1-什么是桶排序法
什么是桶排序法?其实说白了就是把需要排列的元素分到不同的桶中,然后我们对这些桶里的元素进行排序的一种方式,然后我们在根据桶的顺序进行元素的合并。(不过前提是要确定桶的数量以及大小)
按照稍微正式的说法是:
桶排序法是一种基于计数的排序算法。它的基本思想是将要排序的数据分到几个有序的桶里,每个桶里的数据再单独进行排序。桶内排完序之后,再把每个桶里的数据按照顺序依次取出,组成的序列就是排好序的序列。
具体实现时,首先确定桶的个数和每个桶所能容纳数据的范围,然后遍历待排序数据,将每个数据放入对应的桶中。接着对每个桶里的数据进行排序,可以使用其它排序算法,比如插入排序、快速排序等。最后依次取出每个桶里的有序数据,组成排序好的序列。
桶排序法的时间复杂度为O(n),但是其空间复杂度较高,需要额外的桶来存储数据。同时,桶的个数和桶的大小需要根据数据的分布情况来确定,如果数据分布不均匀,容易导致某些桶内数据过多而造成空间浪费或者桶内排序时间过长。
动画演示(来源于哔哩哔哩up主-究尽数学)

1.1 大致应用步骤
-
确定桶的数量和范围:
- 确定要排序的元素的范围,并选择合适的桶的数量。一般来说,桶的数量可以根据元素的分布情况和性能需求进行调整。
-
创建空桶:
- 根据确定的桶的数量,创建对应数量的空桶,用于存放待排序的元素。
-
将元素分配到桶中:
- 遍历待排序的元素列表,根据每个元素的值将其分配到相应的桶中。可以使用一定的映射规则或算法来确定元素应该分配到哪个桶中。
-
对每个桶进行排序:
- 对每个非空桶中的元素进行排序。可以使用其他排序算法(如插入排序、快速排序等)来对每个桶中的元素进行排序。
-
合并桶中的元素:
- 按照桶的顺序,将每个桶中的元素合并起来形成最终的有序序列。可以按照桶的顺序依次取出每个桶中的元素,并将它们按顺序组合起来形成有序序列。
-
返回有序序列:
- 合并完成后,得到的就是排序后的有序序列。
不过有一点一定要注意,那就是适用元素范围较小且数据分布相对均匀的情况。对于大范围的数据或分布不均匀的数据,可能不太使用。
下面用个示例来说明:
假如我们有一个待排序的整数数组:[35, 17, 25, 10, 42, 29, 50, 22]。我们可以使用桶排序对该数组进行排序。
大致的步骤如下:
-
创建桶:根据待排序数组的范围,创建一定数量的桶。假设范围为0-100,我们可以创建10个桶,每个桶表示一个范围区间,如桶0表示0-9,桶1表示10-19,以此类推。
-
分配元素到桶:遍历待排序数组,将每个元素根据其值分配到对应的桶中。例如,35分配到桶3,17分配到桶1,25分配到桶2,以此类推。
- 桶0:
- 桶1: 17
- 桶2: 25, 22
- 桶3: 35, 29
- 桶4:
- 桶5:
- 桶6:
- 桶7:
- 桶8:
- 桶9: 10, 42, 50
-
对每个桶进行排序:对每个非空的桶应用排序算法进行排序,可以选择插入排序、快速排序等。在本例中,我们使用插入排序对每个桶内的元素进行排序。
- 桶0:
- 桶1: 17
- 桶2: 22, 25
- 桶3: 29, 35
- 桶4:
- 桶5:
- 桶6:
- 桶7:
- 桶8:
- 桶9: 10, 42, 50
-
合并桶的结果:按照桶的顺序,将每个非空的桶中的元素按顺序合并到一个新的数组中,得到最终的排序结果。
最终得到的排序结果为:[10, 17, 22, 25, 29, 35, 42, 50]
1.2 可以和哪些排序算法使用
- 插入排序(Insertion Sort):
- 桶排序将元素分散到不同的桶中,每个桶中的元素相对较少。可以对每个非空桶使用插入排序来进行排序。插入排序适用于小规模的数据集,其时间复杂度为O(n^2),但对于已经基本有序的桶来说,插入排序可以快速地完成排序。
- 快速排序(Quick Sort):
- 在桶排序中,每个桶可以视为一个子序列。对每个非空桶应用快速排序算法进行排序,然后按照桶的顺序将它们合并起来。快速排序的平均时间复杂度为O(nlogn),在处理桶时可以有效地进行分区和排序。
- 归并排序(Merge Sort):
- 桶排序后,每个桶内的元素已经是有序的。可以使用归并排序的思想将每个桶中的有序序列合并成一个有序序列。归并排序的时间复杂度为O(nlogn),适用于大规模数据集的排序。
- 基数排序(Radix Sort):
- 基数排序是一种按照元素位数进行排序的算法。在桶排序中,可以将每个桶看作是基数排序中的一个位数,将元素按照每个位数的值分配到对应的桶中,然后按照桶的顺序进行合并。基数排序的时间复杂度为O(kn),其中k是元素的位数。
2-桶排序法的优点
- 高效的时间复杂度:在均匀分布的情况下,桶排序的平均时间复杂度接近线性,具有较高的排序效率。这是因为桶排序将元素分散到多个桶中,每个桶独立地进行排序,而不需要像比较排序算法那样逐个比较和交换元素。
- 适用于外部排序:桶排序适用于需要排序的数据量非常大,无法全部加载到内存中的情况。它可以通过将数据分配到磁盘上的多个桶中,对每个桶进行排序,然后按照桶的顺序合并结果,实现外部排序。
