CSDN官方推出创作助手InsCode AI很多天了,有心人都能发现,在写作界面的右上角多了一个创作助手的浮动按钮,点击后出现如下界面:
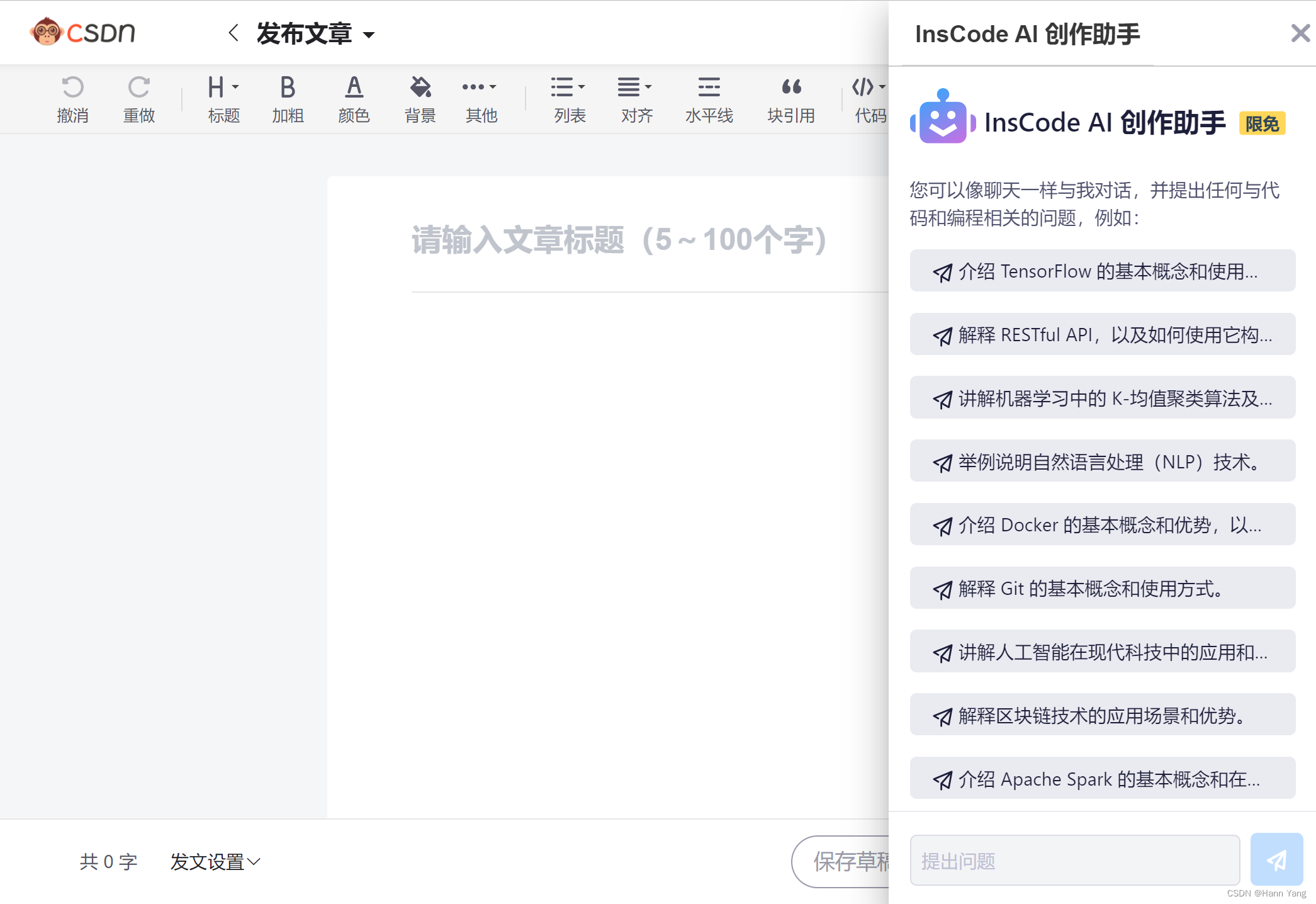
现阶段是“限免”状态,不好好利用它来创作,就有点辜负CSDN官方大佬们的良苦用心了。
以主题“动态规划法”写一篇博客,以下是我用创作助手InsCode AI辅助写作的全过程,教你分分钟搞定一篇“好”文章!
用法简介:
1. 以主题线索列举几个提问,比如“何为动态规划法”、“详细介绍一下动态规划算法”、“写一个动态规划算法并做大量注解”。
2. 把InsCode AI的答案插入写作文本框,整理之后自拟各段文字的多级标题。
3. 最后写段文章小结,插入目录,添加插图美化一下,保存草稿。
快速搞定一篇!正文如下:
目录
动态规划法
定义
条件
步骤
简单实例
题目描述
算法实现
代码实现
进阶实例
题目描述
1. 基于递推的自底向上方法
2. 基于记忆化搜索的自顶向下方法
本文小结
动态规划法

定义
全称为 Dynamic Programming,缩写为DP。是一种常用的解决多阶段决策问题的数学算法。它通常用于求解具有某种最优性质的问题,比如最大值、最小值等等。
动态规划算法通常基于一个递推公式以及一个或多个初始状态。当前子问题的解将由上一次子问题的解推出来。动态规划算法在处理问题时,会把子问题的解缓存起来,这样以后再遇到同样的子问题时可以直接查表而不必重新计算。这种方式可以避免重复计算,减少计算量,提高算法效率。
动态规划算法在求解各种经济、管理、信息、技术等方面的优化问题中有广泛应用。
条件
一般来说,动态规划问题会满足以下几个条件:
-
有重叠子问题:即一个问题的子问题是重复的,需要不断进行重复计算。
-
子问题具有最优子结构:即子问题之间相互独立,且子问题的最优解能够推导出原问题的最优解。
-
无后效性:即某个状态一旦确定,就不受之后决策的影响。
步骤
动态规划(Dynamic Programming)是一种解决多阶段决策过程最优化问题的数学方法,它将原问题分解为相对简单的子问题,并采用递推的方式求解子问题,最终得到原问题的最优解。动态规划算法分为两种类型:一种是基于记忆化搜索的自顶向下的方法,另一种是基于递推的自底向上的方法。在这两种方法中,都需要定义状态和状态转移方程,以确定子问题间的递推关系。具体来说,我们可以通过以下步骤来设计动态规划算法:
-
确定状态:找到问题中的最简单的子问题,列出状态表示,比如最大子序列问题中,状态可能表示为以第i个数为结尾的最大子序列和。
-
确定状态转移方程:列出状态转移方程,即当前子问题的最优解如何由前一个子问题的最优解得到。
-
确定初始状态:确定所有子问题中最简单的状态的解,通常是边界状态。
-
确定计算顺序:根据状态转移方程,确定计算的顺序,通常是按照状态的维度进行计算。
-
优化内存空间:如果状态转移只与前一个状态有关,则可以不必缓存所有状态,只需要缓存前一个状态即可。
简单实例
下面以 LeetCode 509题 "斐波那契数" 为例,给出一个动态规划算法并加上详细的注解。
题目描述
斐波那契数,通常用 F(n) 表示,形成的序列称为 斐波那契数列 。该数列由 0 和 1 开始,后面的每一项数字都是前面两项数字的和。即:
F(0) = 0, F(1) = 1 F(n) = F(n - 1) + F(n - 2), 其中 n > 1.
示例 1:
输入: 2 输出: 1 解释: F(2) = F(1) + F(0) = 1 + 0 = 1.
示例 2:
输入: 3 输出: 2 解释: F(3) = F(2) + F(1) = 1 + 1 = 2.
示例 3:
输入: 4 输出: 3 解释: F(4) = F(3) + F(2) = 2 + 1 = 3.
