目录
- 负载均衡算法
- 负载均衡原理
- 启动两个服务实例
- 开启负载均衡
- 更改Ribbon随机策略
什么是Ribbon:

负载均衡算法
负载均衡算法:
1.轮询法:
将请求按顺序轮流地分配到后端服务器上,它均衡地对待后端的每一台服务器,而不关心服务器实际的连接数和当前的系统负载。
2.随机法:
通过系统的随机算法,根据后端服务器的列表大小值来随机选取其中的一台服务器进行访问。由概率统计理论可以得知,随着客户端调用服务端的次数增多,其实际效果越来越接近于平均分配调用量到后端的每一台服务器,也就是轮询的结果。
3.源地址哈希法
源地址哈希的思想是根据获取客户端的IP地址,通过哈希函数计算得到的一个数值,用该数值对服务器列表的大小进行取模运算,得到的结果便是客服端要访问服务器的序号。采用源地址哈希法进行负载均衡,同一IP地址的客户端,当后端服务器列表不变时,它每次都会映射到同一台后端服务器进行访问。
4.加权轮询法:
不同的后端服务器可能机器的配置和当前系统的负载并不相同,因此它们的抗压能力也不相同。给配置高、负载低的机器配置更高的权重,让其处理更多的请;而配置低、负载高的机器,给其分配较低的权重,降低其系统负载,加权轮询能很好地处理这一问题,并将请求顺序且按照权重分配到后端。
5.加权随机法
