文章目录
- Array
- 数据类型声明
- 数组索引
- 数组范围
- 数组复制
- 数组初始化
- 直接赋值
- 通过拷贝赋值
- 不同索引范围但长度相等
- 非指定类型边界收缩
- 多维数组
- 数组遍历
- 数组切片
- 访问和动态检查
- 直接访问
- 动态检查
- 数组字面量 Array literal
- 数组拼接
- 两个数组拼接
- 数组和单个值拼接
- Array Equality(数组相等判定)
- 数组遍历
- 通过索引遍历(循环变量I不可更改)
- 直接遍历所有的对象 object(对象可以被更改)
- 二维数组
- 高维数组
- Definite / indefinite types (定义类型和非定义类型)
- String 字符串
- 数组的默认值
- Definite type (定义类型)
- Indefinite type(非定义类型)
- unconstrained type(未指定类型)
- Generic type(泛型类型)
- 练习
Array
数据类型声明
- 在 Ada 中,可以使用
type关键字声明数组类型,指定元素类型和维度 。例如:

type IntArray is array(1 .. 10) of Integer;
数组索引
- 数组中的索引是从
1开始,默认情况下不支持从0开始,可以使用索引来访问数组的特定元素:IntArray(3)表示IntArray数组的第3个元素。
数组范围
- 数组的范围由其类型的索引范围定义。例如,
IntArray的索引范围是从1到10。
数组复制

- 这里将
A2的值复制给了A1但是,A1, A2仍然是独立的两个数组, 在其他的编程语言中(有的是指向引用,但是 ada 不会这样,所有的 ada 复制都是deep copy操作) - 但是要求这两个数组的
类型、长度必须是一致的。
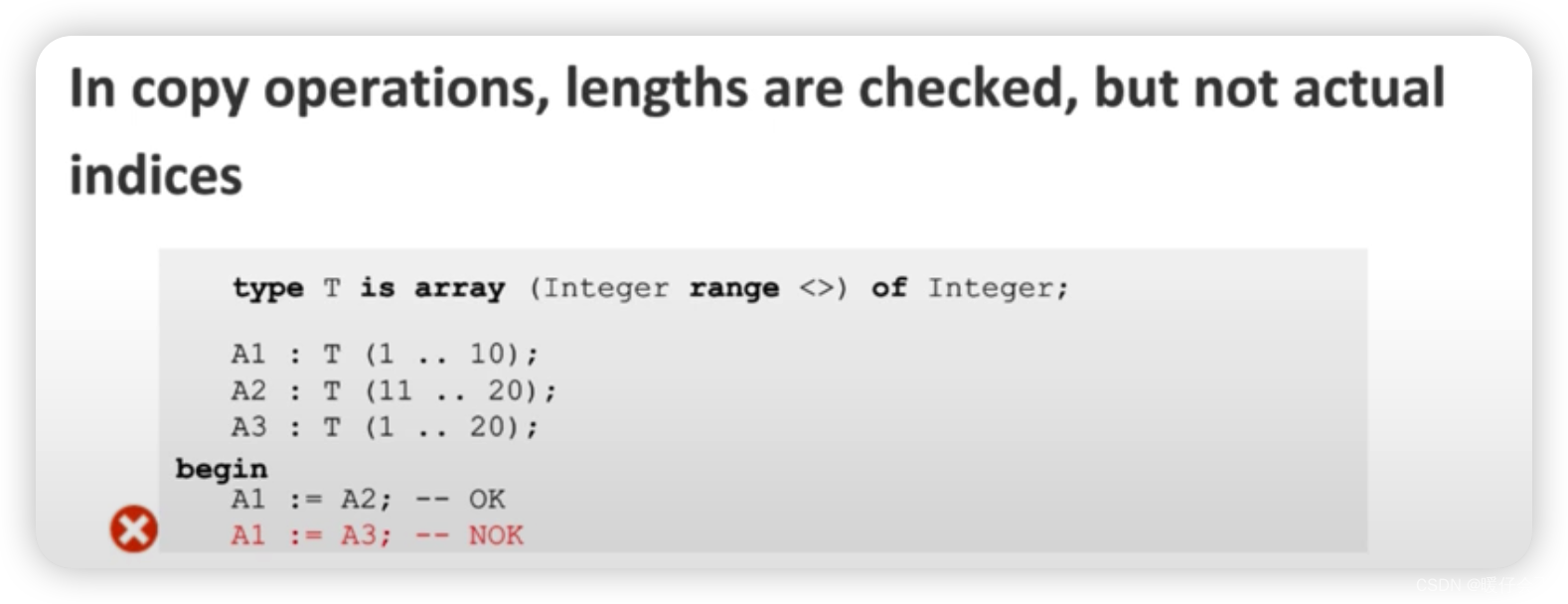
- 在上面的复制中,
A2的内容复制给了A1,因为虽然他们的索引范围不同,但是会对应复制,例如A2(11) = A1(1)以此类推 - 但是
A3的长度和A1不同,因此无法复制
数组初始化
- 可以使用
:=运算符在声明数组时对其进行初始化,或者可以使用赋值语句逐个赋值。例如:
直接赋值
```ada
IntArray: IntArray := (1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
```
通过拷贝赋值
不同索引范围但长度相等

