1、日志收集场景分析与说明
对于那些能够将日志输出到本地文件的Pod,我们可以使用Sidecar模式方式运行一个日志采集Agent,对其进行单独收集日志
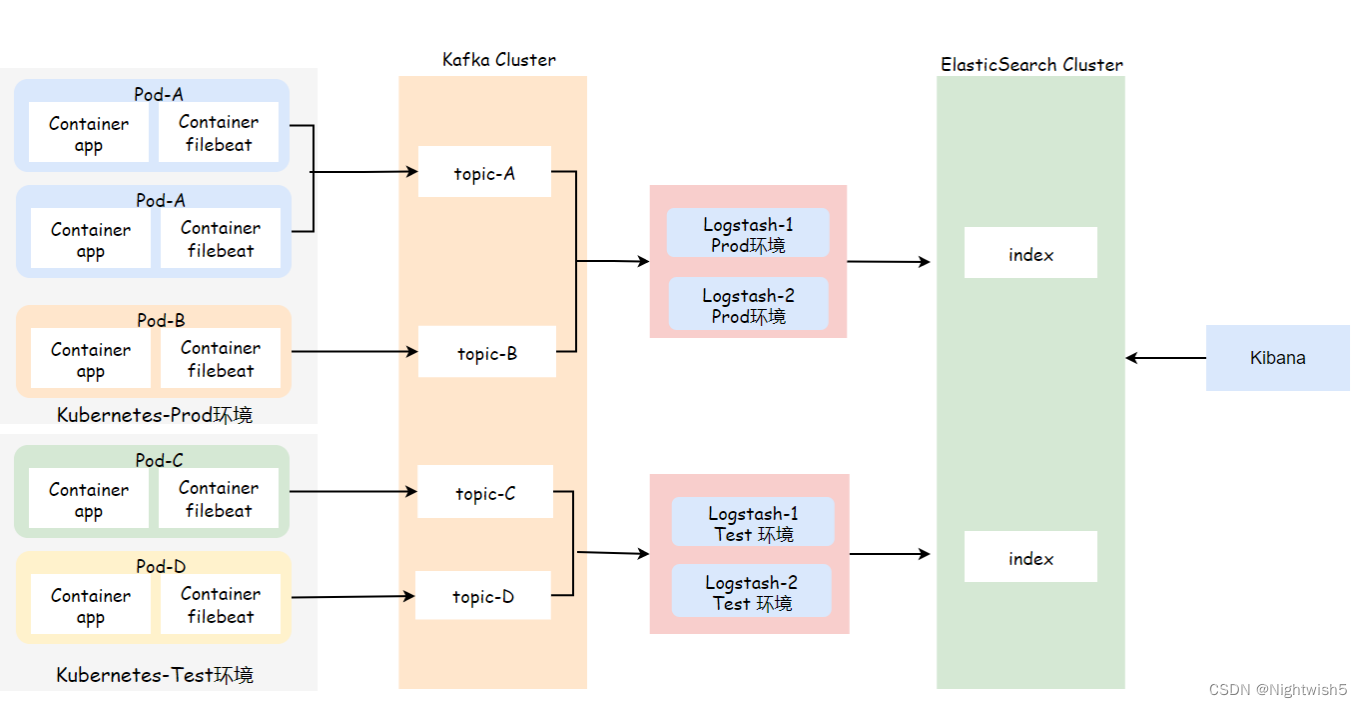
1、首先需要将Pod中的业务容器日志输出至本地文件,而后运行一个Filebeat边车容器,采集本地路径下的日志;
2、Filebeat容器需要传递如下变量;环境:了解Pod属于隶属于哪个环境;项目名称:为了后期能在单个索引中区分出不同的项目;
podip:为了让用户清楚该Pod属于哪个IP;
3、Logstash根据不同的环境,拉取不同的topic数据,然后将数据存储至ES对应的索引中;
4、Kibana添加不同环境的 index pattern,而后选择对应环境 不同的项目 进行日志探索与展示;
Sidecar部署思路
1、制作一个业务镜像,要求镜像输出日志至本地;
2、制作Filebeat镜像,配置Input、output等信息;
3、采用边车模式运行不同环境的Pod,确保日志信息能输出至Kafka集群;
4、准备不同环境下Logstash配置文件,而后读取数据写入ES集群;
5、使用kibana添加索引,进行日志探索与展示;
2、制作Tomcat业务镜像
下载tomcat包
wget https://dlcdn.apache.org/tomcat/tomcat-10/v10.0.27/bin/apache-tomcat-10.0.27.tar.gz --no-check-certificate
#wget https://dlcdn.apache.org/tomcat/tomcat-10/v10.1.8/bin/apache-tomcat-10.1.8.tar.gz --no-check-certificate
[root@master01 tomcatImage]# ls
apache-tomcat-10.0.27.tar.gz
编写Dockerfile
FROM openjdk:8-jre
RUN /bin/cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && \
echo 'Asia/Shanghai' > /etc/timezone
ENV VERSION=10.1.8
ADD ./apache-tomcat-${VERSION}.tar.gz /app
RUN mv /app/apache-tomcat-${VERSION} /app/tomcat && \
rm -f /app/apache-tomcat-${VERSION}.tar.gz
ADD ./entrypoint.sh /entrypoint.sh
RUN chmod +x /entrypoint.sh
EXPOSE 8080
CMD ["/bin/bash","-c","/entrypoint.sh"]
编写entrypoint.sh
# entrypoint.sh
# 启动tomcat方法,并且将日志打到对应的文件中
# 异常是多行的; 这里测试将tomcat jvm调整到20m 不断访问 就会抛出异常 OOM;
OPTS="-Xms${JVM_XMS:-25m} -Xmx${JVM_XMX:-25m} -XX:+UseConcMarkSweepGC"
sed -i "2a JAVA_OPTS=\"${OPTS}\"" /app/tomcat/bin/catalina.sh
cd /app/tomcat/bin && \
./catalina.sh run &>>/app/tomcat/logs/stdout.log
编写entrypoint.sh
# 启动tomcat方法,并且将日志打到对应的文件中
# 异常是多行的; 这里测试将tomcat jvm调整到20m 不断访问 就会抛出异常 OOM;
OPTS="-Xms${JVM_XMS:-25m} -Xmx${JVM_XMX:-25m} -XX:+UseConcMarkSweepGC"
sed -i "2a JAVA_OPTS=\"${OPTS}\"" /app/tomcat/bin/catalina.sh
cd /app/tomcat/bin && \
./catalina.sh run &>>/app/tomcat/logs/stdout.log
构建镜像并推送仓库
[root@master01 tomcatImage]# ls
apache-tomcat-10.1.8.tar.gz Dockerfile entrypoint.sh
docker build -t harbor.oldxu.net/base/tomcat:10.1.8_with_log .
