* lp的状态 */
lp_len:15; /* 元组的长度 */
} ItemIdData;
typedef ItemIdData *ItemId;*
*
/* lp_off:15代表位域,lp_off占用unsigned中的15位,3个定义加起来总共32位。所以ItemIdData是int类型,4个字节,共32位 */
lp_flags定义了4种状态
/*
*lp_flags has these possible states. An UNUSED line pointer is available
*for immediate re-use, the other states are not.
*/
#define LP_UNUSED 0 /* lp没有被使用,元组长度pl_len总是为0 */
#define LP_NORMAL 1 /* lp正在使用,元组长度pl_len总是>0 */
#define LP_REDIRECT 2 /* HOT redirect重定向到其他lp (should have lp_len=0) */
#define LP_DEAD 3 /* dead的lp,可被vacuum */
lzldb=# select lp,lp_flags,lp_off,lp_len from heap_page_items(get_raw_page('lzl1',0));
lp | lp_flags | lp_off | lp_len
----+----------+--------+--------
1 | 1 | 8160 | 28
infomask
infomask提供了事务、锁、元组状态等信息,比如提交、终止、锁、HOT信息等等。header中有两个infomask:infomask和infomask2。他们存储的信息有所不同
infomask,infomask2
infomask源码还是在src/include/access/htup_details.h
#define FIELDNO_HEAPTUPLEHEADERDATA_INFOMASK2 2
uint16 t_infomask2; /* number of attributes + various flags */
#define FIELDNO_HEAPTUPLEHEADERDATA_INFOMASK 3
uint16 t_infomask; /* various flag bits, see below */
infomask的标识含义
/*
* information stored in t_infomask:
*/
#define HEAP_HASNULL 0x0001 /* 元组中是否有null值 */
#define HEAP_HASVARWIDTH 0x0002 /* 元组是否是变长的,如varchar类型 */
#define HEAP_HASEXTERNAL 0x0004 /* 是否有toast存储 */
#define HEAP_HASOID_OLD 0x0008 /* 元组是否有OID */
#define HEAP_XMAX_KEYSHR_LOCK 0x0010 /* 元组是否有for key-share锁 */
#define HEAP_COMBOCID 0x0020 /* t_cid是否是comboCID */
#define HEAP_XMAX_EXCL_LOCK 0x0040 /* 元组是否有for update锁 */
#define HEAP_XMAX_LOCK_ONLY 0x0080 /* xmax只起锁作用 */
/* xmax is a shared locker */
#define HEAP_XMAX_SHR_LOCK (HEAP_XMAX_EXCL_LOCK | HEAP_XMAX_KEYSHR_LOCK)
#define HEAP_LOCK_MASK (HEAP_XMAX_SHR_LOCK | HEAP_XMAX_EXCL_LOCK | \
HEAP_XMAX_KEYSHR_LOCK)
#define HEAP_XMIN_COMMITTED 0x0100 /* t_xmin对应的插入元组的事务已提交 */
#define HEAP_XMIN_INVALID 0x0200 /* t_xmin对于的插入元组的事务无效或终止 */
#define HEAP_XMIN_FROZEN (HEAP_XMIN_COMMITTED|HEAP_XMIN_INVALID)
#define HEAP_XMAX_COMMITTED 0x0400 /* t_xmax对于的删除元组的事务是否提交 */
#define HEAP_XMAX_INVALID 0x0800 /* t_xmax对于的删除元组的事务无效或终止 */
#define HEAP_XMAX_IS_MULTI 0x1000 /* t_xmax是否使用MultiXactId */
#define HEAP_UPDATED 0x2000 /* 该元组是数据行被更新后的版本 */
#define HEAP_MOVED_OFF 0x4000 /* 被 9.0 之前的 VACUUM FULL 移动到另外的地方,为了兼容二进制程序升级而保留 */