算法实现
-
确定状态:根据题目描述,可以定义一个数组 dp[] 来表示斐波那契数列中前n个数字的值,dp[i]表示斐波那契数列中第i个数字的值。
-
确定状态转移方程:根据斐波那契数列的定义,dp[i] = dp[i-1] + dp[i-2],其中i > 1。
-
确定初始状态:根据斐波那契数列的定义,dp[0] = 0,dp[1] = 1。
-
确定计算顺序:从左到右依次计算dp[2]、dp[3]、……、dp[n]。
-
优化内存空间:由于状态转移只与前两个状态有关,因此可以只用两个变量来记录前两个状态的值,不必缓存所有状态。
代码实现
下面是完整的算法实现,每一行都有注释说明。
package main
import "fmt"
func fib(n int) int {
if n < 2 { // 如果n为0或1,直接返回n
return n
}
dp := [2]int{0, 1} // 定义初始状态,dp[0]表示F(0),dp[1]表示F(1)
for i := 2; i <= n; i++ { // 从2到n按照状态转移方程求解
dp_i := dp[0] + dp[1] // 计算dp[i],即F(i)
dp[0] = dp[1] // 更新前两个状态
dp[1] = dp_i
}
return dp[1] // 返回最终结果
}
func main() {
fmt.Println(fib(2)) // 1
fmt.Println(fib(3)) // 2
fmt.Println(fib(4)) // 3
}
该算法的时间复杂度为 O(n),空间复杂度为 O(1)。时间复杂度线性,空间复杂度常数级别,因此在实际应用中较为实用。
进阶实例
下面以 LeetCode 1143题 "最长公共子序列" (LCS)为例,运用动态规划两种类型分别实现:
题目描述
给定两个字符串 text1 和 text2,返回这两个字符串的最长 公共子序列 的长度。如果不存在 公共子序列 ,返回 0 。
一个字符串的 子序列 是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删除任何字符)后组成的新字符串。
- 例如,
"ace"是"abcde"的子序列,但"aec"不是"abcde"的子序列。
两个字符串的 公共子序列 是这两个字符串所共同拥有的子序列。
示例 1:
输入:text1 = "abcde", text2 = "ace" 输出:3 解释:最长公共子序列是 "ace" ,它的长度为 3 。
示例 2:
输入:text1 = "abc", text2 = "abc" 输出:3 解释:最长公共子序列是 "abc" ,它的长度为 3 。
示例 3:
输入:text1 = "abc", text2 = "def" 输出:0 解释:两个字符串没有公共子序列,返回 0 。
提示:
1 <= text1.length, text2.length <= 1000text1和text2仅由小写英文字符组成。
1. 基于递推的自底向上方法
在该方法中,我们从子问题开始,依次计算出所有的子问题,最终得到原问题的答案。具体地,我们使用一个数组来记录子问题的答案,然后根据子问题的结果计算更大的问题的答案,直到求解出原问题的答案。
例如,在求解两个字符串的最长公共子序列问题时,我们可以定义一个二维的数组dp[i][j],表示计算字符串1的前i个字符和字符串2的前j个字符的最长公共子序列。我们首先将数组中所有的元素初始化为0,然后依次遍历字符串1和字符串2的所有字符,根据当前字符是否相等来更新数组中的元素:
- 如果第i个字符和第j个字符相同,则最长公共子序列长度加1,即
dp[i][j] = dp[i-1][j-1] + 1; - 如果第i个字符和第j个字符不同,则最长公共子序列长度等于前一个状态中两个字符串中较长的那个字符串的最长公共子序列长度,即
dp[i][j] = max(dp[i-1][j], dp[i][j-1])。
最终,dp[m][n]就是字符串1和字符串2的最长公共子序列的长度,其中m和n分别为两个字符串的长度。代码如下:
package main
import "fmt"
func MaxLCS(s1, s2 string) int {
m, n := len(s1), len(s2)
dp := make([][]int, m+1)
for i := range dp {
dp[i] = make([]int, n+1)
}
for i := 1; i <= m; i++ {
for j := 1; j <= n; j++ {
if s1[i-1] == s2[j-1] {
dp[i][j] = dp[i-1][j-1] + 1
} else {
dp[i][j] = max(dp[i-1][j], dp[i][j-1])
}
}
}
return dp[m][n]
}
func max(x, y int) int {
if x > y {
return x
}
return y
}
func main() {
text1 := "abcde"
text2 := "ace"
fmt.Println(MaxLCS(text1, text2))
text1 = "abc"
text2 = "abc"
fmt.Println(MaxLCS(text1, text2))
text1 = "abc"
text2 = "def"
fmt.Println(MaxLCS(text1, text2))
}
2. 基于记忆化搜索的自顶向下方法
在该方法中,我们使用递归函数和一个备忘录来实现动态规划。递归函数的基本思想是把原问题划分成若干个子问题,每个子问题都解决一次,然后将其结果缓存,避免重复计算。备忘录记录了已经计算过的子问题的答案,如果当前问题之前已经被解决过,则直接返回备忘录中的结果。
首先定义了一个 lcs 函数,用于递归寻找最长公共子序列。在该函数中,我们需要传入两个字符串 s1 和 s2、以及当前的遍历下标(i 和 j)和记忆化数组 memo。memo 用于存储已经遍历过的字符串长度信息,避免重复计算公共子序列,因为计算公共子序列的递归过程中存在大量的重复计算,使用 memo 记录已有的计算结果可以大大提高计算效率。在进行计算前,我们首先判断当前查询的两个字符串是否为空,如果是,则直接返回 0。如果当前条件已经对应 memo 数组中的值,则直接返回对应结果。
之后,我们通过比较当前遍历的 s1 和 s2 字符串的最后一个字符(即 i-1 和 j-1)是否相等,分别进行判断。如果相等,则将最后一个字符放入公共子序列中,长度加 1,递归向前寻找下一个字符;如果不相等,则通过在 s1 中移去最后一个字符或在 s2 中移去最后一个字符,分别计算得到两种情况下的公共子序列,并将它们的长度比较大小,返回最大的那个长度。
在 MaxLCS 函数中,我们定义了一个 memo 数组,用于存储已经遍历过的字符串长度信息。在循环初始化 memo 数组时,我们将各个位置的值设为 -1,表示尚未进行过计算。最后,我们将 s1 和 s2 的两个尾部下标(即 len(s1) 和 len(s2))以及 memo 数组传入 lcs 函数中,得到最终的最长公共子序列长度。
代码如下:
package main
import "fmt"
func lcs(s1, s2 string, i, j int, memo [][]int) int {
if i == 0 || j == 0 {
return 0
}
if memo[i][j] != -1 {
return memo[i][j]
}
if s1[i-1] == s2[j-1] {
memo[i][j] = lcs(s1, s2, i-1, j-1, memo) + 1
} else {
memo[i][j] = max(lcs(s1, s2, i-1, j, memo), lcs(s1, s2, i, j-1, memo))
}
return memo[i][j]
}
func MaxLCS(s1, s2 string) int {
memo := make([][]int, len(s1)+1)
for i := range memo {
memo[i] = make([]int, len(s2)+1)
for j := range memo[i] {
memo[i][j] = -1
}
}
return lcs(s1, s2, len(s1), len(s2), memo)
}
func max(x, y int) int {
if x > y {
return x
}
return y
}
func main() {
text1 := "abcde"
text2 := "ace"
fmt.Println(MaxLCS(text1, text2))
text1 = "abc"
text2 = "abc"
fmt.Println(MaxLCS(text1, text2))
text1 = "abc"
text2 = "def"
fmt.Println(MaxLCS(text1, text2))
}
本文小结
动态规划是一种通过将原问题拆分成子问题来解决复杂问题的算法。在动态规划中,通过记录之前计算的结果,可以避免重复的计算,从而提高算法效率。
在动态规划问题中,通常需要定义状态,确定状态转移方程和边界条件。通过状态转移方程可以将问题分解为规模更小的子问题,并将子问题的解决结果存储在一个表格中,以方便后续的计算。
动态规划常用于解决最长公共子序列、最长递增子序列、背包问题、字符串编辑距离等问题。在解决这些问题时,我们需要通过分析问题的特殊性质,设计出符合实际情况的状态和状态转移方程。
需要注意的是,在设计状态转移方程时,需要注意计算顺序,尤其是当某个状态的计算依赖于前面的多个状态时,需要仔细排列计算顺序,避免出现错误的结果。
总之,动态规划是一种有效的算法思想,可以解决很多实际问题。虽然需要一定的思维难度和技巧,但是只要掌握了基本原理和方法,就可以灵活地应用到各种场景中,解决各种问题。
整理完成后,先别急着发表,鼠标移动到最下方按钮“保存草稿”,出现“保存并预览”后点击它,得到文章链接,复制粘贴到CSDN质量分查询页面里查分:
https://www.csdn.net/qc
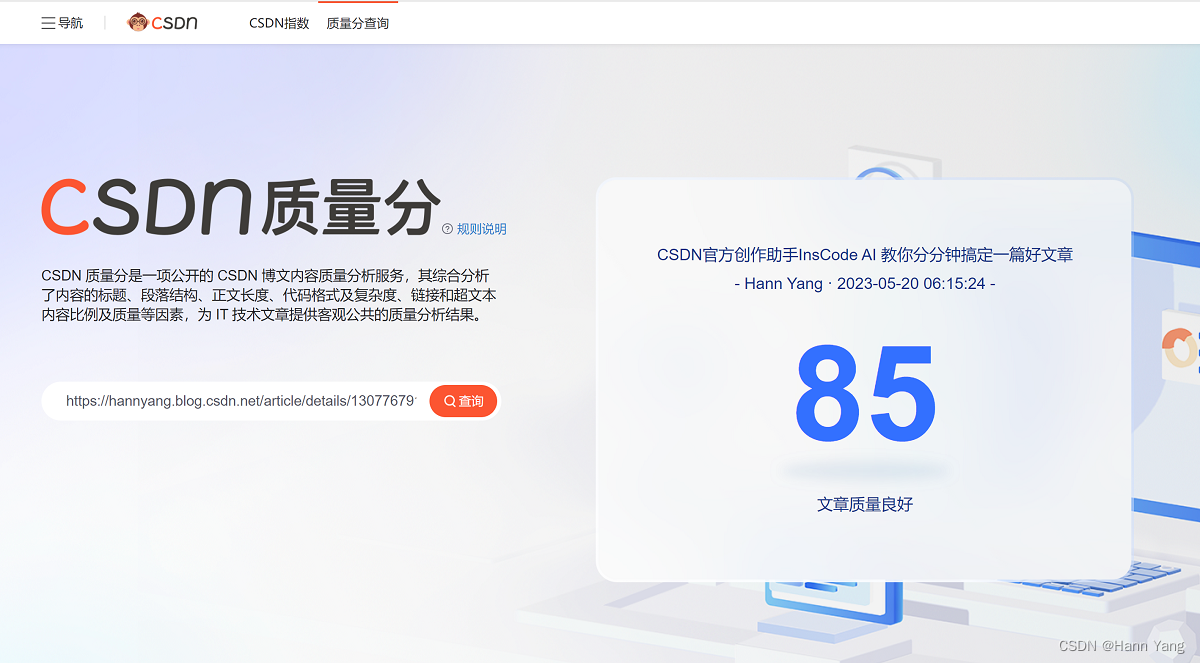
不错,果然是"好"文章!可以发表了,如果感觉本文有点帮助,请收藏点赞,写个评论。谢谢!