docker push harbor.oldxu.net/base/tomcat:10.1.8_with_log
3.制作Filebeat镜像
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.17.6-x86_64.rpm
Dockerfile
FROM centos:7
RUN /bin/cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && \
echo 'Asia/Shanghai' > /etc/timezone
#拷贝filebeat 和 拷贝filebeat配置文件(核心)
ENV VERSION=7.17.6
ADD ./filebeat-${VERSION}-x86_64.rpm /
RUN rpm -ivh /filebeat-${VERSION}-x86_64.rpm && \
rm -f /filebeat-${VERSION}-x86_64.rpm
ADD ./filebeat.yml /etc/filebeat/filebeat.yml
ADD ./entrypoint.sh /entrypoint.sh
RUN chmod +x /entrypoint.sh
CMD ["/bin/bash","-c","/entrypoint.sh"]
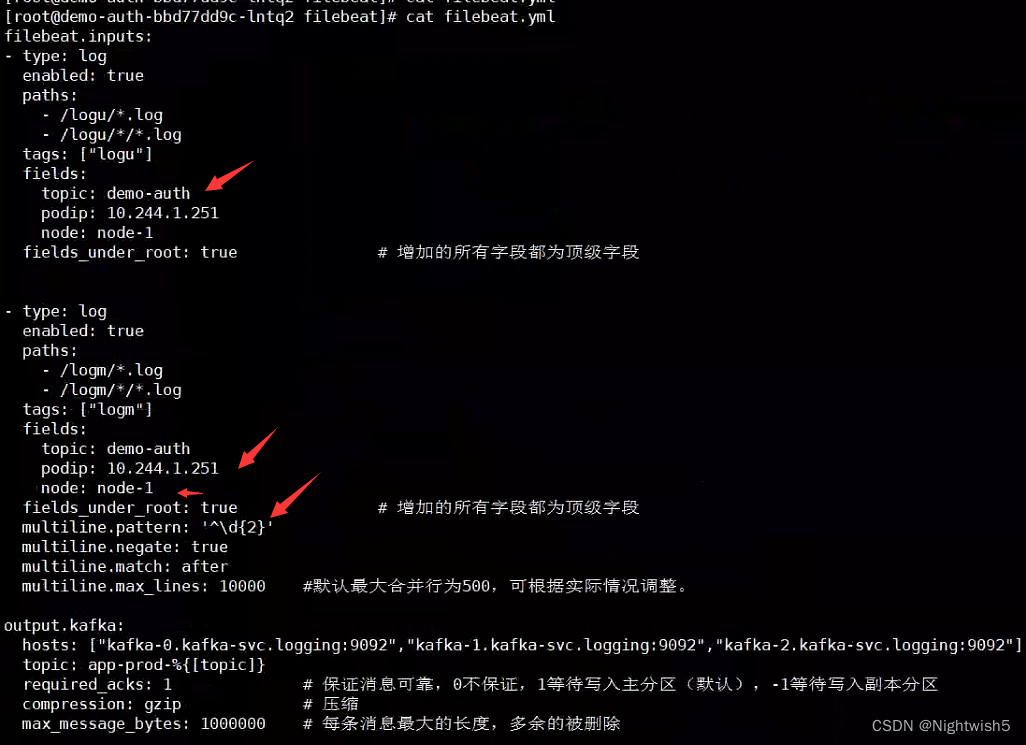
编写filebeat配置
{ENV} :用于定义环境的变量;
{PROJECT_NAME} :用于定义项目名称的变量;
{MULTILINE} :用于定义多行合并的正则变量;
{KAFKA_HOSTS} :用于定义KAFKA集群地址的变量;
{PodIP} :用于获取该Pod地址的变量;
{Node} :用于获取该Pod所处的节点;
filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /logu/*.log
- /logu/*/*.log
tags: ["logu"]
fields:
topic: {PROJECT_NAME}
podip: {PodIP}
node: {Node}
fields_under_root: true # 增加的所有字段都为顶级字段
- type: log
enabled: true
paths:
- /logm/*.log
- /logm/*/*.log
tags: ["logm"]
fields:
topic: {PROJECT_NAME}
podip: {PodIP}
node: {Node}
fields_under_root: true # 增加的所有字段都为顶级字段
multiline.pattern: '{MULTILINE}'
multiline.negate: true
multiline.match: after
multiline.max_lines: 10000 #默认最大合并行为500,可根据实际情况调整。
output.kafka:
hosts: [{KAFKA_HOSTS}]
topic: app-{ENV}-%{[topic]}
required_acks: 1 # 保证消息可靠,0不保证,1等待写入主分区(默认),-1等待写入副本分区
compression: gzip # 压缩
max_message_bytes: 1000000 # 每条消息最大的长度,多余的被删除
entrypoint.sh
#1、替换filbeat配置文件中的内容
Beat_Conf=/etc/filebeat/filebeat.yml
sed -i s@{ENV}@${ENV:-test}@g ${Beat_Conf}
sed -i s@{PodIP}@${PodIP:-"no-ip"}@g ${Beat_Conf}
sed -i s@{Node}@${Node:-"none"}@g ${Beat_Conf}
sed -i s@{PROJECT_NAME}@${PROJECT_NAME:-"no-define"}@g ${Beat_Conf}
sed -i s@{MULTILINE}@${MULTILINE:-"^\\\d{2}"}@g ${Beat_Conf} # \\用来转义
sed -i s@{KAFKA_HOSTS}@${KAFKA_HOSTS}@g ${Beat_Conf}
# 运行filebeat
filebeat -e -c /etc/filebeat/filebeat.yml
制作镜像&推送
[root@master01 filebeatImage]# ls
Dockerfile entrypoint.sh filebeat-7.17.6-x86_64.rpm filebeat.yml
docker build -t harbor.oldxu.net/base/filebeat_sidecar:7.17.6 .