#define HEAP_MOVED_IN 0x8000 /* 与 HEAP_MOVED_OFF 相对,表明是从别处移动过来的,也是为了兼容性而保留 */
#define HEAP_MOVED (HEAP_MOVED_OFF | HEAP_MOVED_IN)
#define HEAP_XACT_MASK 0xFFF0 /* 可见性相关位 */
infomask2的标识含义
#define HEAP_NATTS_MASK 0x07FF /* 有11位用来保存元组的列的数量,(MaxHeapAttributeNumber用户的列长度是1600个)*/
/* bits 0x1800 are available */
#define HEAP_KEYS_UPDATED 0x2000 /* 元组更新或者删除 */
#define HEAP_HOT_UPDATED 0x4000 /* 元组更新后,新元组是HOT */
#define HEAP_ONLY_TUPLE 0x8000 /* HOT tuple */
#define HEAP2_XACT_MASK 0xE000 /* 可见性相关位 */
#define HEAP_TUPLE_HAS_MATCH HEAP_ONLY_TUPLE
/*在 Hash Join 中临时使用的标志,只用于 Hash 表中的 tuple,且不需要可见性信息,所以我们可以用一个可见性标志覆盖他,而不是使用一个单独的位 */
infomask的位与位计算
把16进制转换为2进制,就比较容易理解位所代表的含义
--将16进制的1600转换为2进制
lzldb=# select x'1600'::bit(16);
bit
------------------
0001011000000000
infomask:
0000000000000001 0x0001 HEAP_HASNULL
0000000000000010 0x0002 HEAP_HASVARWIDTH
0000000000000100 0x0004 HEAP_HASEXTERNAL
0000000000001000 0x0008 HEAP_HASOID_OLD
0000000000010000 0x0010 HEAP_XMAX_KEYSHR_LOCK
0000000000100000 0x0020 HEAP_COMBOCID
0000000001000000 0x0040 HEAP_XMAX_EXCL_LOCK
0000000010000000 0x0080 HEAP_XMAX_LOCK_ONLY
0000000001010000 0x0050 HEAP_XMAX_SHR_LOCK 位或计算一下(HEAP_XMAX_EXCL_LOCK | HEAP_XMAX_KEYSHR_LOCK)=10|40=50
0000000001010000 0x0050 HEAP_LOCK_MASK 位或计算一下(HEAP_XMAX_SHR_LOCK | HEAP_XMAX_EXCL_LOCK | HEAP_XMAX_KEYSHR_LOCK)=50|40|10=50
0000000100000000 0x0100 HEAP_XMIN_COMMITTED
0000001000000000 0x0200 HEAP_XMIN_INVALID
0000001100000000 0x0300 HEAP_XMIN_FROZEN 位或计算一下(HEAP_XMIN_COMMITTED|HEAP_XMIN_INVALID)=100|200=300
0000010000000000 0x0400 HEAP_XMAX_COMMITTED
0000100000000000 0x0800 HEAP_XMAX_INVALID
0001000000000000 0x1000 HEAP_XMAX_IS_MULTI
0010000000000000 0x2000 HEAP_UPDATED
0100000000000000 0x4000 HEAP_MOVED_OFF
1000000000000000 0x8000 HEAP_MOVED_IN
1100000000000000 0xC000 HEAP_MOVED 位或计算一下(HEAP_MOVED_OFF | HEAP_MOVED_IN)=4000|8000=C000
1111111111110000 0xFFF0 HEAP_XACT_MASK
infomask2:
0000011111111111 0x07FF HEAP_NATTS_MASK pg库的列最多有1600个=0000011001000000,所以前11位保存元组列足够
0001100000000000 0x1800 available位,看上去是空闲不用的
0010000000000000 0x2000 HEAP_KEYS_UPDATED
0100000000000000 0x4000 HEAP_HOT_UPDATED
1000000000000000 0x8000 HEAP_ONLY_TUPLE
1110000000000000 0xE000 HEAP2_XACT_MASK
怎么计算infomask?
infomask的标识是16进制,pageinspect插件查infomask出来的是10进制。需要to_hex(),10进制转换为16进制的函数 ,做一个转换
lzldb=# select lp,t_ctid,to_hex(t_infomask) infomask,to_hex(t_infomask2) infomask2 from heap_page_items(get_raw_page('lzl1',0));
lp | t_ctid | infomask | infomask2
----+--------+----------+-----------
1 | (0,1) | 2b00 | 1
infomask=2b00,还是有点转不过来,转成16进制有点难凑,转成二进制对着上面的位含义再凑一下0010101100000000=HEAP_UPDATED+HEAP_XMAX_INVALID+HEAP_XMIN_FROZEN
其含义为:标识元组更新过,xmax为invalid也就是0,xmin frozen对所有事务可见
infomask2=1,二进制的前11位,十进制的前2047(最多1600列),都是代表用户列的个数,所以1代表只有1个列
手动算infomask有点麻烦,从pg13开始pageinspect提供了函数heap_tuple_infomask_flags转换infomask,infomask2的含义。有单独位标识的是raw flag,联合多个位标识的是combined_flags
lzldb=# SELECT t_ctid, raw_flags, combined_flags
FROM heap_page_items(get_raw_page('lzl1', 0)),
LATERAL heap_tuple_infomask_flags(t_infomask, t_infomask2)
WHERE t_infomask IS NOT NULL OR t_infomask2 IS NOT NULL;
t_ctid | raw_flags | combined_flags
--------+------------------------------------------------------------------------+--------------------
(0,1) | {HEAP_XMIN_COMMITTED,HEAP_XMIN_INVALID,HEAP_XMAX_INVALID,HEAP_UPDATED} | {HEAP_XMIN_FROZEN}
提交日志clog
pg用提交日志(commit log,clog)来保存事务状态。pg会在事务完成前就将事务写进wal日志,这也是wal的含义。如果终止事务,将事务状态写进wal和clog,在实例恢复时,也能知道事务是没有完成提交的。
在需要获取事务状态时,比如判断事务可见性时,pg会读取clog的事务状态。
事务状态
源码src/include/access/clog.h
#define TRANSACTION_STATUS_IN_PROGRESS 0x00
#define TRANSACTION_STATUS_COMMITTED 0x01
#define TRANSACTION_STATUS_ABORTED 0x02
#define TRANSACTION_STATUS_SUB_COMMITTED 0x03
clog中事务定义了4种状态:IN_PROGRESS,COMMITTED,ABORTD,SUB_COMMITTED
事务状态大小
源码src/backend/access/transam/clog.c
/* We need two bits per xact, so four xacts fit in a byte */
#define CLOG_BITS_PER_XACT 2
#define CLOG_XACTS_PER_BYTE 4
#define CLOG_XACTS_PER_PAGE (BLCKSZ * CLOG_XACTS_PER_BYTE)
#define CLOG_XACT_BITMASK ((1 << CLOG_BITS_PER_XACT) - 1)
事务状态非常小,一个事务只需要2位,1字节可以保存4个事务状态
一个标准的page可以保留 8K*4=32768个事务状态
clog持久化
pg关库或落盘时,clog数据会写入pg_clog目录下,在10.0及以后的版本,pg_clog重命名为pg_xact。
[pg@lzl pg_xact]$ ll
total 8
-rw------- 1 pg pg 8192 Mar 28 23:33 0000
磁盘上的clog文件命名为0000,0001等。
clog文件大小为256KB,而内存中通过page存储事务为8K,所以0000文件的大小只会是8192的倍数,当写了32个clog page后,下个page便写入0001文件。PostgreSQL 启动时会从 pg_xact 中读取事务的状态加载至内存。
系统运行过程中,并不是所有事务的状态都需要长期保留在 CLOG 文件中,因此 vacuum 操作会定期将不再使用的 CLOG 文件删除
Hint Bits
什么是hintbits?
