一、背景
公司CDH6.3.2里面的版本是Flink1.12.0。而因为FlinkCDC2.0.0只支持Flink1.13.0以后,版本不匹配,所以只能升级版本。但是升级版本是个大工程,要编译、要parcel制作工具,而且是生产环境的升级,没办法因为要测试FlinkCDC,所以只能搭建个单机测试,等后面生产环境升级后再迁移;
二、软件安装
2.1 安装Hadoop单节点
具体的就不介绍了。。。。。
可参照:https://blog.csdn.net/J080624/article/details/67638594
2.2 安装Flink1.13.6
官网下载:https://flink.apache.org/downloads.html
2.2.1 解压安装文件到/opt/module
tar -zxvf flink-1.13.6-bin-scala_2.12.tgz -C /opt/module/
2.2.2 添加Flink到环境变量
[root@localhost ~]# vim /etc/profile.d/my_env.sh
//在my_env.sh文件末尾添加如下内容:
export FLINK_HOME=/opt/module/flink-1.13.6
export PATH=$FLINK_HOME/bin:$PATH
[root@localhost ~]# source /etc/profile
2.2.3 测试
[root@localhost flink-1.13.6]# flink --version
Version: 1.13.6, Commit ID: b2ca390
2.2.4 开启8081端口
打开${flink}/conf/flink-conf.yaml文件,修改一下信息。
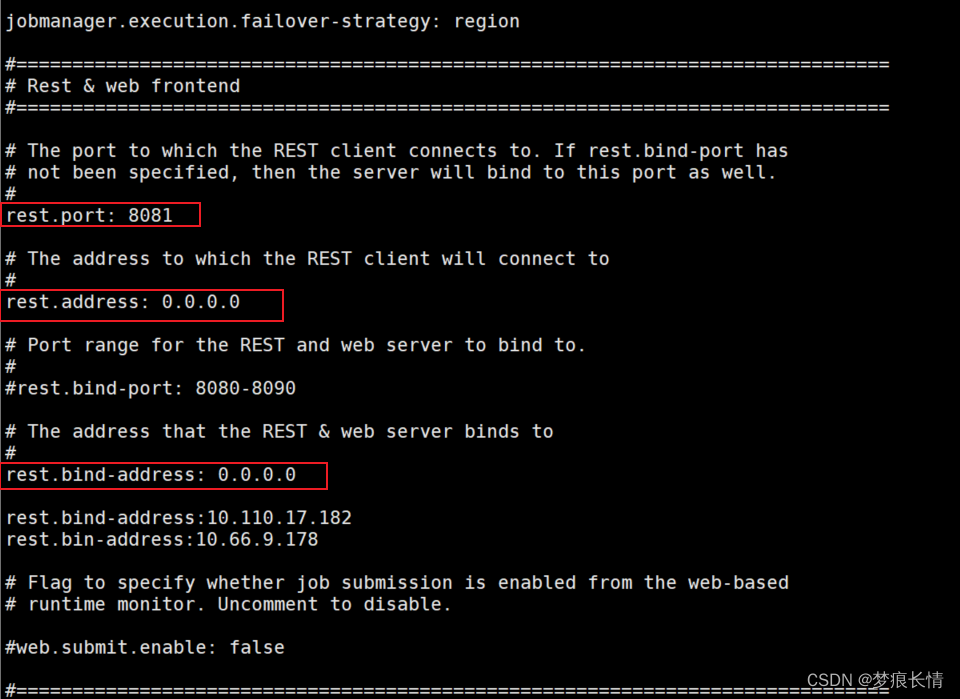
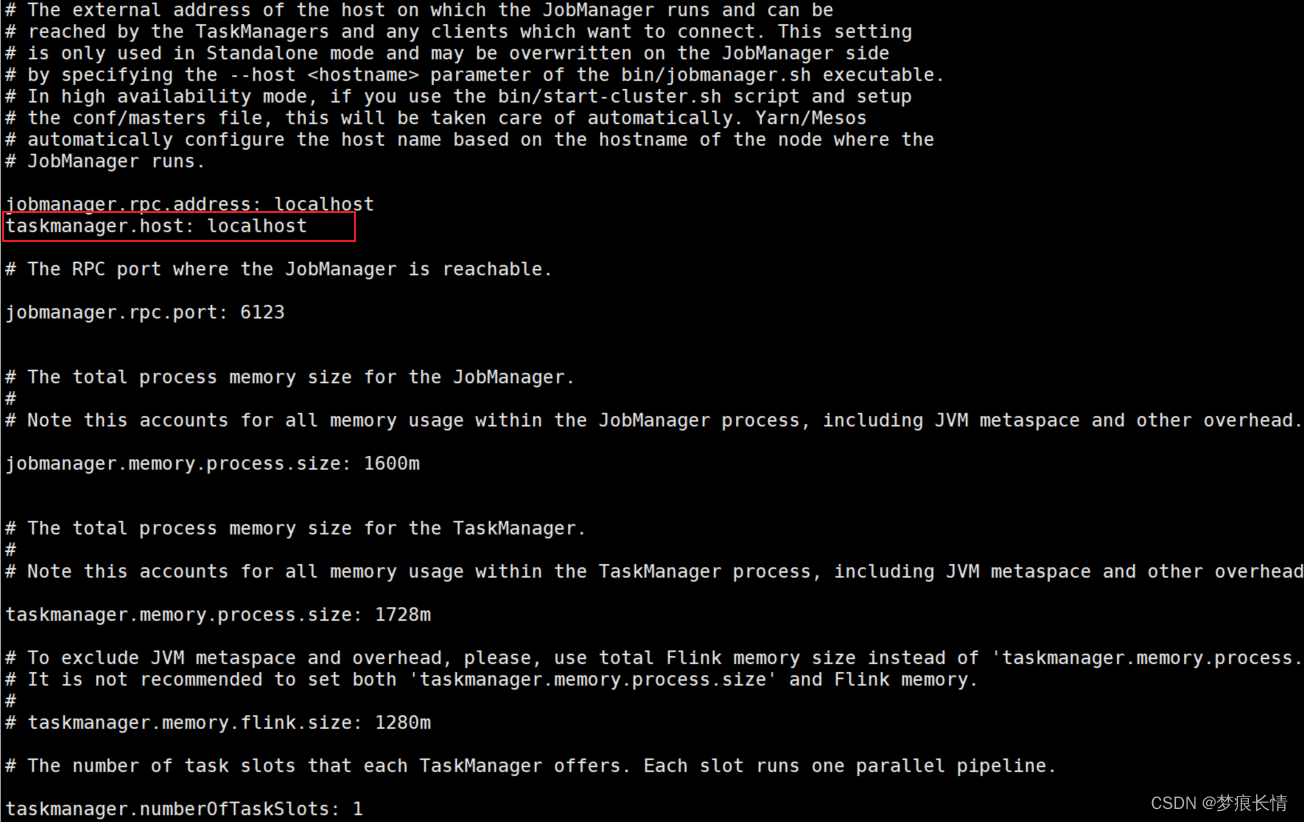
taskmanager.host: localhost要添加,不然会报以下的错:
TaskExecutor akka.tcp://xxx has no more allocated slots for job
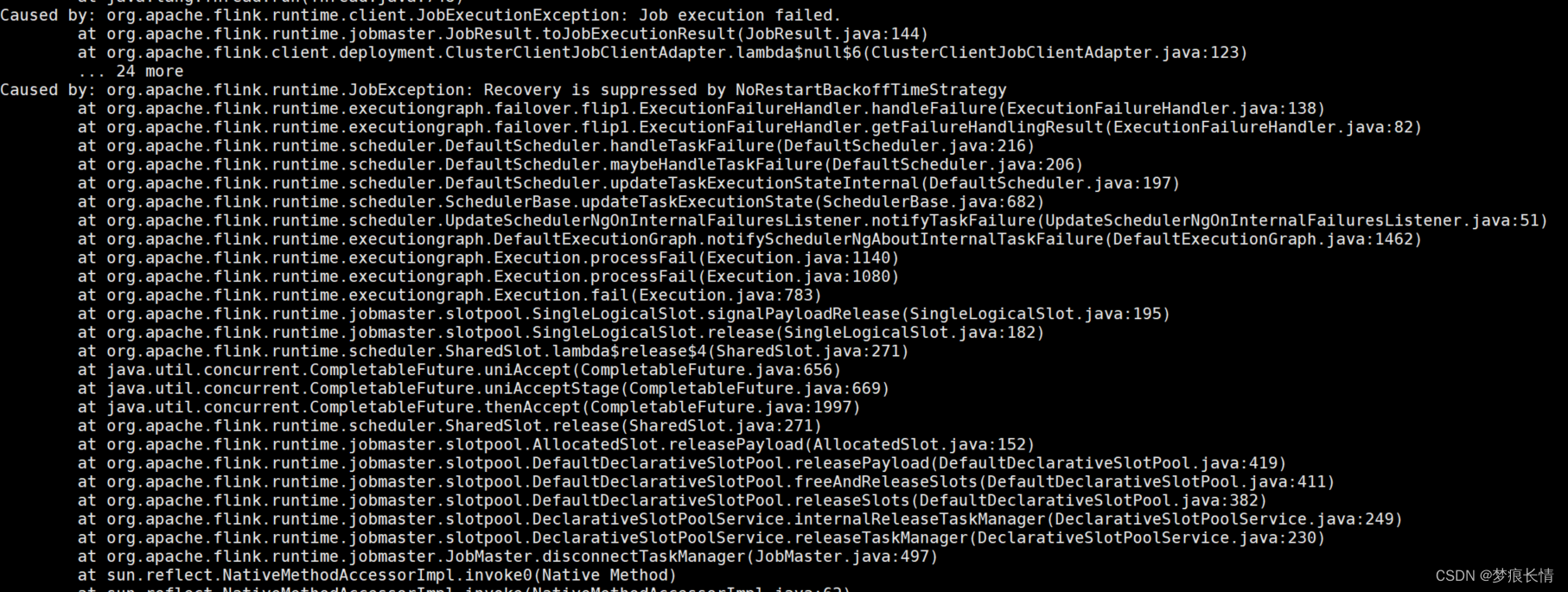
原因:flink部署到集群上,standalone模式,需要指定TaskManager主机的地址:修改flink-conf.yaml配置并添加配置 taskmanager.host: localhost
2.2.5 启动Flink和Hadoop。
[root@locahost hadoop-3.1.3]# ./sbin/start-dfs.sh
[root@locahost flink-1.13.6]# ./bin/start-cluster.sh
[root@locahost bin]# jps
9408 DataNode
21504 TaskManagerRunner
9633 SecondaryNameNode
9285 NameNode
23399 Jps
21210 StandaloneSessionClusterEntrypoint
[root@locahost bin]#
2.2.6 打开UI页面
发现无法打开,原因是防火墙未关闭,联系运维开放8081端口。重新打开;
三、Flink自带代码测试
[root@localhost bin]# ./flink run ../examples/batch/WordCount.jar
Executing WordCount example with default input data set.
Use --input to specify file input.
