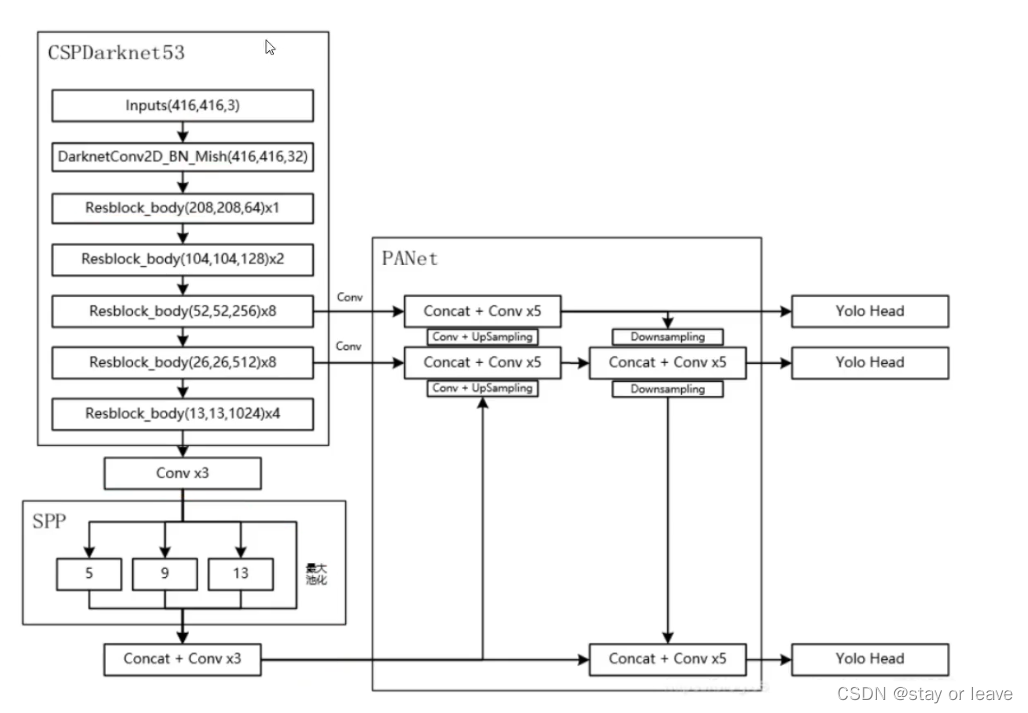
Apache Flink 是大数据领域又一新兴框架。它与 Spark 的不同之处在于,它是使用流式处理来模拟批量处理的,因此能够提供亚秒级的、符合 Exactly-once 语义的实时处理能力。Flink 的使用场景之一是构建实时的数据通道,在不同的存储之间搬运和转换数据。本文将介绍如何使用 Flink 开发实时 ETL 程序,并介绍 Flink 是如何保证其 Exactly-once 语义的。
示例程序
让我们来编写一个从 Kafka 抽取数据到 HDFS 的程序。数据源是一组事件日志,其中包含了事件发生的时间,以时间戳的方式存储。我们需要将这些日志按事件时间分别存放到不同的目录中,即按日分桶。时间日志示例如下:
{"timestamp":1545184226.432,"event":"page_view","uuid":"ac0e50bf-944c-4e2f-bbf5-a34b22718e0c"}
{"timestamp":1545184602.640,"event":"adv_click","uuid":"9b220808-2193-44d1-a0e9-09b9743dec55"}
{"timestamp":1545184608.969,"event":"thumbs_up","uuid":"b44c3137-4c91-4f36-96fb-80f56561c914"}产生的目录结构为:
/user/flink/event_log/dt=20181219/part-0-1
/user/flink/event_log/dt=20181220/part-1-9创建 Flink 项目
官方提供了快速生成 Flink 项目的模板,可以直接运行下面命令,这里我使用的是 flink 1.9 版本
$ mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-scala \
-DarchetypeVersion=1.9.0将生成好的代码导入到 IDE 中,可以看到名为 StreamingJob 的文件,我们由此开始编写程序。
Kafka 数据源
Flink 对 Kafka 数据源提供了 原生支持,我们需要选择正确的 Kafka 依赖版本,将其添加到 POM 文件中:
Properties props = new Properties();
props.setProperty("bootstrap.servers", "localhost:9092");
FlinkKafkaConsumer010 consumer = new FlinkKafkaConsumer010 < > (
"flink_test", new SimpleStringSchema(), props);
DataStream stream = env.addSource(consumer);Flink 会连接本地的 Kafka 服务,读取 flink_test 主题中的数据,转换成字符串后返回。除了 SimpleStringSchema,Flink 还提供了其他内置的反序列化方式,如 JSON、Avro 等,我们也可以编写自定义逻辑。
流式文件存储
StreamingFileSink 替代了先前的 BucketingSink,用来将上游数据存储到 HDFS 的不同目录中。它的核心逻辑是分桶,默认的分桶方式是 DateTimeBucketAssigner,即按照处理时间分桶。处理时间指的是消息到达 Flink 程序的时间,这点并不符合我们的需求。因此,我们需要自己编写代码将事件时间从消息体中解析出来,按规则生成分桶的名称:
public class EventTimeBucketAssigner implements BucketAssigner < String, String > {@
Override
public String getBucketId(String element, Context context) {
JsonNode node = mapper.readTree(element);
long date = (long)(node.path("timestamp").floatValue() * 1000);
String partitionValue = new SimpleDateFormat("yyyyMMdd").format(new Date(date));
return "dt=" + partitionValue;
}
}上述代码会使用 Jackson 库对消息体进行解析,将时间戳转换成日期字符串,添加前缀后返回。如此一来,StreamingFileSink 就能知道应该将当前记录放置到哪个目录中了。完整代码可以参考 GitHub(链接)。
StreamingFileSink sink = StreamingFileSink
.forRowFormat(new Path("/tmp/kafka-loader"), new SimpleStringEncoder())
.withBucketAssigner(new EventTimeBucketAssigner())
.build();
stream.addSink(sink);forRowFormat 表示输出的文件是按行存储的,对应的有 forBulkFormat,可以将输出结果用 Parquet 等格式进行压缩存储。
关于 StreamingFileSink 还有一点要注意,它只支持 Hadoop 2.7 以上的版本,因为需要用到高版本文件系统提供的 truncate 方法来实现故障恢复,这点下文会详述。
开启检查点
代码编写到这里,其实已经可以通过 env.execute() 来运行了。但是,它只能保证 At-least-once 语义,即消息有可能会被重复处理。要做到 Exactly-once,我们还需要开启 Flink 的检查点功能:
env.enableCheckpointing(60 _000);
env.setStateBackend((StateBackend) new FsStateBackend("/tmp/flink/checkpoints"));
env.getCheckpointConfig().enableExternalizedCheckpoints(
ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION);检查点(Checkpoint)是 Flink 的故障恢复机制,同样会在下文详述。代码中,我们将状态存储方式由 MemoryStateBackend 修改为了 FsStateBackend,即使用外部文件系统,如 HDFS,来保存应用程序的中间状态,这样当 Flink JobManager 宕机时,也可以恢复过来。Flink 还支持 RocksDBStateBackend,用来存放较大的中间状态,并能支持增量的状态更新。
提交与管理脚本
Flink 程序可以直接在 IDE 中调试。我们也可以搭建一个本地的 Flink 集群,并通过 Flink CLI 命令行工具来提交脚本:
bin/flink run -c com.shzhangji.flinksandbox.kafka.KafkaLoader target/flink-sandbox-0.1.0.jar脚本的运行状态可以在 Flink 仪表盘中查看:
使用暂存点来停止和恢复脚本
当需要暂停脚本、或对程序逻辑进行修改时,我们需要用到 Flink 的暂存点机制(Savepoint)。暂存点和检查点类似,同样保存的是 Flink 各个算子的状态数据(Operator State)。不同的是,暂存点主要用于人为的脚本更替,而检查点则主要由 Flink 控制,用来实现故障恢复。flink cancel -s 命令可以在停止脚本的同时创建一个暂存点:
$ bin/flink cancel -s /tmp/flink/savepoints 1253cc85e5c702dbe963dd7d8d279038
Cancelled job 1253cc85e5c702dbe963dd7d8d279038. Savepoint stored in file:/tmp/flink/savepoints/savepoint-1253cc-0df030f4f2ee.具体到我们的 ETL 示例程序,暂存点中保存了当前 Kafka 队列的消费位置、正在写入的文件名等。当需要从暂存点恢复执行时,可以使用 flink run -s 传入目录位置。Flink 会从指定偏移量读取消息队列,并处理好中间结果文件,确保没有缺失或重复的数据。
flink run -s /tmp/flink/savepoints/savepoint-1253cc-0df030f4f2ee -c com.shzhangji.flinksandbox.kafka.KafkaLoader target/flink-sandbox-0.1.0.jar在 YARN 上运行
要将脚本提交到 YARN 集群上运行,同样是使用 flink run 命令。首先将代码中指定文件目录的部分添加上 HDFS 前缀,如 hdfs://localhost:9000/,重新打包后执行下列命令:
$ export HADOOP_CONF_DIR=/path/to/hadoop/conf
$ bin/flink run -m yarn-cluster -c com.shzhangji.flinksandbox.kafka.KafkaLoader target/flink-sandbox-0.1.0.jar
Submitted application application_1545534487726_0001Flink 仪表盘会在 YARN Application Master 中运行,我们可以通过 ResourceManager 界面进入。返回的应用 ID 可以用来管理脚本,添加 -yid 参数即可:
bin/flink cancel -s hdfs://localhost:9000/tmp/flink/savepoints -yid application_1545534487726_0001 84de00a5e193f26c937f72a9dc97f386Flink 如何保证 Exactly-once 语义
Flink 实时处理程序可以分为三个部分,数据源、处理流程、以及输出。不同的数据源和输出提供了不同的语义保证,Flink 统称为 连接器。处理流程则能提供 Exactly-once 或 At-least-once 语义,需要看检查点是否开启。
实时处理与检查点
Flink 的检查点机制是基于 Chandy-Lamport 算法的:Flink 会定时在数据流中安插轻量的标记信息(Barrier),将消息流切割成一组组记录;当某个算子处理完一组记录后,就将当前状态保存为一个检查点,提交给 JobManager,该组的标记信息也会传递给下游;当末端的算子(通常是 Sink)处理完这组记录并提交检查点后,这个检查点将被标记为“已完成”;当脚本出现问题时,就会从最后一个“已完成”的检查点开始重放记录。
