bug:Golang解决csv文件用excel打开中文乱码问题
1 场景及分析
场景:今天在生成csv文件之后,测试发现用office和wps打开乱码
- 分析:经过测试之后发现使用记事本打开不乱码,同时用记事本打开之后另存为ANSI编码之后用office和wps打开之后也不乱码
- 由此可以断定应该是生成的csv文件缺少bom头导致,office和wps无法断定使用哪种编码打开文件,最终产生中文乱码问题
拓展:BOM头
BOM(Byte Order Mark字节顺序标记)是用来判断文本文件是哪一种Unicode编码的标记,其本身是一个Unicode字符(“\uFEFF”),位于文本文件头部。 在不同的Unicode编码中,对应的bom的二进制字节也不同,因此在文件写入的时候,我们通常根据BOM头判断是哪种编码
2 解决
由此可以知道,是因为我们的文件没有BOM头导致中文乱码,所以我们对症下药,直接写入BOM头即可
- writer.Write([]string{“\xEF\xBB\xBF”})
package main
import (
"encoding/csv"
"fmt"
"os"
)
func writeBom(fileName string) {
//1. 打开文件
f, err := os.OpenFile(fileName, os.O_RDWR, 0666)
if err != nil {
fmt.Println("open file error, err=", err)
}
//2. 获取文件的writer
writer := csv.NewWriter(f)
//3. 写入UTF-8编码的BOM头[根据自己文件编码写入对应的BOM头即可]
//写入UTF-8 BOM头,避免使用excel软件打开.csv文件出现中文乱码
err = writer.Write([]string{"\xEF\xBB\xBF"})
if err != nil {
fmt.Println("写入bom头失败...")
return
}
//4. 刷新
writer.Flush()
fmt.Println("写入bom头成功....")
}
func main() {
fileName := "E:\\Go\\GoPro\\src\\go_code\\demo01\\bom\\test.csv"
writeBom(fileName)
}
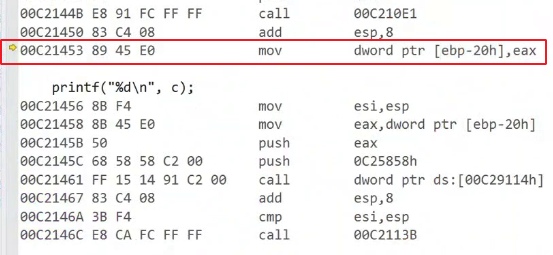
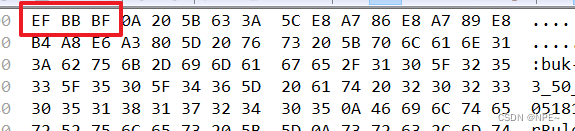
结果:
写入之后,用十六进制查看
3 拓展:常见编码和BOM头
①中文编码:
- gb2312 (采用两个字节保存字符汉字,英文数字一个字节)
- GBK (采用两个字节保存字符汉字,英文数字一个字节)
- GB18030 (英文数字都是一个字节,中文是两个或四个字节)
- Unicode字符集(包含每个国家的所有字符)国际通用,unicode编码 使用两个字节—65536个字符,浪费空间为了节省空间使用转码形式
- utf-8 使用 1 、2、3个字节 (EF BB BF 记事本添加的BOM(Byte Order Mark)头,编码的标记)
- utf-16 使用两个字节—65536个字符 (FF FE 小端(尾) FE FF 大端(尾))
- utf-32 使用4个字节
- 台湾 big5
- ANSI:在简体中文Windows操作系统中, ANSI 编码代表 GBK 编码
②BOM头(记事本特有的)BOM头: Byte Order Mark
- 标识文件的编码,实际大小比数据多3个字节
- 直接在记事本编辑数据保存,默认会给你的数据添加上BOM头,使你的文件的大小比实际数据多3个字节(utf-8编码)。但是,当你使用java程序往记事本写入数据的时候,不会添加BOM头
- 例如:当你用utf-8的格式编码的时候,用程序去读取文件,虽然显示的数据是文件中保存的数据,但是,可以用EditPlus打开程序编译后的.class文件,并且转化为16进制展示,你就会发现,在前面的3个字节会是 :EF BB BF 这三个字节告诉记事本,这是一个用utf-8编码的文件。
③分类
- utf-8 EF BB BF
- utf-16(Unicode) FF FE 编码的时候,小的在后面(FE在后面) 小端 little endian
- utf-16(Unicode big endian) FE FF 编码的时候,大的在后面(FF在后面) 大端 little endian
我用Notepad2新建个文本,写上2个字: 我a