- 在上面的例子中,我们使用
非定义类型的方式声明了一个类型T,这是一个数组类型,但是T的范围我们并不知道,只知道T中的元素都是整数而已。 - 同时
A1数组是T类型,并且包含了 10 个元素,索引范围是1-10 A2数组也是T类型,并且包含了 10 个元素,索引范围是11-20, 但是她复制了A1的值,虽然现在我们并不知道A1的值是什么。- 如果后面我们对
A1的值进行修改,那么A2的值实际上并不会改变,因为 ada 的赋值是深拷贝
type T is array (Integer range <>) of Integer;
A1: T (1 .. 10);
A2: T (1 .. 10);
-- Fill A1 with some data.
for I in A1'Range loop
A1(I) := I;
end loop;
-- Copy A1 to A2.
A2 := A1;
-- Change the value of A1(1)
A1(1) := 99;
-- Now, A1(1) is 99, but A2(1) is still 1.
非指定类型边界收缩

- 如上图,如果
A1是一个T,并且A1数组的元素索引就是从1-10,而这时,A2复制了A1的值,虽然A2仍然是T类型(非定义类型),但是她也会复制A1的索引范围。
多维数组
- Ada 支持多维数组的声明和操作。可以通过指定多个维度来声明多维数组,例如:
type Matrix is array(1 .. 3, 1 .. 3) of Integer;
数组遍历
可以使用 for 循环结构遍历数组中的元素。例如:
for i in IntArray'Range loop
Put_Line(Integer'Image(IntArray(i)));
end loop;
数组切片
-
可以使用数组切片(array slice)来访问数组的子集。切片允许通过指定范围来提取数组的一部分。例如:
SubArray: IntArray := IntArray(3 .. 6);- SubArray 将包含 IntArray 数组索引为 3 到 6 的元素。

- SubArray 将包含 IntArray 数组索引为 3 到 6 的元素。
-
虽然在
copy的时候,不同长度的 array 不能进行 copy 行为,但是我们可以 copy 其中的一部分。 -
上图中
A2的前 10 个元素复制给了A1,然后A1的2-4索引的元素又获得了A2中5-7索引元素的值。
访问和动态检查
直接访问
- ada 中的数组中的元素可以被直接访问:

- 这里定义了一个数组
V,他的索引范围是1..10, 因此可以直接取V(1)
- 这里定义了一个数组
动态检查
- 数组会被进行动态检查:

- 因为这里的
V(0)中的0并没有被覆盖在定义的索引范围中,因此这样是一种越界行为
- 因为这里的
数组字面量 Array literal
-
可以使用 array literals(数组字面量) 来初始化数组或者赋值给数组。数组字面量是由一系列逗号分隔的值,这些值被括在括号内。
-
例如,可以使用数组字面量来初始化一个数组:
type T is array (1 .. 5) of Integer; A : T := (1, 2, 3, 4, 5); -- array literal -
在这个例子中,
(1, 2, 3, 4, 5)是一个数组字面量,用来初始化数组 A。 -
也可以使用数组字面量来给数组赋值:
A := (6, 7, 8, 9, 10); -- array literal -
此外,Ada 语言还提供了 others 关键字来初始化或赋值数组中剩余的所有元素:
A := (1, 2, others => 3); -- array literal with 'others'