- 可以实现稳定排序:通过在每个桶中使用稳定的排序算法,如插入排序,可以实现桶排序的稳定性。稳定排序意味着具有相同值的元素在排序后的顺序仍然保持不变。
- 适用于分布均匀的数据:当待排序的数据在各个桶中分布相对均匀时,桶排序的效率最高。对于数据分布不均匀的情况,桶排序的性能可能会受到影响,需要在每个桶中使用其他排序算法。
- 可以灵活调节桶的数量:通过调节桶的数量,可以对桶排序的性能进行优化。较少的桶数量可以节省内存空间,但可能会导致桶中元素的数量较多,需要使用较复杂的排序算法。较多的桶数量可以使每个桶中的元素较少,简化排序过程,但可能会消耗更多的内存。
3-桶排序法的缺点
- 需要额外的存储空间:桶排序需要额外的存储空间来存储桶,桶的数量与待排序元素的数量相关。如果待排序元素数量非常大,可能需要分配大量的桶和相应的存储空间,占用更多的内存。
- 对数据分布要求较高:桶排序的性能受到待排序数据的分布情况影响较大。如果数据分布不均匀,导致部分桶中的元素数量过多,可能需要在每个桶中使用其他排序算法进行排序,从而降低了桶排序的效率。
- 不适用于数据范围过大或过小的情况:当待排序的数据范围非常大或非常小时,桶排序可能不是最佳选择。如果数据范围过大,需要创建大量的桶,消耗过多的内存;如果数据范围过小,桶之间的差距会变得很大,导致很多桶为空,浪费了存储空间。
- 不稳定性:桶排序本身并不保证稳定性,即相同值的元素在排序后的顺序可能会改变。要实现稳定的桶排序,需要在每个桶内使用稳定的排序算法,增加了额外的操作和复杂性。
- 不适用于动态数据集:桶排序对于动态数据集的排序效果不佳。如果待排序数据集经常发生变化,需要频繁地重新进行桶排序,而且可能需要重新分配桶和重新排序,导致性能下降。
4-桶排序法可以应用哪些场景
- 范围有限的整数排序:桶排序对于待排序的整数数据集,在数据范围较小且分布相对均匀的情况下,可以实现高效的排序。例如,对学生成绩(0-100范围)进行排序。
- 外部排序:当待排序的数据量过大,无法一次性全部加载到内存中时,桶排序可以进行外部排序。它可以将数据分散到磁盘上的多个桶中,对每个桶进行排序,然后按照桶的顺序合并结果,实现排序。
- 基于分布的排序:如果待排序数据集的分布相对均匀,桶排序可以充分利用数据的分布特点,将数据分散到多个桶中进行独立排序,从而提高排序效率。例如,对一段时间内的温度数据进行排序。
- 并行排序:由于桶排序将数据分散到多个桶中,每个桶可以独立进行排序,因此可以在多个处理单元或多个线程上并行执行排序操作,提高排序的速度。
- 分布式排序:桶排序可以应用于分布式系统中的排序问题。将待排序数据分散到不同的节点或机器上的桶中,各个节点独立进行桶内排序,最后再合并结果,实现分布式的排序。
- 部分有序数据排序:如果待排序数据集中存在一部分已经有序的子序列,桶排序可以有效地利用这些子序列的有序性。通过将子序列分散到不同的桶中,各个桶内的排序效率较高,最后再将各个桶的结果合并起来,提高整体的排序效率。
从上面来看,桶排序适用性受到数据的规模、分布、内存以及计算等一些因素的影响。具体使用什么方式需要根据实际 的情况进行。
5-举例
下面我们来举一个例子:
#include <stdio.h>
#include <stdlib.h>
// 定义桶的数量
#define BUCKET_COUNT 10
// 定义桶的结构
typedef struct
{
int count;
int *values;
} Bucket;
void bucketSort(int arr[], int n)
{
// 创建桶数组
Bucket buckets[BUCKET_COUNT];
// 初始化桶
for (int i = 0; i < BUCKET_COUNT; i++)
{
buckets[i].count = 0;
buckets[i].values = NULL;
}
// 将元素放入桶中
for (int i = 0; i < n; i++)
{
int bucketIndex = arr[i] / BUCKET_COUNT;
Bucket *bucket = &buckets[bucketIndex];
// 扩展桶的容量
bucket->values = realloc(bucket->values, (bucket->count + 1) * sizeof(int));
bucket->values[bucket->count] = arr[i];
bucket->count++;
}
// 对每个桶中的元素进行排序
for (int i = 0; i < BUCKET_COUNT; i++)
{
Bucket *bucket = &buckets[i];
int bucketSize = bucket->count;
// 使用简单的插入排序对桶中的元素进行排序
for (int j = 1; j < bucketSize; j++)
{
