接上次博客:和数组处理有关的一些OJ题;ArrayList 实现简单的洗牌算法(JAVA)(ArrayList)_di-Dora的博客-CSDN博客
目录
链表的基本概念
链表的类型
单向、不带头、非循环链表的实现
遍历链表并打印节点值:
在链表头部插入节点:
在链表尾部插入节点:
得到单链表的长度 :
查找是否包含关键字key是否在单链表当中:
删除第一次出现关键字为key的节点 (两种实现方式):
删除所有值为key的节点:
指定任意位置插入数据:
清空链表:
链表的优缺点
数组是一块连续的内存,逻辑上和物理内存上都是连续的;
链表是在逻辑上是连续的,但是在物理内存上是不连续的。
链表的基本概念
链表是一种常见的数据结构,它由一系列节点组成,每个节点包含两部分:数据元素 (value) 和指向下一个节点的指针 ( next 域 )。通过这些节点的连接,可以形成一个链式结构。
链表的基本概念如下:
1、节点(Node):链表的基本单元,包含数据元素和指针。数据元素可以是任意类型的数据,指针指向下一个节点。每个节点都是一个对象。最后一个节点的 next 域是 null 。
2、头节点(Head):链表的第一个节点,用于标识链表的起始位置。通常使用一个指针变量来指向头节点。
3、尾节点(Tail):链表的最后一个节点,其指针指向空(NULL),表示链表的结束。
4、链表长度(Length):链表中节点的数量,可以通过遍历链表来计算。
5、空链表(Empty List):不包含任何节点的链表。
6、单向链表(Singly Linked List):每个节点只有一个指针,指向下一个节点。最后一个节点的指针指向空。
7、双向链表(Doubly Linked List):每个节点有两个指针,一个指向前一个节点,一个指向下一个节点。头节点的前一个指针和尾节点的后一个指针都指向空。
注意:
1.链式结构在逻辑上是连续的,但是在物理上不一定连续;
2.现实中的节点一般都是从堆上申请出来的;
3.从堆上申请的空间,是按照一定的策略来分配的,两次申请的空间可能连续,也可能不连续。
链表的类型
链表的组合方式有多种,可以根据以下两个方面来区分和计算组合的种类:
1、单向链表和双向链表:
根据节点的指针数量,链表可以分为单向链表和双向链表。
单向链表每个节点只有一个指针,指向下一个节点;
而双向链表每个节点有两个指针,分别指向前一个节点和后一个节点。
2、是否带头节点:
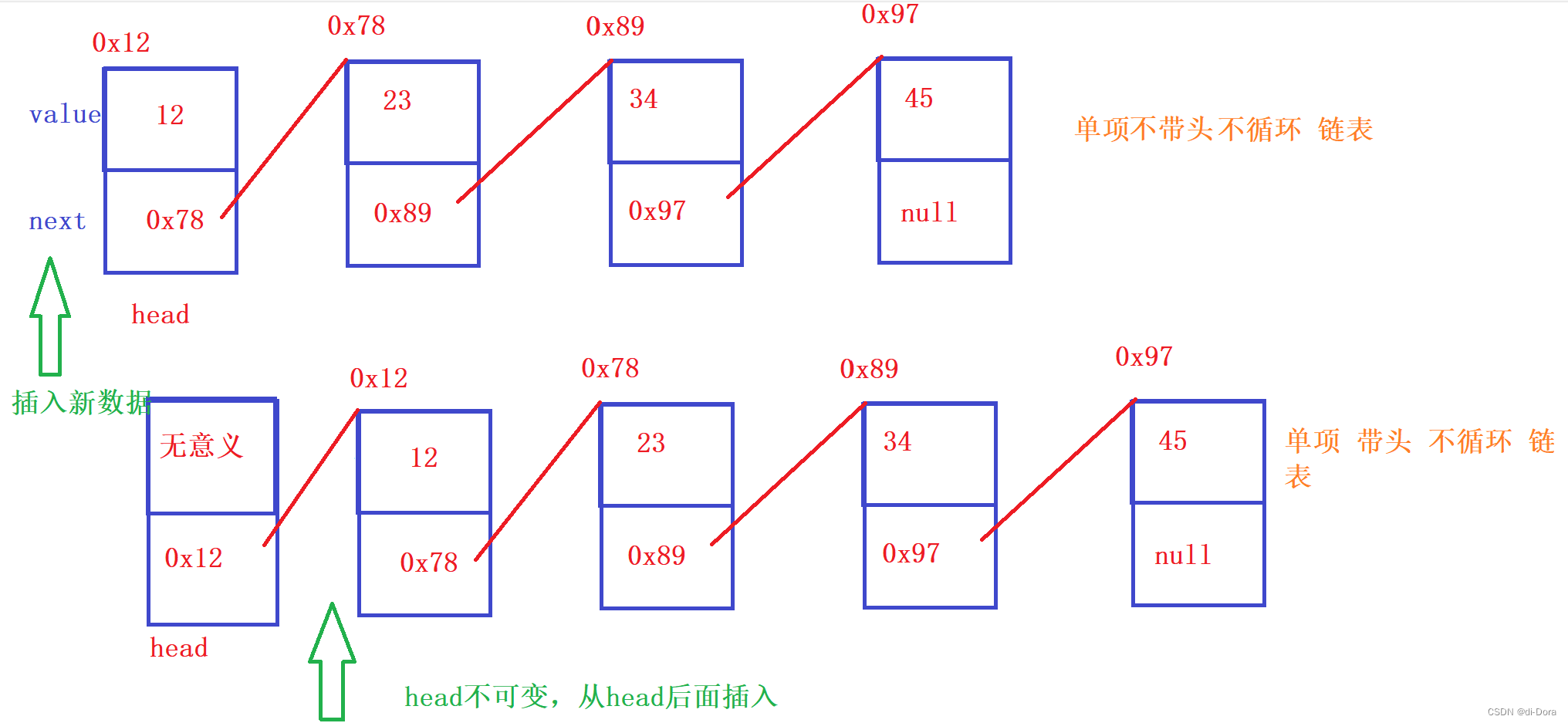
带头节点的链表在第一个节点之前有一个额外的头节点,用于标识链表的起始位置。(head的value是无意义的,如果想从最开头插入数据时,head是不可变的,从head后面插入)
而不带头节点的链表则直接以第一个节点作为链表的起始位置。(head是有value的,如果想从最开头插入数据时,head是可变的,变成新插入的数据)
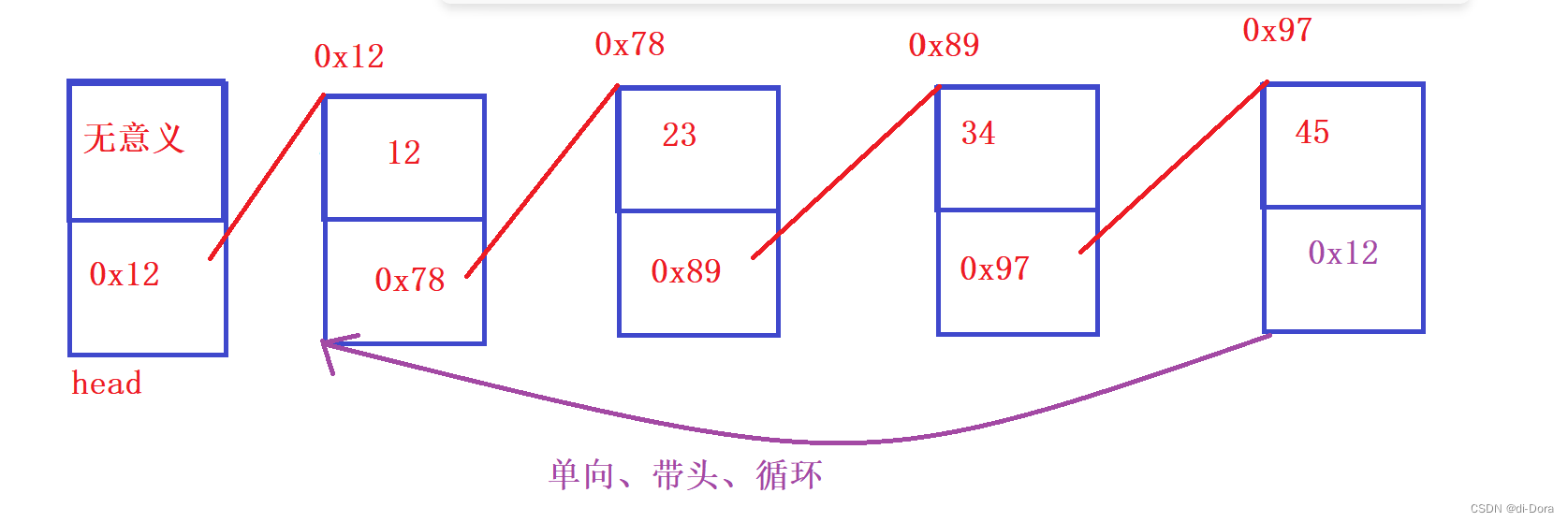
3、是否循环:
循环链表是在链表的尾部节点和头部节点之间形成一个循环连接,使得链表的最后一个节点指向头部节点。
综合考虑上述两个方面,我们可以得到链表的组合方式共有8种:
单向、不带头节点、非循环链表(重点)
单向、不带头节点、循环链表
单向、带头节点、非循环链表
单向、带头节点、循环链表
双向、不带头节点、非循环链表(重点)
双向、不带头节点、循环链表
双向、带头节点、非循环链表
双向、带头节点、循环链表
每种组合方式都有自己的特点和应用场景,我们可以根据具体需求选择合适的链表类型。
单向、不带头、非循环链表的实现
我们可以先来实现一个最简易的链表,即手动创建一个单向链表:
public class MySingleList {
static class ListNode {
public int val; // 节点的值域
public ListNode next; // 下一个节点的地址
public ListNode(int val) {
this.val = val;
}
}
public ListNode head; // 表示当前链表的头节点