docker push harbor.oldxu.net/base/filebeat_sidecar:7.17.6
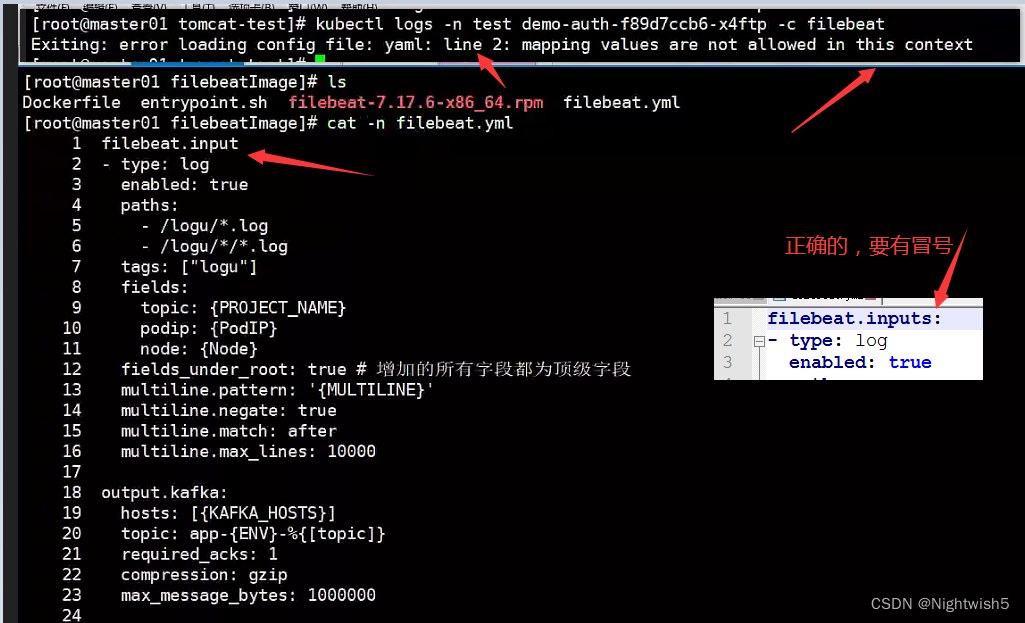
排错:漏写冒号
[root@master01 tomcat-test]# kubectl logs -n test demo-auth-f89d7ccb6-x4ftp -c filebeat
Exiting: error loading config file: yaml: line 2: mapping values are not allowed in this context
4.以边车模式运行Pod
4.1 运行测试环境Pod
4.1.1 创建namespace 和 Secrets
kubectl create namespace test
kubectl create secret docker-registry harbor-admin \
--docker-username=admin \
--docker-password=Harbor12345
--docker-server=harbor.oldxu.net -n test
4.1.2 创建tomcat deployment
demo-auth-test.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: demo-auth
namespace: test
spec:
replicas: 2
selector:
matchLabels:
app: auth
template:
metadata:
labels:
app: auth
spec:
imagePullSecrets:
- name: harbor-admin
volumes:
- name: log
emptyDir: {}
containers:
- name: auth
image: harbor.oldxu.net/base/tomcat:10.0.27_with_log
imagePullPolicy: Always
ports:
- containerPort: 8080
volumeMounts:
- name: log
mountPath: /app/tomcat/logs
livenessProbe: # 存活探针
httpGet:
path: '/index.jsp'
port: 8080
scheme: HTTP
initialDelaySeconds: 10
readinessProbe: # 就绪探针
httpGet:
path: '/index.jsp'
port: 8080
scheme: HTTP
initialDelaySeconds: 10
- name: filebeat
image: harbor.oldxu.net/base/filebeat_sidecar:7.17.6
imagePullPolicy: Always
volumeMounts:
- name: log
mountPath: /logm
env:
- name: ENV
value: "test" # 也可以使用metadata.namespace 具体看业务如何规划
- name: PodIP
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: Node
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: PROJECT_NAME
value: "demo-auth"
- name: KAFKA_HOSTS
value: '"kafka-0.kafka-svc.logging:9092","kafka-1.kafka-svc.logging:9092","kafka-2.kafka-svc.logging:9092"'
4.1.3 创建tomcat svc
apiVersion: v1
kind: Service
metadata:
name: tomcat-svc
namespace: test
spec:
selector:
#app: tomcat
app: auth
ports:
- port: 8080
targetPort: 8080
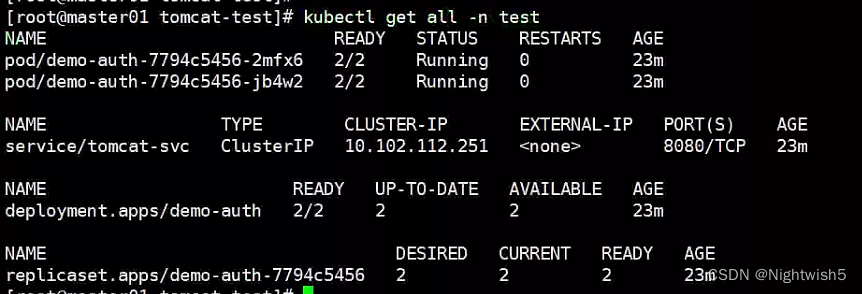
特别说明
这里一个pod运行两个容器,名称分别为: auth和filebeat 。
kubectl logs xxxPodName -n test -c auth
此时是一点日志都没有的。auth的日志在/app/tomcat/logs/stdout.log .
所以要换成看filebeat的logs
kubectl logs xxxPodName -n test -c filebeat
如果启动的pod,状态出现1/2 CrashLoopBackOff ,则去到filebeat容器里面 /logm/查看日志 排查。
#可进入filebeat容器,查看内容是否替换成功。
cat /etc/filebeat/filebeat.yml
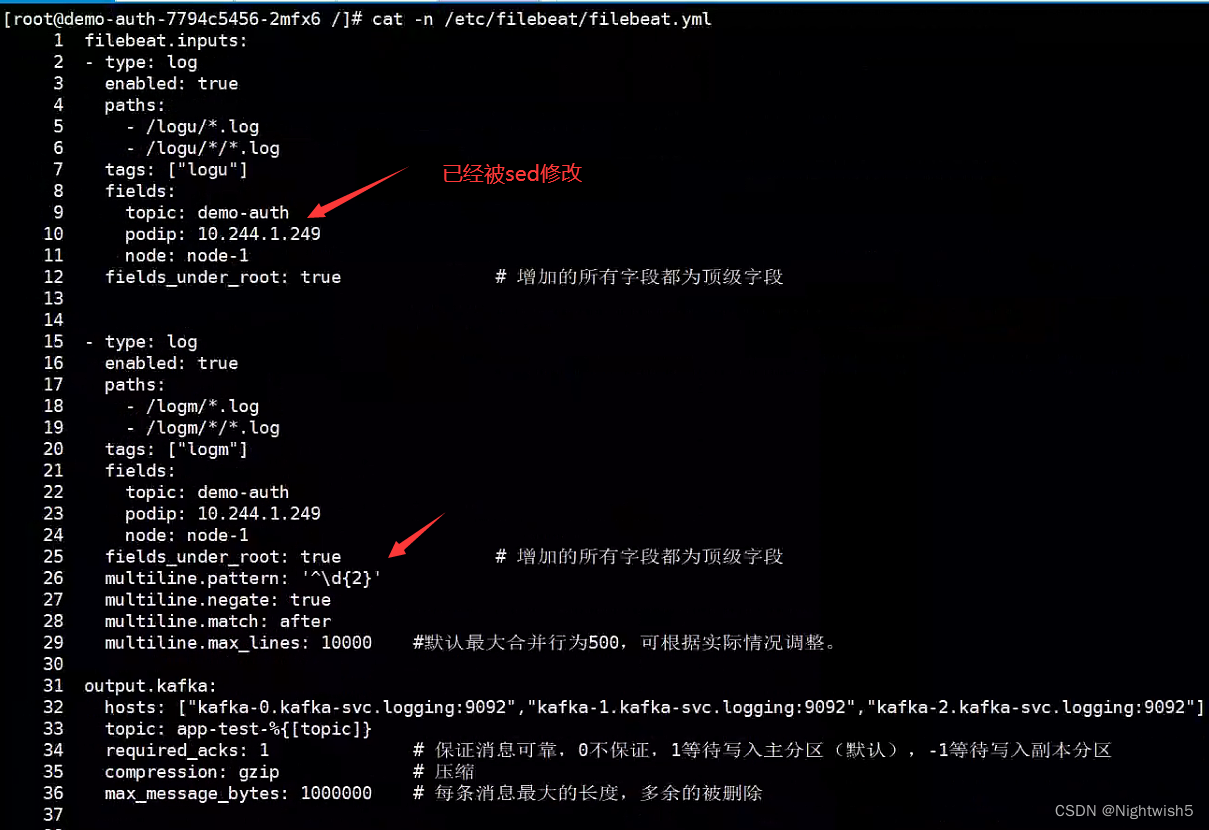


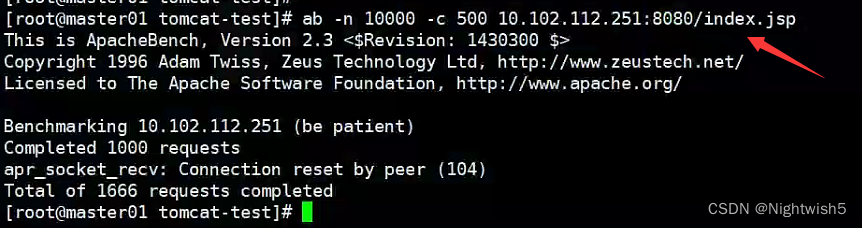
4.1.4 进行压力测试
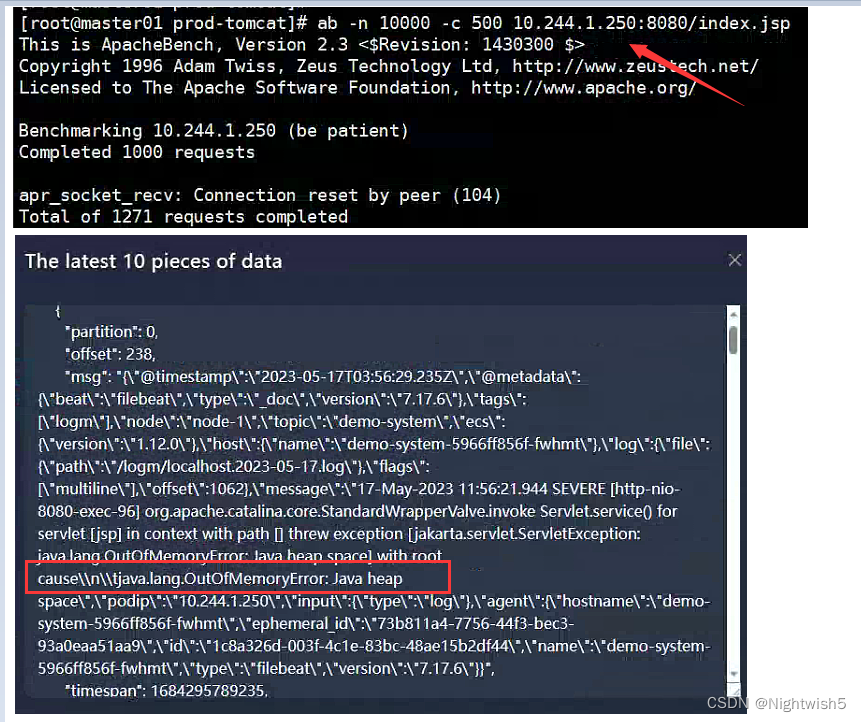
ab -n 10000 -c 500 10.102.112.251:8080/index.jsp
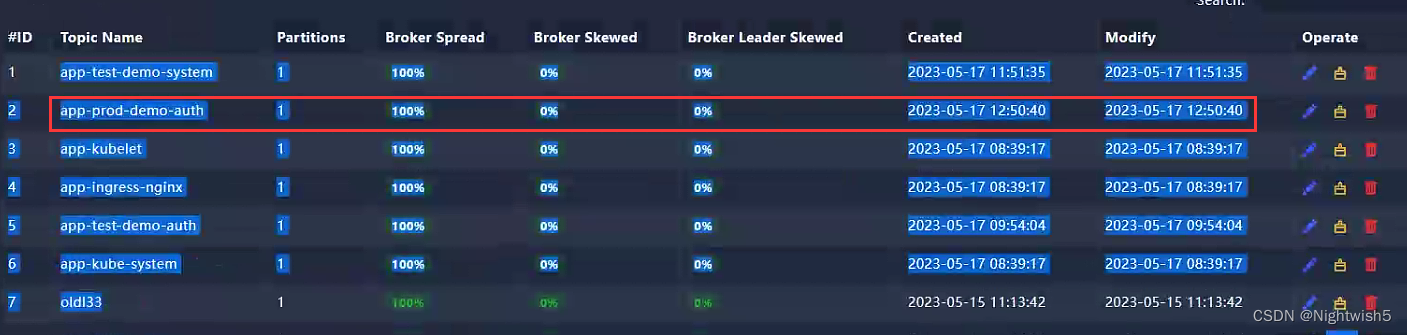
4.1.5 检查KafkaTopic
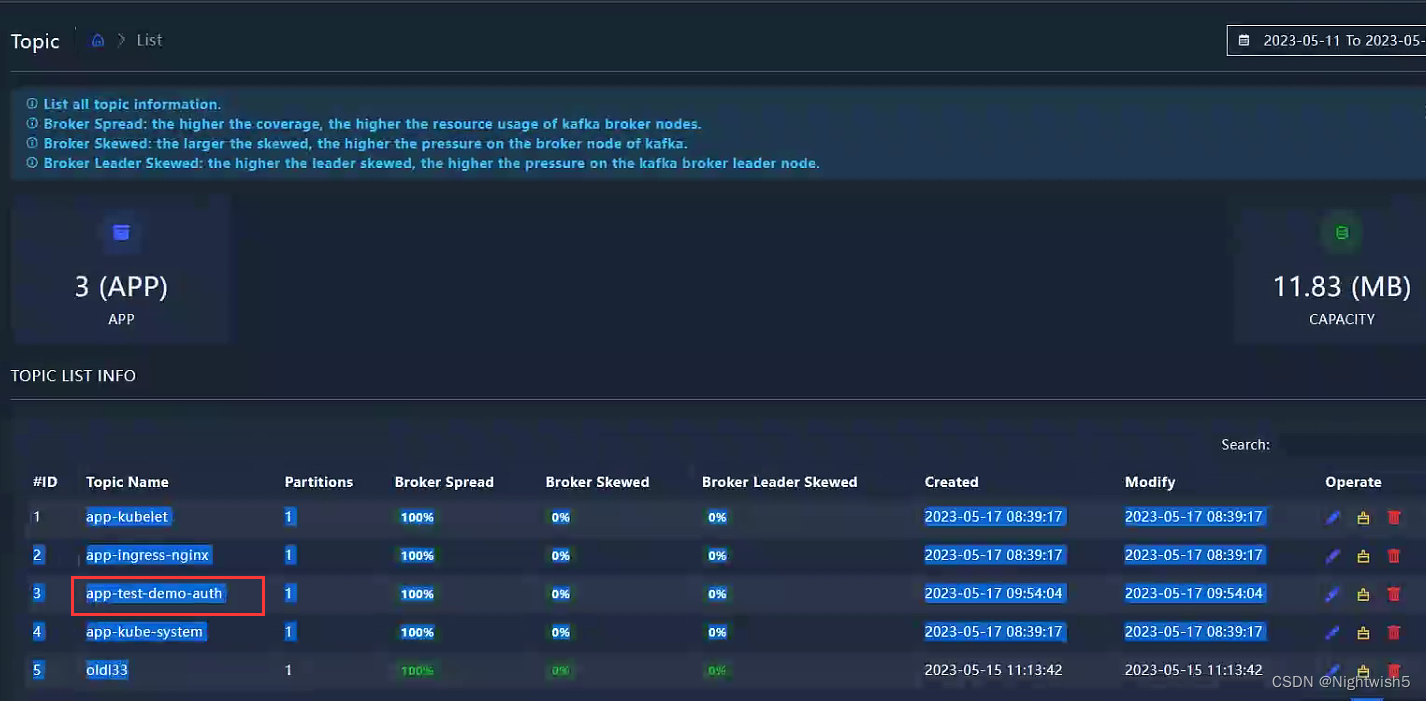
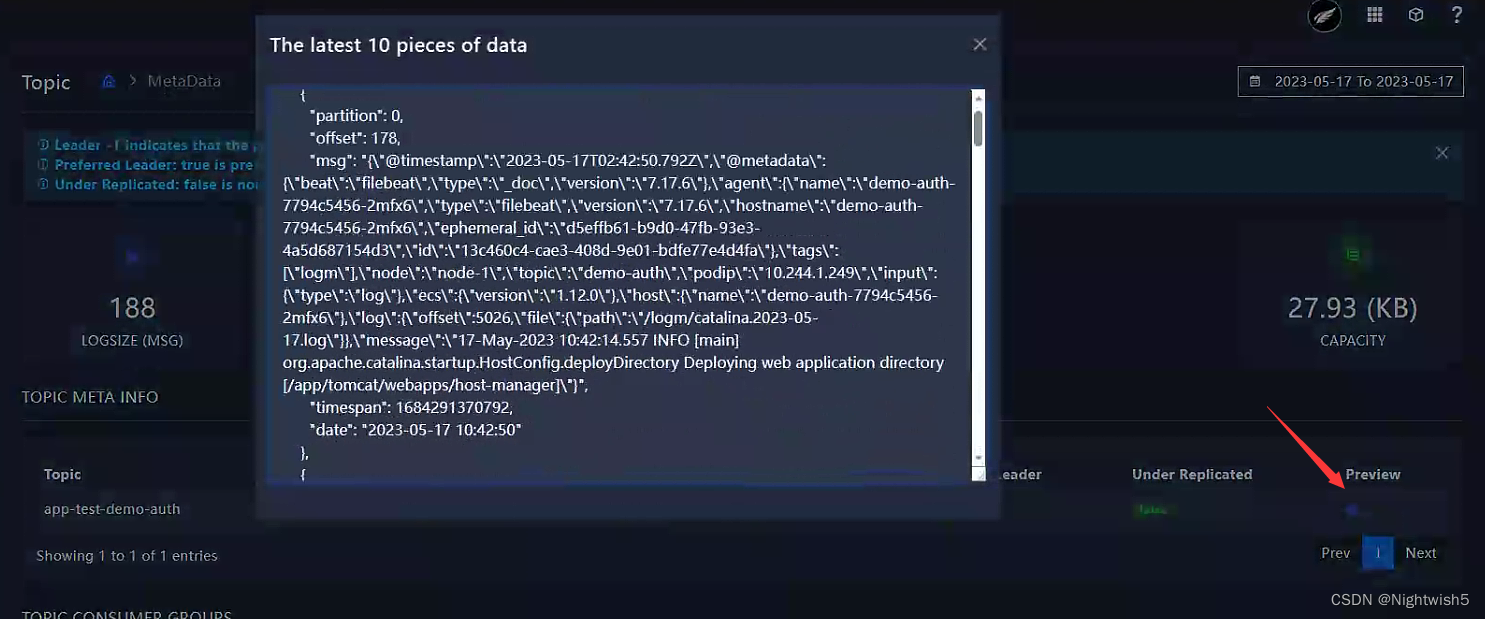
点击“preview” ,查看最近的日志
4.1.6 demo-system-test-dp.yaml
在namespace test,创个新的 demo-system ,看看efak 有没有创建对应的topics
apiVersion: apps/v1
kind: Deployment
metadata:
name: demo-system
namespace: test
spec:
replicas: 2
selector:
matchLabels:
app: system
template:
metadata:
labels:
app: system
spec:
imagePullSecrets:
- name: harbor-admin
volumes:
- name: log
emptyDir: {}
containers:
- name: system
image: harbor.oldxu.net/base/tomcat:10.0.27_with_log
imagePullPolicy: Always
ports:
- containerPort: 8080
volumeMounts:
- name: log
mountPath: /app/tomcat/logs
livenessProbe: # 存活探针
httpGet:
path: '/index.jsp'
port: 8080
scheme: HTTP
initialDelaySeconds: 10
readinessProbe: # 就绪探针
httpGet:
path: '/index.jsp'
port: 8080
scheme: HTTP
initialDelaySeconds: 10
- name: filebeat
image: harbor.oldxu.net/base/filebeat_sidecar:7.17.6
imagePullPolicy: Always
volumeMounts:
- name: log
mountPath: /logm
env:
- name: ENV
value: "test" # 也可以使用metadata.namespace 具体看业务如何规划
- name: PodIP
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: Node
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: PROJECT_NAME
value: "demo-system"
- name: KAFKA_HOSTS
value: '"kafka-0.kafka-svc.logging:9092","kafka-1.kafka-svc.logging:9092","kafka-2.kafka-svc.logging:9092"'
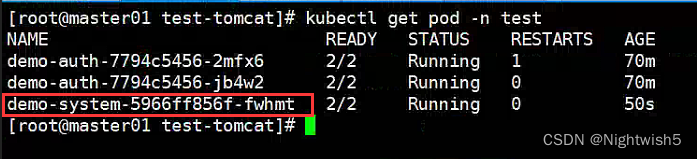
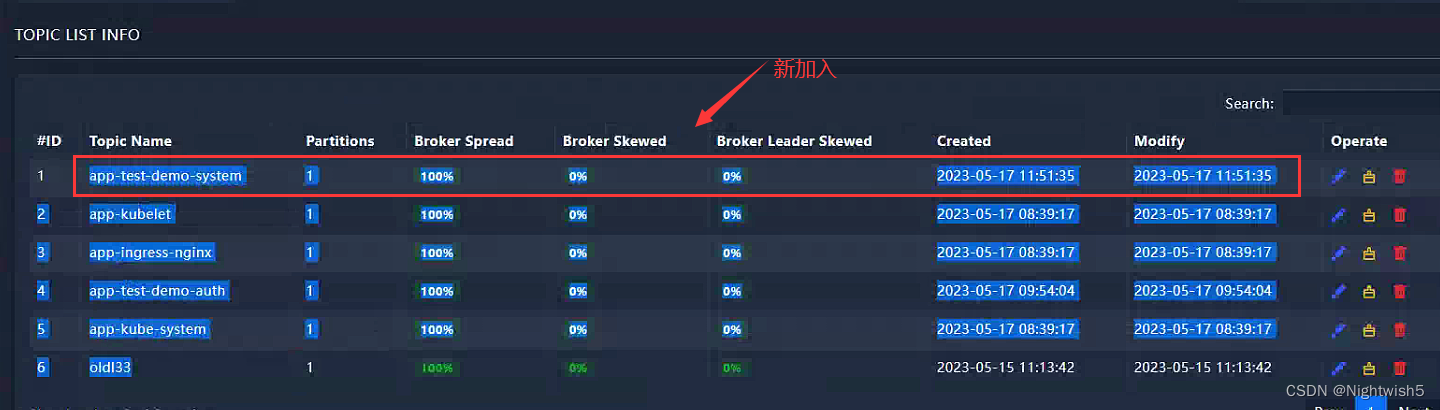
压测这个demo-system
分割线
4.2 运行生产环境Pod (prod)
4.2.1 创建namespace和 Secrets
kubectl create namespace prod
kubectl create secret docker-registry harbor-admin --docker-username=admin --docker-password=Harbor12345 --docker-server=harbor.oldxu.net -n prod
4.2.2 创建tomcat deployment (prod)
apiVersion: apps/v1
kind: Deployment
metadata:
name: demo-auth
namespace: prod
spec:
replicas: 1
selector:
matchLabels:
app: auth
template:
metadata:
labels:
app: auth
spec:
imagePullSecrets:
- name: harbor-admin
volumes:
- name: log
emptyDir: {}
containers:
- name: auth
image: harbor.oldxu.net/base/tomcat:10.0.27_with_log
imagePullPolicy: Always
ports:
- containerPort: 8080
volumeMounts:
- name: log
mountPath: /app/tomcat/logs
livenessProbe:
httpGet:
path: '/index.jsp'
port: 8080
scheme: HTTP
initialDelaySeconds: 10
readinessProbe:
httpGet:
path: '/index.jsp'
port: 8080
scheme: HTTP
initialDelaySeconds: 10
- name: filebeat
image: harbor.oldxu.net/base/filebeat_sidecar:7.17.6
imagePullPolicy: Always
volumeMounts:
- name: log
mountPath: /logm
env:
- name: ENV
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: PodIP
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: Node
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: PROJECT_NAME
value: "demo-auth"
- name: KAFKA_HOSTS
value: '"kafka-0.kafka-svc.logging:9092","kafka-1.kafka-svc.logging:9092","kafka-2.kafka-svc.logging:9092"'
4.2.3 创建service (prod)
apiVersion: v1
kind: Service
metadata:
name: tomcat-svc
namespace: prod
spec:
selector:
app: auth
ports:
- port: 8080
targetPort: 8080
4.2.4 进行压力测试 (prod)
不懂跟不跟压测tomcat有关,压测完后efak也寄了 ,出现nginx 502
4.2.5 检查KafkaTopic (prod)
5.交付测试环境Logstash
5.1 测试环境Logstash配置
1、编写logstash配置
input{
kafka{
bootstrap_servers => "kafka-0.kafka-svc:9092,kafka-1.kafka-svc:9092,kafka-2:kafka-svc:9092"
group_id => "logstash-test" #消费者组名称
consumer_threads => "3"
topics_pattern => "app-test-.*" #通过正则表达式匹配要订阅的主题
}
}
filter {
json {
source => "message"
}
}
output {
stdout{
codec => rubydebug
}
elasticsearch{
hosts => ["es-data-0.es-svc:9200","es-data-1.es-svc:9200"]
index => "app-test-%{+YYYY.MM.dd}" #输出的显示
template_overwrite => true
}
}
5.2 创建测试环境configmap
mkdir conf
kubectl create configmap logstash-test-conf \
--from-file=logstash.conf=conf/logstash-test.conf -n logging
5.3 运行测试环境Logstash (03-logstash-test-sts.yaml)
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: logstash-test
namespace: logging
spec:
serviceName: "logstash-svc"
replicas: 1
selector:
matchLabels:
app: logstash
env: test
template:
metadata:
labels:
app: logstash
env: test
spec:
imagePullSecrets:
- name: harbor-admin
containers:
- name: logstash
image: harbor.oldxu.net/base/logstash-oss:7.17.6
args: ["-f","config/logstash.conf"]
resources:
limits:
memory: 512Mi
env:
- name: PIPELINE_WORKERS
value: "2"
- name: PIPELINE_BATCH_SIZE
value: "10000"
lifecycle:
postStart:
exec:
command:
- "/bin/bash"
- "-c"
- "sed -i -e '/^-Xms/c-Xms512m' -e '/^-Xmx/c-Xmx512m' /usr/share/logstash/config/jvm.options"
volumeMounts:
- name: data
mountPath: /usr/share/logstash/data
- name: conf
mountPath: /usr/share/logstash/config/logstash.conf
subPath: logstash.conf
volumes:
- name: conf
configMap:
name: logstash-test-conf
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: ["ReadWriteMany"]
storageClassName: "nfs"
resources:
requests:
storage: 20Gi
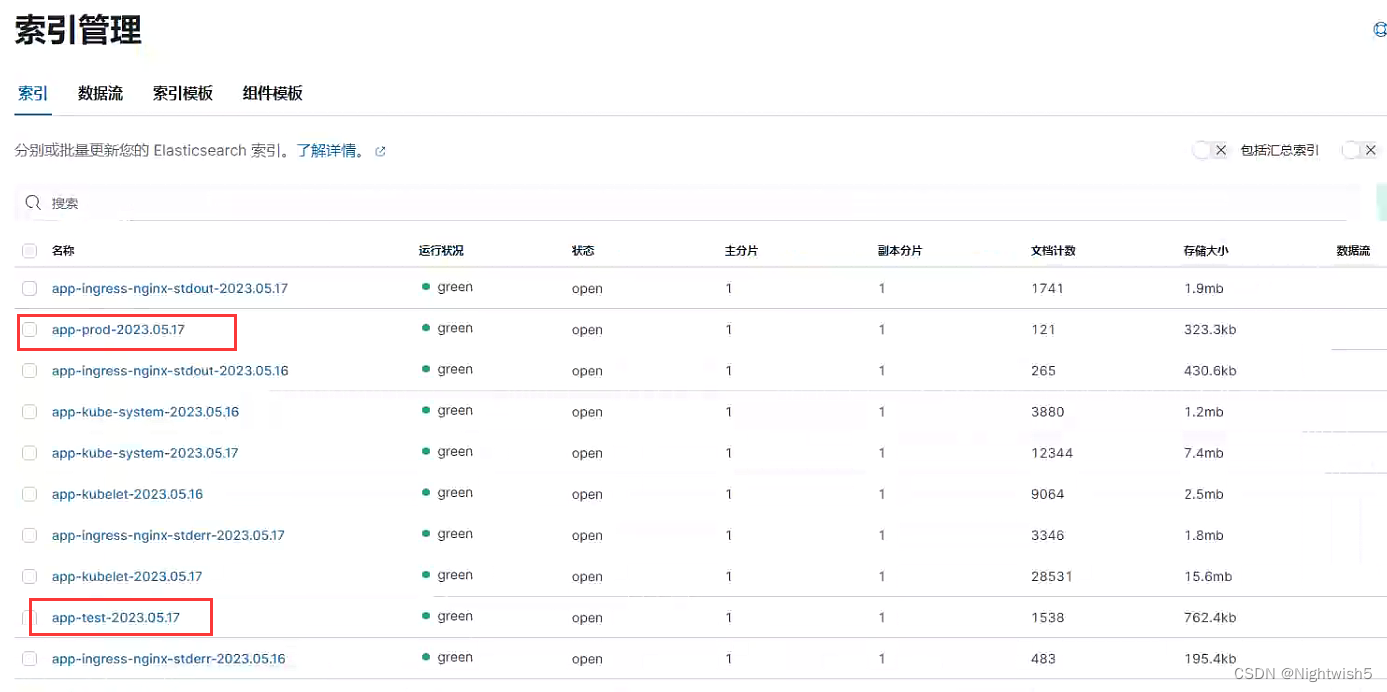
5.4 检查ES测试环境索引
6.交付生产环境Logstash
6.1 生产环境Logstash配置
2、准备 logstash 读取kafka生成环境配置
input {
kafka {
bootstrap_servers => "kafka-0.kafka-svc:9092,kafka-1.kafka-svc:9092,kafka-2.kafka-svc:9092"
group_id => "logstash-prod" # 消费者组名称
consumer_threads => "3" # 理想情况下,配置与分区数一样多的线程,实现均衡
topics_pattern => "app-prod-.*" # 通过正则表达式匹配要订阅的主题
}
}
filter {
json {
source => "message"
}
}
output {
stdout {
codec => rubydebug
}
elasticsearch {
hosts => ["es-data-0.es-svc:9200","es-data-1.es-svc:9200"]
index => "app-prod-%{+YYYY.MM.dd}"
template_overwrite => true
}
}
6.2 创建生产环境configmap
kubectl create
configmap logstash-prod-conf \
--from-file=logstash.conf=conf/logstash-prod.conf -n logging
6.3 运行生产环境Logstash ((03-logstash-prod-sts.yaml))
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: logstash-prod
namespace: logging
spec:
serviceName: "logstash-svc" # 使用此前创建的svc,则无需重复创建
replicas: 2
selector:
matchLabels:
app: logstash
env: prod
template:
metadata:
labels:
app: logstash
env: prod
spec:
imagePullSecrets:
- name: harbor-admin
containers:
- name: logstash
image: harbor.oldxu.net/base/logstash-oss:7.17.6
args: ["-f","config/logstash.conf"] # 启动时指定加载的配置文件
resources:
limits:
memory: 512Mi
env:
- name: PIPELINE_WORKERS
value: "2"
- name: PIPELINE_BATCH_SIZE
value: "10000"
lifecycle:
postStart: # 设定JVM
exec:
command:
- "/bin/bash"
- "-c"
- "sed -i -e '/^-Xms/c-Xms512m' -e '/^-Xmx/c-Xmx512m' /usr/share/logstash/config/jvm.options"
volumeMounts:
- name: data # 持久化数据目录
mountPath: /usr/share/logstash/data
- name: conf
mountPath: /usr/share/logstash/config/logstash.conf
subPath: logstash.conf
volumes:
- name: conf
configMap:
name: logstash-prod-conf
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: ["ReadWriteMany"]
storageClassName: "nfs"
resources:
requests:
storage: 22Gi
6.4 检查ES测试环境索引
推荐使用ab压测 namespace prod的podIP 。 使用手动curl几十次后,这个podIP ,竟然kibana没数据!?
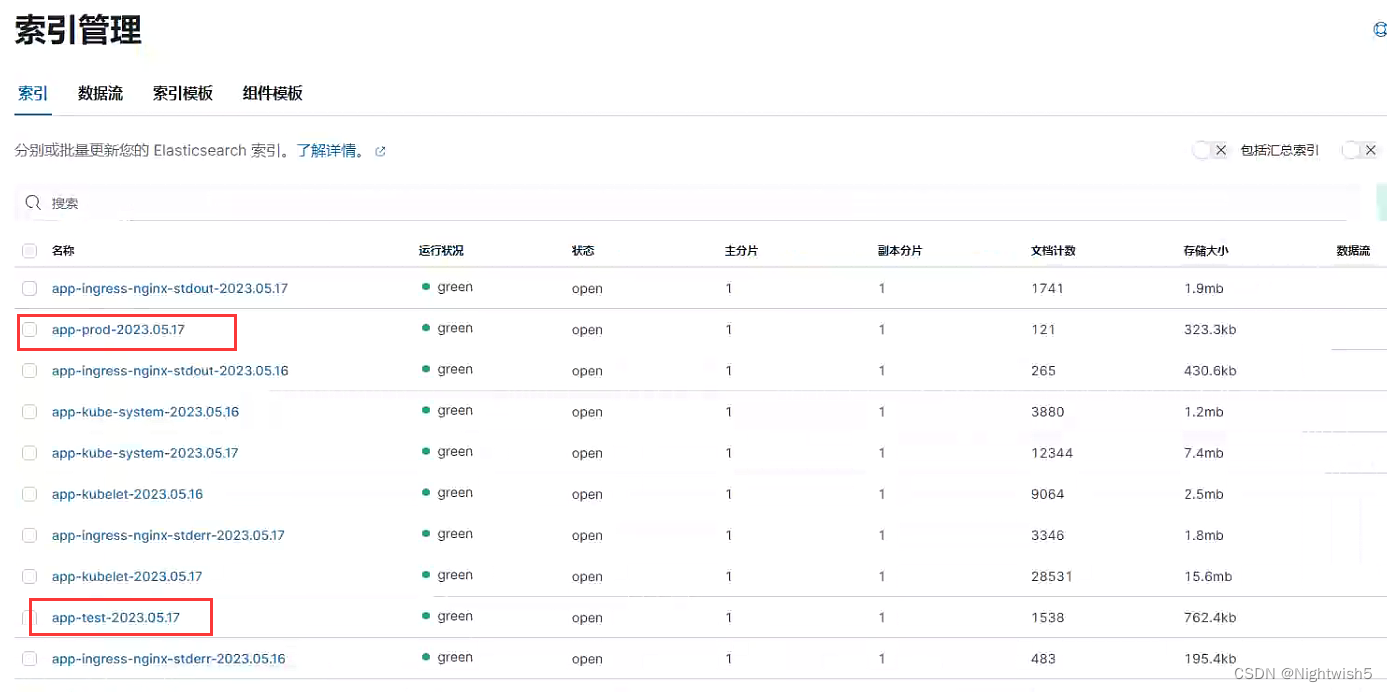
7.Kibana数据展示
7.1 添加索引
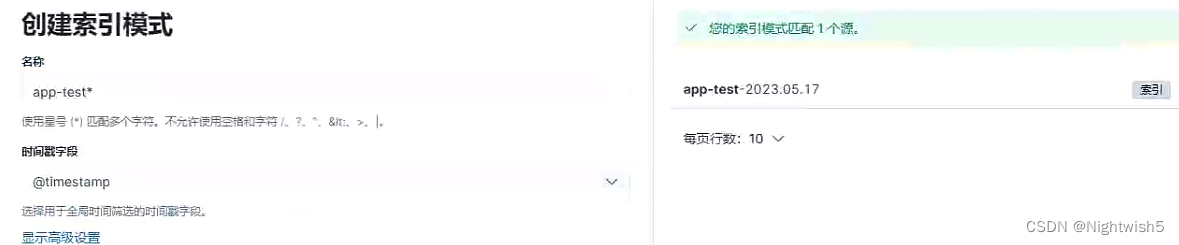
1、添加测试环境索引
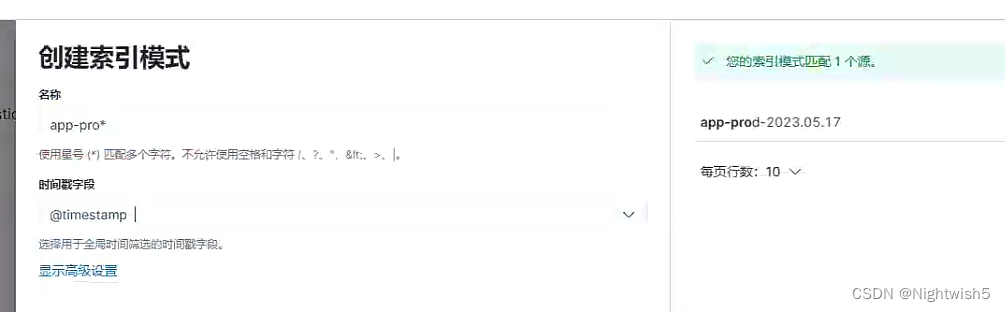
2、添加生产环境索引
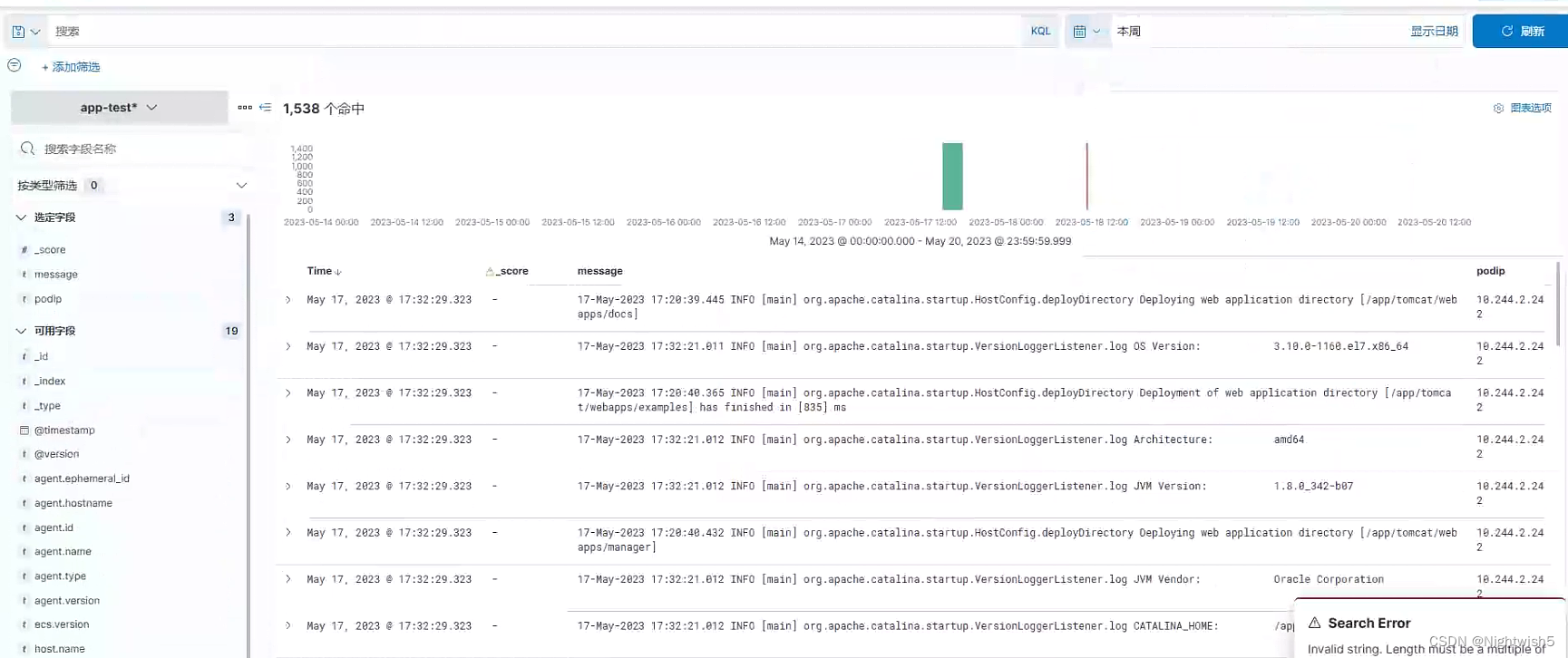
7.2 查看测试环境数据
1、点击测试环境索引
2、选择需要查看的字段
3、进行filter筛选项目
4、选择对应时间段
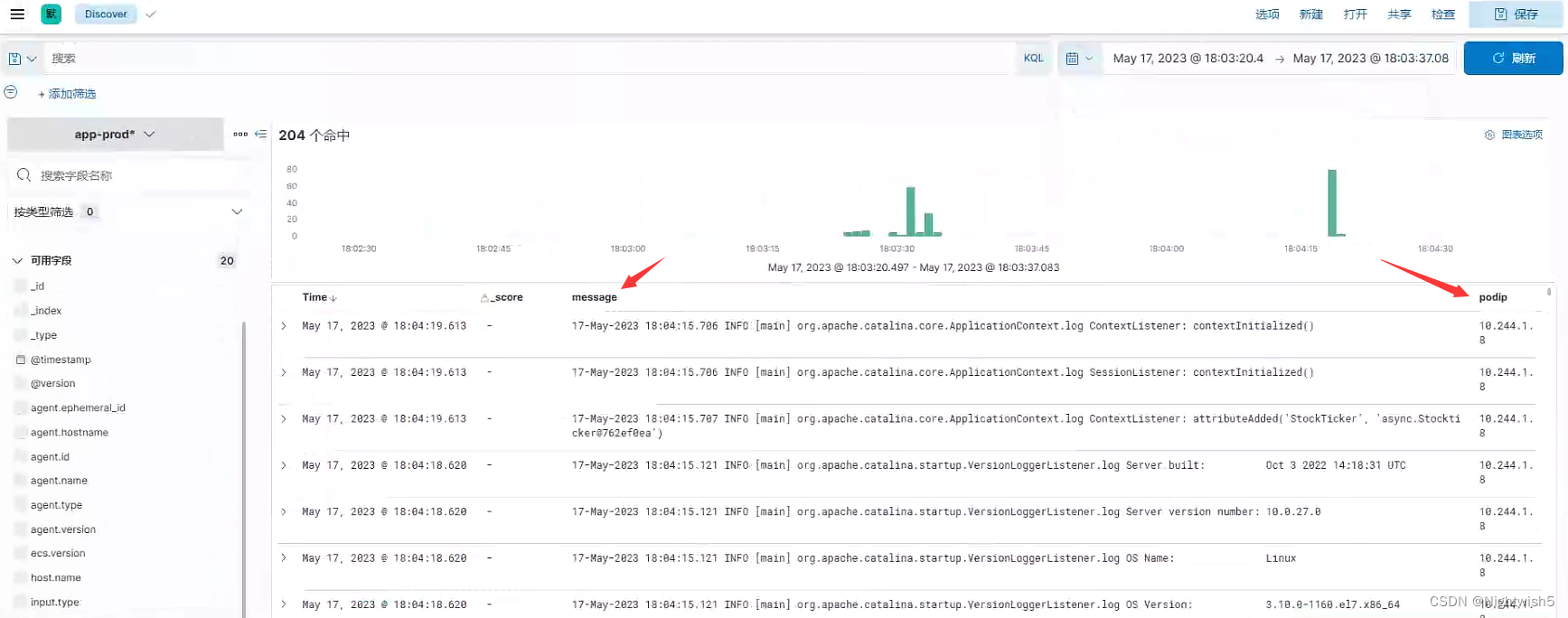
7.3 查看生产环境数据
1、点击测试环境索引
2、选择需要查看的字段
3、进行filter筛选项目
4、选择对应时间段
2023年5月18日11:27:56
END