Printing result to stdout. Use --output to specify output path.
Job has been submitted with JobID aed77c0e3c8d6a7abc0d7ffbd9f86e16
Program execution finished
Job with JobID aed77c0e3c8d6a7abc0d7ffbd9f86e16 has finished.
Job Runtime: 369 ms
Accumulator Results:
- 748bb343c29c89864924c9572dc09c07 (java.util.ArrayList) [170 elements]
(a,5)
(action,1)
(after,1)
(against,1)
(all,2)
(and,12)
(arms,1)
(arrows,1)
(awry,1)
(ay,1)
(bare,1)
(be,4)
(bear,3)
(bodkin,1)
(bourn,1)
(but,1)
(by,2)
(calamity,1)
(cast,1)
(coil,1)
(come,1)
(conscience,1)
(consummation,1)
(contumely,1)
(country,1)
(cowards,1)
(currents,1)
(d,4)
(death,2)
(delay,1)
(despis,1)
(devoutly,1)
(die,2)
(does,1)
(dread,1)
(dream,1)
(dreams,1)
(end,2)
(enterprises,1)
(er,1)
(fair,1)
(fardels,1)
(flesh,1)
(fly,1)
(for,2)
(fortune,1)
(from,1)
(give,1)
(great,1)
(grunt,1)
(have,2)
(he,1)
(heartache,1)
(heir,1)
(himself,1)
(his,1)
(hue,1)
(ills,1)
(in,3)
(insolence,1)
(is,3)
(know,1)
(law,1)
(life,2)
(long,1)
(lose,1)
(love,1)
(make,2)
(makes,2)
(man,1)
(may,1)
(merit,1)
(might,1)
(mind,1)
(moment,1)
(more,1)
(mortal,1)
(must,1)
(my,1)
(name,1)
(native,1)
(natural,1)
(no,2)
(nobler,1)
(not,2)
(now,1)
(nymph,1)
(o,1)
(of,15)
(off,1)
(office,1)
(ophelia,1)
(opposing,1)
(oppressor,1)
(or,2)
(orisons,1)
(others,1)
(outrageous,1)
(pale,1)
(pangs,1)
(patient,1)
(pause,1)
(perchance,1)
(pith,1)
(proud,1)
(puzzles,1)
(question,1)
(quietus,1)
(rather,1)
(regard,1)
(remember,1)
(resolution,1)
(respect,1)
(returns,1)
(rub,1)
(s,5)
(say,1)
(scorns,1)
(sea,1)
(shocks,1)
(shuffled,1)
(sicklied,1)
(sins,1)
(sleep,5)
(slings,1)
(so,1)
(soft,1)
(something,1)
(spurns,1)
(suffer,1)
(sweat,1)
(take,1)
(takes,1)
(than,1)
(that,7)
(the,22)
(their,1)
(them,1)
(there,2)
(these,1)
(this,2)
(those,1)
(thought,1)
(thousand,1)
(thus,2)
(thy,1)
(time,1)
(tis,2)
(to,15)
(traveller,1)
(troubles,1)
(turn,1)
(under,1)
(undiscover,1)
(unworthy,1)
(us,3)
(we,4)
(weary,1)
(what,1)
(when,2)
(whether,1)
(whips,1)
(who,2)
(whose,1)
(will,1)
(wish,1)
(with,3)
(would,2)
(wrong,1)
(you,1)
[root@flink0 bin]#
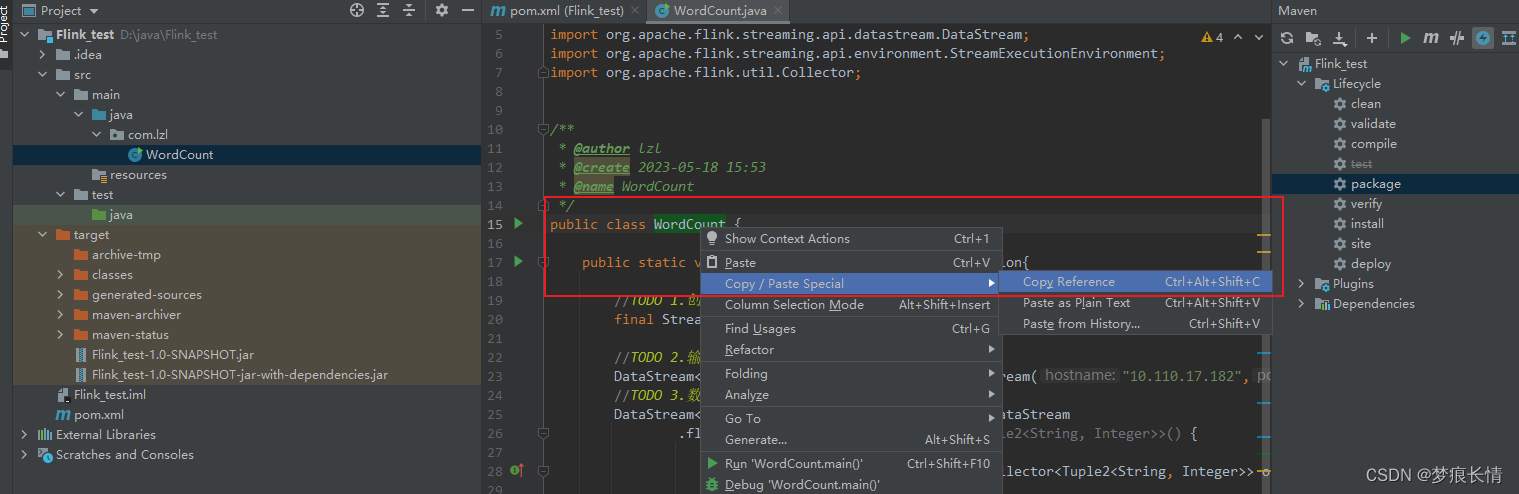
四、自定义wordcount测试
package com.lzl;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @author lzl
* @create 2023-05-18 15:53
* @name WordCount
*/
public class WordCount {
public static void main(String[] args) throws Exception{
//TODO 1.创建环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//TODO 2.输入流窗口的信息配置
DataStream<String> dataStream = env.socketTextStream("10.110.17.182", 9999, "\n");
//TODO 3.数据转换
DataStream<Tuple2<String,Integer>> countData = dataStream
.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] words = value.toLowerCase().split("\\W+");
for(String word:words) {
if (word.length() > 0) {
out.collect(new Tuple2<>(word,1));
}
}
}
}).keyBy(value -> value.f0)
.sum(1);
//TODO 4.数据打印到控制台
countData.print();
//TODO 5.执行任务
env.execute("CountSocketWord");
}
}
本地代码测试报错:
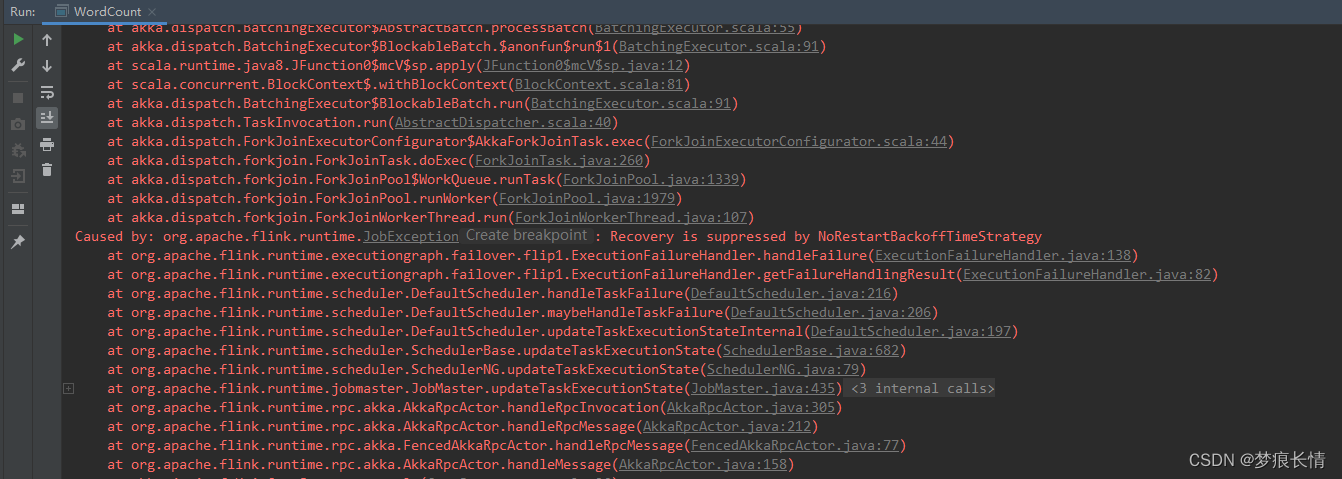
原因:又是防火墙的问题,防火墙没开通9999端口。
[root@flink0 software]# firewall-cmd --zone=public --add-port=9999/tcp --permanent
success
[root@flink0 software]# systemctl restart firewalld
[root@flink0 software]#
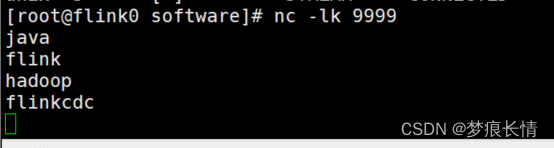
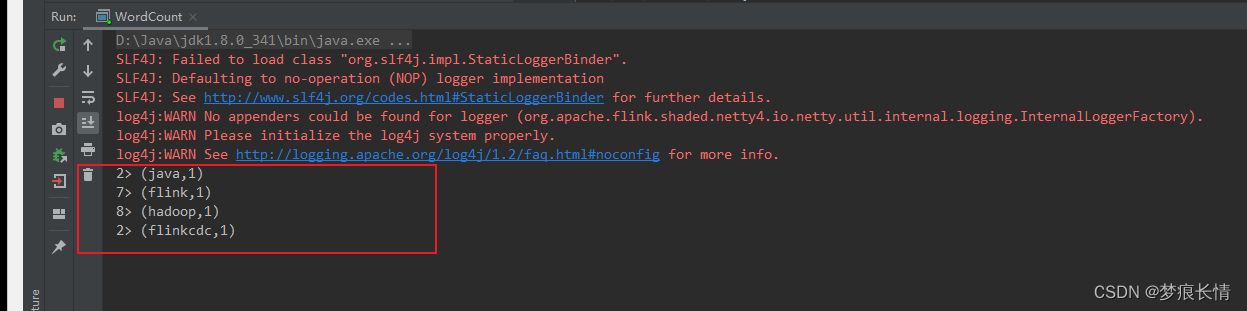
本地测试ok~!