//我们先来写一个最笨的方法:手动创建链表节点
public void createlist() {
// 创建链表节点
head = new MySingleList.ListNode(-1);
MySingleList.ListNode node1 = new MySingleList.ListNode(12);
MySingleList.ListNode node2 = new MySingleList.ListNode(23);
MySingleList.ListNode node3 = new MySingleList.ListNode(34);
MySingleList.ListNode node4 = new MySingleList.ListNode(45);
MySingleList.ListNode node5 = new MySingleList.ListNode(56);
// 构建链表关系
node1.next = node2;
node2.next = node3;
node3.next = node4;
node4.next = node5;
this.head = node1;//head 是一个指向第一个节点的引用
}
}public class Test {
public static void main(String[] args) {
MySingleList list = new MySingleList();
list.createlist();
System.out.println(list);
System.out.println("12345");
}
}通过这个代码,我们可以直观地观察到链表的大致结构:
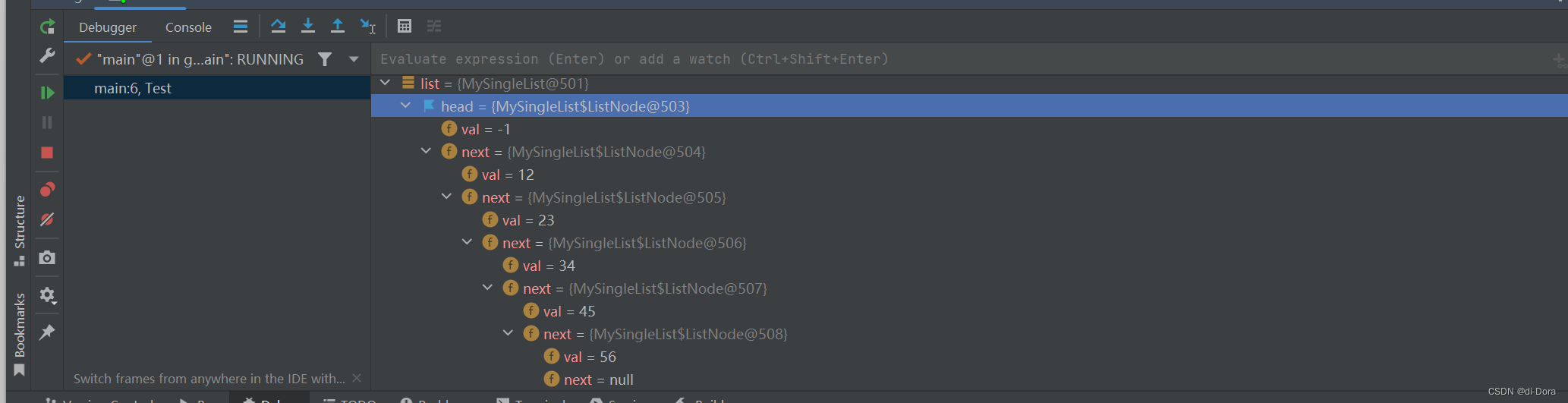
好了,现在我们就正式开始实现一个完整的单向链表了:
首先我们还是先给出链表的基本代码:
我们先要有一个引用 head 指向第一个节点,它是“节点”类型,就如同 Person person = new Person; 一样。
链表的头节点,是链表的成员变量、链表的属性,而不是一个节点类的成员变量。
public class MySingleList {
static class ListNode {
public int val; // 节点的值域
public ListNode next; // 下一个节点的地址
public ListNode(int val) {
this.val = val;
}
}
public ListNode head; // 表示当前链表的头节点
// 在链表头部插入节点
public void insertAtHead(int val)
// 在链表尾部插入节点
public void insertAtTail(int val)
//得到单链表的长度
public int size()
//查找是否包含关键字key是否在单链表当中
public boolean contains(int key)
//删除第一次出现关键字为key的节点
public void deleteNode(int key)
// 删除所有值为key的节点
public void removeAllKey(int key)
//任意位置插入,第一个数据节点为0号下标
public void insertAtIndex(int index, int val)
// 遍历链表并打印节点值
public void display()
// 清空链表
public void clear()
}以上都是我们需要实现的方法。
先来实现第一个:
遍历链表并打印节点值:
// 遍历链表并打印节点值
public void display() {
//不可以让head本身移动,否则将遗失head的位置
ListNode curr = head;
while (curr != null) {
System.out.print(curr.val + " ");
curr = curr.next; //引用向后移动一位
}
System.out.println();
}
这里我们要注意:curr 是一个引用!!!