- 需要特别注意的是:在使用数组字面量进行初始化的时候,要注意分清楚下面的情况:

V1虽然是一个非指定类型的数组,但是由于其索引就只有 3 个,因此我们可以使用others来为V1中的所有的元素赋值- 但是
V2没有指定元素的个数,而直接使用others这种情况在 ada 中是不被允许的
数组拼接
两个数组拼接

- 通过
&符号,可以直接拼接两个一维的数组
那现在就有疑问了,假设
A1的索引范围是(1..10),A2
的索引范围是(8..12),那么A3作为A1 & A2的结果,索引范围应该会是什么样子?
- 其实是这个完全不需要担心,因为再给
A3赋值之前,我们需要先定义A3的索引,例如下面的代码:
type T is array (Integer range <>) of Integer;
A1: T (1 .. 10);
A2: T (8 .. 12);
A3: T (1 .. 15); -- The range of A3 should be the total length of A1 and A2.
-- Fill A1 and A2 with some data.
for I in A1'Range loop
A1(I) := I;
end loop;
for I in A2'Range loop
A2(I) := I;
end loop;
-- Concatenate A1 and A2.
A3 := A1 & A2;
- 可以看到,其实我们只需要关注
A3的元素个数即可,而不用担心元素的索引。
数组和单个值拼接

Array Equality(数组相等判定)

- 数组的
size需要相等 - 数组中的每个元素都必须相等
- 数组的
类型必须相等 - 数组的索引范围不影响数组的相等判定
type T is array (Integer range <>) of Integer; A1 : T (1 .. 3) := (1, 2, 3); A2 : T (2 .. 4) := (1, 2, 3); -- This will print "Equal" if A1 = A2 then Put_Line("Equal"); else Put_Line("Not Equal"); end if;
数组遍历
通过索引遍历(循环变量I不可更改)

- 使用
A数组的Range属性来得到所有的索引,并进行遍历 - 但是使用的循环变量
I是不可以被修改的
直接遍历所有的对象 object(对象可以被更改)

- 使用
of关键字 - 如果我在循环中更改了
V(如上图)那么这个V就会切实地被更改成0
二维数组
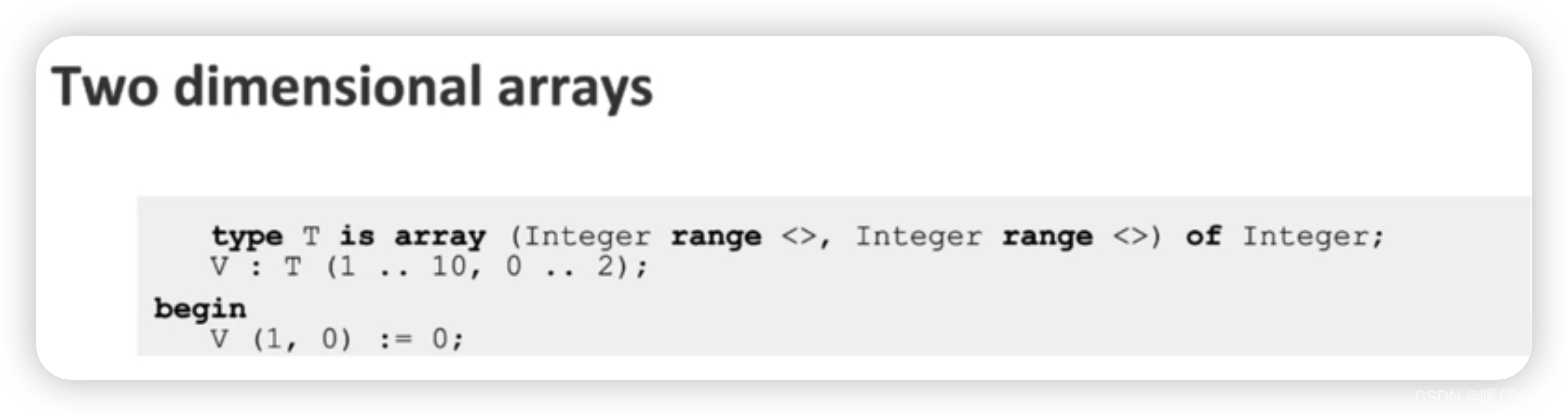
高维数组
type T1 is array (Integer range <>) of Integer;
type T2 is array (Integer range <>) of T1 (0 .. 2); -- specify the range of T1 here
V: T2 (1 .. 10);
begin
V (1)(0) := 0; -- Now this is OK.
end;
- 在这段代码中,
V是一个T2类型的数组,其中每个元素都是一个T1类型的数组。T1类型的数组的范围是0 .. 2,因此V (1)(0) := 0;这行代码现在是正确的,它将V的第1个元素(一个T1类型的数组)的第0个元素设置为0。 - 在定义一个多维数组的后面的维度的时候,需要将前面的维度都定义好
所以这是一个几行几列的数组?
- 类型
T2定义为type T2 is array (Integer range <>) of T1 (0 .. 2);,其中每个元素都是一个T1类型的数组(这里,T1的范围是0 .. 2,因此T1类型的数组有3个元素)。
因此,当你声明 V: T2 (1 .. 10); 时,你正在创建一个有10行、每行3列的二维数组。具体来说,这是一个10行3列的数组。
对于一个 ada 中的 2维数组 V, 那么 V(0)(1) 和 V(0,1) 是相等的么
- 是的,
V(0)(1)和V(0,1)在 Ada 中是等价的。它们都是用来访问二维数组V中的特定元素。具体来说,它们都访问的是V的第 0 行第 1 列的元素。V(0,1)的写法可能在阅读和理解代码时更清晰,因为它明确表示了这是一个二维索引,而V(0)(1)则可能需要更多的解析才能理解。
Definite / indefinite types (定义类型和非定义类型)

