H.265/HEVC编码原理及其处理流程的分析
H.265/HEVC编码的框架图,查了很多资料都没搞明白,各个模块的处理的分析网上有很多,很少有把这个流程串起来的。本文的主要目的是讲清楚H.265/HEVC视频编码的处理流程,不涉及复杂的计算过程。
文章目录
- H.265/HEVC编码原理及其处理流程的分析
- 一、什么是H.265/HEVC?
- 1.1、H.265/HEVC的作用
- 1.2、H.265/HEVC编码框架
- 二、DCT变换和量化
- 2.1、DCT变换
- 2.2、 量化
- 三、H265的预测
- 3.1、帧内预测
- 3.2、帧间估计
- 3.3、 预测方式的选择
- 四、环路滤波
- 五、总结
- 六、参考资料
一、什么是H.265/HEVC?
1.1、H.265/HEVC的作用
♈️H.265/HEVC是一种新的视频压缩标准,而视频是由一张张连续的图片组成的,因此对视频的压缩就可以理解为对一组图片的压缩。30帧的视频就表示一秒有30张的图片,60帧就表示该视频一秒有60张图片,对视频的压缩,就是对一组图片的压缩。由于一个视频里相邻的图片间常常存在大量相同的部分。比如这两张照片,相似度就很高,没必要两张都完整的存储下来。
♉️一张图片是由很多像素点组成,即使同一张图片内部也存在大量相同的部分,比如这张图片的背景几乎全是白色,我们没有必要把每个白色的位置及其像素值全部存储下来,这样既耗费资源又没有必要。
♊️因此,H.265/HEVC主要采用帧内预测(根据同一张图片的其他位置的像素点预测当前位置的像素值), 或者帧间预测(根据其他图片的像素,来推测当前图片) 对组成视频的图片进行压缩,以减少他们的大小。
1.2、H.265/HEVC编码框架
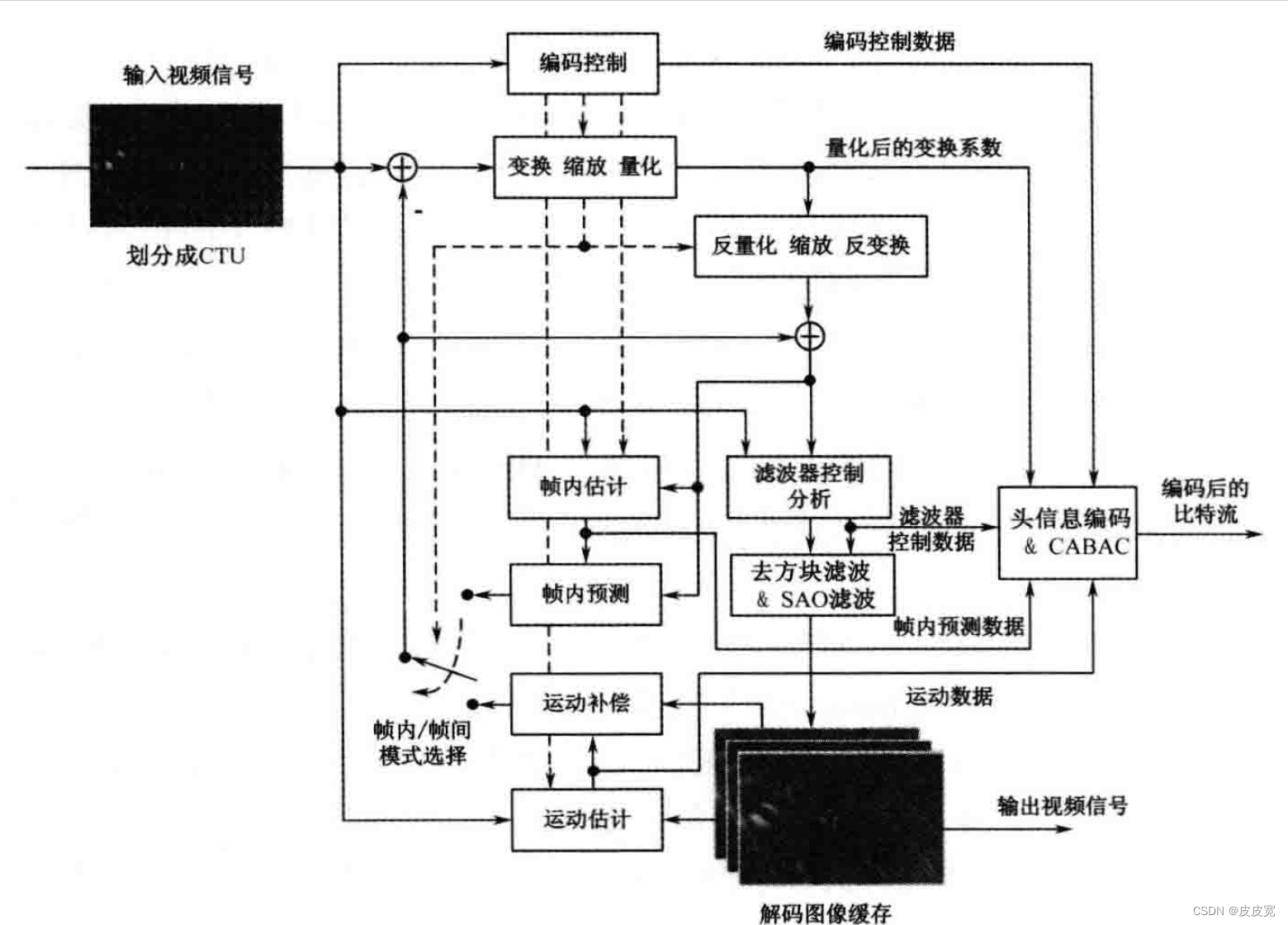
♋️H.265/HEVC的编码框架如图所示,图片来源【1】,本文的主要目的是为了讲清楚这张图展示的处理流程。首先,输入的图片被划分为一个个相似的块(CTU),这些块的大小最大为64*64,通过这样的划分,使得每个CTU的差别都不大。通过合理的划分CTU,可以将图片划分成相似度较高的一个个CTU块,这就是H.265/HEVC的第一步操作。
二、DCT变换和量化
2.1、DCT变换
♌️当一个视频,也就是一组图片的一个CTU输入时,我们先将其进行DCT变换`。
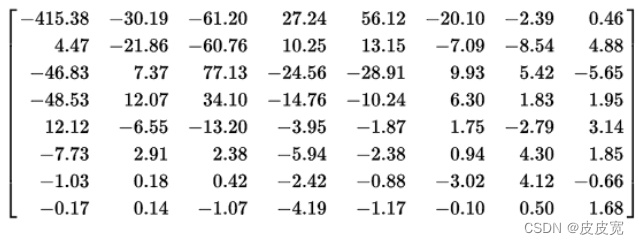
♍️由于我们人眼对高频信息不敏感,比如一张白纸上写一个字,我们对高频率出现的背景白色并不敏感,黑色线条虽然占据较小的比例,但这低频率出现的黑色信号才是我们关注的重点。该图是某个图片经过DCT变换后的结果,由图可以看出(图片来源【2】),DCT变换后得到频域矩阵,低频部分幅度很大(左上角低频,右下角高频),而高频部分幅度较低。
2.2、 量化
♎️ 为了减少存储数据所需要的内存资源。CTU经过DCT变换后,我们再将其进行量化。由于量化步长选取的不一样,造成的精度损失也不一样(参考【3】)。举个例子,如果我们选最小步长是1,向下取整,那么0.6,0.2都将被量化为0,412.6就会被量化为412。可以看到,高频信号由于幅度较小,因此量化后的损失很大,而低频信号由于幅度较大,因此影响较小。毕竟普通人丢了100块钱和富豪丢了100块钱损失是不一样的。
♏️通过DCT变换和量化,在尽可能保持低频、敏感(容易被人眼察觉)信息情况下,对图片进行了压缩。
三、H265的预测
3.1、帧内预测
♐️ 我们通过DCT变换和量化后,要先经过反DCT变换和量化,恢复图像,才能进行进一步预测;恢复的图像和原始图像比,已经是在尽可能保持低频、敏感(容易被人眼察觉)信息情况下,对图片进行了压缩。
♑️ 如第一节所说,由于同一张图片中各个块之间有较强的关联性,且一个CTU块内部的相似度也很高,因此提出了一种帧内预测压缩算法,比如一个图像为
[ 0 2 2 3 0 2 1 3 0 2 2 2 0 1 2 3 ] (2) \begin{bmatrix} 0 & 2 & 2 & 3 \\ 0 & 2 & 1 & 3 \\ 0 & 2 & 2 & 2 \\ 0 & 1 & 2 & 3 \end{bmatrix} \tag{2} 0000222121223323 (2)
♒️ 我们只保留最上面一行的数据【0,2,2,3】,解压缩时,下面几行都直接复制这一行就可以恢复图像
[ 0 2 2 3 0 2 2 3 0 2 2 3 0 2 2 3 ] (2) \begin{bmatrix} 0 & 2 & 2 & 3 \\ 0 & 2 & 2 & 3 \\ 0 & 2 & 2 & 3 \\ 0 & 2 & 2 & 3 \end{bmatrix} \tag{2} 0000222222223333 (2)
