文章目录
- 一、前言
- 二、R-CNN原理步骤
- 2.1.Selective Search生成目标检测框
- 2.2.对候选区域使用深度网络提取特征
- 2.3.SVM分类
- 2.4.使用回归器精细修正候选框位置
- 三、总结
- 参考博客与学习视频
一、前言
学习目标检测当然要学习目标检测领域的开山之作R-CNN,本文为个人笔记。

二、R-CNN原理步骤
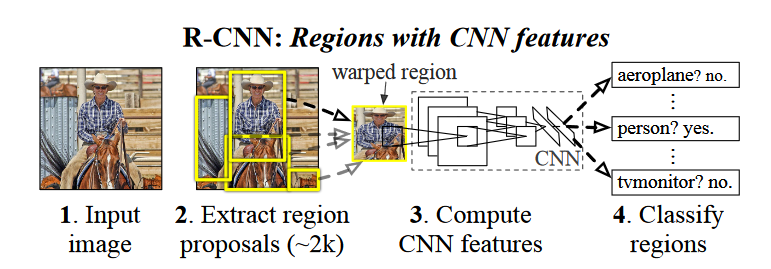
R-CNN分为四个步骤:
1.由SS算法生成大约1-2k个候选框。
2.将候选框输入深度网络,提取特征。
3.使用SVM分类器得到每一个候选框属于每一个类别的分数。
4.使用回归器修正候选框位置
2.1.Selective Search生成目标检测框
关于Selective search的原理,详细的可以去看我写的另一篇博客博客地址。简要来说:大概的意思就是首先根据图像分割的算法来初始化划分区域,