int key = bucket->values[j];
int k = j - 1;
while (k >= 0 && bucket->values[k] > key)
{
bucket->values[k + 1] = bucket->values[k];
k--;
}
bucket->values[k + 1] = key;
}
}
// 合并桶中的元素到原始数组
int index = 0;
for (int i = 0; i < BUCKET_COUNT; i++)
{
Bucket *bucket = &buckets[i];
int bucketSize = bucket->count;
for (int j = 0; j < bucketSize; j++)
{
arr[index] = bucket->values[j];
index++;
}
free(bucket->values);
}
}
int main()
{
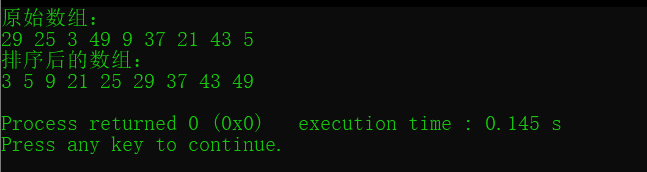
int arr[] = {29, 25, 3, 49, 9, 37, 21, 43, 5};
int n = sizeof(arr) / sizeof(arr[0]);
printf("原始数组:\n");
for (int i = 0; i < n; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
bucketSort(arr, n);
printf("排序后的数组:\n");
for (int i = 0; i < n; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
return 0;
}
#include <iostream>
#include <vector>
#include <algorithm>
void bucketSort(std::vector<int> &arr, int bucketSize)
{
if (arr.empty())
{
return;
}
// 找到最大值和最小值
int minValue = arr[0];
int maxValue = arr[0];
for (int i = 1; i < arr.size(); i++)
{
if (arr[i] < minValue)
{
minValue = arr[i];
}
else if (arr[i] > maxValue)
{
maxValue = arr[i];
}
}
// 计算桶的数量
int bucketCount = (maxValue - minValue) / bucketSize + 1;
// 创建桶
std::vector<std::vector<int>> buckets(bucketCount);
// 将元素分配到桶中
for (int i = 0; i < arr.size(); i++)
{
int bucketIndex = (arr[i] - minValue) / bucketSize;
buckets[bucketIndex].push_back(arr[i]);
}
// 对每个桶中的元素进行排序
for (int i = 0; i < buckets.size(); i++)
{
std::sort(buckets[i].begin(), buckets[i].end());
}
// 合并桶中的元素
int index = 0;
for (int i = 0; i < buckets.size(); i++)
{
for (int j = 0; j < buckets[i].size(); j++)
{
arr[index++] = buckets[i][j];
}
}
}
int main()
{
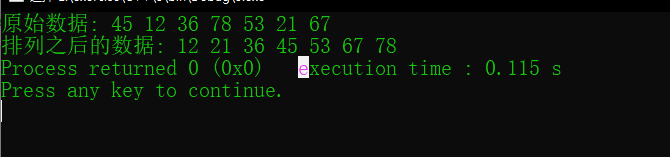
std::vector<int> arr = {45, 12, 36, 78, 53, 21, 67};
int bucketSize = 10;
std::cout << "原始数据: ";
for (int num : arr)
{
std::cout << num << " ";
}
bucketSort(arr, bucketSize);
std::cout << "\n排列之后的数据: ";
for (int num : arr)
{
std::cout << num << " ";
}
return 0;
}
![[数字图像处理]第四章 频率域滤波](https://img-blog.csdnimg.cn/b4a8edd4b3e84cef9de4984c21a5abb8.png)




![[创业之路-68]:科创板上市公司符合哪些条件](https://img-blog.csdnimg.cn/img_convert/abfc5dfbc4304c9f9e5b93e7f5bf067f.jpeg)