curr = null 代表的是已经遍历了整个链表。
在链表头部插入节点:
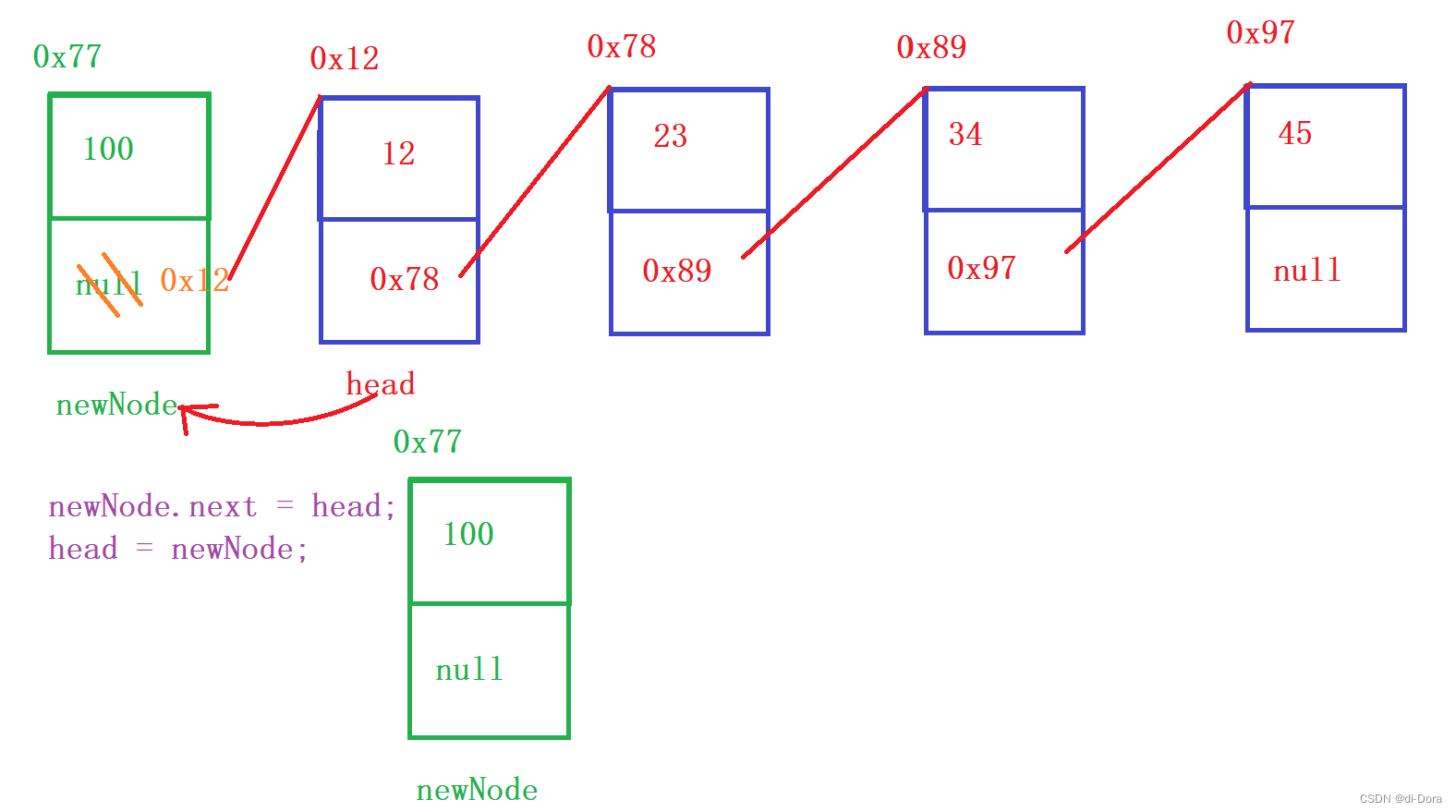
// 在链表头部插入节点
//一般建议,再插入的时候,先绑定后面的节点信息
//就算链表中一个代码都没有,也不影响我们插入节点
//以头插法插入,数据是倒序的
public void insertAtHead(int val) {
ListNode newNode = new ListNode(val);
newNode.next = head;
head = newNode;
} public static void main(String[] args) {
MySingleList list = new MySingleList();
//list.createlist();
list.insertAtHead(12);
list.insertAtHead(23);
list.insertAtHead(34);
list.insertAtHead(45);
list.insertAtHead(56);
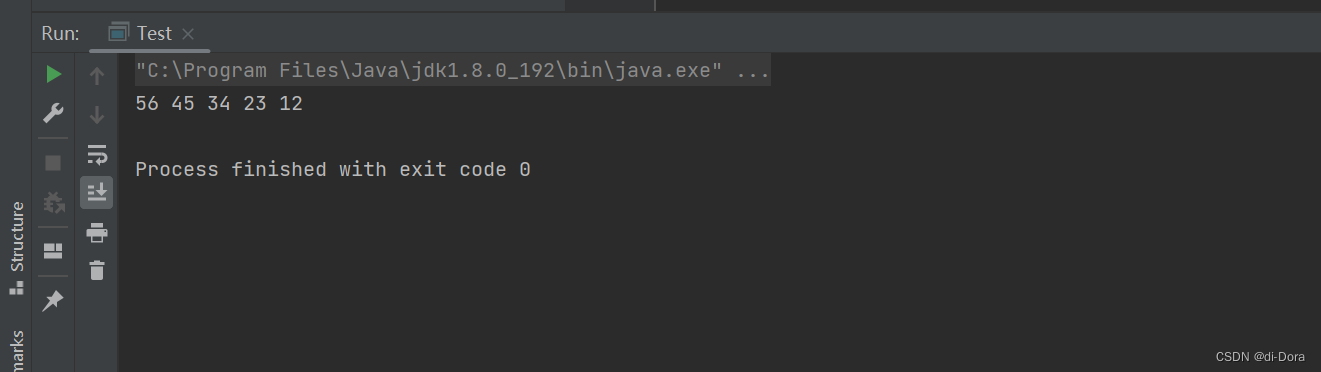
list.display();
}注意:以头插法插入,数据是倒序的:
在链表尾部插入节点:
// 在链表尾部插入节点
public void insertAtTail(int val) {
ListNode newNode = new ListNode(val);
//cur = null 代表把链表的每一个节点都遍历完了
//cur.next = null 代表cur现在是最后一个节的位置
//一定要写,否则会报:空指针异常
//如果head等于null,curr也就等于null,就不存在curr.next
if (head == null) {
head = newNode;
} else {
ListNode curr = head;
while (curr.next != null) {
curr = curr.next;
}
curr.next = newNode;
}
}
注意区分:
curr = null 表示当前节点 curr 引用已经指向了链表的末尾,即已经遍历完了链表的所有节点。在这种情况下,可以用来判断是否已经遍历到了链表的末尾。
curr.next = null 表示当前节点 curr 的下一个节点指针指向 null,即当前节点 curr 是链表中的最后一个节点。这通常用于在遍历链表时进行判断,以确定是否已经到达了链表的末尾节点。
得到单链表的长度 :
//得到单链表的长度
public int size() {
int length = 0;
ListNode curr = head;
while (curr != null) {
length++;
curr = curr.next;
}
return length;
}查找是否包含关键字key是否在单链表当中:
//查找是否包含关键字key是否在单链表当中
public boolean contains(int key) {
ListNode curr = head;
while (curr != null) {
if (curr.val == key) {
return true;
}
curr = curr.next;
}
return false;
}删除第一次出现关键字为key的节点 (两种实现方式):
找到你要删除的节点的前驱,用 del = curr.next;进行删除:curr.next = del.next;
//删除第一次出现关键字为key的节点
//找到指定删除的节点的前一个节点,即找到key的前驱