然后根据不同颜色模式、目标颜色、纹理、大小、形状等特征来计算相似度合并子区域,使得区域相比穷举法更少,节省计算资源,提高效率,
同时可以有很好的召回率,使得生成的候选框可以很好的覆盖所有待检测目标。
2.2.对候选区域使用深度网络提取特征
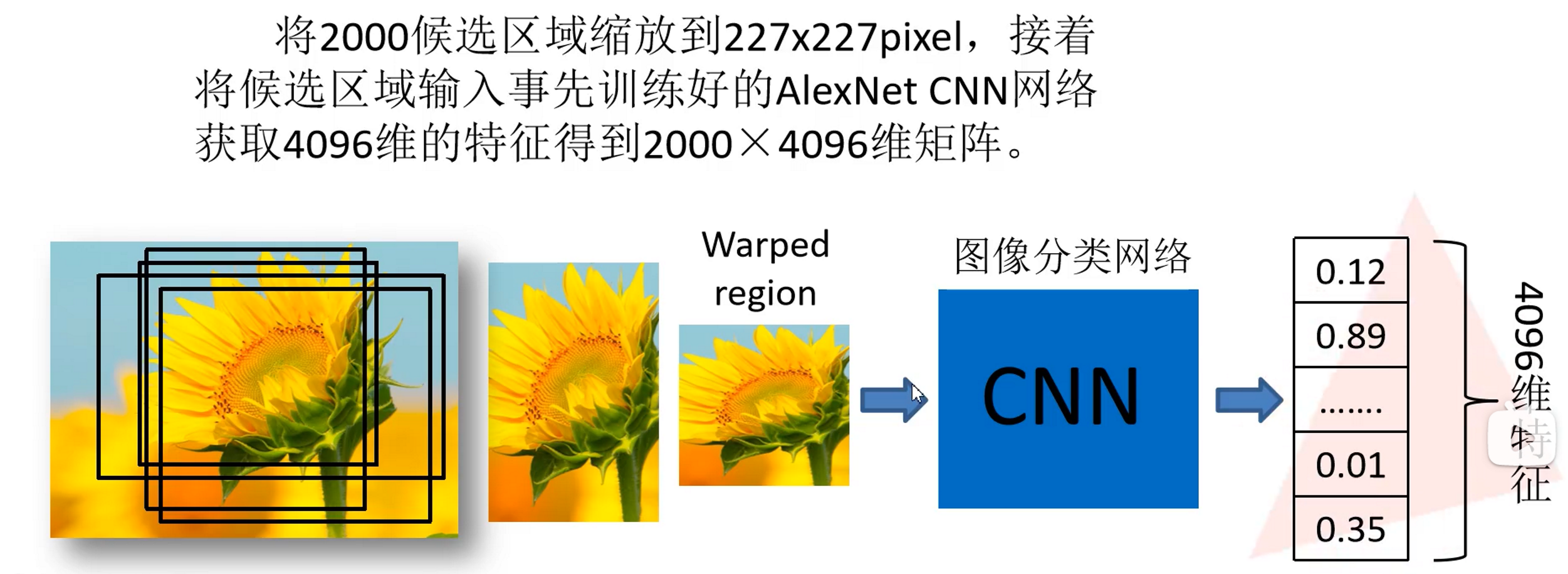
与之前不同的是这里的AlexNet去掉了后面的全连接层,只保留了一层全连接
2.3.SVM分类
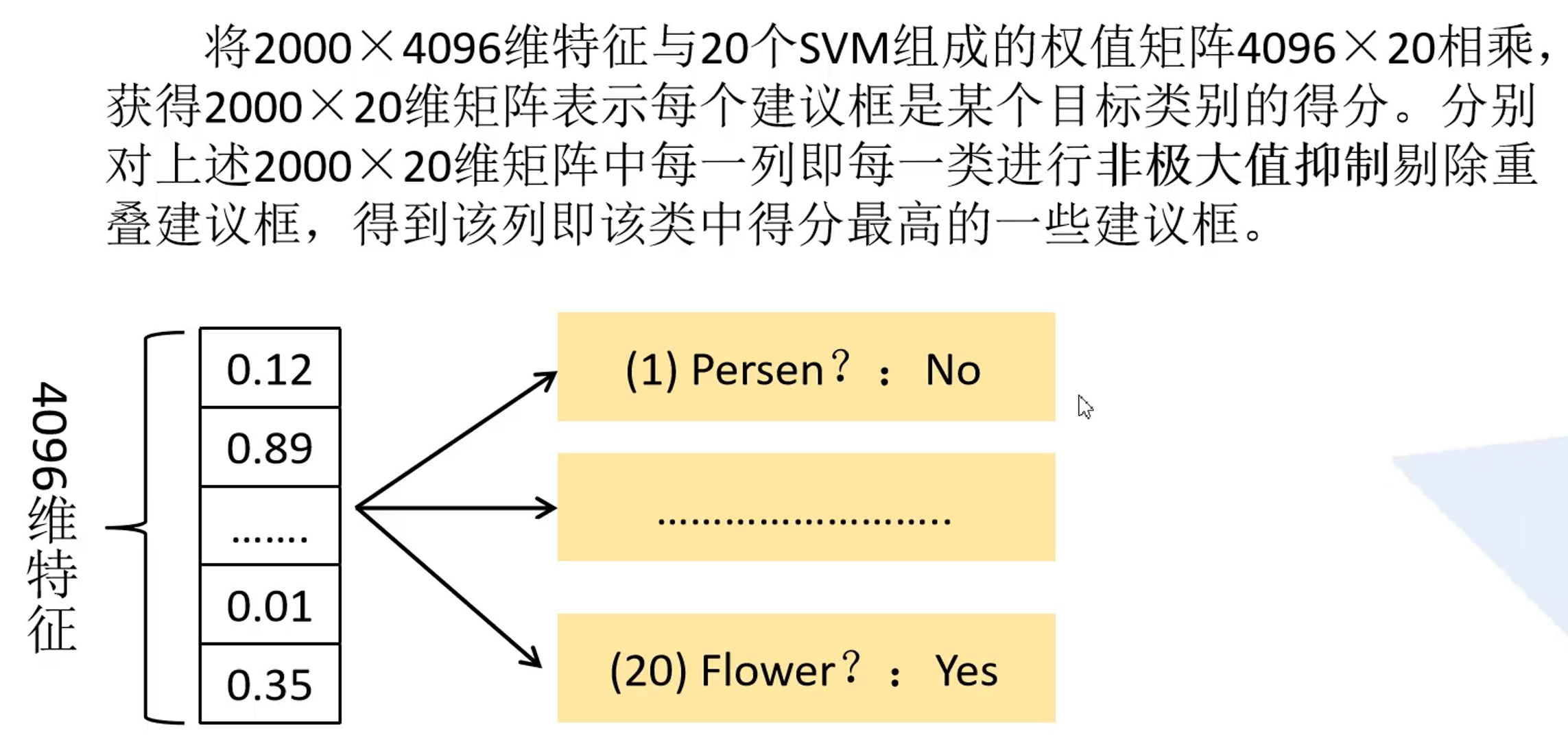
因为这里使用的使PASCAL VOC数据集,所以最终是有20个SVM分类器
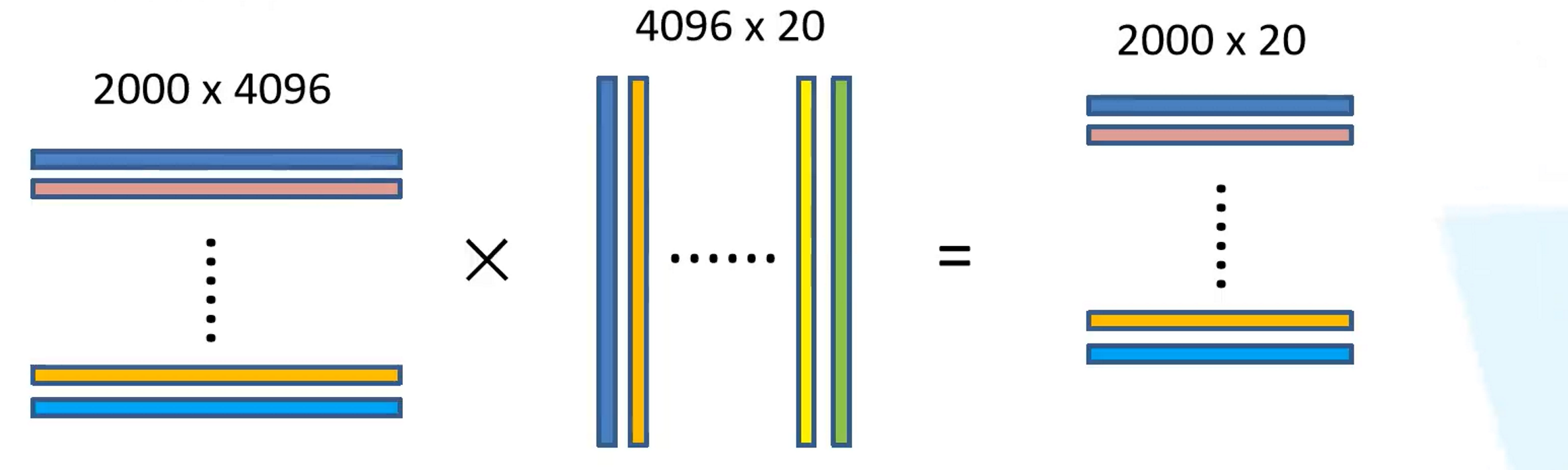
如上图,2000✖4096的特征矩阵代表了2000个候选框经过深度卷积网络后提取的特征,对于每一个候选框,也即对于每一个4096维特征向量,我们需要使用SVM去判断它的类别,对于每一个类别都需要判断,总共20个类别,因此权值矩阵为2000✖20,最终得到的2000✖20的概率矩阵,每一行代表了它属于这20个类别的概率分布,对于每一个20维的概率向量来说,当中的每一个位置上的概率表示这个候选框目标属于该对应位置类别的概率。
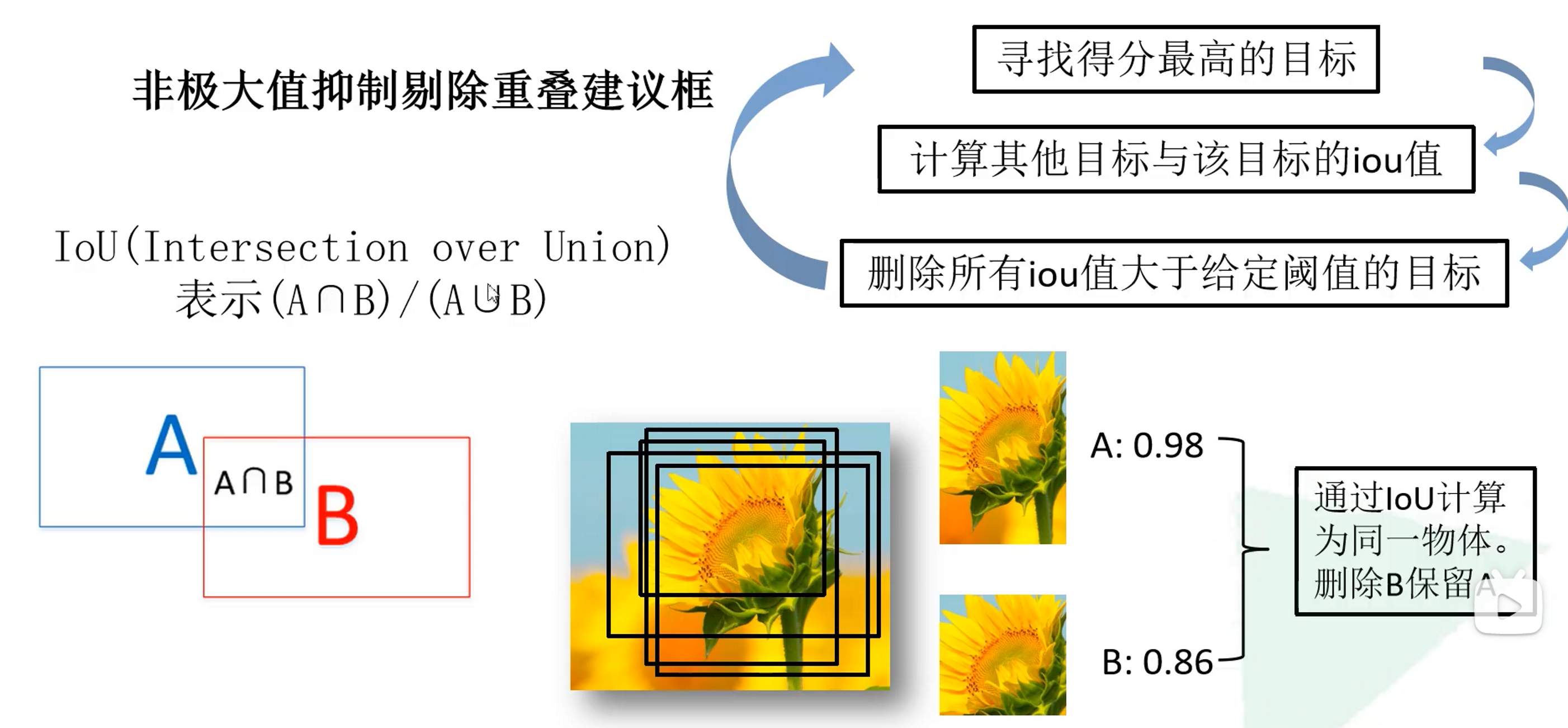
得到所有候选框的类别分数后,还要进行非极大值抑制来剔除一些重叠的候选框
举例:假设我们得到上图中对于向日葵的一些候选框,通过输入深度卷积网络提取特征,再使用SVM分类器,我们最终得到了这些候选框对于向日葵这个类别的分数,我们找出得分最高的候选框,计算该候选框与其他候选框的IOU,如果IOU大于某个阈值,我们可以认为这两个框是一样的,可以删除掉这个候选框。保留下来的多个候选框我们可以认为都是向日葵的候选框,只不过位置不一样,也就是说图片中有多个向日葵。
疑问1:可能有人在想为什么不直接保留最大得分的候选框,设定一个阈值大于某个分数不就也可以保留了多个候选框吗?
答:这么理解其实是不对的 ,因为我们并不能保证候选框检测的不是同一个目标,如果检测的的同一个目标,分数都大于这个阈值,岂不是保留了同一个目标的多个预测框,这里非极大值抑制个人理解是为了删除同一个目标的多余候选框,也就是说最后保留下来的候选框我们认为它们检测不是同一个目标。
疑问2:图中有循环的操作,是怎么进行的呢?
答:个人认为是我们先找最大的得分的检测框,然后计算其他的框与它的IOU,删除和它检测的是同一个目标的检测框,保留这个最大的检测框(这个检测框之后不再加入计算),然后再继续寻找一个得分最高的检测框,同样的删除与它检测是同一个目标但是得分没有它高的检测框,依此类推。
2.4.使用回归器精细修正候选框位置

这里的进一步筛选指的是:需要对上一步筛选后的候选框与真实框计算IOU,保留IOU大于某个阈值的候选框,目的是为了删除与真实框差别过大的候选框。之后同样使用回归器来回归修正候选框位置,得到修正的中心点的x,y偏移量与x,y方向缩放比例。
三、总结


参考博客与学习视频
B站up主视频(强推)
原论文地址
代码地址