String 字符串
- 在 Ada 语言中,字符串被视为一种特殊类型的数组,其索引是
Positive范围的整数(也就是从 1 开始的整数),而元素类型是Character。这意味着可以像处理其他数组一样来处理字符串,比如用下标来访问特定字符,或者用'Length属性来获取字符串的长度。
S : String := "Hello, world!";
Put_Line("The first character is: " & S(1));
Put_Line("The length of the string is: " & Integer'Image(S'Length));
- 此外,还要注意的是 Ada 中的字符串是不可变的。也就是说,一旦一个字符串被创建,就不能修改它的内容。不过,可以通过字符串拼接操作(用
&运算符)来创建新的字符串。比如:
S1 : String := "Hello";
S2 : String := ", world!";
S3 : String := S1 & S2; -- S3 is now "Hello, world!"
- 但如果你需要一个可变的字符串,你可以使用
Unbounded_String类型,这是 Ada 的标准库Ada.Strings.Unbounded中提供的一种类型。Unbounded_String类型的对象可以通过To_Unbounded_String函数从普通字符串创建,可以用To_String函数转回普通字符串,也可以用&=运算符来修改内容。

数组的默认值
-
在 Ada 语言中,当你声明一个数组但不给它赋初始值时,数组的元素将不会被自动初始化为默认值。相反,数组元素的初始值是不确定的。这与许多其他编程语言有所不同,这些语言可能会给新的数组元素自动赋予默认值。
-
如果你想给数组的所有元素赋予相同的初始值,你可以使用
(others => value)语法,其中value是你想要赋予的初始值。例如,以下代码将创建一个浮点数数组A,并将其所有元素初始化为0.0:type T is array (Integer range <>) of Float; A : T (1 .. 10) := (others => 0.0); -
请注意,
(others => value)只能用于初始化数组。如果你在后续的代码中想要修改数组的所有元素,你需要使用一个循环来遍历数组并为每个元素赋值。 -
当然也可以强迫数组拥有默认值:

-
为了性能考虑,上述代码一般不会使用
Definite type (定义类型)
-
定义类型是通过使用
type关键字显式定义的类型。它们是具体的类型,具有明确定义的结构和语义。定义类型可以是基本类型(如Integer、Float、Boolean)或派生类型(通过限定范围、枚举、数组等方式创建的类型)。例如:type MyInteger is range 1 .. 10;
Indefinite type(非定义类型)
-
非定义类型是一种未具体定义的类型,它们是一种抽象概念,没有具体的结构和语义。它们通常用作模板或占位符,在需要时可以被实例化为具体的类型。
-
Ada 中的非定义类型包括未指定类型(unconstrained type)和泛型类型(generic type)。
unconstrained type(未指定类型)
-
未指定类型:未指定类型是一种可以通过参数传递进行实例化的占位符类型。它们在声明时不指定范围或大小,需要在使用时提供具体的值或范围。
```ada type MyUnconstrainedArray is array (Positive range <>) of Integer; ```- 在上述示例中,
MyUnconstrainedArray是一个未指定类型的数组类型,可以根据实际需要传递不同的范围进行实例化。 Positive被用作array的索引范围。通过使用Positive range <>,表示数组的索引可以是任意的正整数范围。- 例如,可以将
MyUnconstrainedArray实例化为索引范围为1 到 100的数组:MyArray : MyUnconstrainedArray(1 .. 100); - 使用
Positive子类型作为数组索引范围的好处是,它可以确保索引始终是正整数,符合实际需求,并提供了类型安全性。
- 在上述示例中,
Generic type(泛型类型)
-
泛型类型是一种可以根据参数化的类型或值来创建通用代码模板的类型。它们在定义时可以指定一个或多个参数,然后在使用时提供具体的参数值来实例化。
例如:generic type ElementType is private; package Stack is type Stack_Type is private; procedure Push(Item : in ElementType); function Pop return ElementType; ... end Stack; -
在上述示例中,
