目录
- 1.Redis用的什么数据类型
- 2.Hash底层结构
- 3.JVM垃圾判别阶段算法
- 4.MySQL索引模型
- 5.为什么用B+树
- 6.联合索引在B+树如何构造的
- 7.覆盖索引知道吗
1.Redis用的什么数据类型
1.String(字符类型)
2.Hash(散列类型)
3.List(列表类型)
4.Set(集合类型)
5.SortedSet(有序集合类型,简称zset)
6.Bitmap(位图)
7.HyperLogLog(统计)
8.GEO(地理)
9.Stream
2.Hash底层结构
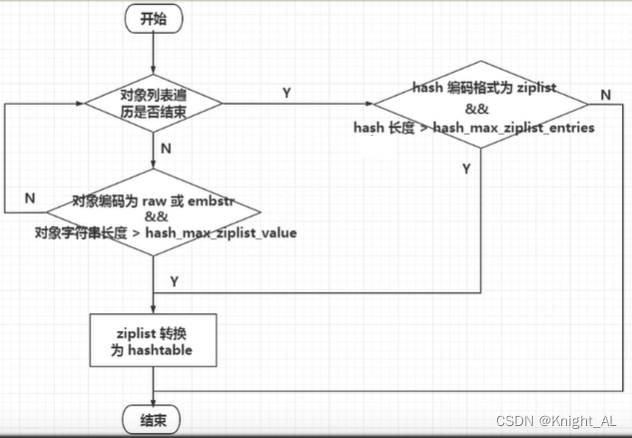
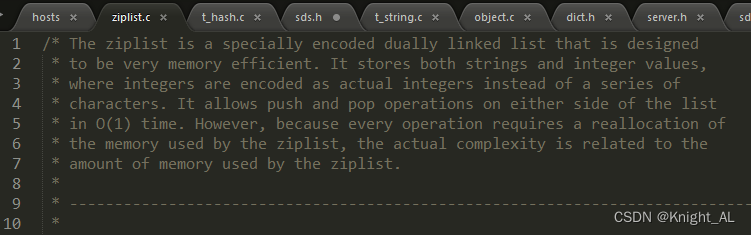
结构
hash-max-ziplist-entries:使用压缩列表保存时哈希集合中的最大元素个数。
hash-max-ziplist-value:使用压缩列表保存时哈希集合中单个元素的最大长度。
结论
1.哈希对象保存的键值对数量小于 512 个;
2.所有的键值对的健和值的字符串长度都小于等于 64byte(一个英文字母一个字节) 时用ziplist,反之用hashtable
ziplist升级到hashtable可以,反过来降级不可以
一旦从压缩列表转为了哈希表,Hash类型就会一直用哈希表进行保存而不会再转回压缩列表了。
在节省内存空间方面哈希表就没有压缩列表高效了。
hash的两种编码格式
ziplist
hashtable
ziplist.c
Ziplist 压缩列表是一种紧凑编码格式,总体思想是多花时间来换取节约空间,即以部分读写性能为代价,来换取极高的内存空间利用率,
因此只会用于 字段个数少,且字段值也较小 的场景。压缩列表内存利用率极高的原因与其连续内存的特性是分不开的。
想想我们的学过的一种GC垃圾回收机制:标记–压缩算法
当一个 hash对象 只包含少量键值对且每个键值对的键和值要么就是小整数要么就是长度比较短的字符串,那么它用 ziplist 作为底层实现
ziplist什么样
ziplist是一个经过特殊编码的双向链表,它不存储指向上一个链表节点和指向下一个链表节点的指针,而是存储上一个节点长度和当前节点长度,通过牺牲部分读写性能,来换取高效的内存空间利用率,节约内存,是一种时间换空间的思想。只用在字段个数少,字段值小的场景里面
明明有链表了,为什么出来一个压缩链表?