1.先转成ANSI编码:用Hex WorkShop打开 CE D2 61 (我:CE D2 , a:61H)
2.转成Unicode编码:(little-endian) FF FE 11 62 61 00 (我:6211H , a:0061H)
3.转成Unicode编码:(big-endian) FE FF 62 11 00 61
4.转成UTF-8编码: E6 88 91 61 (我:E68891H , a:61H)
5.转成UTF-8编码:(带BOM) EF BB BF E6 88 91 61 (就多了个EF BB BF头)
3.1 ANSI
(American National Standards Institute,美国国家标准学会)
ANSI编码标准是指所有从基本ASCII码基础上发展起来的编码标准,
比如扩展的ASCII码(128~255占用)、GB2312、GBK、GB18030、BIG5等。每种编码在ANSI标准中都为一页,
比如encoding.gb2312页代表GB2312字符集编码
3.2 ASCII
(American Standard Code for Information Interchange,美国信息交换标准码)码
ANSI的ASCII字符集占一个字节 ,8个位
起始占用: 0x00-0x7f(127个字符状态) ,半角
扩充后全部占用: 0x00-0xff(共256个字符)
3.3 GB2312
常说的全角,使用2个字节编码,共收录了7445个字符,包括6763个汉字和682个其它符号
小于127的字符意义与原来相同,
当两个大于127的字节连在一起,就表示一个汉字,
前面的一个字节(高字节)从0xA1-0xF7,后面一个字节(低字节)从0xA1-0xFE。
GB2312的两个字节的最高位都是1,符合这个条件的码位只有128*128=16384个
3.4 GBK
不再要求低字节一定小于127,只要第一个字节大于127,就认为是一个汉字的开始,
不管后面的字节是否小于127,都要和第一个字节组成一个两字节的汉字.
GBK包含了GB2312的所有内容,同时又增加了近20000个新的汉子(包括繁体字)和符号
3.5 BG18030
就是GBK的升级版,增加了很多字符,
中文Windows的缺省内码还是GBK,因为GB18030相对GBK增加的字符,
普通人是很难用到的
BG18030每个字可以由1个、2个或4个字节组成
单字节:其值从0到0x7F。
双字节:第一个字节的值从0x81到0xFE,第二个字节的值从0x40到0xFE(不包括0x7F)
四字节:第一个字节的值从0x81到0xFE,第二个字节的值从0x30到0x39,第三个字节从0x81到0xFE,第四个字节从0x30到0x39。
3.6 BIG5
是香港、台湾繁体中文区的字符集编码标准。由于是各自独立完成编码标准,所以最后互相不兼容。
从ASCII、GB2312、GBK到GB18030,,这些编码方法是向前兼容的,即同一个字符在这些方案
中总是有相同的编码,区分中文编码的方法是高字节的最高位不为0。按照程序员的称呼,
GB2312、GBK到GB18030和BIG5都属于DBCS(double-byte charater set,双字节字符集)
或者说MBCS(mutil-byte charater set,多字节字符集)
在DBCS双字节字符集中,GB内码的存储格式始终是big endian,即高位在前。
在读取DBCS字符流时,只要遇到高位为1的字节,就可以将下两个字节作为一个双字节编码,
而不用管低字节的高位是什么。
3.7 Unicode
Unicode的学名是"Universal Multiple-Octet Coded Character Set",简称为UCS。
UCS可以看作是"Unicode Character Set"的缩写。
ISO(International Organization for Standardization或International Standard Organized)国际标准化组织
废除了所有地区性编码方案,重新搞了一套可以包含地球上所有文化的文字和符号的编码方案。
他们称这个方案为Universal Multiple-Octet Coded Character Set(通用多8位编码字符集),简称UCS
ISO直接规定必须用两个字节,也就是16位来统一表示所有的字符,对于ASCII里的那些“半角”字符,
UNICODE保持其原码不变,只是将其由原来的8位扩展为16位,而其它文化和语言的字符则全部重新统一编码。
由于“半角”英文符号只用到了低8位,所以其高8位永远是0,会多浪费一倍的空间.
由于UNICODE设计初期的局限性(并没有考虑到与现有编码的兼容性),
所以使得UNICODE与GBK(GB18030、BG2312等)在排版上完全不一样,
没有一种简单的算法可以把内容从UNICODE编码和两一种编码进行转换,这种转换必须通过查表来进行。
Unicode是2个字节的编码,所以也称UCS-2,如果几百年后地球上的字符又多了很多的话,ISO已经准备好了UCS-4方案了
也就是4个字节的编码,而Unicode只与ASCII兼容(更准确地说,是与ISO-8859-1兼容),与GB码不兼容。
例如“汉”字的Unicode编码是6C49,而GB码是BABA。
在非 Unicode 环境下,由于不同国家和地区采用的字符集不一致,很可能出现无法正常显示所有字符的情况。
微软公司使用了代码页(Codepage)转换表的技术来过渡性的部分解决这一问题,
即通过指定的转换表将非 Unicode 的字符编码转换为同一字符对应的系统内部使用的 Unicode 编码。
可以在“语言与区域设置”中选择一个代码页作为非Unicode编码所采用的默认编码方式,
如936为简体中文GBK,950为正体中文Big5(皆指PC上使用的)。在这种情况下,
一些非英语的欧洲语言编写的软件和文档很可能出现乱码。而将代码页设置为相应语言中文处理又会出现问题,
这一情况无法避免。从根本上说,完全采用统一编码才是解决之道,但目前尚无法做到这一点。
代码页技术现在广泛为各种平台所采用。UTF-7(的代码页是65000,UTF-8 的代码页是65001。
3.8 UTF-8
任何文字在Unicode中都对应一个值,这个值称为代码点code point.代码点的值通常写成U+ABCD的格式
而文字和代码点之间的对应关系就是UCS-2(Universal Character Set coded in 2 octets)
UCS-4,即用四个字节表示代码点。
它的范围为 U+00000000~U+7FFFFFFF,其中 U+00000000~U+0000FFFF和UCS-2是一样的。
UCS-2和UCS-4只规定了代码点和文字之间的对应关系,并没有规定代码点在计算机中如何存储。
规定存储方式的称为UTF(Unicode Transformation Format),其中应用较多的就是UTF-16和UTF-8了
UTF是“UCS Transformation Format”的缩写,
是"Unicode字符集转换格式",是"怎么样将Unicode定义的数字转换成程序数据"
UTF-8以字节为单位对Unicode进行的特殊编码。从Unicode到UTF-8的编码方式如下:
Unicode编码(16进制) ║ UTF-8 字节流(二进制)
000000 - 00007F ║ 0xxxxxxx
000080 - 0007FF ║ 110xxxxx 10xxxxxx
000800 - 00FFFF ║ 1110xxxx 10xxxxxx 10xxxxxx
010000 - 10FFFF ║ 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
UTF-8的特点是以字节为单位对Unicode进行编码,对不同范围的字符使用不同长度的编码。
对于0x00-0x7F之间的字符,UTF-8编码与ASCII编码完全相同。UTF-8编码的最大长度是4个字节。
从上表可以看出,4字节模板有21个x,即可以容纳21位二进制数字。Unicode的最大码位0x10FFFF也只有21位。
例1:“汉”字的Unicode编码是0x6C49。0x6C49在0x0800-0xFFFF之间,使用3字节模板了 1110xxxx 10xxxxxx 10xxxxxx
将0x6C49写成二进制是:0110 1100 0100 1001, 用这个比特流依次代替模板中的x,
得到:11100110 10110001 10001001,即E6 B1 89。
例2:Unicode编码0x20C30在0x010000-0x10FFFF之间,使用用4字节模板了:
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx。
将0x20C30写成21位二进制数字(不足21位就在前面补0):0 0010 0000 1100 0011 0000,
用这个比特流依次代替模板中的x,
得到:11110000 10100000 10110000 10110000,即F0 A0 B0 B0。
UTF-8是ASCII的一个超集。因为一个纯ASCII字符串也是一个合法的UTF-8字符串,所以现存的ASCII文本不需要转换。
为传统的扩展ASCII字符集设计的软件通常可以不经修改或很少修改就能与UTF-8一起使用。
使用标准的面向字节的排序例程对UTF-8排序将产生与基于Unicode代码点排序相同的结果。
(尽管这只有有限的有用性,因为在任何特定语言或文化下都不太可能有仍可接受的文字排列顺序。)
UTF-8和UTF-16都是可扩展标记语言文档的标准编码。所有其它编码都必须通过显式或文本声明来指定。
任何面向字节的字符串搜索算法都可以用于UTF-8的数据(只要输入仅由完整的UTF-8字符组成)。
但是,对于包含字符记数的正则表达式或其它结构必须小心。
3.9 UTF-16、UTF-32
- UTF-16编码以16位无符号整数为单位,详见百度google
- UTF-32编码以32位无符号整数为单位,详见百度google
字节序和BOM
① 字节序
PowerPC系列采用big endian方式存储数据,
而x86系列则采用little endian方式存储数据,
比如:0x12345678 双字型数据 ,占4个字节
低位数据----------------->高位数据
12 34 56 78 H
低地址------------------->高地址
0x01 0x02 0x03 0x04 内存中
| 12 | 34 | 56 | 78 | big endian 方式
| 78 | 56 | 34 | 12 | little endian方式
little endian方式个人理解:
(起始地址存放高位数据,左边12是低数据位放在尾部,是低数据位,不是指二进制中的右边的低数值位)
C/C++语言编写的程序里数据存储顺序是跟编译平台所在的CPU相关的,
而java是跨平台的,采用big endian方式来存储数据
网络字节序也是big endian方式
②BOM
BOM(byte-order mark)文件编码头,即 字节顺序标记.
它是插入到以UTF-8、UTF16或UTF-32编码文件开头的特殊标记,
用来标记多字节编码文件的编码类型和字节顺序(big-endian或little- endian)。
一般用来识别文件的编码类型。
根据字节序的不同,UTF-16可以被实现为UTF-16LE或UTF-16BE,UTF-32可以被实现为UTF-32LE或UTF-32BE。
例如:
Unicode编码 ║ UTF-16LE ║ UTF-16BE ║ UTF32-LE ║ UTF32-BE
0x006C49 ║ 49 6C ║ 6C 49 ║ 49 6C 00 00 ║ 00 00 6C 49
0x020C30 ║ 43 D8 30 DC ║ D8 43 DC 30 ║ 30 0C 02 00 ║ 00 02 0C 30
Unicode标准建议用BOM(ByteOrderMark)来区分字节序,
即在传输字节流前,先传输被作为BOM的字符"零宽无中断空格"。
这个字符的编码是FEFF,而反过来的FFFE(UTF-16)和FFFE0000(UTF-32)在Unicode中都是未定义的码位,
不应该出现在实际传输中。
BOM编码头 常见形式如下:
EF BB BF = UTF-8 (可选标记,因为Unicode标准未有建议)
FE FF = UTF-16, big-endian (大尾字节序标记)
FF FE = UTF-16, little-endian (小尾字节序标记) (也是windows中的Unicode编码默认标记)
00 00 FE FF = UTF-32, big-endian (大尾字节序标记)
FF FE 00 00 = UTF-32, little-endian (小尾字节序标记)
对于UTF-8来说,BOM标记的有无并不是必须的,是可选的,因为UTF8字节没有顺序,不需要标记.
也就是说一个UTF-8文件可能有BOM,也可能没有BOM.
微软在自己的UTF-8格式的文本文件之前加上了EF BB BF三个字节,
windows上面的notepad等程序就是根据这三个字节来确定一个文本文件是ASCII的还是UTF-8的,
然而这个只是微软暗自作的标记, 其它平台上不一定会对UTF-8文本文件做个这样的标记。
微软的一些软件会做这种检测,但有些软件不做这种检测, 而把它当作正常字符处理。(传说中的乱码问题)
再举个例子
说的是Notepad2这个体积小,启动速度快,功能强的轻量级文本编辑器,代码高亮等,完全可以替代系统记事本
以前刚用Notepad2的时候,经常在打开一个文本文件时显示乱码,点什么编码转换也没用,
比如ViDown.exe维棠下载器程序目录下的Readme.txt,打开就是乱码,点击"文件",“编码"方式,看到的是Unicode,
ok.先关掉Readme.txt,用16进制编辑器比如Hex WorkShop打开后发现前2个字节是CF C2,这在GBK中的编码是
下载的"下”,说明该Readme.txt编码不是Unicode,而是属于ANSI编码,
那么避免乱码就要对Notepad2设置下,点"文件",“编码’,“默认”,在下拉菜单中找到ANSI936,(上面说过它就是GBK)
并勾上"跳过Unicode检测”, 好了再打开Readme.txt就正常显示中文了.
在"文件",“编码’,下有"UTF-8"和"UTF-8包含签名”,这2个有什么区别呢?
其中"UTF-8包含签名",这一选项是将文件编码格式转换为UTF-8(包含BOM编码头),
翻译成"包含签名"就看不懂了…
③关系
参考:https://www.cnblogs.com/saxum/p/15775502.html