文章目录
- 一、背景
- 二、方法
- 2.1 基础内容
- 2.2 数据集
- 2.3 预训练方法
- 2.4 模型尺寸
- 三、效果
论文:Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese
代码:https://github.com/OFA-Sys/Chinese-CLIP
出处:阿里达摩院
时间:2022.11
贡献:
- 提出了 Chinese CLIP,是经过在大尺度中文图像-文本对儿的两阶段预训练
一、背景
CLIP 的成功极大地促进了对比学习在视觉-语言模型预训练上的研究和应用
不同于传统生成式预训练,CLIP 是一种基于对比学习的模型,在从网络上收集的约 4 亿个 image-text pair 上进行预训练,而且有很好的 zero-shot 迁移能力
由于 CLIP 能够在视觉和文本之间建立联系,所有页改变了多模态表达学习和计算机视觉的相关研究
在 CLIP 之后有很多的工作,如 DALL-E,StyleCLIP,SLIP,CLIP4Clip 等
尽管如此,但在中国还没有一个专为中文多模态学习设计的模型
所以,本文中提出了 Chinese CLIP (CN-CLIP),模型在大量的中文文本-图像对儿上进行了预训练
数据:
- 约 2 亿 image-text pairs
模型大小:
- 建立了 5 个不同大小的模型,从 77M 到 958M 参数量
训练方式:
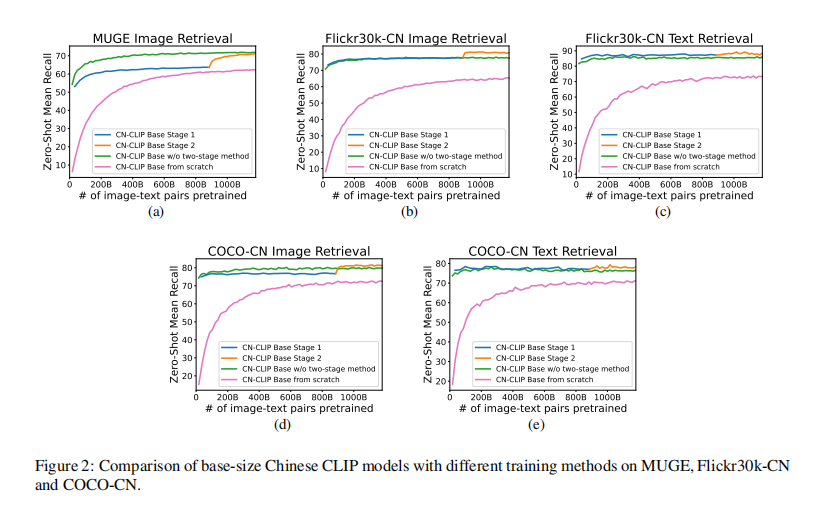
- 使用两阶段训练的方式
- 第一阶段:冻结 image encoder
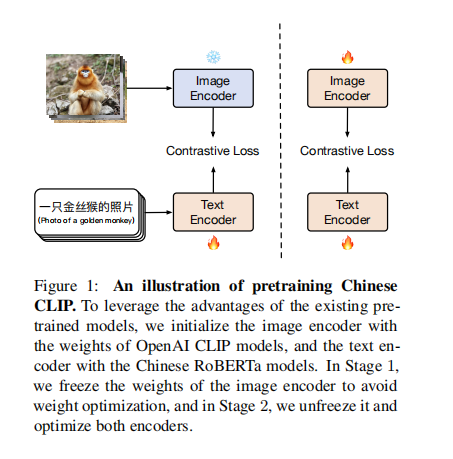
- 第二阶段:image encoder 和 text encoder 都参与训练(如图 1)
- 消融实验证明了两阶段训练的好处
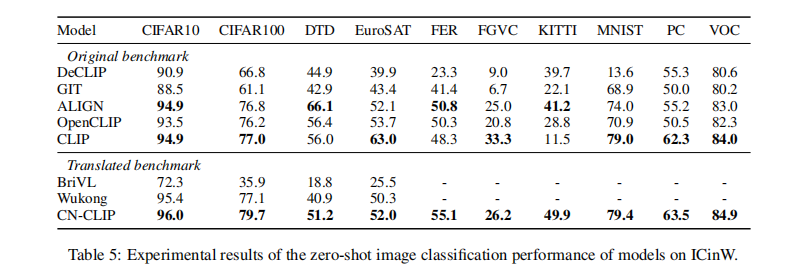
测试数据集:
- 在 3 个 Chinese cross-modal 检索数据集上进行的测试
- 包括 MUGE2, Flickr30K-CN, COCO-CN
二、方法
2.1 基础内容
首先介绍一下 CLIP 的训练方法:
- CLIP 是由 image encoder 和 text encoder 构成的
- image encoder:是 vision backbone,如 ResNet、ViT 等
- text encoder:是 transformer model,如 BERT、GPT 等
- CLIP 有多种不同大小的模型尺度