-
1 普通的双向链表会有两个指针,在存储数据很小的情况下,我们存储的实际数据的大小可能还没有指针占用的内存大,得不偿失。ziplist 是一个特殊的双向链表没有维护双向指针:prev next;而是存储上一个 entry的长度和 当前entry的长度,通过长度推算下一个元素在什么地方。牺牲读取的性能,获得高效的存储空间,因为(简短字符串的情况)存储指针比存储entry长度更费内存。这是典型的“时间换空间”。
-
2 链表在内存中一般是不连续的,遍历相对比较慢,而ziplist可以很好的解决这个问题,普通数组的遍历是根据数组里存储的数据类型找到下一个元素的(例如int类型的数组访问下一个元素时每次只需要移动一个sizeof(int)就行),但是ziplist的每个节点的长度是可以不一样的,而我们面对不同长度的节点又不可能直接sizeof(entry),所以ziplist只好将一些必要的偏移量信息记录在了每一个节点里,使之能跳到上一个节点或下一个节点。
-
3 头节点里有头节点里同时还有一个参数 len,和string类型提到的 SDS 类似,这里是用来记录链表长度的。因此获取链表长度时不用再遍历整个链表,直接拿到len值就可以了,这个时间复杂度是 O(1)
3.JVM垃圾判别阶段算法
引用计数算法
对于一个对象A,只要有任何一个对象引用了A ,则A 的引用计数器就加1,当引用失效时,引用计数器就减1。只要对象A 的引用计数器的值为0,即表示对象A不可能再被使用,可进行回收。
优缺点
优点:实现简单,垃圾对象便于辨识;判定效率高,回收没有延迟性。
缺点:
缺点1:它需要单独的字段存储计数器,这样的做法增加了存储空间的开销。
缺点2:每次赋值都需要更新计数器,伴随着加法和减法操作,这增加了时间开销。
缺点3:引用计数器有一个严重的问题,即无法处理循环引用的情况。这是一条致命缺陷,导致在Java 的垃圾回收器中没有使用这类算法。

可达性分析算法
原理:
其原理简单来说,就是将对象及其引用关系看作一个图,选定活动的对象作为 GC Roots,然后跟踪引用链条,如果一个对象和GC Roots之间不可达,也就是不存在引用链条,那么即可认为是可回收对象。
基本思路:
- 可达性分析算法是以根对象集合(GC Roots)为起始点,按照从上至下的方式搜索被根对象集合所连接的目标对象是否可达。
- 使用可达性分析算法后,内存中的存活对象都会被根对象集合直接或间接连接着,搜索所走过的路径称为引用链(Reference Chain)
- 如果目标对象没有任何引用链相连,则是不可达的,就意味着该对象己经死亡,可以标记为垃圾对象。
- 在可达性分析算法中,只有能够被根对象集合直接或者间接连接的对象才是存活对象。

优点
实现简单,执行高效 ,有效的解决循环引用的问题,防止内存泄漏。
GC Roots 对象包括以下几种:(巧记:两栈两方法)
- 虚拟机栈中引用的对象
- 方法区中类静态属性引用的对象
- 方法区中常量引用的对象
- 本地方法栈中 JNI 引用的对象
4.MySQL索引模型
5.为什么用B+树
- B+Tree的磁盘读写代价更低:由于非叶子节点只存放索引不存放数据,所以每个节点可以存放更多的索引,一次读取查找的关键字更多,树的高度更低
- B+Tree的查询效率更加稳定,因为只有叶子节点存在数据,所以每次查询的路径长度都是相同的
- B+Tree更适合范围查询,因为B-Tree的非叶子节点存放数据,所以需要使用中序遍历来查询,而B+Tree只有叶子节点有数据,叶子节点之间使用链表连接,所以只要顺序扫描进行,更加方便
基于上述的原因,B+Tree比B-Tree更适合做数据库索引
6.联合索引在B+树如何构造的
在B+树上,联合索引的存储结构与单列索引类似,只是在每个节点上存储的不再是单个列的值而是多个列的值。具体来说,每个节点上存储的是一个键值对,其中键是多个列的值的组合值是指向对应数据行的指针。
在进行数据查找时,首先根据联合索引的第一个列的值在B+树上进行查找,找到对应的节点。然后,在该节点上查找第二个列的值,如果找到了,则继续查找下一个列的值,直到找到所有列的值对应的节点。最后,根据节点上存储的指针找到对应的数据行。
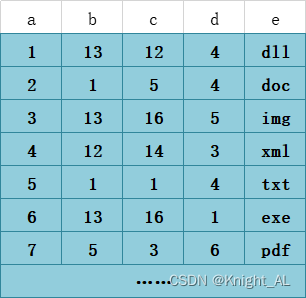
联合索引的查找方式
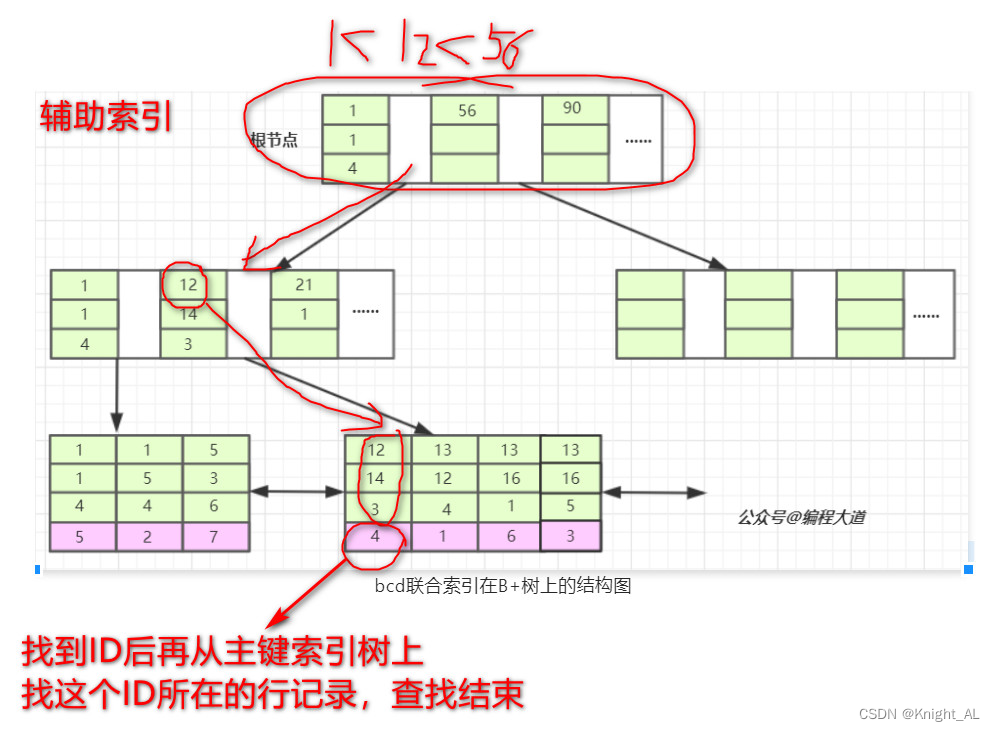
当我们的SQL语言可以应用到索引的时候,比如 select * from T1 where b = 12 and c = 14 and d = 3; 也就是T1表中a列为4的这条记录。存储引擎首先从根节点(一般常驻内存)开始查找,第一个索引的第一个索引列为1,12大于1,第二个索引的第一个索引列为56,12小于56,于是从这俩索引的中间读到下一个节点的磁盘文件地址,从磁盘上Load这个节点,通常伴随一次磁盘IO,然后在内存里去查找。当Load叶子节点的第二个节点时又是一次磁盘IO,比较第一个元素,b=12,c=14,d=3完全符合,于是找到该索引下的data元素即ID值,再从主键索引树上找到最终数据。
7.覆盖索引知道吗
覆盖索引可以减少树的搜索次数,显著提升查询性能
简单说就是,select 到 from 之间查询的列使用了索引!