♓️ 如图可知,恢复后的图像与原始图像依然有差异,这个差异的成为残差,因此我们不仅要保存帧内压缩的压缩模式(本文只提到了一种),还需要保存残差。DCT变换和量化的意义已经在上节提到过了,我们对残差也是保存通过DCT变换和量化后的残差。
3.2、帧间估计
♓️ 前面也说到了,视频里连续的图片相似度很高,因此H.265/HEVC引入了帧间编码。这个CTU块跟其他哪张图片相似(ref_idx),跟相似图片的具体哪个CTU块相似(mvd),只需要保存ref_idx,和mvd即可,同样的,相似的这个CTU跟当前CTU的差距,依然按残差系数输出
3.3、 预测方式的选择
⛎ H265将各种预测模式所造成的图片的失真(ΔD)和保存这些压缩后的信息所消耗的资源(R)进行计算代价函数(ΔJ),最终选择代价函数最小的模式进行预测,并输出其残差;
四、环路滤波
🔯由于CTU的处理方式,和高频信号损失的原因,因此我们恢复信号时,还需要增加一个去方块滤波和SAO滤波【4】,来减小预测后的图像和原始图像的差距(即,进一步减小残差)。
五、总结
- 🅰️H265先通过DCT变换和量化对图像进行处理,消除其一些不敏感的高频信息,减小信息量
- 🅱️H265选择一种代价函数最小的预测方式(帧内预测,或帧间预测),对图像进行压缩;
- 🆎压缩后的图像,直接恢复的话,和原始图像差距过大,因此需要进行环路滤波缩小这段差距
- 🅾️环路滤波后,依然存在误差,误差也需要被保留(DCT变换和量化后保留)
简单来说,H265就是通过一系列预测算法对视频进行压缩,再将因此产生的和原始图像的差异(残差,失真)保存。解压缩时,就可以通过反预测,加残差的方式恢复图像。
六、参考资料
-
【1】新一代高效视频编码H.265/HEVC:原理、标准与实现,作者:万帅、杨付正;
-
【2】 CSDN博客: JPEG压缩原理与DCT离散余弦变换
-
【3】CSDN博客:pytorch量化中torch.quantize_per_tensor()函数参数详解
-
【4】振铃效应与样点自适应补偿(Sample Adaptive Offset,SAO)技术