如果算子有多个上游,Flink 会使用一种称为“消息对齐”的机制:如果某个上游出现延迟,当前算子会停止从其它上游消费消息,直到延迟的上游赶上进度,这样就保证了算子中的状态不会包含下一批次的记录。显然,这种方式会引入额外的延迟,因此除了这种 EXACTLY_ONCE 模式,我们也可将检查点配置为 AT_LEAST_ONCE,以获得更高的吞吐量。具体方式请参考 官方文档。
可重放的数据源
当出错的脚本需要从上一个检查点恢复时,Flink 必须对数据进行重放,这就要求数据源支持这一功能。Kafka 是目前使用得较多的消息队列,且支持从特定位点进行消费。具体来说,FlinkKafkaConsumer 类实现了 CheckpointedFunction 接口,会在检查点中存放主题名、分区名、以及偏移量:
abstract class FlinkKafkaConsumerBase implements CheckpointedFunction {
public void initializeState(FunctionInitializationContext context) {
OperatorStateStore stateStore = context.getOperatorStateStore();
this.unionOffsetStates = stateStore.getUnionListState(new ListStateDescriptor < > (
OFFSETS_STATE_NAME,
TypeInformation.of(new TypeHint < Tuple2 < KafkaTopicPartition, Long >> () {})));
if (context.isRestored()) {
for (Tuple2 < KafkaTopicPartition, Long > kafkaOffset: unionOffsetStates.get()) {
restoredState.put(kafkaOffset.f0, kafkaOffset.f1);
}
}
}
public void snapshotState(FunctionSnapshotContext context) {
unionOffsetStates.clear();
for (Map.Entry < KafkaTopicPartition, Long > kafkaTopicPartitionLongEntry: currentOffsets.entrySet()) {
unionOffsetStates.add(Tuple2.of(kafkaTopicPartitionLongEntry.getKey(),
kafkaTopicPartitionLongEntry.getValue()));
}
}
}当数据源算子从检查点或暂存点恢复时,我们可以在 TaskManager 的日志中看到以下信息,表明当前消费的偏移量是从算子状态中恢复出来的:
2018-12-23 10:56:47,380 INFO FlinkKafkaConsumerBase
Consumer subtask 0 will start reading 2 partitions with offsets in restored state:
{KafkaTopicPartition{topic='flink_test', partition=1}=725,
KafkaTopicPartition{topic='flink_test', partition=0}=721}恢复写入中的文件
程序运行过程中,StreamingFileSink 首先会将结果写入中间文件,以 . 开头、in-progress 结尾。这些中间文件会在符合一定条件后更名为正式文件,取决于用户配置的 RollingPolicy,默认策略是基于时间(60 秒)和基于大小(128 MB)。当脚本出错或重启时,中间文件会被直接关闭;在恢复时,由于检查点中保存了中间文件名和成功写入的长度,程序会重新打开这些文件,切割到指定长度(Truncate),然后继续写入。这样一来,文件中就不会包含检查点之后的记录了,从而实现 Exactly-once。
以 Hadoop 文件系统举例,恢复的过程是在 HadoopRecoverableFsDataOutputStream 类的构造函数中进行的。它会接收一个 HadoopFsRecoverable 类型的结构,里面包含了中间文件的路径和长度。这个对象是 BucketState 的成员,会被保存在检查点中。
HadoopRecoverableFsDataOutputStream(FileSystem fs, HadoopFsRecoverable recoverable) {
this.tempFile = checkNotNull(recoverable.tempFile());
truncate(fs, tempFile, recoverable.offset());
out = fs.append(tempFile);
}结论
Apache Flink 构建在实时处理之上,从设计之初就充分考虑了中间状态的保存,而且能够很好地与现有 Hadoop 生态环境结合,因而在大数据领域非常有竞争力。它还在高速发展之中,近期也引入了 Table API、流式 SQL、机器学习等功能,像阿里巴巴这样的公司也在大量使用和贡献代码。Flink 的应用场景众多,有很大的发展潜力,值得一试。



![[230528] 托福阅读真题|TPO66 13/30|整卷得分22/30|9:45~10:45|15:40~16:40](https://img-blog.csdnimg.cn/82b16bf7d5644c408dc6f2ba3d3cf89a.png)