hint bits是为了标记那些创建或删除的行的事务是否提交或终止。如果没有hint bits,事务可见性需要访问磁盘pg_clog或pg_subtrans,这种访问代价比较昂贵。如果元组被设置了hint bits,那么访问page中的元组,就能知道元组状态,不需要额外的访问。
源码中使用SetHintBits()函数设置hintbits
如
SetHintBits(tuple, buffer, HEAP_XMIN_COMMITTED,
InvalidTransactionId);
SetHintBits设置的只是infomask中的2位,共4种hint bits(其实这2位infomask还有一个联合标识HEAP_XMIN_FROZEN,能看出来hintbits就是单纯为了标记事务状态的)
#define HEAP_XMIN_COMMITTED 0x0100 /* t_xmin对应的插入或更新事务已提交 */
#define HEAP_XMIN_INVALID 0x0200 /* t_xmin对于的插入或更新事务无效或终止 */
#define HEAP_XMAX_COMMITTED 0x0400 /* t_xmax对于的删除或更新事务是否提交 */
#define HEAP_XMAX_INVALID 0x0800 /* t_xmax对于的删除或更新事务无效或终止 */
查询会产生写入
事务开始后,pg的dml事务会在元组header中记录t_min等事务id和事务状态。但事务结束时,不会在header中作任何事情,而是在后面的DML或者DQL,VACUUM等SQL扫描到对应的TUPLE时,触发SetHintBits的操作(产生新快照访问数据时SetHintBits,代码在HeapTupleSatisfiesMVCC()中,后面可见性规则小节会介绍)。
在没有触发SetHintBits之前,pg在clog中寻找事务状态;触发SetHintBits后,在数据页的元组header中找hintbits所代表的事务状态。
例如一个insert语句
lzldb=# insert into lzl1 values(1);
INSERT 0 1
lzldb=# SELECT t_ctid, raw_flags, combined_flags
lzldb-# FROM heap_page_items(get_raw_page('lzl1', 0)),
lzldb-# LATERAL heap_tuple_infomask_flags(t_infomask, t_infomask2)
lzldb-# WHERE t_infomask IS NOT NULL OR t_infomask2 IS NOT NULL;
t_ctid | raw_flags | combined_flags
--------+---------------------+----------------
(0,1) | {HEAP_XMAX_INVALID} | {}
(1 row)
lzldb=# select * from lzl1; --仅做一次查询
a
---
1
(1 row)
lzldb=# SELECT t_ctid, raw_flags, combined_flags
FROM heap_page_items(get_raw_page('lzl1', 0)),
LATERAL heap_tuple_infomask_flags(t_infomask, t_infomask2)
WHERE t_infomask IS NOT NULL OR t_infomask2 IS NOT NULL;
t_ctid | raw_flags | combined_flags
--------+-----------------------------------------+----------------
(0,1) | {HEAP_XMIN_COMMITTED,HEAP_XMAX_INVALID} | {}
一次查询后,t_infomask发生了变化,说明tuple header发生了变化。
在insert后,SetHintBits只有HEAP_XMAX_INVALID,因为insert本身只会更新xmin,无论事物是否提交或终止(退出或rollback)xmax都是没用的,可以随事务一起SetHintBits为HEAP_XMAX_INVALID
但是事务可能提交,也可能终止(退出或rollback),又由于事务完成不会更新元组,所以HEAP_XMIN_COMMITTED不能随事务完成而SetHintBits
在检测事务可见性(heapam_visibility.c)时,可见性检测更新了元组的事务状态SetHintBits到t_infomask中,所以查询更新了HEAP_XMIN_COMMITTED
hintbits优点:事务中数据更新的完成(包括失败),不会对元组产生任何写入。提交和回退会非常快。
hintbits缺点:如果一个事务更新了多行,下一次查询检测可见性时可能会从pg_clog中读取事务状态,并更新非常多的page。
hintbits是否会产生WAL日志?
在开启 checksum 或者参数 wal_log_hints 为 true 的情况下,如果 checkpoint 后第一次使页面 dirty 的操作是更新 Hint Bits,则会产生一条 WAL 日志,将当前页面写入 WAL 日志中(即 Full Page Image),避免产生部分写,导致数据 checksum 异常。
因此,在开启 checksum 或者 参数 wal_log_hints 为 true 时,即便执行 SELECT,也可能更改页面的 Hint Bits,从而导致产生 WAL 日志,这会在一定程度上增加 WAL 日志占用的存储空间。如果在使用pg中发现执行SELECT会触发磁盘的写入操作,可以检查一下是否开启了CHECKSUM或者wal_log_hints。
hintbits为什么延迟更新?