Stack是一个泛型包(generic package),使用了一个参数ElementType。这个参数ElementType可以是任意类型,它在使用时可以通过传递具体的类型来实例化。也就是说,可以使用不同的类型来创建不同类型的堆栈。 -
例如,可以使用 Stack 泛型包创建一个整数类型的堆栈:
package Integer_Stack is new Stack(ElementType => Integer);
非定义类型 (indefinite types) 的灵活性和可扩展性使得它们在处理通用数据结构和算法时非常有用。通过使用非定义类型,可以编写更通用和可复用的代码,适应不同的数据类型和需求。
练习


- 这种情况的类型定义没问题,但是没有限定数组的大小,因此会报错

- 从结构上来说,他们都是长度为
3的数组, - 但是他们不是同一个
type,虽然他们的type定义看起来完全一样的,但是却并不符合数组复制的要求

-
在 Ada 中,数组的默认索引起始值是
1,而不是像一些其他语言(如 C 或 Python)那样是0。因此,V (0)是无效的,会导致范围错误。 -
在代码中创建了一个名为
V的数组,类型为T,并将其初始化为(1, 2, 3)。这将创建一个包含三个元素的数组,这些元素的索引是1、2和3。


- 开始
X=10,即,V1创建出来的时候具备 10 个元素 - 虽然后来
X的值修改为100,但是V1已经固定了, - 因此可以直接将
V2复制给V1
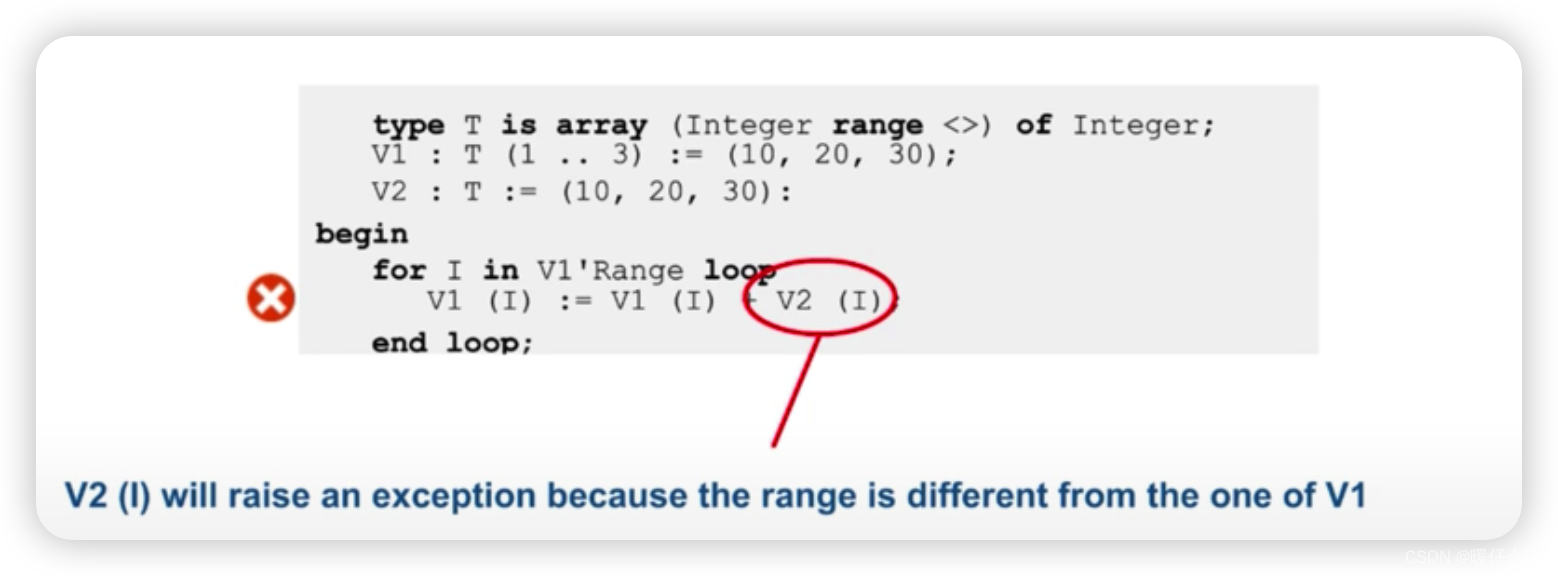
- 从定义中我们只知道
V1的索引范围是1-3并且给定了 3 个值 - 同时我们知道
V2的值也是(10, 20, 30) - 但是定义中并没有明确指定
V2的 boundary,也就是索引范围,因此我们并不能够盲目推测 - 也就是当
I=1时,我们无法确定V2的值,对V2来说,因为没有给定boundary,所以V2的第一个索引其实是-2^16(也就是integer类型中最小的数)
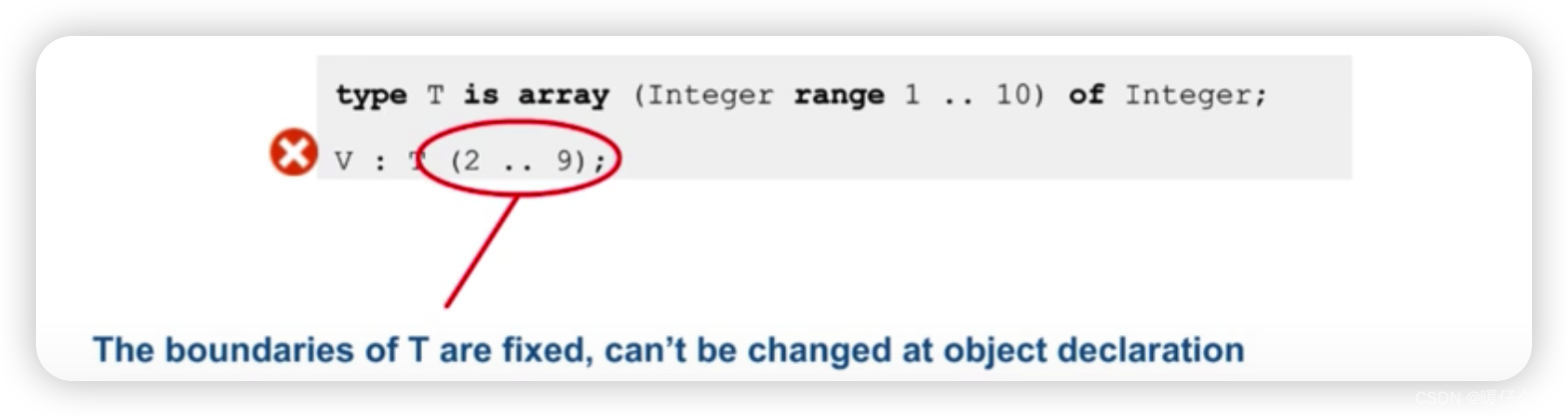
- 这里是通过
definite的方式来定义数组,T的boundary固定为1-10,因此不能被随意改变,如果这里使用的是indefinite的形式,例如type T is array(Integer range<>) of Integer那么在定义V的时候是可以更改boundary的

- 在 Ada 中,