与加权轮询法一样,加权随机法也根据后端机器的配置,系统的负载分配不同的权重。不同的是,它是按照权重随机请求后端服务器,而非顺序。
6.最小连接数法
最小连接数算法比较灵活和智能,由于后端服务器的配置不尽相同,对于请求的处理有快有慢,它是根据后端服务器当前的连接情况,动态地选取其中当前积压连接数最少的一台服务器来处理当前的请求,尽可能地提高后端服务的利用效率,将请求合理地分流到每一台服务器。
负载均衡原理
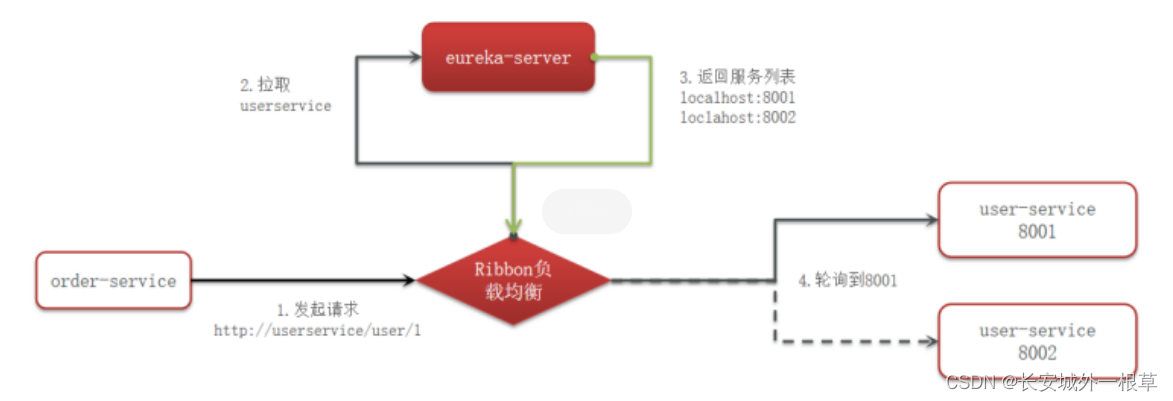
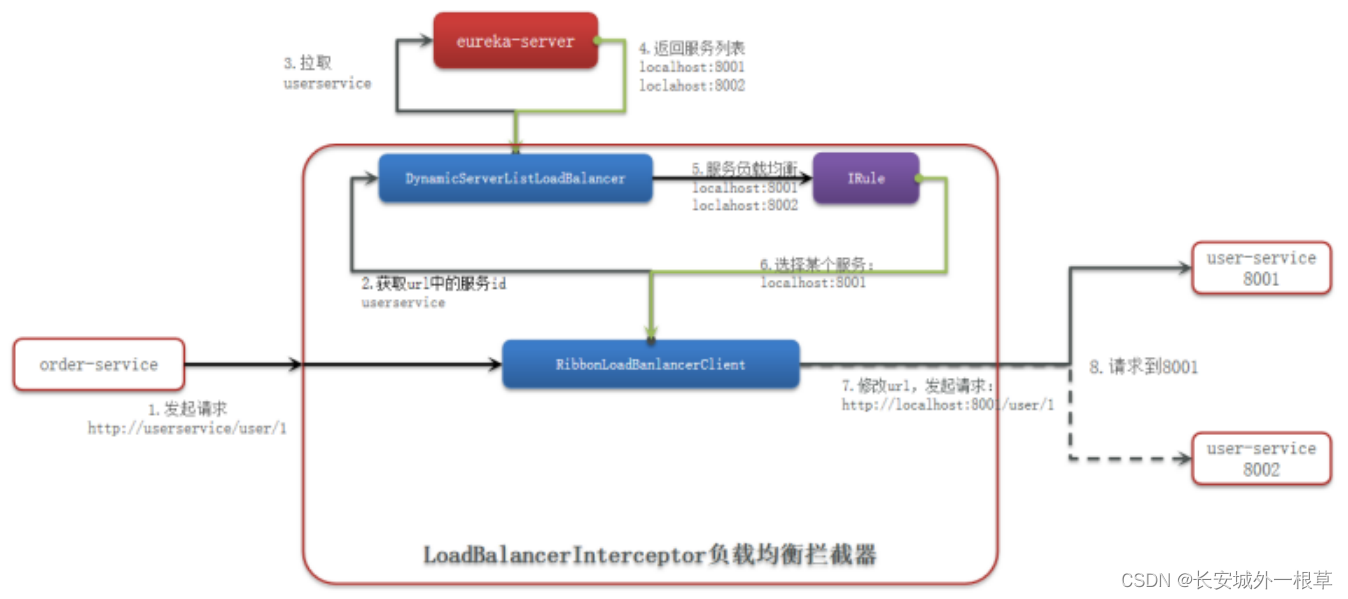
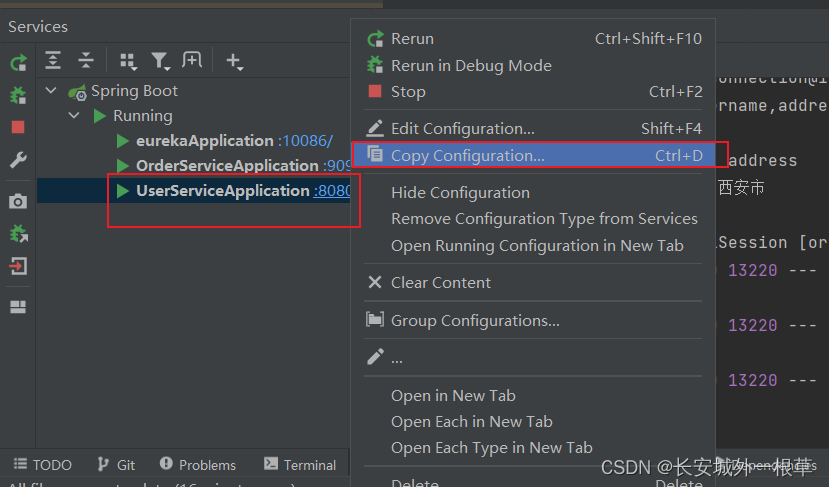
启动两个服务实例
首先我们启动两个user-service实例,一个8000,一个8001。
方法:
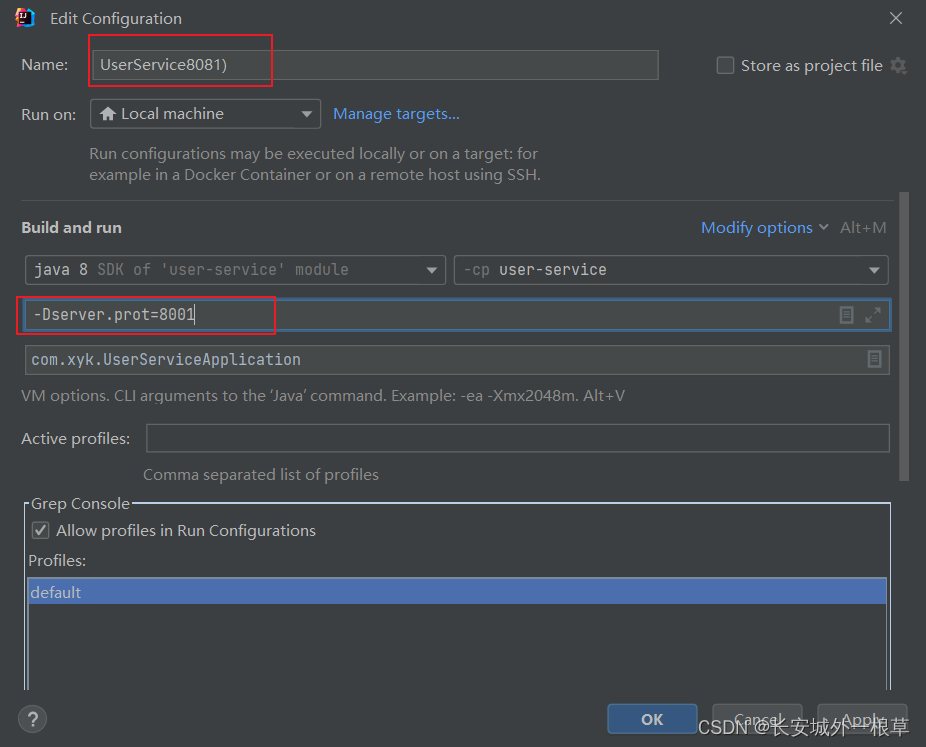
-Dserver.prot=8001
运行结果:

开启负载均衡
因为Eureka中已经集成了Ribbon,所以我们无需引入新的依赖。直接修改代码:
在RestTemplate的配置方法上添加:
@LoadBalanced

增加一个新的调用方式,不再手动获取ip和端口,而是直接通过服务名称调用:
controller:
@RestController
@RequestMapping("/order")
public class OrderController {
@Autowired
private OrderService orderService;
@Autowired
private RestTemplate restTemplate;
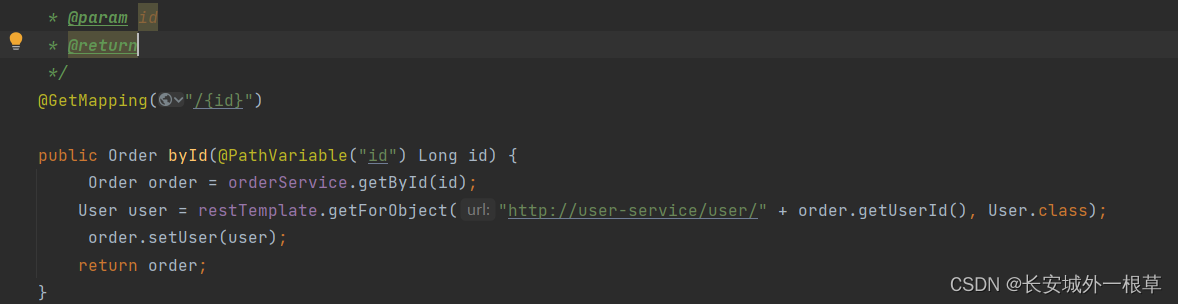
/**
* 根基ID查询
* @param id
* @return
*/
@GetMapping("/{id}")
public Order byId(@PathVariable("id") Long id) {
Order order = orderService.getById(id);
User user = restTemplate.getForObject("http://user-service/user/" + order.getUserId(), User.class);
order.setUser(user);
return order;
}
更改Ribbon随机策略
user-service:
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule