第6章 Join优化
6.1 Hive Join算法概述
Hive拥有多种join算法,包括common join,map join,sort Merge Bucket Map Join等。下面对每种join算法做简要说明:
1)common join
Map端负责读取参与join的表的数据,并按照关联字段进行分区,将其发送到Reduce端,Reduce端完成最终的关联操作。
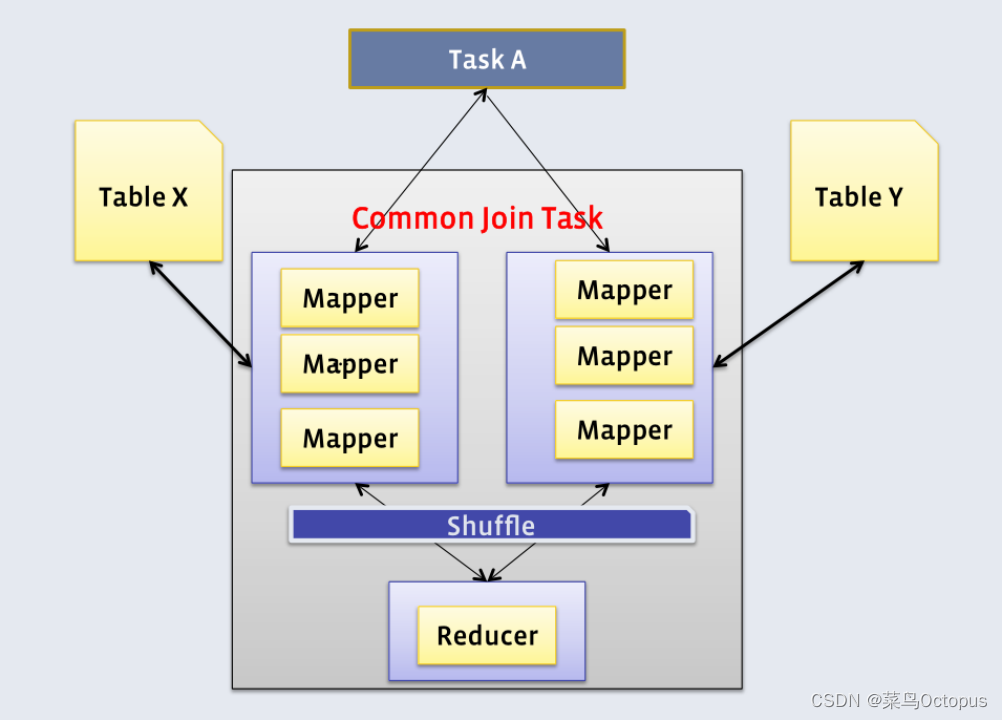
2)map join
若参与join的表中,有n-1张表足够小,Map端就会缓存小表全部数据,然后扫描另外一张大表,在Map端完成关联操作。

3)Sort Merge Bucket Map Join
若参与join的表均为分桶表,且关联字段为分桶字段,且分桶字段是有序的,且大表的分桶数量是小表分桶数量的整数倍。此时,就可以以分桶为单位,为每个Map分配任务了,Map端就无需再缓存小表的全表数据了,而只需缓存其所需的分桶。
6.2 Map Join优化
示例SQL语句如下:
select
*
from
(
select
*
from dwd_trade_order_detail_inc
where dt='2020-06-16'
)fact
left join
(
select
*
from dim_sku_full
where dt='2020-06-16'
)dim
on fact.sku_id=dim.id;6.2.1 优化前执行计划
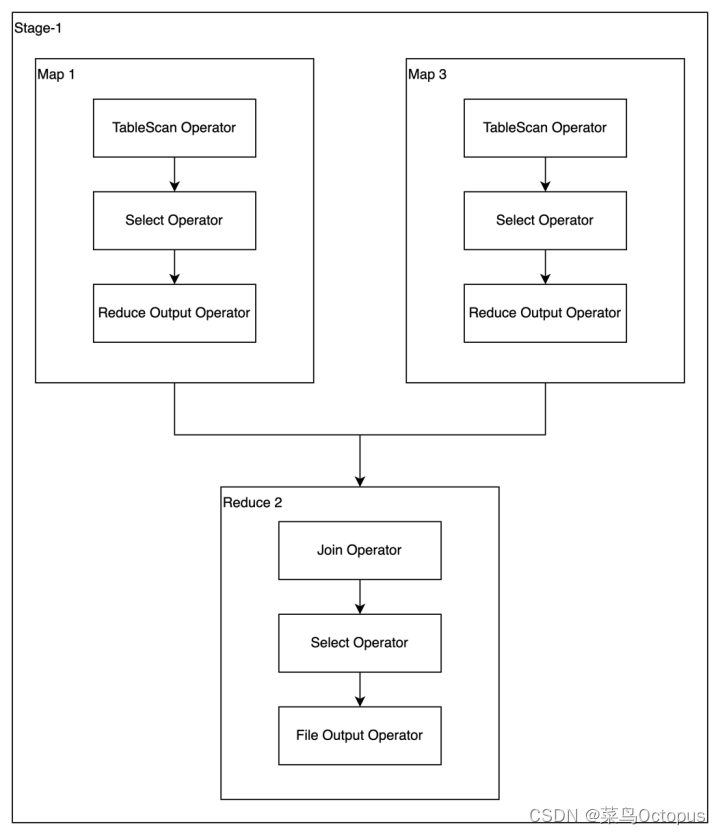
6.2.2 优化思路
上述参与join的两表一大一小,可考虑map join优化。
Map Join相关参数如下:
--启用map join自动转换
set hive.auto.convert.join=true;
--common join转map join小表阈值
set hive.auto.convert.join.noconditionaltask.size6.2.3 优化后执行计划

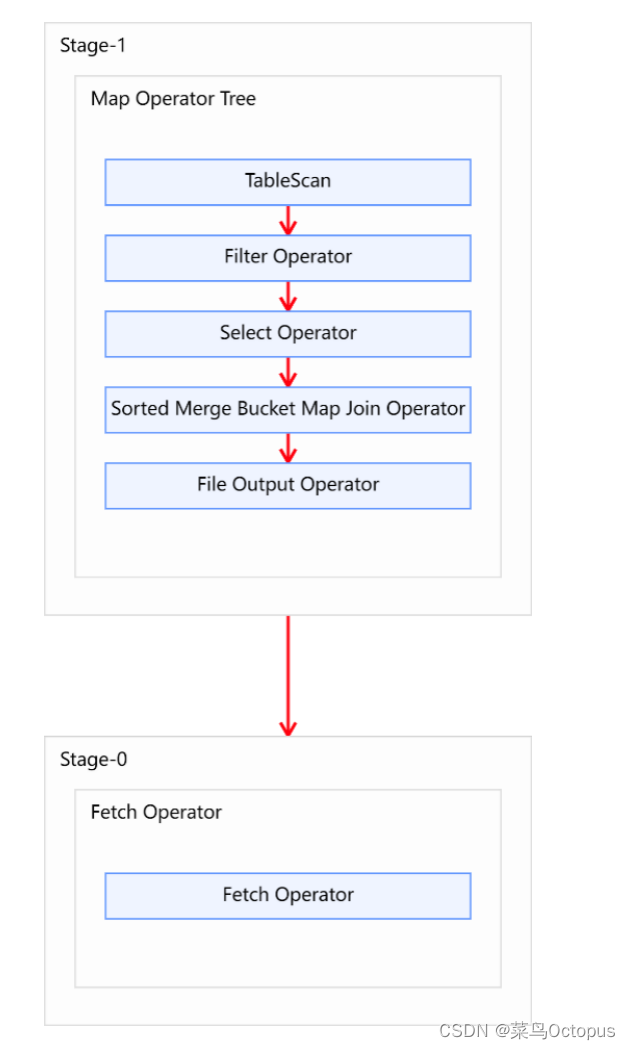
6.3 Sort Merge Bucket Map Join
6.3.1 优化说明
Sort Merge Bucket Map Join相关参数:
--启动Sort Merge Bucket Map Join优化
set hive.optimize.bucketmapjoin.sortedmerge=true;
--使用自动转换SMB Join
set hive.auto.convert.sortmerge.join=true;6.3.2 优化案例
1)示例SQL语句
select
*
from(
select
*
from dim_user_zip
where dt='9999-12-31'
)duz
join(
select
*
from dwd_trade_order_detail_inc
where dt='2020-06-16'
)dtodi
on duz.id=dtodi.user_id;2)优化前
上述SQL语句共有两张表一次join操作,故优化前的执行计划应包含一个Common Join任务,通过一个MapReduce Job实现。
3)优化思路
经分析,参与join的两张表,数据量如下:
| 表名 | 大小 |
| dwd_trade_order_detail_inc | 162900000000(约160g) |
| dim_user_zip | 12320000000 (约12g) |
两张表都相对较大,可以考虑采用SMBSMB Map Join对分桶大小是没有要求的。下面演示如何使用SMB Map Join。
首先需要依据源表创建两个的有序的分桶表,dwd_trade_order_detail_inc建议分36个bucket,dim_user_zip建议分6个bucket,注意分桶个数的倍数关系以及分桶字段和排序字段。
--订单明细表
hive (default)>
drop table if exists dwd_trade_order_detail_inc_bucketed;
create table dwd_trade_order_detail_inc_bucketed(
id string,
order_id string,
user_id string,
sku_id string,
province_id string,
activity_id string,
activity_rule_id string,
coupon_id string,
date_id string,
create_time string,
source_id string,
source_type_code string,
source_type_name string,
sku_num bigint,
split_original_amount decimal(16,2),
split_activity_amount decimal(16,2),
split_coupon_amount decimal(16,2),
split_total_amount decimal(16,2)
)
clustered by (user_id) sorted by(user_id) into 36 buckets
row format delimited fields terminated by '\t';
--用户表
hive (default)>
drop table if exists dim_user_zip_bucketed;
create table dim_user_zip_bucketed(
id string,
login_name string,
nick_name string,