String是一种预定义的数组类型,其元素类型为Character。在 Ada 中,没有直接创建字符串数组的方式。通常,你会创建一个数组,它的元素类型是固定长度的字符串,或者是Unbounded_String。 - 同时,如果创建一个字符串,那么对于索引类型
Integer range <>也要更改为Positive range <>因为在 Ada 中,String是一种特定类型的数组,其索引类型是Positive,
如果你想创建一个可以存储任意长度字符串的数组,你可以使用 Ada.Strings.Unbounded.Unbounded_String 类型。这个类型可以存储任意长度的字符串,并提供了一些实用的操作。以下是一个示例:
with Ada.Strings.Unbounded; use Ada.Strings.Unbounded;
type String_Array is array (Integer range <>) of Unbounded_String;
- 如果你只需要处理固定长度的字符串,你可以这样定义:
type String_Array is array (Integer range <>) of String (1 .. Max_Length);
- 在这个例子中,
Max_Length是一个你预先定义的常量,表示字符串的最大长度。这种方式的限制是所有的字符串都必须有相同的长度,而且这个长度是在编译时决定的。
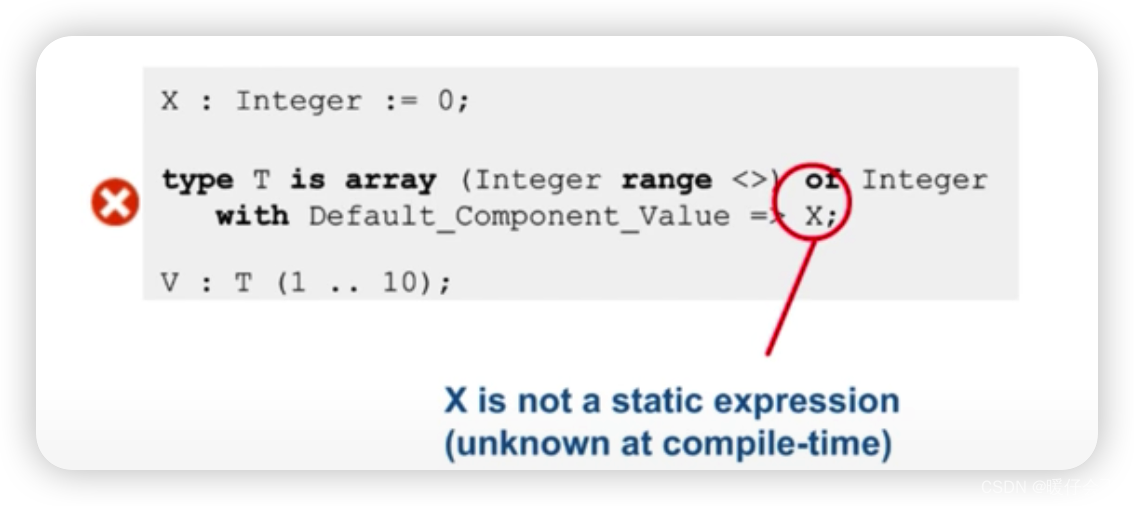
-
在 Ada 中,
Default_Component_Value属性应用于类型标签,并将默认值分配给类型的每个实例的组件。但是,此默认值必须是编译时可以确定的值,不能是变量。以上代码中,尝试将变量X作为默认组件值,这是不允许的。 -
如果希望每个数组元素的默认值为
0,那么应该直接使用数值0,而不是变量X。下面是修改后的代码:type T is array (Integer range <>) of Integer with Default Component Value => 0; V: T(1 .. 10); -
如果
X的值在编译时可以确定,那么也可以使用常量来替代变量,如下:X: constant Integer := 0; type T is array (Integer range <>) of Integer with Default Component Value => X; V: T(1 .. 10);