源码src/backend/access/heap/heapam_visibility.c里,在可见性规则HeapTupleSatisfiesMVCC()注释中有一段hintbits为什么延迟更新的解释
/*
*插入、删除操作还在跑时,哪怕事务已提交或者回退,都不会更新元组上的hint bits,也就是更新事务状态
*因为在高并发场景下共享数据结构可能会造成争用,而且这也不会影响可见性判断
*hintbits只会发生在首次全新快照访问已完成事务的数据之后
*所以HeapTupleSatisfiesMVCC每次都会运行TransactionIdIsCurrentTransactionId,XidInMVCCSnapshot,以判断是否当前事务的元组
*在老版本中,pg尝试立即更新hintbits(即使事务在运行中),但是造成对PGXACT array的更多争用
*/
简单点说,hintbits立即更新性能非常差,所以将事务状态先放在clog,减少PGXACT的争用,以提升性能。hintbits延迟更新就造成了后续查询可能会更新元组的情况
元组的增删改
在积累了元组header、系统列、clog、hintbits等知识点后,我们来看下pg是如何完成增删改操作。
观察DML事务
通过对lp,lp_flags,ctid,xmin,xmax,cid(cmin,cmax),infomask,infomask2这些元组头部信息,观察pg的DML事务行为
观察这些内容会使用以下sql
select t_ctid,lp,case lp_flags when 0 then '0:LP_UNUSED' when 1 then 'LP_NORMAL' when 2 then 'LP_REDIRECT' when 3 then 'LP_DEAD' end as lp_flags,t_xmin,t_xmax,t_field3 as t_cid, raw_flags, info.combined_flags from heap_page_items(get_raw_page('lzl1',0)) item,LATERAL heap_tuple_infomask_flags(t_infomask, t_infomask2) info order by lp;
(稍微说下,有些资料里喜欢这样SELECT '(0,'||lp||')' AS ctid,这样写不太合适,lp跟ctid是两码事,lp相当于行号,ctid是指向行号的,lp是可以不等于ctid的)
为了更好的阅读,创建一个view简化一下sql
create view vlzl1 as select t_ctid,lp,case lp_flags when 0 then '0:LP_UNUSED' when 1 then 'LP_NORMAL' when 2 then 'LP_REDIRECT' when 3 then 'LP_DEAD' end as lp_flags,t_xmin,t_xmax,t_field3 as t_cid, raw_flags, info.combined_flags from heap_page_items(get_raw_page('lzl1',0)) item,LATERAL heap_tuple_infomask_flags(t_infomask, t_infomask2) info order by lp;
查询就像这样
lzldb=# \x
Expanded display is on.
lzldb=# select * from vlzl1;
-[ RECORD 6 ]--+-------
t_ctid | (0,6)
lp | 6
lp_flags | LP_NORMAL
t_xmin | 653
t_xmax | 0
t_cid | 0
raw_flags | {HEAP_XMAX_INVALID,HEAP_UPDATED,HEAP_ONLY_TUPLE}
combined_flags | {}
插入
清空数据,insert插入一行
lzldb=# begin ;
BEGIN
lzldb=*# insert into lzl1 values(1);
INSERT 0 1
lzldb=*# insert into lzl1 values(2);
INSERT 0 1
lzldb=*# commit;
lzldb=# select * from vlzl1;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+---------------------+----------------
(0,1) | 1 | LP_NORMAL | 664 | 0 | 0 | {HEAP_XMAX_INVALID} | {}
(0,2) | 2 | LP_NORMAL | 664 | 0 | 1 | {HEAP_XMAX_INVALID} | {}
ctid指向(page 0,lp 1),也就指向自身
lp,line pointer行指针编号,递增
2个元组xmin是同一个事务,表示2个元组是一个事务插入
xmax为0表示无效事务ID,infomask也仅说明xmax无效,该元组还没有"经历"删除事务
cid从0开始递增,0代表事务第一个command,1代表事务第二个command
删除
lzldb=# begin;
BEGIN
lzldb=*# delete from lzl1 where a=1;
DELETE 1
lzldb=*# commit;
COMMIT
lzldb=# select * from vlzl1;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+-----------------------------------------+----------------
(0,1) | 1 | LP_NORMAL | 664 | 665 | 0 | {HEAP_XMIN_COMMITTED,HEAP_KEYS_UPDATED} | {}
(0,2) | 2 | LP_NORMAL | 664 | 0 | 1 | {HEAP_XMIN_COMMITTED,HEAP_XMAX_INVALID} | {}
删除了第一个元组,元组没有物理上删除,只是几个属性打了标记
ctid未变还是指向自身
xmax更新为删除事务id
infomask标识有HEAP_KEYS_UPDATED表示元组删除了(实际上HEAP_KEYS_UPDATED的有删除或更新的意思)
虽然只更新了第一个元组,但是第二个元组更新了infomask HEAP_XMIN_COMMITTED
更新
lzldb=# begin;
BEGIN
lzldb=# update lzl1 set a=3;
UPDATE 1
lzldb=*# commit;
COMMIT
lzldb=# select * from vlzl1;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+-------------------------------------------------------------+----
(0,1) | 1 | LP_NORMAL | 664 | 665 | 0 | {HEAP_XMIN_COMMITTED,HEAP_XMAX_COMMITTED,HEAP_KEYS_UPDATED} | {}
(0,3) | 2 | LP_NORMAL | 664 | 666 | 0 | {HEAP_XMIN_COMMITTED,HEAP_HOT_UPDATED} | {}
(0,3) | 3 | LP_NORMAL | 666 | 0 | 0 | {HEAP_XMAX_INVALID,HEAP_UPDATED,HEAP_ONLY_TUPLE} | {}
更新事务不会再元组上操作,而是将老元组标识为不可用,新增一个新元组
lp=2 为更新事务的老元组,t_xmax更新为更新事务id,infomask增加标识HEAP_HOT_UPDATED,表示该元组是hot,ctid指向了新元组
lp=3 为更新事务的新元组,相当于插入了一个新元组,不过xmin事务id跟老元组xmax一致,并且infomask有额外标识HEAP_UPDATED表示该元组是update后的row
另外,一个看不见的被删除的元组 lp=1,在不相关的更新事务发生后,infomask增加了标识HEAP_XMAX_COMMITTED
回退
lzldb=# truncate table lzl1;
TRUNCATE TABLE
lzldb=# begin;
BEGIN
lzldb=*# insert into lzl1 values(1); --插入
INSERT 0 1
lzldb=*# select * from vlzl1;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+---------------------+----------------
(0,1) | 1 | LP_NORMAL | 679 | 0 | 0 | {HEAP_XMAX_INVALID} | {}
(1 row)
lzldb=*# rollback; --插入回退
ROLLBACK
lzldb=# select * from vlzl1;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+---------------------+----------------
(0,1) | 1 | LP_NORMAL | 679 | 0 | 0 | {HEAP_XMAX_INVALID} | {}
lzldb=# select * from lzl1;
a
---
(0 rows)
--插入后回退,元组header信息没有任何变化
lzldb=# insert into lzl1 values(2);
INSERT 0 1
lzldb=# begin ;
BEGIN
lzldb=*# delete from lzl1 ; --删除
DELETE 1
lzldb=*# select * from vlzl1;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+-----------------------------------------+----------------
(0,1) | 1 | LP_NORMAL | 684 | 0 | 0 | {HEAP_XMIN_INVALID,HEAP_XMAX_INVALID} | {}
(0,2) | 2 | LP_NORMAL | 685 | 686 | 0 | {HEAP_XMIN_COMMITTED,HEAP_KEYS_UPDATED} | {}
(2 rows)
lzldb=*# rollback; --删除回退
ROLLBACK
lzldb=# select * from vlzl1;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+-----------------------------------------+----------------
(0,1) | 1 | LP_NORMAL | 684 | 0 | 0 | {HEAP_XMIN_INVALID,HEAP_XMAX_INVALID} | {}
(0,2) | 2 | LP_NORMAL | 685 | 686 | 0 | {HEAP_XMIN_COMMITTED,HEAP_KEYS_UPDATED} | {}
--删除后回退,元组header信息没有任何变化
lzldb=*# update lzl1 set a=100 ; --更新
UPDATE 1
lzldb=*# select * from vlzl1;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+--------------------------------------------------+---------------
(0,1) | 1 | LP_NORMAL | 684 | 0 | 0 | {HEAP_XMIN_INVALID,HEAP_XMAX_INVALID} | {}
(0,3) | 2 | LP_NORMAL | 685 | 688 | 0 | {HEAP_XMIN_COMMITTED,HEAP_HOT_UPDATED} | {}
(0,3) | 3 | LP_NORMAL | 688 | 0 | 0 | {HEAP_XMAX_INVALID,HEAP_UPDATED,HEAP_ONLY_TUPLE} | {}
(3 rows)
lzldb=*# rollback; --更新回退
ROLLBACK
lzldb=*# select * from vlzl1;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+--------------------------------------------------+---------------
(0,1) | 1 | LP_NORMAL | 684 | 0 | 0 | {HEAP_XMIN_INVALID,HEAP_XMAX_INVALID} | {}
(0,3) | 2 | LP_NORMAL | 685 | 688 | 0 | {HEAP_XMIN_COMMITTED,HEAP_HOT_UPDATED} | {}
(0,3) | 3 | LP_NORMAL | 688 | 0 | 0 | {HEAP_XMAX_INVALID,HEAP_UPDATED,HEAP_ONLY_TUPLE} | {}
--更新后回退,元组header信息没有任何变化
• 事务回退,元组信息不会有任何变化。这也是为什么pg的mvcc不用担心回滚段不够用,因为回滚只是可见性操作,不会更新数据本身
• xmax在回退后也没有变,说明xmax有值不一定代表元组被删除,也可能是删除或更新事务回退了
• 但是,只要产生了可见性检测,哪怕不产生数据变化,所有元组的infomask都会更新HEAP_XMIN_INVALID。其中非HOT元组都加上HEAP_XMIN_INVALID,HOT指向的元组当然也是HEAP_XMIN_INVALID
参考
books:
《postgresql指南 内幕探索》
《postgresql实战》
《postgresql技术内幕 事务处理深度探索》
《postgresql数据库内核分析》
https://edu.postgrespro.com/postgresql_internals-14_parts1-2_en.pdf
官方资料:
https://en.wikipedia.org/wiki/Concurrency_control
https://wiki.postgresql.org/wiki/Hint_Bits
https://www.postgresql.org/docs/current/routine-vacuuming.html#VACUUM-FOR-WRAPAROUND
https://www.postgresql.org/docs/10/storage-page-layout.html
https://www.postgresql.org/docs/13/pageinspect.html3
pg事务必读文章 interdb
https://www.interdb.jp/pg/pgsql05.html
https://www.interdb.jp/pg/pgsql06.html
源码大佬
https://blog.csdn.net/Hehuyi_In/article/details/102920988
https://blog.csdn.net/Hehuyi_In/article/details/127955762
https://blog.csdn.net/Hehuyi_In/article/details/125023923
pg的快照优化性能对比
https://techcommunity.microsoft.com/t5/azure-database-for-postgresql/improving-postgres-connection-scalability-snapshots/ba-p/1806462
其他资料
https://brandur.org/postgres-atomicity
https://mp.weixin.qq.com/s/j-8uRuZDRf4mHIQR_ZKIEg








![[CTF/网络安全] 攻防世界 robots 解题详析](https://img-blog.csdnimg.cn/2e490a5cd85a4a409e52cfde431659fd.png#pic_center)



![[CTF/网络安全] 攻防世界 cookie 解题详析](https://img-blog.csdnimg.cn/d83fd330b9a443c49edd46c0ee844132.png#pic_center)
