前言
仅记录学习笔记,如有错误欢迎指正。
一、哈希函数和哈希表:
hash():
(1) 输入是无限的,输出有限!
(2)相同的输入,相同的输出(无随机因子)
(3)不同的输入,也可能相同的输出 (hash碰撞,概率极低)
(4)不同的输入,但是分布具有均匀性
一致性哈希原理:
key的选择:尽量种类多

因为一致性Hash算法对于节点的增减都只需重定位环空间中的一小部分数据,只有部分缓存会失效,不至于将所有压力都在同一时间集中到后端服务器上,具有较好的容错性和可扩展性。(增减机器数据迁移工作量大大减少)
问题1:如果机器数据少,怎么把环均分?
问题2:增减机器怎么负载均衡?
解决方案:虚拟节点
一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点,一个实际物理节点可以对应多个虚拟节点,虚拟节点越多,hash环上的节点就越多,缓存被均匀分布的概率就越大,hash环倾斜所带来的影响就越小,同时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射。
题目:
一个大文件,文件中都是无符号的整数(0-2^32),40亿个数字,
1g内存,返回出现次数最多的数字!
思路:
对于每一个数做hash运算,取模100,得到100个文件夹分别存模后的数据,
因为均匀性,所以文件中的数字数量基本一致,相同的数字肯定都在一个文件中,
之后在对每个文件找出现次数最多数字,100个文件找出100个数字,再取出现最多的数字!
布隆过滤器:(通过hash计算值的)
就是bitmap实现的!
布隆过滤器优缺点 :
下图hash1(key)=1,那么在第2个格子将0变为1(数组是从0开始计数的),hash2(key)=7,那么将第8个格子置位1,依次类推。
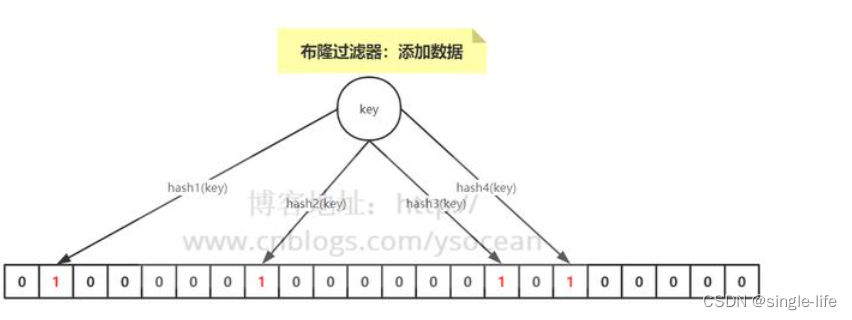
怎么判断数据是否存在?
只要把这个数据的hash值找出来,去看value是不是1,不是1就肯定不存在,是1就可能存在,还有可能是其他数据。
优点:优点很明显,二进制组成的数组,占用内存极少,并且插入和查询速度都足够快。
缺点:随着数据的增加,误判率会增加;还有无法判断数据一定存在;另外还有一个重要缺点,无法删除数据。
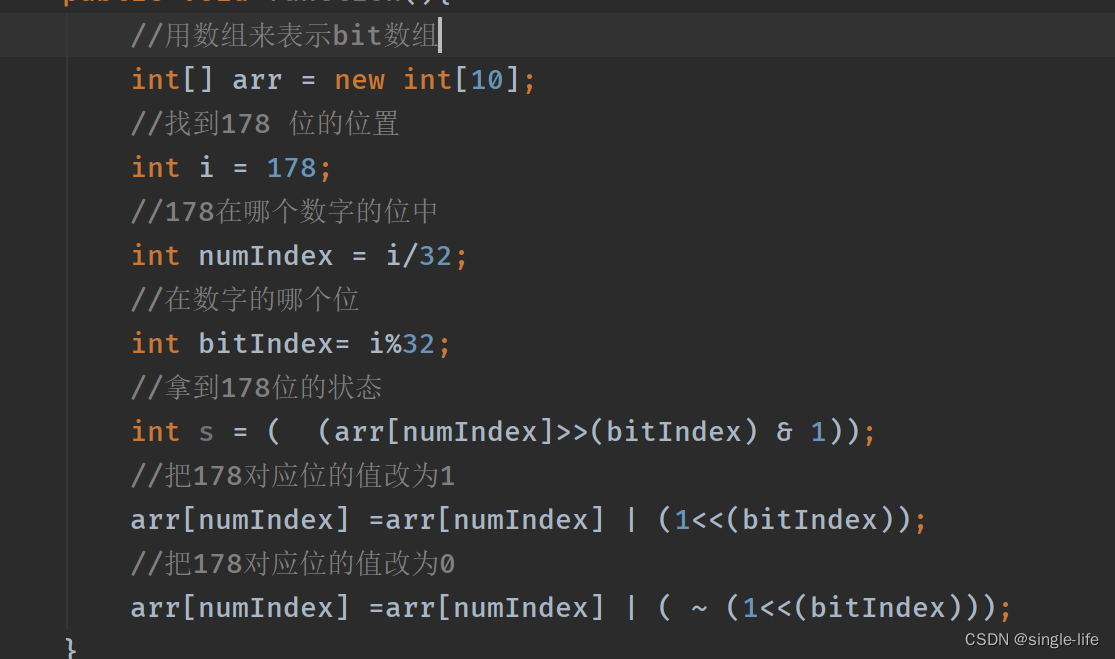
BitMap:
占用空间1B,很小
用int类型表示bit类型
二、大数据类型题目:

题目1.

思路:
法一:
利用磁频统计数量来定位没出现的数字,如果只有3kb,约等于512B,用40亿除512=x
然后遍历40亿数字,用每个数字/x 出来的范围++,肯定有某个范围小于x的数量。
然后在当前范围内用bitmap,存在置为1,再次遍历 为0的数字就是不存在的数据
法二:
或者利用0~40亿二分,最多遍历32次,把数字所在区间找出来、
然后在当前范围内用bitmap,存在置为1,再次遍历 为0的数字就是不存在的数据
题目2:

法一:把大文件hash后取模为小文件,之后去小文件中统计重复的url,汇总
法二:利用布隆过滤器,每次插入的数据的时候先去查询是否已经存在,存在则保存。(有一定误判率)
补充问题:(利用小根堆)
hash为小文件之后,把各个文件的内容以出现次数作大根堆处理,然后新增一个总的大根堆用来存放各个小文件的堆顶,此时弹出总堆的堆顶;
这个值为所有搜索内容的top1,然后看top1来自于哪个小文件中,删除该小文件中的堆顶,重复以上过程找出top2,top3.。
题目三:
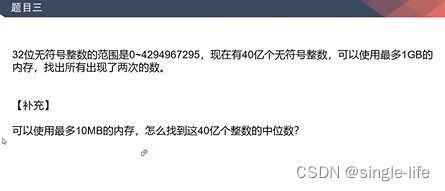
思路:
可以用位图,两位来表示状态,00表示没出现过,01表示出现一次,10表示2次,11表示出现2次以上
补充思路:按照题目1的法一,累加前n个文件的数量,看第20亿左右数字出现在哪个文件,然后继续分割该文件的内容,直到精确找出第20亿个数字就是中位数。
题目四:
10g的文件,内容为无序的正整数,给你5g内存,怎么生成一个新文件,文件内容为有序的数字。(2021Goggle面试题)
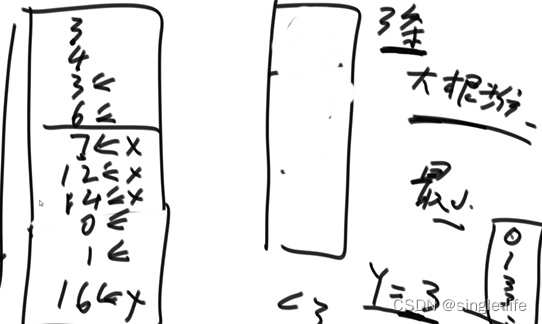
建立一个大根堆去遍历文件,找出最大值小于y的数字和频率,写入另一个文件,然后y变大,
找出大于之前y,小于当前y的数字,重复此过程
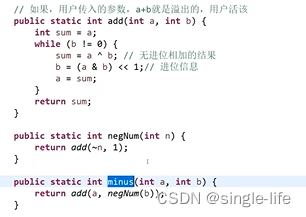
三、位运算题目:

思路:利用位运算,获取符号位,判断a的符号,b的符号,a-b的符号
通过符号来判断a,b的大小

getMax1方法a-b可能会有溢出,所以有了getMax2()
为什么能用+来表示if的意思,因为difSab和SameSab是互斥关系!
在这里插入图片描述
位运算题目二:
判断一个32位数是不是2的幂或者4的幂
思路:
如果是2的幂,那么32位只能有一个1,如000000…001就是2的0次方
x &(x-1)==0 可以判断是否只有一个1
判断4的幂的前提:首先是2的幂,其次1的位置是在0,2,4,8…位上

题目三:

除法建议自行百度。比较难理解。




![[附源码]计算机毕业设计保护濒危动物公益网站Springboot程序](https://img-blog.csdnimg.cn/8e370b9f206f4c05ba155487d4d371e0.png)