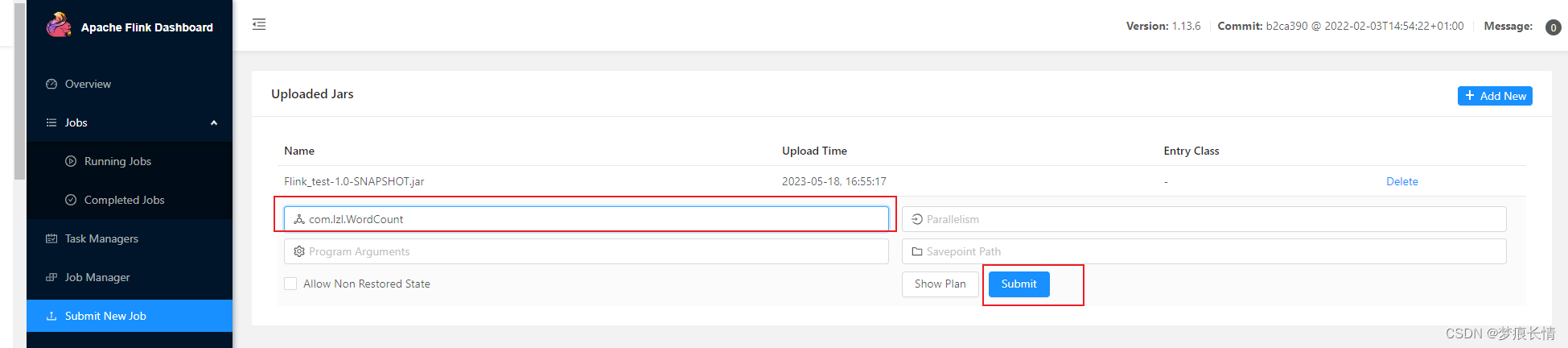
4.2 上传Flink Web测试
填写Entry Class(注意格式,可复制),提交。
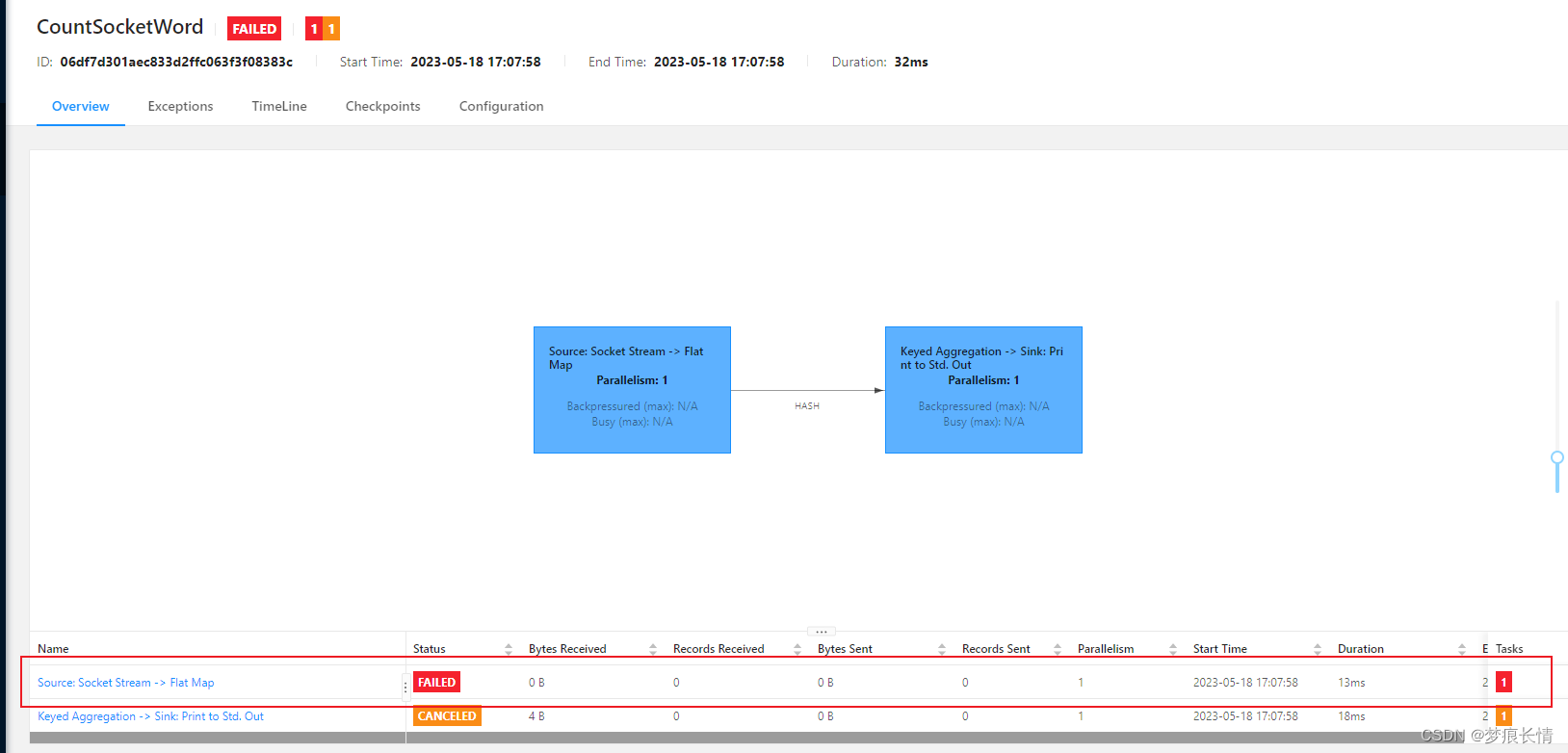
报错:是因为9999端口没启动。

重新提交!
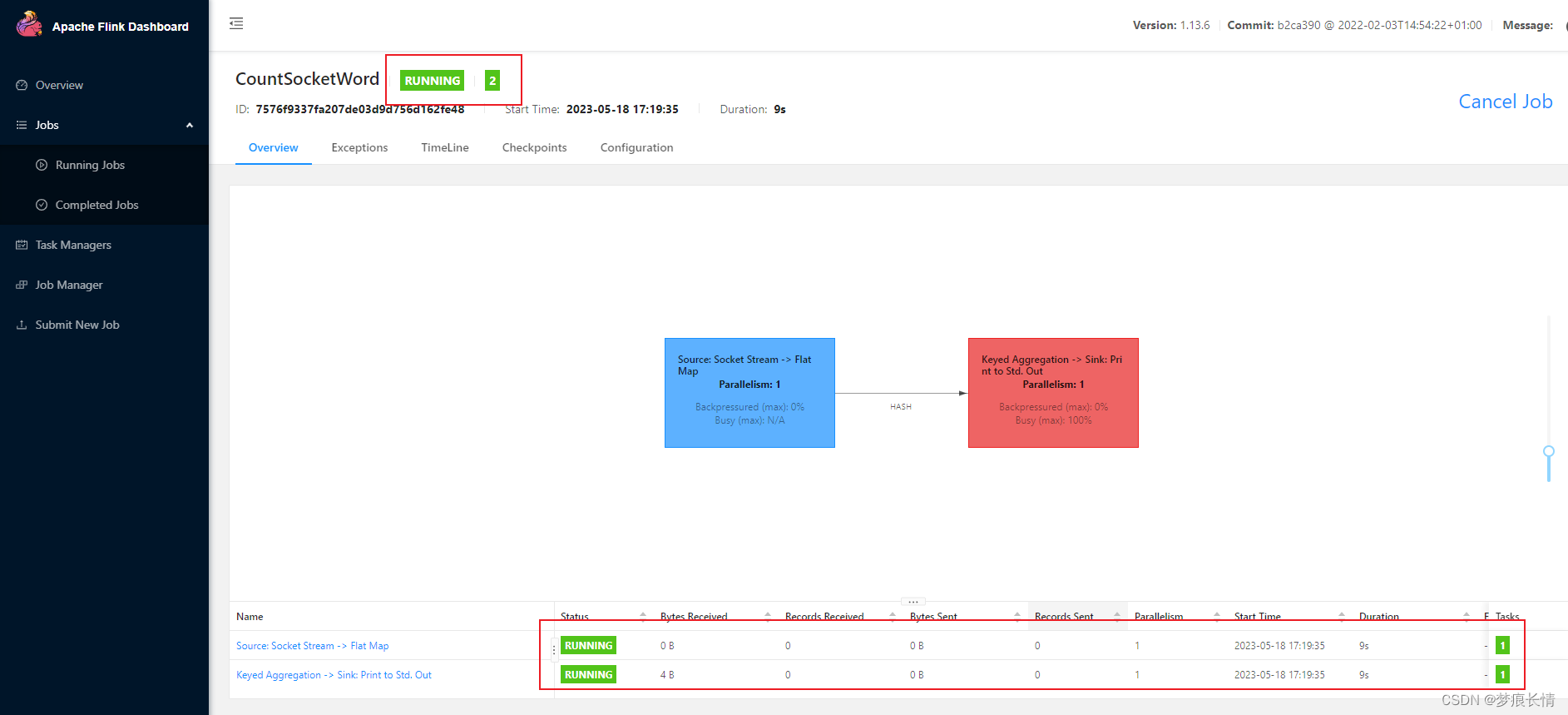
显示running。
输入单词之后,有收到字节大小,以及在标准输出控制台,可以看到它的输出。
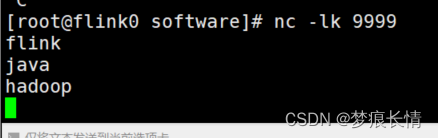

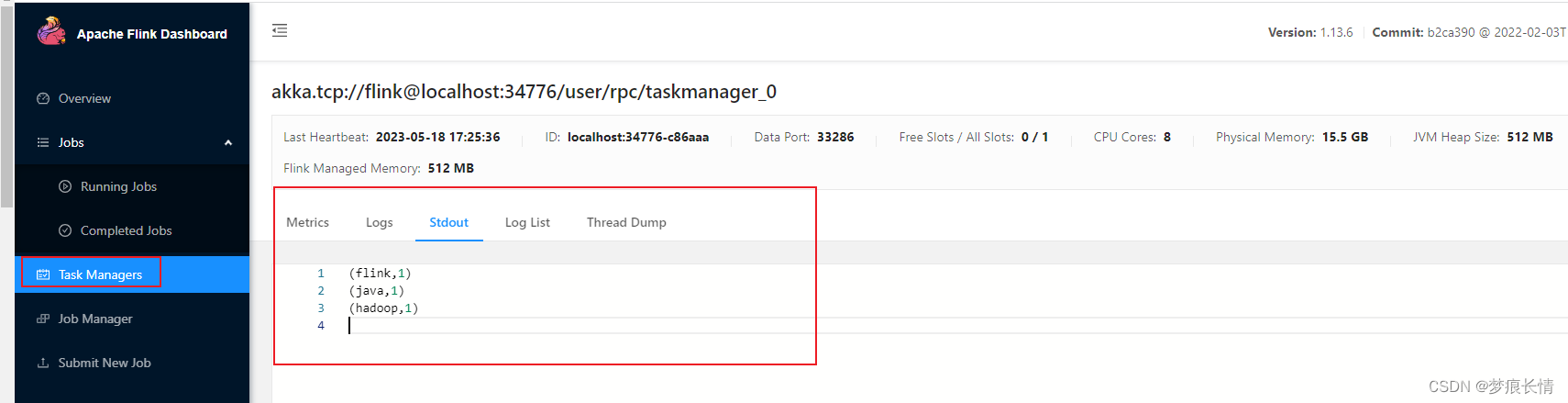
测试ok!
五、FlinkCDC同步MySQL数据测试
5.1 自定义反序列MyDeserializationSchema
package com.lzl;
import com.alibaba.fastjson.JSONObject;
import com.ververica.cdc.debezium.DebeziumDeserializationSchema;
import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.util.Collector;
import org.apache.kafka.connect.data.Field;
import org.apache.kafka.connect.data.Struct;
import org.apache.kafka.connect.source.SourceRecord;
import java.util.List;
/**
* @author lzl
* @create 2023-05-18 15:41
* @name MyDeserializationSchema
*/
public class MyDeserializationSchema implements DebeziumDeserializationSchema<JSONObject> {
private static final long serialVersionUID = -3168848963265670603L;
public MyDeserializationSchema() {
}
@Override
public void deserialize(SourceRecord record, Collector<JSONObject> out) {
Struct dataRecord = (Struct) record.value();
Struct afterStruct = dataRecord.getStruct("after");
Struct beforeStruct = dataRecord.getStruct("before");
/*
todo 1,同时存在 beforeStruct 跟 afterStruct数据的话,就代表是update的数据
2,只存在 beforeStruct 就是delete数据
3,只存在 afterStruct数据 就是insert数据
*/
JSONObject logJson = new JSONObject();
String canal_type = "";
List<Field> fieldsList = null;
if (afterStruct != null && beforeStruct != null) {
System.out.println("这是修改数据");
canal_type = "update";
fieldsList = afterStruct.schema().fields();
//todo 字段与值
for (Field field : fieldsList) {
String fieldName = field.name();
Object fieldValue = afterStruct.get(fieldName);
// System.out.println("*****fieldName=" + fieldName+",fieldValue="+fieldValue);
logJson.put(fieldName, fieldValue);
}
} else if (afterStruct != null) {
System.out.println("这是新增数据");
canal_type = "insert";
fieldsList = afterStruct.schema().fields();
//todo 字段与值
for (Field field : fieldsList) {
String fieldName = field.name();
Object fieldValue = afterStruct.get(fieldName);
// System.out.println("*****fieldName=" + fieldName+",fieldValue="+fieldValue);
logJson.put(fieldName, fieldValue);
}
} else if (beforeStruct != null) {
System.out.println("这是删除数据");
canal_type = "delete";
fieldsList = beforeStruct.schema().fields();
//todo 字段与值
for (Field field : fieldsList) {
String fieldName = field.name();
Object fieldValue = beforeStruct.get(fieldName);
// System.out.println("*****fieldName=" + fieldName+",fieldValue="+fieldValue);
logJson.put(fieldName, fieldValue);
}
} else {
System.out.println("一脸蒙蔽了");
}
//todo 拿到databases table信息
Struct source = dataRecord.getStruct("source");
Object db = source.get("db");
Object table = source.get("table");
Object ts_ms = source.get("ts_ms");
logJson.put("canal_database", db);
logJson.put("canal_table", table);
logJson.put("canal_ts", ts_ms);
logJson.put("canal_type", canal_type);
//todo 拿到topic
String topic = record.topic();
System.out.println("topic = " + topic);
//todo 主键字段
Struct pk = (Struct) record.key();
List<Field> pkFieldList = pk.schema().fields();
int partitionerNum = 0;
for (Field field : pkFieldList) {
Object pkValue = pk.get(field.name());
partitionerNum += pkValue.hashCode();
}
int hash = Math.abs(partitionerNum) % 3;
logJson.put("pk_hashcode", hash);
out.collect(logJson);
}
@Override
public TypeInformation<JSONObject> getProducedType() {
return BasicTypeInfo.of(JSONObject.class);
}
}
5.2 写入MySQL类
package com.lzl;
import com.alibaba.fastjson.JSONObject;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
/**
* @author lzl
* @create 2023-05-12 18:24
* @name Writer
*/
public class MysqlWriter extends RichSinkFunction<JSONObject> {
private static final Logger LOGGER = LoggerFactory.getLogger(MysqlWriter.class);
private Connection connection = null;
private PreparedStatement insertStatement = null;
private PreparedStatement updateStatement = null;
private PreparedStatement deleteStatement= null;
//目标库的信息
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
if (connection == null) {
Class.forName("com.mysql.jdbc.Driver");//加载数据库驱动
connection = DriverManager.getConnection("jdbc:mysql://10.110.17.37:3306/flink_cdc?serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=UTF-8",
"root",
"xxb@5196");//获取连接
}
insertStatement = connection.prepareStatement( // 获取执行语句
"insert into flink_cdc.student_2 values (?,?,?,?)"); //插入数据
updateStatement = connection.prepareStatement( // 获取执行语句
"update flink_cdc.student_2 set name=?,age=?,dt=? where id=?"); //更新数据
deleteStatement = connection.prepareStatement( // 获取执行语句
"delete from flink_cdc.student_2 where id=?"); //删除数据
}
//执行插入和更新语句
@Override
public void invoke(JSONObject value, Context context) throws Exception {
// 获取binlog
Integer id = (Integer) value.get("id");
String name = (String) value.get("name");
Integer age = (Integer) value.get("age");
String dt = (String) value.get("dt");
String canal_type =(String) value.get("canal_type");
if(canal_type =="insert"){
insertStatement.setInt(1, id);
insertStatement.setString(2, name);
insertStatement.setInt(3, age);
insertStatement.setString(4, dt);
insertStatement.execute();
// LOGGER.info(insertStatement.toString();
}
if (canal_type =="update"){
// 每条数据到来后,直接执行更新语句 这里强调注意:1,2,3,4序号必须与占位符(?)对应起来,比如第一位是name,id最后一位
updateStatement.setString(1,name);
updateStatement.setInt(2, age);
updateStatement.setString(3, dt);
updateStatement.setInt(4, id);
updateStatement.execute(); // 执行更新语句
// LOGGER.info(updateStatement.toString());
}
if (canal_type =="delete"){
deleteStatement.setInt(1, id);
deleteStatement.execute();
}
// // 每条数据到来后,直接执行更新语句 这里强调注意:1,2,3,4序号必须与占位符(?)对应起来,比如第一位是name,id最后一位
// updateStatement.setString(1,name);
// updateStatement.setInt(2, age);
// updateStatement.setString(3, dt);
// updateStatement.setInt(4, id);
// updateStatement.execute(); // 执行更新语句
// LOGGER.info(updateStatement.toString());
//如果更新数为0,则执行插入语句
// if(updateStatement.getUpdateCount() == 0)
// insertStatement.setInt(1, id);
// insertStatement.setString(2, name);
// insertStatement.setInt(3, age);
// insertStatement.setString(4, dt);
// insertStatement.execute();
// LOGGER.info(insertStatement.toString());
//
}
//关闭数据库连接
@Override
public void close() throws Exception {
super.close();
if (connection != null) {
connection.close();
}
if (updateStatement != null) {
updateStatement.close();
}
if (insertStatement != null) {
insertStatement.close();
}
// super.close();
}
}
5.3 主类
Flink_CDC_To_MySqlBinlog
package com.lzl;
import com.alibaba.fastjson.JSONObject;
import com.ververica.cdc.connectors.mysql.MySqlSource;
import com.ververica.cdc.connectors.mysql.table.StartupOptions;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
/**
* @author lzl
* @create 2023-05-18 17:33
* @name Flink_CDC_To_MySqlBinlog
*/
public class Flink_CDC_To_MySqlBinlog {
public static void main(String[] args) throws Exception{
//TODO 1.获取Flink的执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//TODO 2.Flink-CDC将读取 binlog的位置信息以状态的方式保存在 CK,如果想要做到断点续传 ,需要从 Checkpoint或者 Savepoint启动程序
//2.1 开启 Checkpoint,每隔 5秒钟做一次 CK
env.enableCheckpointing(5000L);
//2.2 指定 CK的一致性语义
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//2.3 设置任务关闭的时候保留最后一次 CK数据
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//2.4 指定从 CK自动重启策略
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 2000L));
//2.5 设置状态后端
env.setStateBackend(new FsStateBackend("hdfs://flink0:8020/flinkCDCTest"));
//2.6 设置访问 HDFS的用户名
System.setProperty("HADOOP_USER_NAME", "root");
//TODO 3.通过FlinkCDC构建SourceFunction
// DebeziumSourceFunction<String> sourceFunction = MySqlSource.<String>builder()
SourceFunction<JSONObject> sourceFunction = MySqlSource.<JSONObject>builder()
.hostname("10.110.17.52")
.port(3306)
.username("root")
.password("xxb@5196")
.databaseList("flink_cdc")
.tableList("flink_cdc.student") //表前一定要加上库名
.deserializer(new MyDeserializationSchema()) //自己定义反序列
.startupOptions(StartupOptions.initial()) //全量同步
.build();
//TODO 4.使用 CDC Source从 MySQL读取数据
// DataStreamSource<String> dataStreamSource = env.addSource(sourceFunction);
DataStreamSource<JSONObject> dataStream = env.addSource(sourceFunction);
//TODO 5.数据打印
dataStream.print("=====>>>>>>>");
//TODO 6.写入另一个MySQL中
dataStream.addSink(new MysqlWriter());
//TODO 7.启动任务
env.execute("Flink_CDC_To_MySqlBinlog");
}
}
5.4 打包上传
打包顺序:先clean–>再build–>package
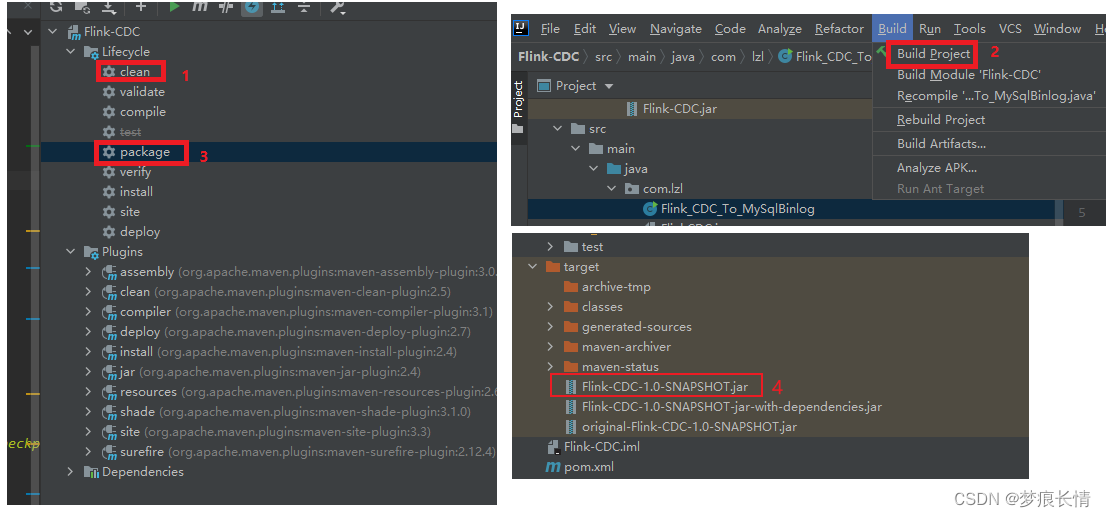
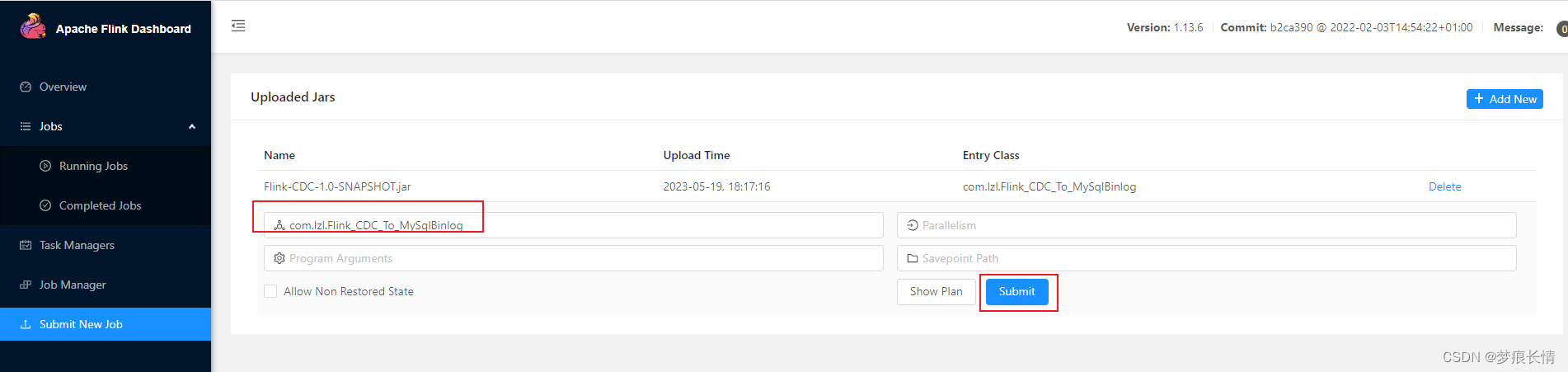

查看控制台标准输出:
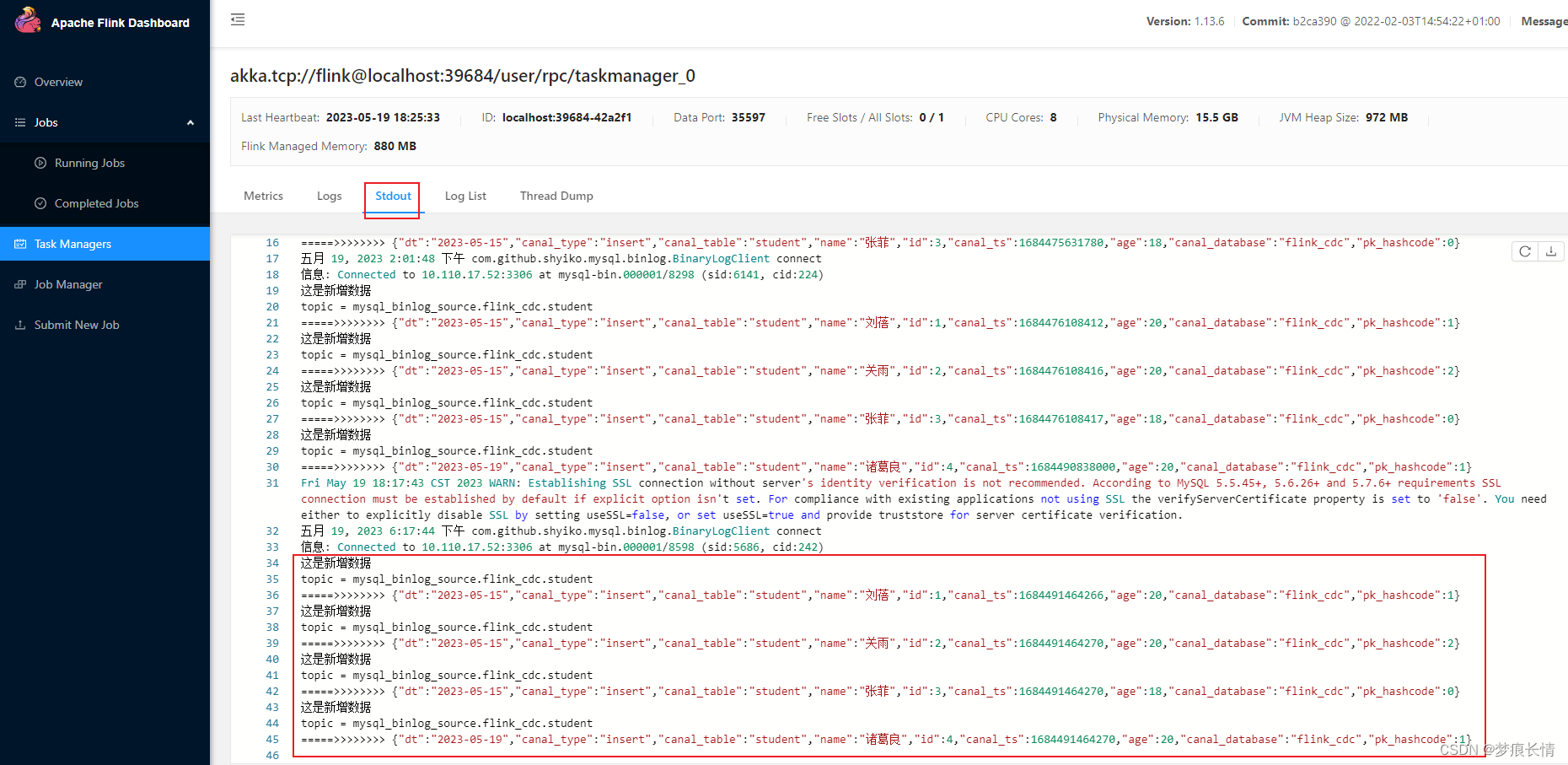
5.5 验证MySQL的增删改同步
新增:
源数据库:
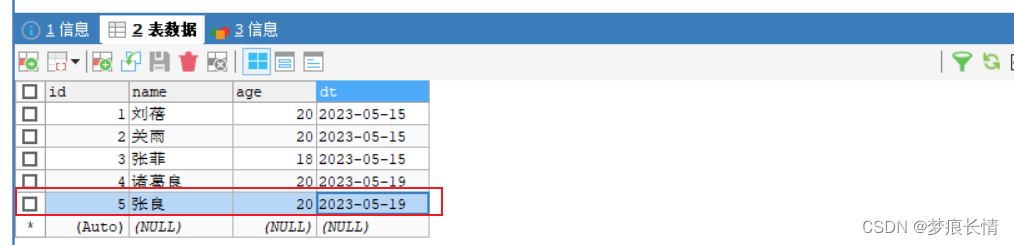
Flink控制台:
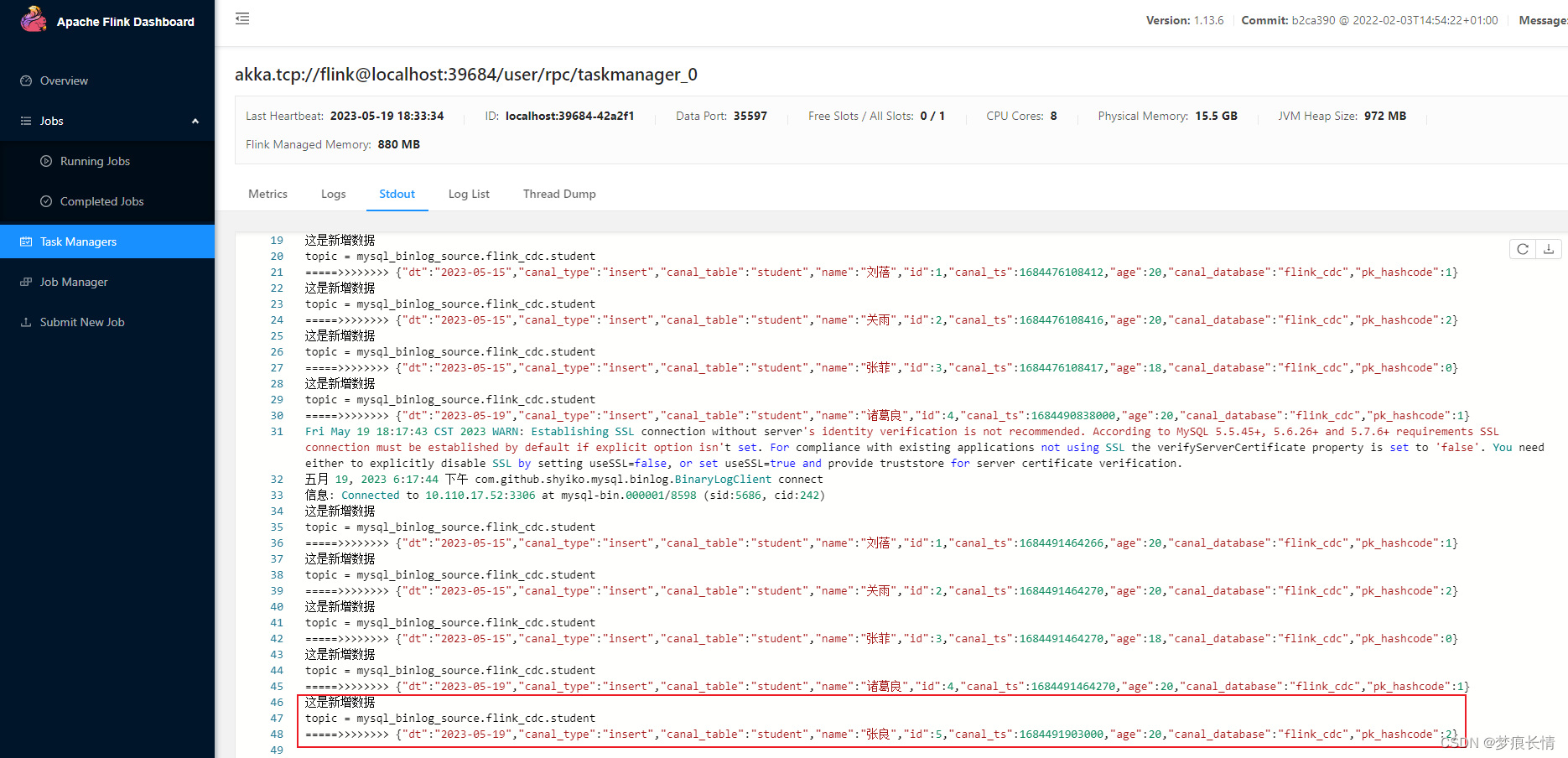
目标库:
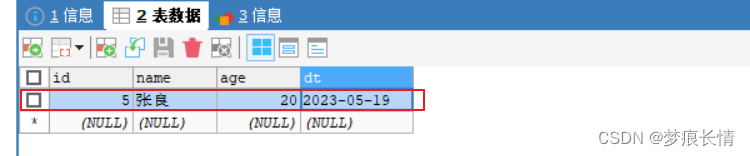
更改:(张良年龄改为18)
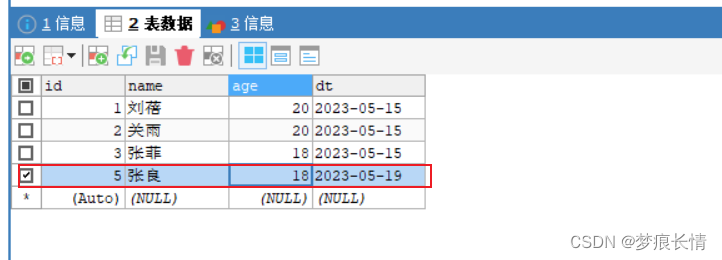

目标库:
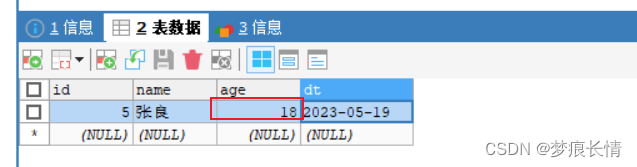
删除:(删掉张良这一条数据)

目标库:
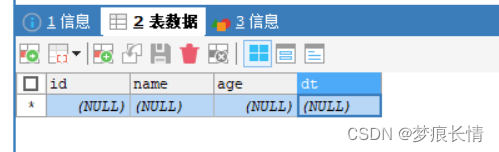
实现了数据的增删改同步~!。
5.6 、查看Hadoop上的CK检查点存储~!
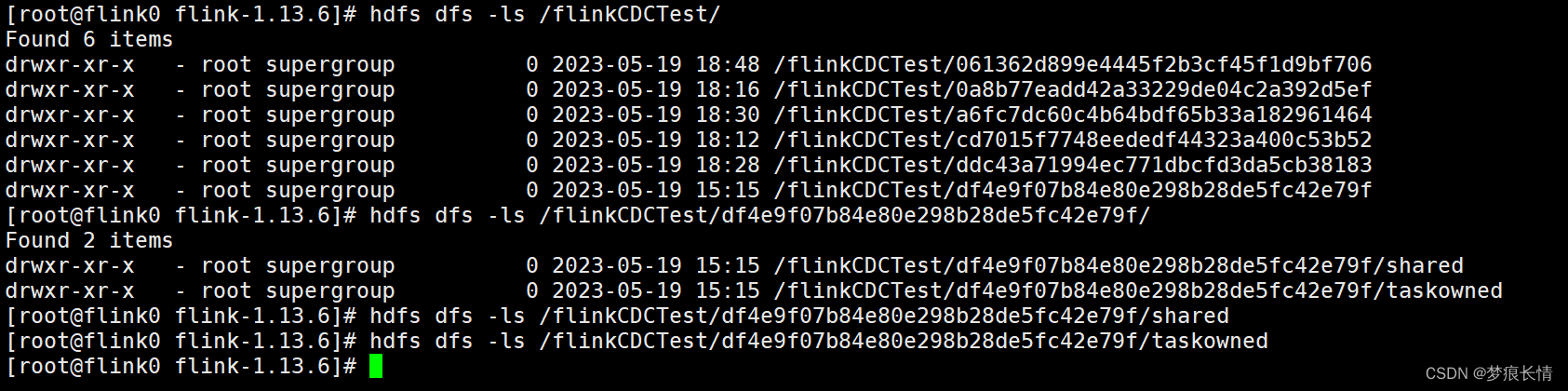
CK也存储成功!

![[Hadoop]Apache Hadoop、HDFS](https://img-blog.csdnimg.cn/92dd458754534d6d9506357057eda08c.png)



![[Windows驱动开发]-BlackBone实现内存读取的三种方式](https://img-blog.csdnimg.cn/img_convert/2cd131d6fc4e4fb9cdd03ab94890e95d.webp?x-oss-process=image/format,png)