- vision backbone:5 个不同尺度的 resnet(ResNet-50, ResNet101, RN50x4, RN50x16, RN50x64),3 个饼图的 ViT (ViT-B/32, ViT-B/16, and ViT-L/14)
- 模型的训练使用的是 large-batch 的对比学习,给定一个 batch 中有 N 个图像,则共有 N × N N \times N N×N 个可能的图文对儿,有 N 对儿 positive samples,有 N 2 − N N^2-N N2−N 对儿 negative samples。则共有 N 2 N^2 N2 个 similarity score,来优化 cross-entropy loss
CLIP 的扩展:
- 可以迁移到跨模态的检索
- image encoder 可以作为 vision backbone 来代替在 ImageNet 上预训练的 ResNet 或 ViT
- 通过计算给定的 image 和固定形式 Candidate label (如 a photo of [label]) 的相似性,也可以进行开集的 zero-shot 分类
2.2 数据集
CLIP 成功的另外一个原因在于预训练使用的超大尺度的训练集
由在 CLIP 上进行的实验可知,通过增大数据量、增长训练周期都可以提供模型在 zero-shot 学习任务上的效果
训练数据集:
- 从 LAION-5B 中抽取包含 ‘zh’ 的中文数据,共抽取 1.08 亿数据
- 从 Wukong 中获得 0.72 亿数据
- 将英文多模态数据翻译为中文的,包括 Visual Genome 和 MSCOCO
- 最后共得到约 2 亿的训练数据
- 一般将图像 resize 为 224x224 来使用,在 ViT-L/14 中使用 336x336 大小
2.3 预训练方法
最简单的训练方法是从头开始训练,就是会受到训练数据的数量和质量的限制
为了利用现有的预训练模型优势:
- 对于 image encoder ,使用了官方 CLIP 开源预训练模型来初始化
- 对于 text encoder,使用 RoBERTa-wwm-ext 和 RBT3
如何基于开源模型来预训练:
- constrastive tuning, 对比微调,类似于将 CLIP 迁移到下游任务上去
- Locked-image Tuning(LiT),效果更好
Chinese CLIP 如何进行预训练:两阶段预训练方法,如图 1 所示
- 主要思想是冻结 image encoder(冻结所有的参数)使用 LiT 让 text encoder 能够从 OpenAI 的 CLIP 的基础视觉模型中读出高质量的表示,然后将这些表示迁移到需要的数据域中。
- 第一阶段:冻结 image encoder 的所有参数,只训练 text encoder,这一动作是基于一个假设:训练好的 vision backbone 已经有很强的能力来抽取视觉特征了。第一阶段的训练直到对下游任务没有明显的提升而结束
- 第二阶段,让 image encoder 的参数参与训练,这样一来 image encoder 的参数就可以学习从中文网站来的图了
- 实验结果表明两阶段的预训练能够比直接从训练好的模型来 finetune 效果更好
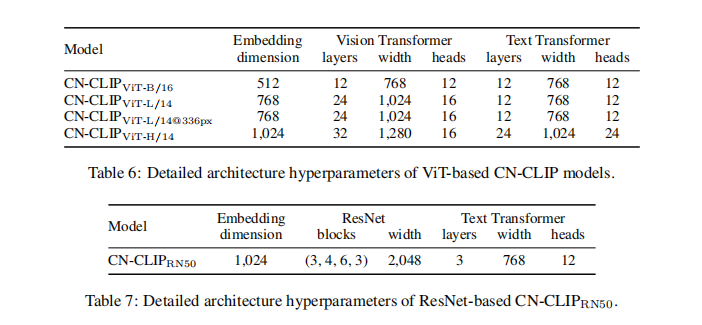
2.4 模型尺寸
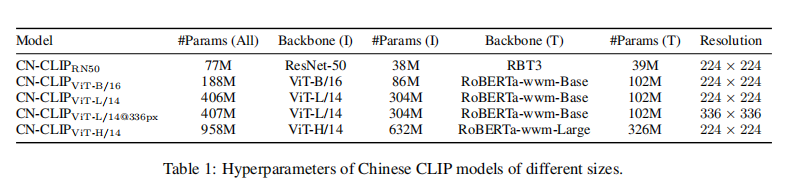
有 5 种不同的模型尺寸,从 77 ~ 958 million 参数量,无特殊说明情况下预训练图像大小为 224x224
- ResNet 50 model: C N − C L I P R N 50 CN-CLIP_{RN50} CN−CLIPRN50
- C N − C L I P V i T − B / 16 CN-CLIP_{ViT-B/16} CN−CLIPViT−B/16
- C N − C L I P V i T − L / 14 CN-CLIP_{ViT-L/14} CN−CLIPViT−L/14
- C N − C L I P V i T − L / 14 @ 336 p x CN-CLIP_{ViT-L/14@336px} CN−CLIPViT−L/14@336px
- C N − C L I P V i T − H / 14 CN-CLIP_{ViT-H/14} CN−CLIPViT−H/14
三、效果
数据集:
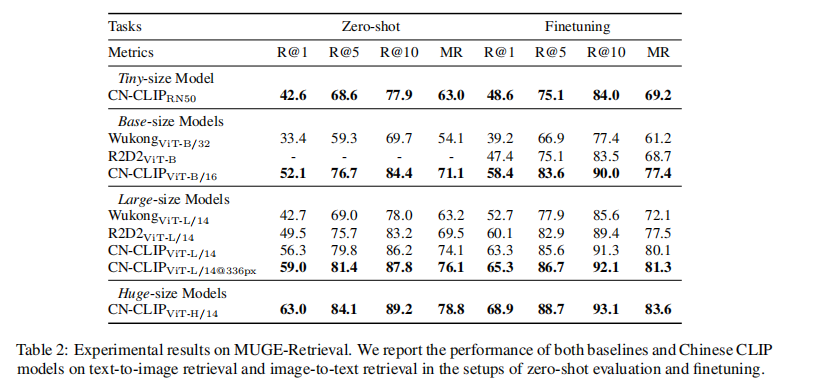
- MUGE-Retrieval:image-text 检索数据集
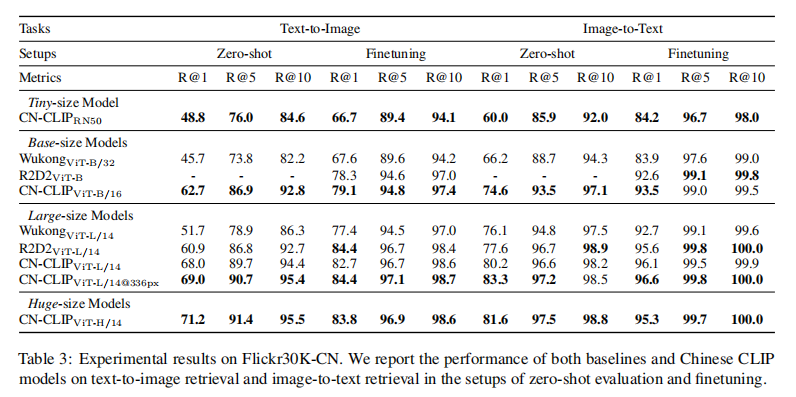
- Flickr30K-CN:Flickr30K 数据集且将标签翻译为中文
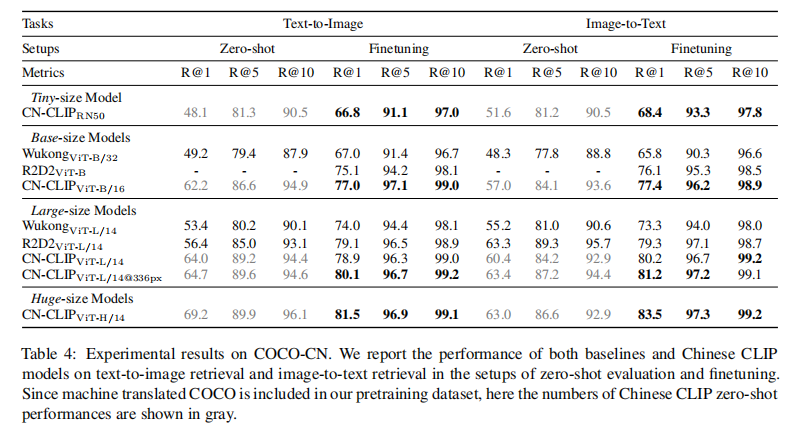
- COCOCN:COCO 数据集且将标签翻译为中文
评价指标:
- zero-shot learning:使用 image 和 text 之间的 smilarity score 来衡量,使用 top-k similar candidates
- finetuning:使用 Recall@K 来评价,K={1, 5, 10},也会使用 Mean Recall (MR)来评价,即 Recall@K 的均值