public void deleteNode(int key) {
if (head == null) {
System.out.println("当前链表无数据");
return;
}
//单独删除头节点
if (head.val == key) {
head = head.next;
return;
}
ListNode curr = head;
//如果 curr.next = null ,表示已经没有下一个节点了
while (curr.next != null) {
if (curr.next.val == key) {
curr.next = curr.next.next;
return;
}
//curr 后移,继续往后寻找
curr = curr.next;
}
}
//删除第一次出现关键字为key的节点 -------第2种方法
public void remove(int key){
if(head == null) {
System.out.println("当前链表无数据");
return;
}
//单独删除头节点
if(head.val == key) {
head = head.next;
return;
}
ListNode cur = searchPrev(key);
if(cur == null) {
System.out.println("没有你要删除的数字");
return;
}
ListNode del = cur.next;
cur.next = del.next;
}
private ListNode searchPrev(int key) {
ListNode cur = head;
while (cur.next != null) {
if(cur.next.val == key) {
return cur;
}
cur = cur.next;
}
return null;
}删除所有值为key的节点:
// 删除所有值为key的节点
public void removeAllKey(int key) {
ListNode dummy = new ListNode(0); // 创建一个虚拟头节点,方便处理头节点的情况
dummy.next = head;
ListNode prev = dummy;
ListNode curr = head;
while (curr != null) {
if (curr.val == key) {
prev.next = curr.next;
} else {
prev = curr;
}
curr = curr.next;
}
head = dummy.next;
}指定任意位置插入数据:
定义一个引用 curr,让它走到即将插入位置的前一个位置,这样我们可以同时访问到插入位置前和插入位置后的节点。先把 curr.next 赋值给newNode.next ,即新插入节点的指向原来位于插入位置的节点,再把 curr.next 变成 newNode 的值。
往 0 位置插入,相当于头插法,往结尾插入,相当于尾插法。
//任意位置插入,第一个数据节点为0号下标
public void insertAtIndex(int index, int val) {
if (index < 0 || index > size()) {
throw new IndexOutOfBoundsException("Invalid index: " + index);
}
if (index == 0) {
insertAtHead(val);
return;
}
if(index==size()){
insertAtTail(val);
return;
}
ListNode newNode = new ListNode(val);
ListNode curr = head;
int count = 0;//定义一个计数器
while (curr != null && count < index - 1) {
curr = curr.next;
count++;
}
if (curr == null) {
throw new IndexOutOfBoundsException("Invalid index: " + index);
}
newNode.next = curr.next;
curr.next = newNode;
}或者,你也可以单独封装出去一个方法:
private ListNode findIndexSubOne(int index){
ListNode curr=head;
while (index-1!=0){
curr=curr.next;
index--;
}
return curr;
}清空链表:
// 清空链表
public void clear() {
head = null;
}最后可以测试了看看:
public class Test {
public static void main(String[] args) {
MySingleList list = new MySingleList();
//list.createlist();
list.insertAtHead(12);
list.insertAtHead(23);
list.insertAtHead(34);
list.insertAtHead(45);
list.insertAtHead(56);
list.display();
list.insertAtTail(666);
list.display();
list.deleteNode(12);
list.display();
list.insertAtTail(23);
list.insertAtTail(34);
list.insertAtTail(45);
list.insertAtTail(23);
list.display();
list.removeAllKey(23);
list.display();
list.insertAtIndex(2,99999);
list.display();
list.insertAtIndex(5,188);
list.display();
int lengh=list.size();
System.out.println(lengh);
}
}链表的优缺点
链表相比于数组具有以下特点和优势:
- 动态性:链表的长度可以根据需要动态地增长或缩小,不需要预先定义大小。
- 插入和删除操作效率高:由于链表的节点之间通过指针连接,插入和删除节点的操作只需要改变指针的指向,时间复杂度为O(1)。
- 空间利用效率高:链表节点在内存中分散存储,不需要连续的内存空间,可以更灵活地利用内存。
- 链表长度没有固定限制:链表的长度可以根据需要动态调整,不受固定大小的限制。
然而,链表也有一些缺点:
访问效率较低:链表中的节点不是连续存储的,访问特定位置的节点需要从头节点开始遍历,时间复杂度为O(n),其中n为链表长度。
额外的存储空间:链表中的每个节点都需要额外的指针来指向下一个节点(以及前一个节点,对于双向链表),因此需要额外的存储空间。
综上,链表适用于需要频繁插入和删除节点的场景,而不太关注访问效率。我们还是需要根据具体的应用场景和需求,选择合适的数据结构(如数组或链表),这是很重要的。







![[人工智能原理]](https://img-blog.csdnimg.cn/5f82dbfdc1ce443f87af171c2b5651a8.png)