name string,
phone_num string,
email string,
user_level string,
birthday string,
gender string,
create_time string,
operate_time string,
start_date string,
end_date string,
dt string
)
clustered by (id) sorted by(id) into 6 buckets
row format delimited fields terminated by '\t';然后向两个分桶表导入数据。
--订单明细分桶表
hive (default)>
insert overwrite table dwd_trade_order_detail_inc_bucketed
select
id ,
order_id ,
user_id ,
sku_id ,
province_id ,
activity_id ,
activity_rule_id ,
coupon_id ,
date_id ,
create_time ,
source_id ,
source_type_code ,
source_type_name ,
sku_num ,
split_original_amount ,
split_activity_amount ,
split_coupon_amount,
split_total_amount
from dwd_trade_order_detail_inc
where dt='2020-06-16';
--用户分桶表
hive (default)>
insert overwrite table dim_user_zip_bucketed
select
id,
login_name,
nick_name,
name,
phone_num,
email,
user_level,
birthday,
gender,
create_time,
operate_time,
start_date,
end_date,
dt
from dim_user_zip
where dt='9999-12-31';然后设置以下参数:
--启动Sort Merge Bucket Map Join优化
set hive.optimize.bucketmapjoin.sortedmerge=true;
--使用自动转换SMB Join
set hive.auto.convert.sortmerge.join=true;
最后在重写SQL语句,如下:
hive (default)>
select
*
from dwd_trade_order_detail_inc_bucketed od
join dim_user_zip_bucketed duser
on od.user_id = duser.id;优化后的执行计如图所示: